“It was five years ago when Dor Laor and Avi Kivity had a dream…” So began the opening remarks at ScyllaDB Summit 2019. The dreams of ScyllaDB’s founders have since manifested and made their impact all across the Big Data industry.
The world’s leading ScyllaDB practitioners gathered in San Francisco earlier this month to hear about the latest ScyllaDB product developments and production deployments. Once again your intrepid reporter tried to keep up with the goings-on, live tweeting, along with others under the #ScyllaDBSummit hashtag about the event’s many sessions.
It’s impossible to pack two days and dozens of speakers into a few thousand words, so I’ll give just the highlights. We’ll get the SlideShare links and videos posted for you over the coming days.
Pre-Summit Programs: Training Day and the Seastar Summit
The day before the official opening of ScyllaDB Summit was set aside for our all-day training program. The training program included novice and advanced administration tracks that were well attended. There were courses on data modeling, debugging, migrating, using ScyllaDB Manager, the ScyllaDB Operator for Kubernetes, and more!

Between sessions students flock around ScyllaDB’s Customer Success Manager Tomer Sandler to learn how to migrate to ScyllaDB.
Training Day was held concurrently as a separate-but-related developer conference: the first-ever Seastar Summit, which featured speakers from Red Hat, Lightbits Labs, Vectorized.io as well as ScyllaDB. It was a unique opportunity for those building solutions based on the Seastar engine to engage directly with peers .
Keynotes

ScyllaDB CEO Dor Laor
The Tuesday keynotes kicked off with ScyllaDB CEO Dor Laor providing a review of how we got to this point in history in terms of scalability. He recounted the C10k problem — the problem with optimizing network sockets to handle 10,000 concurrent sessions. The C10k barrier has since been shattered by orders of magnitude — it is now the so-called “C10M problem” — with real-world examples of 10 million, 12 million or even 40 million concurrent connections.
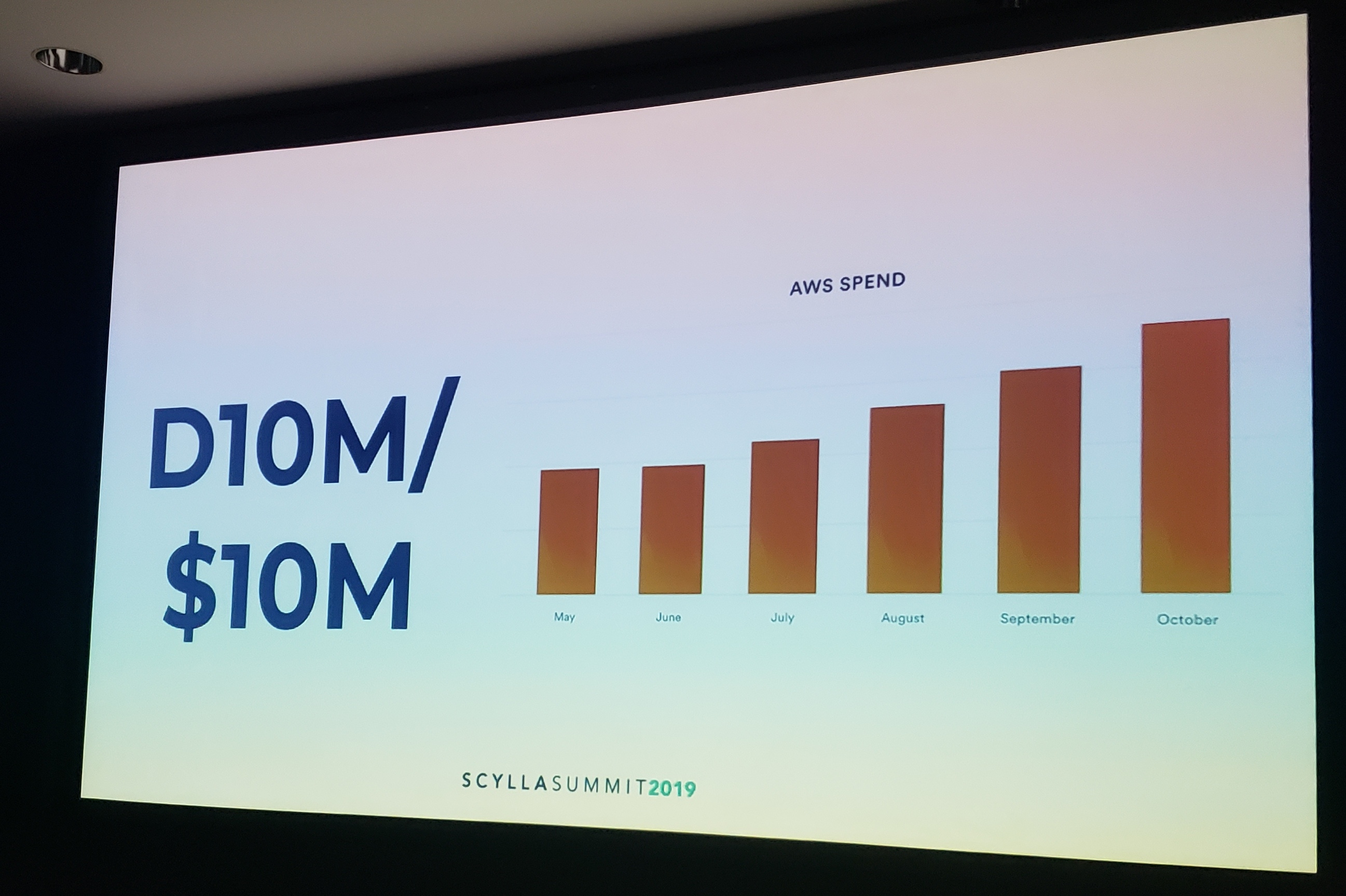
In an analogous vein, there is also the so-called $1 million engineering problem, which has at its core the following axiom: “it’s easy to fall into a cycle where the first response to any problem is to spend more money.”
Dor dubbed this issue the “D10M” problem, where customers are spending $10 million or more on their cloud provider bill. He asserted large organizations using Big Data could literally save millions of dollars a year if they just had performant systems that scaled to their needs.
To that point, Dor brought to the stage ScyllaDB’s VP of Field Engineering, Glauber Costa, and Packet’s Solution Architect James Malachowski to reveal a new achievement in scalability. They had created a test scenario simulating 1 million IoT sensors sampling temperature data every minute over the course of a year. That resulted in a data set of 536 billion temperature readings — 1.44 billion data points per day.
