



Today we feature a guest blog by Rohit Saboo, Machine Learning Engineering Lead at Nauto. Rohit has spoken at multiple ScyllaDB Summits, and in 2018 his work at Nauto was awarded the ScyllaDB User Award for More Interesting Technical Use Case.
How we build trips consistently in a distributed system
Early on, I noticed that one of our services would often have errors in retrieving data from the database. Upon investigation, we discovered that some of the queries were being run with full consistency, which in this case was the equivalent of enforcing that if any single node in a three node database cluster is not reachable the query should fail. The CAP theorem in distributed systems states that you cannot have it all — a system that is fully consistent will not be available in the event of a network partition and if we want it to be available, we cannot do so with assured full consistency.
For most applications that do not involve a bank account, having less than full consistency is often more than enough. Still, the engineer who wrote the code and had previously only worked with fully consistent, SQL systems exclaimed, “How can we run a production system without full consistency!”
This leads one to question if the limits imposed by the CAP theorem are truly absolute or is it possible to get around them for specific applications?
The Problem
One of Nauto’s technologies is a “trip builder” that processes and analyzes large volumes of data in the cloud to enable a number of product features. The trip builder needs to have low latency, high availability, and good reliability. It also needs to be cost-effective and scalable with low operational overhead.
It needs to process data by batching it up into chunks, which even for a small scale would amount to over 2,000 write operations/second with each operation using the trip route and associated data for that time segment.
Additionally, due to various reasons in how distributed systems operate, a large percentage of the data does not arrive in-order and sometimes sending the latest information first when recovering from errors is required. As a result, a solution that simply appends data at the end does not work for us.
| Data Arriving at | Percentage. |
| end of trip
in-between a trip beginning of trip between two trips causing them to merge |
46% 34% 19% 1% |
Achieving a few of these goals is perhaps easy; achieving all of them together is not.
Solution
We built a distributed time-series merging solution modeled on a new ACID paradigm that provides strong application-level guarantees without being limited by the CAP hypothesis using ScyllaDB as the backing store.
While designing the solution, one of the decisions we needed to make was which database would store all the data. We explored various technologies based on publicly available benchmarks, and concluded that traditional SQL solutions such as Postgres would not scale (let alone achieve other goals). We considered sharded Postgres, but the management/operational overhead brought on by such a system would not scale well. Other solutions we considered could not meet one or more of our requirements for reliability, cost, or throughput. We decided to go with a Cassandra-like solution and settled on ScyllaDB for reasons of reliability, cost, latency, and maintainability.
When we consider NoSQL solutions, we also have to decide how we trade off between consistency and availability. Do we really need to be consistent? What does consistency really mean for our data? We will explore later how in our particular problem, we can provide strong theoretical guarantees that the solution is perfectly safe under eventual consistency.