Against that data, they created a query to check for average, min and max temperatures every minute across a given timespan.
To give an idea of how large such a dataset is, if you were to analyze it at 1 million rows per second it would take 146 hours — almost a week. Yet organizations don’t want to wait for hours, never mind days, to take action against their data. They want immediacy of insights, and the capability to take action in seconds or minutes.

Packet’s Solution Architect James Malachowski (left) and ScyllaDB VP of Field Engineering, Glauber Costa (right) describe the architecture needed to scale to 1,000,000,000 reads per second
This was why ScyllaDB partnered with Packet to run the bare-metal instances needed to analyze that data as fast as possible. Packet is a global bare metal cloud built for enterprises. Packet ran the ScyllaDB database on a cluster of 83 instances. This cluster was capable of scanning three months of data in less than two minutes at a speed of 1.1 billion rows per second!
Scanning the entire dataset from disk (i.e., without leveraging any caching) took only 9 minutes.
As Glauber put it, “Bare metal plus ScyllaDB are like peanut butter and jelly.”

Packet’s bare-metal cluster that achieved a billion reads-per-second comprised 83 servers with a total of 2800 physical cores, 34 TB of RAM and 314 TB of NVMe.
And while your own loads may be nowhere near as large, the main point was that if ScyllaDB can scale to that kind of load, it can performantly handle pretty much anything you throw at it.
Dor then retook the stage noted how Jay Kreps, CEO of Confluent, recently scratched out the last word in Nadella’s famous quote, declaring instead “All companies are software.”
Yet even if “all companies are software,” he also noted many company’s software isn’t at all easy. So a major goal of ScyllaDB is to make it EASY for software companies to adopt, to use and to build upon ScyllaDB. He then outlined the building blocks for ScyllaDB that help address this issue.
- ScyllaDB Cloud (NoSQL DBaaS) allows users to deploy a highly-performant scalable NoSQL database without having to hire a team of experts to administer the back end.
- Project Alternator, ScyllaDB’s DynamoDB-compatible API, is now available in beta on ScyllaDB Cloud. Dor noted how with provisioned pricing 120,000 operations per second would cost $85 per hour on DynamoDB whereas running ScyllaDB Alternator a user could do the same workload for $7.50 an hour — an order of magnitude cheaper.
- With workload prioritization, you can now automatically balance workloads across a single cluster, providing greater cost savings by minimizing wasteful overprovisioning.
Beyond that, there are needs for workhorse features coming soon from ScyllaDB, such as
- Database backup with ScyllaDB Manager
- Lightweight Transactions (LWT)
- Change Data Capture (CDC) for database updates and
- User Defined Functions (UDFs) which will support data transformations
While Dor observed the trend to think of “all companies are software,” he also recognized that companies are still at their heart driven by people, highlighting the case of a ScyllaDB user. He finished by making a bold assertion of his own. If all companies are software, then “ScyllaDB is a damned good choice for your software.”
ScyllaDB CTO Avi Kivity

It was then time for Avi Kivity, ScyllaDB’s CTO to take the stage. Avi emphasized how ScyllaDB was doubling down on density. While today’s cloud servers are capable of scaling to 60 terabytes of storage, he pointed out how features like ScyllaDB’s innovative incremental compaction strategy will allow users to get the most out of those large storage systems. Also, to safeguard your data, ScyllaDB now supports encryption at rest.
What Avi gets most excited about are the plans for new features. For instance User Defined Functions (UDFs) and User Defined Aggregates (UDAs). Also now that ScyllaDB has provided Cassandra and DynamoDB APIs, Avi noted that there’s also work afoot on a Redis API (#5132) that allows for disk-backed persistence.
Avi clarified there are also going to be two implementations for Lightweight Transactions (LWT). First, a Paxos-based implementation for stricter guarantees, and then, in due time, a Raft implementation for higher throughput.
Avi also spoke about the unique nature of ScyllaDB’s Change Data Capture (CDC) implementation. Instead of being a separate interface, it will be a standard CQL-readable table for increased integration with other systems.
He finished with a review of ScyllaDB release roadmaps for 2020.
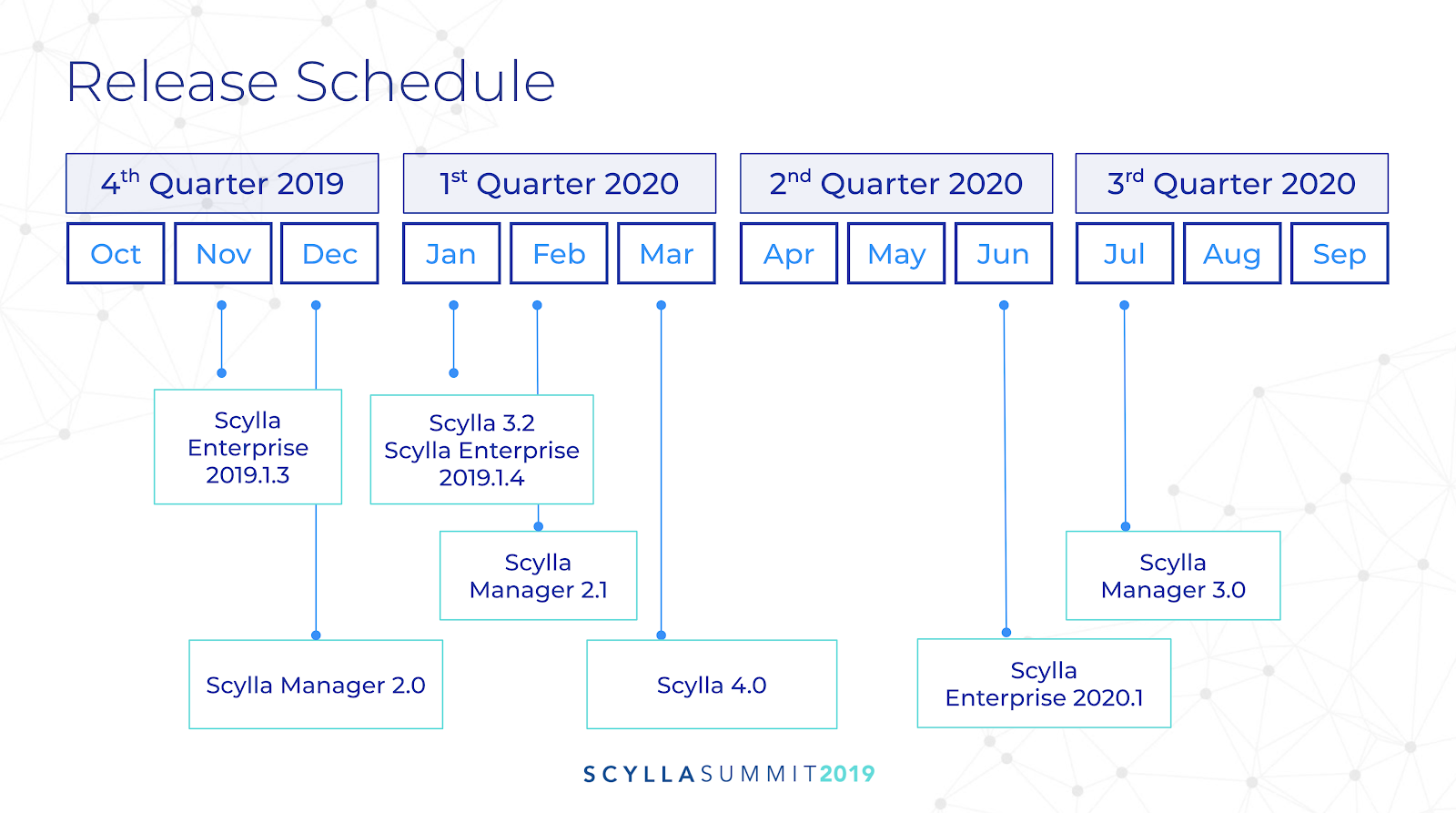
ScyllaDB CTO Avi Kivity showed the Release Schedule for ScyllaDB Enterprise, ScyllaDB Open Source and ScyllaDB Manager for 2020
Philip Zimich, Comcast X1