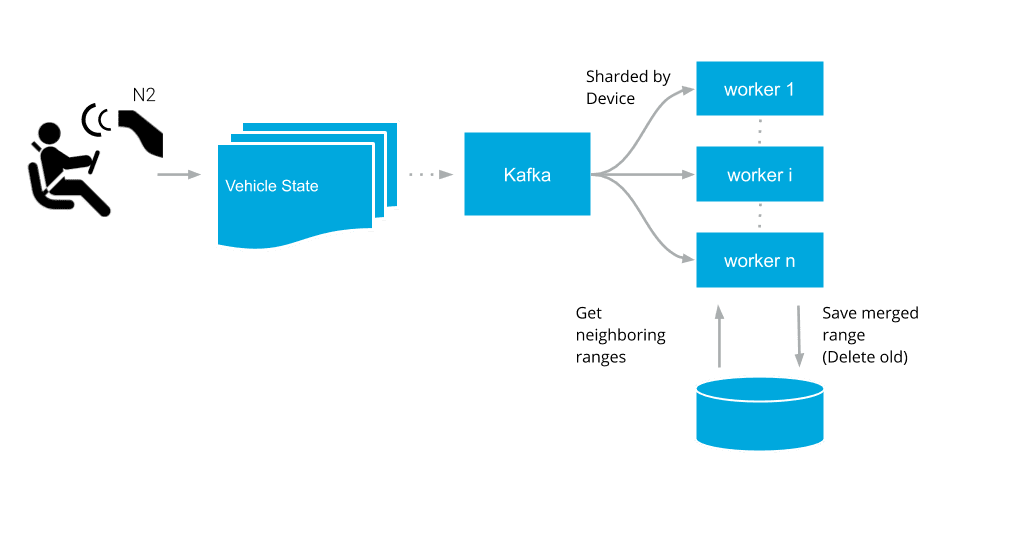
The GPS points along with the vehicle state are ingested by an edge service, which forward the data to Kafka. The Kafka partitions are sharded by the device id. Multiple instances of the trip building service consume the data from these partitions. Each of these instances internally subdivides the work across several workers. The work is distributed using a different hash function and a slightly different sharding scheme which relies on both the device id and the day bucket. (Using the same sharding scheme and a number of workers that is not coprime with the number of Kafka partitions would have resulted in some workers not receiving any data.) This setup ensures that all data relevant to a particular time range (except for the edge case of cross day trips) are delivered to the same worker, i.e., two different workers never process data meant for the same trip (time range) barring rare conditions such as network partitions causing worker disconnects followed by Kafka rebalances and lagging workers. (Network partitions do tend to happen because it’s relatively easy to saturate the network bandwidth when working at high throughputs on one of the smaller AWS instances.)
This algorithm reads and writes from the trips table, whose schema is:
CREATE TABLE trips (
version int,
id text,
bucket timestamp,
end_ms timestamp,
start_ms timestamp,
details blob,
summary blob,
PRIMARY KEY ((version, id, bucket), end_ms, start_ms))
WITH CLUSTERING ORDER BY (end_ms DESC, start_ms DESC)Where
versionallows us to run multiple versions or experiments at the same time while maintaining data separation.idis the device id (or id for the timeseries).bucketis the day bucket.start_ms,end_msare the trip start and end times respectively.detailscontains the detailed information related to the trip, e.g., the location coordinates for the route. We save this as a compressed, serialized protocol buffer as opposed to json because it both saves space and stops the individual cell sizes from becoming too large. This could have been saved as compressed, serialized flatbuffers, too, if one were very sensitive to client-side deserialization costs.summarycontains summarized information from the trip such as total distance traveled. The summary fields avoid the need to load details each time we retrieve a trip but don’t really need the path. Again we use compressed, serialized protocol buffers to save this.
The partition key is chosen to include the version, id, and the day bucket because we don’t need to access data across two different partitions at the same time for this algorithm. The clustering key is chosen to make the common case of in-order arrival of data as optimal as possible.
The table has a replication factor of 3. All writes to the table are written with consistency level Quorum so that we are sure that at least two replicas have the data. Now if we want to guarantee that we are reading the latest data that was written, given that we have a three node cluster, one could do all reads with consistency level quorum. However, that is not important for us, and therefore we read with a consistency level of one.
The Merging Step
Let’s follow the algorithm through an example. Each sequence of timestamped location coordinates forms a trip segment. For illustrative purposes, we will use batch sizes much larger than normal. Let’s say the device has sent the following trip segment so far.

After a while, we receive some additional data for this trip, but there’s a large break in between because data was sent out of order due to some connectivity issue. We consider two trip segments to be part of the same trip only if they are within five minutes of each other.