Next up to speak was Comcast’s Philip Zimich, who presented the scope and scale of use cases behind Comcast’s video and DVR services. When Comcast’s X1 platform team began to consider ScyllaDB they had grown their business to 15 million households and 31 million devices. Their data had grown to 19 terabytes per datacenter spanning 962 nodes of Casssandra. They make 2.4 billion RESTful calls per day, their business logic persisting both recordings and recording instructions. Everything from the DVRs and their recording history to back office data, recording intents, reminders, lookup maps and histories.
Their testing led the Xfinity team to spin up a 200 node cluster, first on Cassandra and then on ScyllaDB, to simulate multiple times the normal peak production load of a single datacenter. Their results were startling. Cassandra is known as a fast-write oriented database. In Comcast’s testing it was able to achieve 22,000 writes per second. Yet ScyllaDB was able to get over 26,500 writes per second — an improvement of 20%. On reads the difference was even more dramatic. Cassandra was able to manage 144,000 reads while ScyllaDB was able to get 553,000 reads — an improvement of over 280%.

Comcast’s testing showed that ScyllaDB could improve their read transactions by 2.8x and lower their long-tail (p999) latencies by over 22x
Difference in latencies were similarly dramatic. Median reads and writes for ScyllaDB were both sub-millisecond. ScyllaDB’s p999s were in the single-digit millisecond range. Under all situations latencies for ScyllaDB were far better than for Cassandra — anywhere between 2x to 22x faster.
| Latencies (in milliseconds) | Cassandra | ScyllaDB | Improvement | |
| Reads | Median | 3.959 | 0.523 | 7.5x |
| p90 | 22.338 | 0.982 | 22.7x | |
| p99 | 84.318 | 3.839 | 22x | |
| p999 | 218.15 | 9.786 | 22.3x | |
| Writes | Median | 1.248 | 0.609 | 2x |
| p90 | 4.094 | 0.913 | 4.5x | |
| p99 | 31.914 | 2.556 | 12.5x | |
| p999 | 117.344 | 7.152 | 16.4x | |
With performance testing complete Comcast moved forward with their migration to ScyllaDB. ScyllaDB’s architectural advantages allowed Comcast to scale their servers vertically, minimizing the number of individual nodes they need to administer.
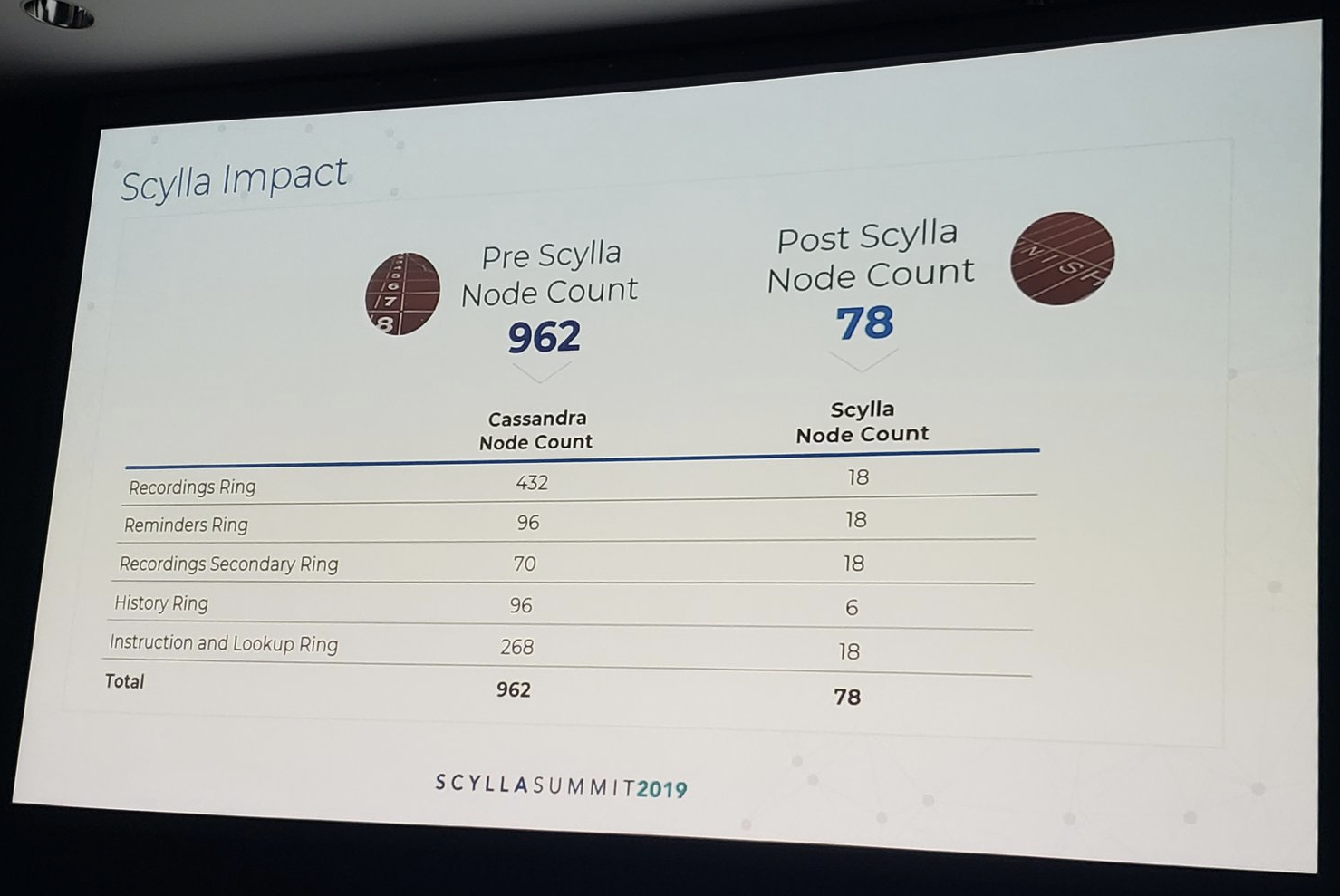
Comcast’s dramatic node count reduction, from 962 nodes of Cassandra to 78 of ScyllaDB
When fully deployed, Comcast will shrink their deployment radically from 962 servers on Cassandra to only 78 nodes on ScyllaDB. This new server topology gives them all the capacity they need to support their user base but without increasing their costs, capping their spending and sustaining their planned growth through 2022.
Martin Strycek, Kiwi.com

Last year when the global travel booking giant Kiwi.com took the stage at ScyllaDB Summit they were still in the middle of their migration and described that stage of their implementation as “taking flight with ScyllaDB.” At this year’s Summit Martin continued the analogy to “reaching cruising altitude” and updated the crowds regarding their progress.
Martin described how they were able to use two specific features of ScyllaDB to make all the difference for their production efficiency.
The first feature that improved Kiwi.com’s performance dramatically was enabling BYPASS CACHE for full table scan queries. With 90 million rows to search against, bypassing the cache allowed them to drop the time to do a full table scan from 520 seconds down to 330 seconds – a 35% improvement.
The second feature was SSTable 3.0 (“mc’) format. Enabling this allowed Kiwi.com to shrink their storage needs from 32 TiB of total data down to 22 TiB on disk — a 31% reduction.