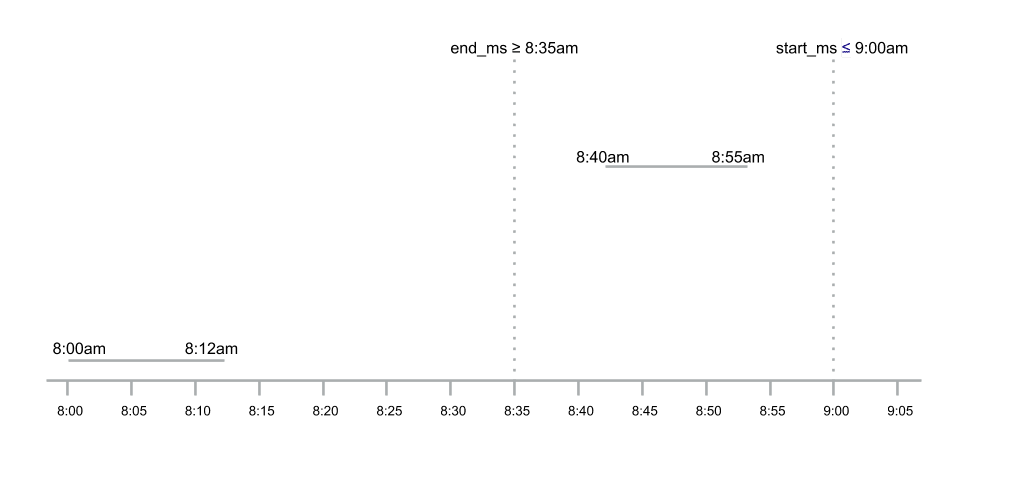
We query the table to see if there is a trip segment that ended within five minutes of this trip segment starting or that starts within five minutes of this trip segment ending. This constraint can be simplified by the following observation: If there’s only a single thread operating on trip segments for a device at a time, we should have at most one trip segment before and one trip segment after within range of being merged. This is because if we have more than these, they would have been merged in some previous step. However, given that we are working with eventual consistency, we may end up with more than two trips for merging with potential overlap. We will address this consistency issue later. For now, we can use this observation to simplify by only looking for the first three trips (one more than strictly necessary so that at each operation, we allow for one additional trip not previously merged to get merged) that end after five minutes before the current trip segment start time.
In the example, there’s nothing to merge the new trip segment with. Therefore, we save it as it is. Next, we get a new trip segment for which both of the previously received trip segments fall within its 5 minute neighborhood.
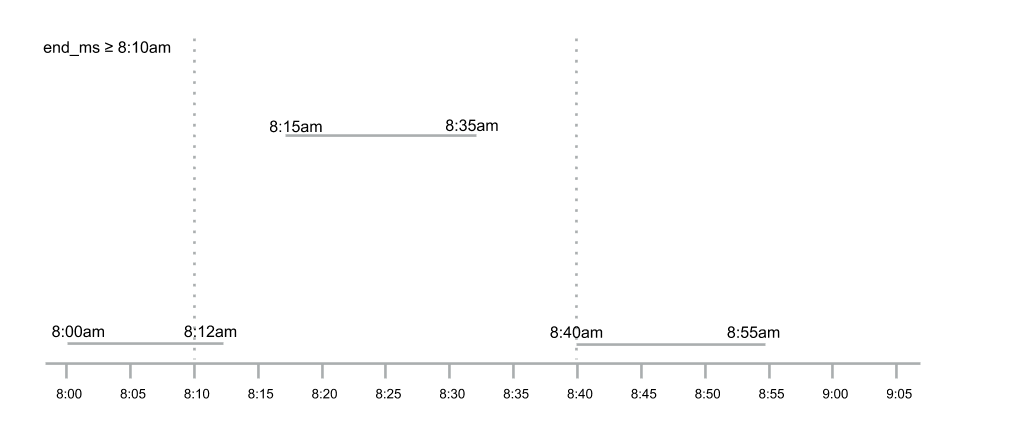
Therefore, we create a new combined trip, save it back, and delete the former ones. We first save the combined trip and then delete the older ones so that if anything failed in between, all we have is a couple of trips that overlap with some larger trip but were not deleted and will get deleted sometime later. You could also ask why not use logged batches here? Logged batches are expensive and this operation happens a lot. Therefore we choose not to use logged batches.