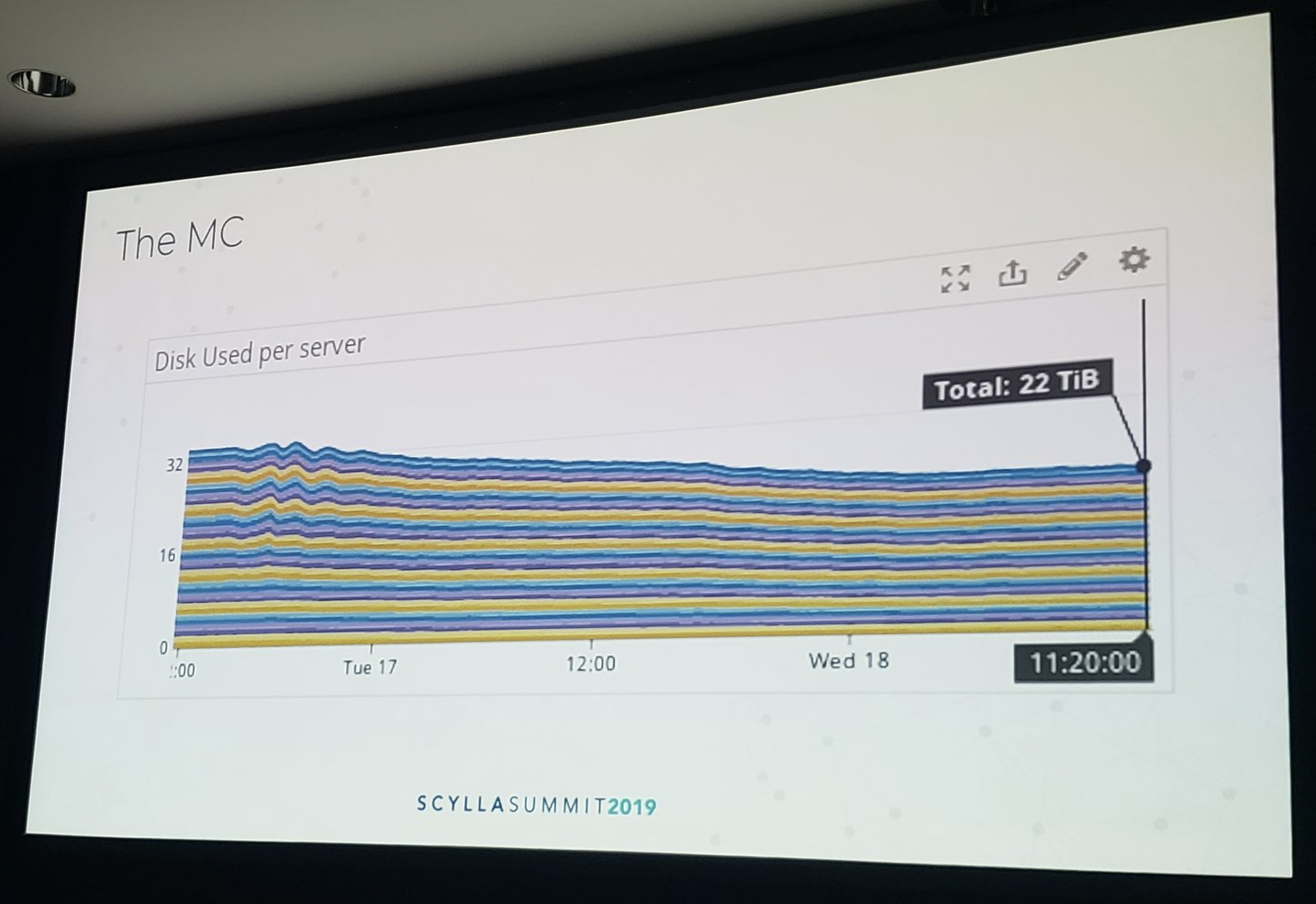
The amount of disk used per server shrank once Kiwi.com enabled SSTable 3.0 (“mc”) format.
Enabling these features was a smooth, error-free operation for the Kiwi.com team. Martin finished his presentation by thanking ScyllaDB, especially Glauber, for making the upgrade experience entirely uneventful: “Thank you for a boring database.”
We take that as high praise!
Glauber Costa

After announcing the winners of the ScyllaDB User Awards for 2019 the keynotes continued with Glauber Costa returning to the stage to share tips and tricks for how to be successful with ScyllaDB.
First off he made distinctions for long-time Cassandra admins of what to remember from their prior experience (data model and consistency issues) and what they’ll need to forget about — such as trying to tune the system the exact same way as before. Because many of the operational aspects of Cassandra may work completely differently or may not even exist in ScyllaDB.
In terms of production hardware, Glauber suggested NVMe if minimizing latency is your main goal. SSD is best if you need high throughput. But forget about using HDDs or any network interface below 1 Gbps if you care about performance. And, generally, never use more, smaller nodes if the result is the same amount of resources. However, in practice it is acceptable to use them to smooth out expansion.
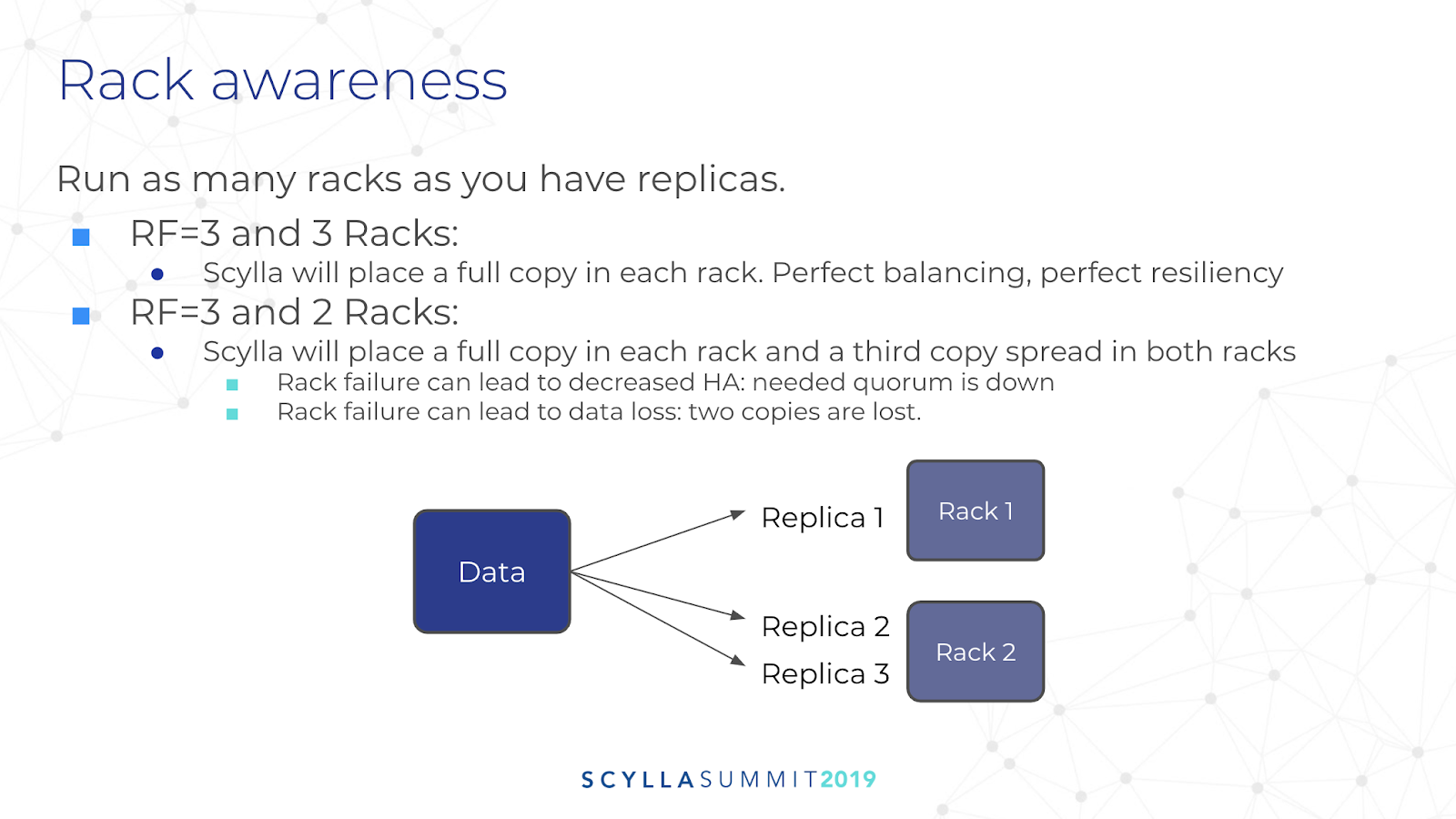
Another key point Glauber touched upon was rack awareness. It is best to “run as many racks as you have replicas.” So if you have a replication factor of three, use three racks for your deployment. This provides perfect balance and perfect resiliency.
These are just two of many topics that Glauber touched upon, and we’ll work to get you the full video of his presentation soon. For now, here are his slides:
Alexys Jacob, Numberly
 Alexys Jacob, Numberly
Alexys Jacob, NumberlyKnown to the developer community as @ultrabug, Alexys is the CTO of Numberly. His presentation was his production experience comparison of MongoDB and ScyllaDB. Numberly uses both of these NoSQL databases in their environment, and Alexys wished to contrast their purpose, utility, and architecture.
For Alexys, it’s not an either-or situation with NoSQL databases. Each is designed for specific data models and use cases. Alexys’ presentation highlighted some of the commonalities between both systems, then drilled down into the differences.