We could define the merging function as taking two trip segments and producing a merged trip segment m.
f(a,b) → m
This function is
- Associative:
If there are three trips to merge, say a, b, and c, both
f(f(a,b), c) and f(a, f(b, c))
will yield the same result: it doesn’t matter which of those two trips we merge first. - Commutative:
f(a, b) = f(b, a).
It doesn’t matter in which order we give the trips, the merged trip is always the same. - Idempotent:
f(a, f(a, b)) = f(a, b)
The merged path always de-duplicates and orders the time series data before saving it. - Deterministic:
f(a, b) is always the same.
There’s no non-determinism in the merging process and the output is always the same.
Such a function is also sometimes referred to as having ACID 2.0 properties. For such a function, starting with any set of inputs, we will always arrive at the same output irrespective of the path of operations chosen. A program implementing this function is also referred to as monotonic. One could reason that the monotonicity falls out because in order to arrive at the output we don’t have to run any coordination between the distributed execution of this function so that a particular execution order is guaranteed.
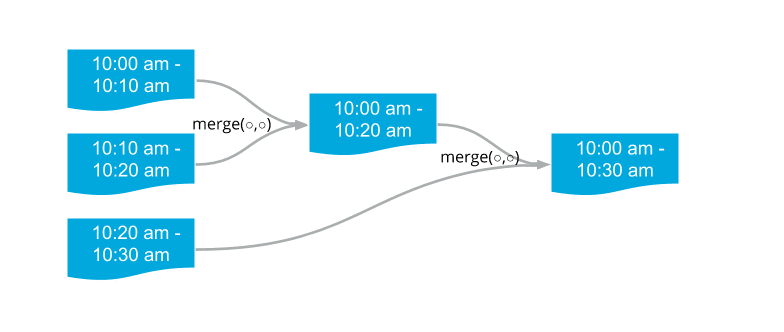
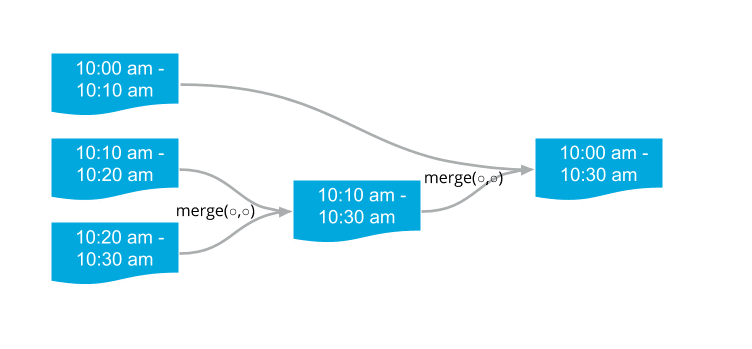
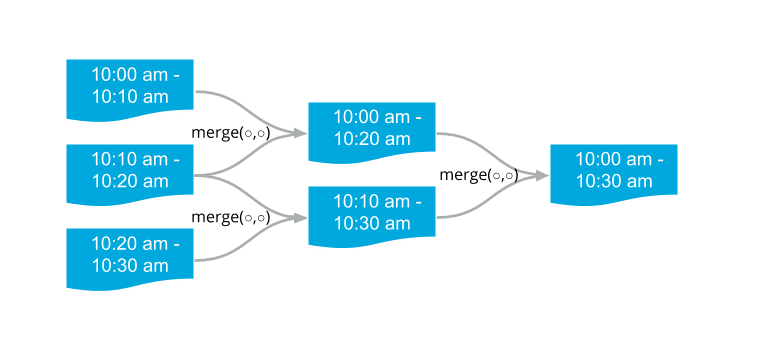
Let’s take an example with two instances and three trips. Let’s call these trips T0 (10:00 am — 10:10 am), T1 (10:10 am — 10:20 am), and T2 (10:20 am — 10:30 am), and the workers as W0 and W1.