His operations takeaways between the two systems were unsparing but fair. Whereas he hammered MongoDB’s claims about their sharding-based clustering — which, to his view had both poor TCO and operations, he said that replica-sets should be enough, and gave them a moderate TCO rating (“vertical scaling is not a bad thing!”) and good operations rating (“Almost no tuning needed”).
He gave ScyllaDB a good rating for TCO due to its clean and simple topology, maximized hardware utilization and capability to scale horizontally (as well as vertically). For operations, what Alexys wanted was even more automation.
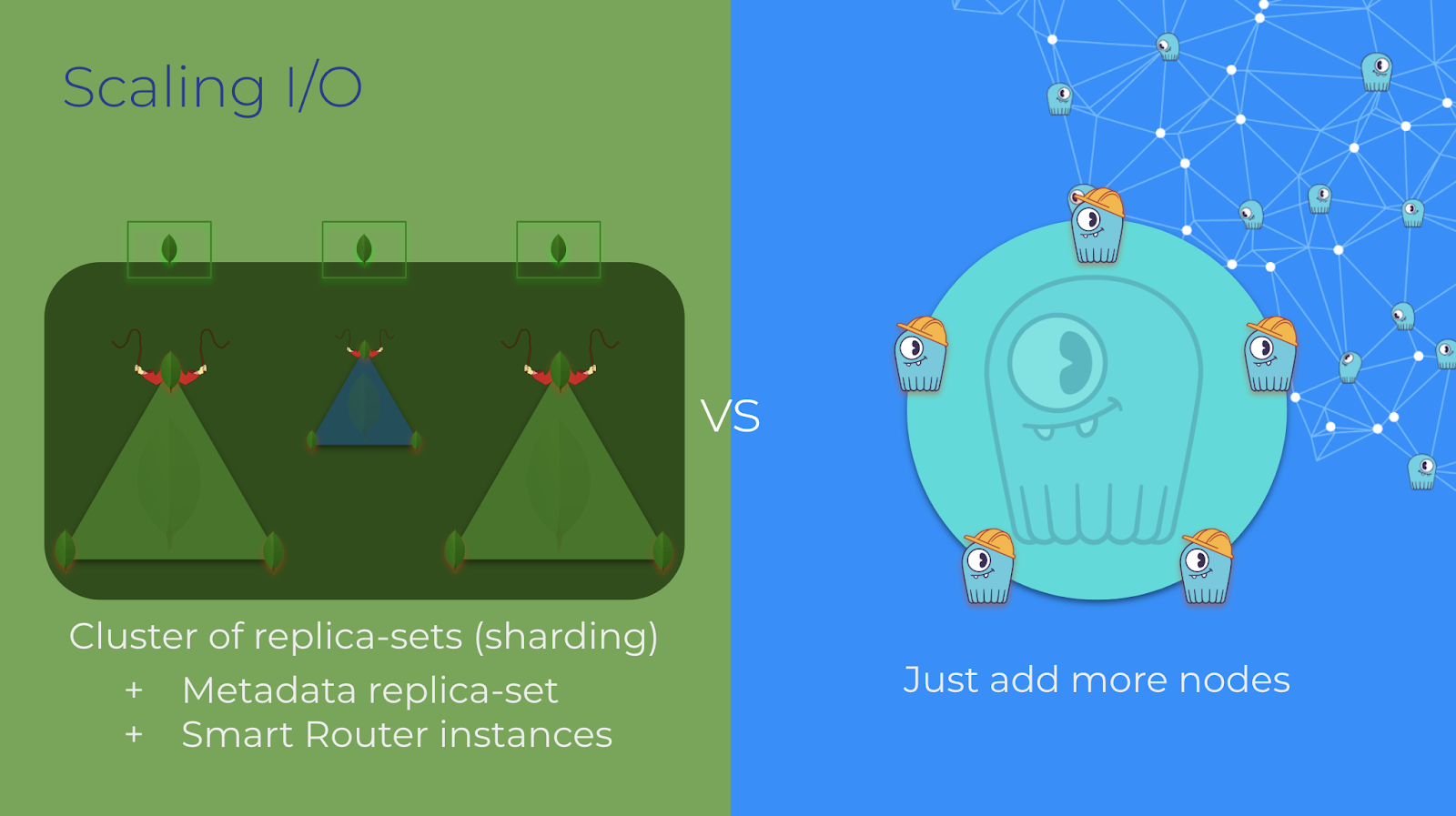
Alexys observed there are complex and mandatory background maintenance operations for ScyllaDB. For example, while compactions are seamless, repairs are still only “semi-seamless.”
From Alexys’ perspective, MongoDB favors flexibility to performance, while ScyllaDB favors consistent performance to versatility.