Running this coordination-free, let’s look at some of the ordering of operations
Case 1:
- W0 loads T0 and T1.
- W0 writes merged trip of T0 and T1 (T01).
- W0 deletes T0 and T1.
- W1 loads T01 and T2
- W1 writes merged trip of T01 and T2 (T012).
- W1 deletes T01 and T2.
Case 2:
- W0 loads T1 and T2.
- W0 writes merged trip of T1 and T2 (T12).
- W0 deletes T1 and T2.
- W1 loads T0 and T12.
- W2 writes merged trip of T0 and T12 (T012).
- W2 deletes T0 and T12.
Case 3: There’s a “race” between W0 and W1.
- W0 loads T0 and T1.
- W1 loads T1 and T2.
- W0 writes merged trip of T0 and T1 (T01).
- W1 writes merged trip of T1 and T2 (T12).
- W0 deletes trips T0 and T1.
- W1 deletes trips T1 and T2. The delete operation for T1 may fail at this point, but that’s okay.
- W0 now loads T01 and T12.
- W0 writes merged trip T012. (Our merge operation is defined such that we de-duplicate the data inside.
The article “Relational Transducers for Declarative Networking” by Ameloot, Neven, et al. [pdf] substantiates this method.
If we apply this function at all reads and writes to this table, including reads where we are surfacing this data in various frontends, we are guaranteed to have consistent data, where data consistency includes correctness, no duplicates, and being in-order, but does not include having the latest data.
ScyllaDB deployment
Our ScyllaDB cluster is comprised of three i3.4xlarge EC2 instances spread across three availability zones where the availability zones are the same as the ones in which the cloud services run. AWS inter-availability zone network bandwidth as well as bandwidth on smaller instances often tends to be lower. Additionally, the high update rate created a large internode traffic in order for ScyllaDB to manage the replication, resulting in us running into network bandwidth limits. (This also happened to be quite expensive and was several multiples of the cost of everything else.) At the time of writing this article, ScyllaDB does not enable internode compression by default, and we enabled it to stop us from running into bandwidth limits and reduce network costs. The cluster has its own VPC with limited ports exposed to only the relevant VPCs that run services needing access to ScyllaDB.
For each region, we run a completely isolated cluster to ensure that data related to customers in that region stays within the physical boundary of the particular region. In order to simplify management and operation of these isolated ScyllaDB clusters, we use cloudformation with a custom AMI based on ScyllaDB’s public AMI that can bring up the entire cluster with a single cloudformation command allowing us to have an identical setup across various environments. This cloudformation template also includes ScyllaDB manager and the Grafana/Prometheus ScyllaDB monitoring stack running on a different instance. Backups are done using the cassandras3 tool. The tool is configured to run via a cron schedule on each machine at midnight local time.
Overall, we have been able to find a low management overhead, low latency, cost-effective solution by using ScyllaDB for our DB layer for our algorithms.
Conclusion
In conclusion, we see how formulating our problem as a monotonic function has helped us build a coordination-free algorithm on top of ScyllaDB that achieves all of our goals — high availability, good reliability, cost-effective, and scalable with low operational overhead.
About Nauto
NautoⓇ is the only real-time AI-powered, Driver Behavior Learning Platform to help predict, prevent, and reduce high-risk events in the mobility ecosystem. By analyzing billions of data points from over 400 million AI-processed video miles, Nauto’s machine learning algorithms continuously improve and help to impact driver behavior before events happen, not after. Nauto has enabled the largest commercial fleets in the world to avoid more than 25,000 collisions, resulting in nearly $100 million in savings. Nauto is located in North America, Japan, and Europe. Learn more at nauto.com or on LinkedIn, Facebook, Twitter and YouTube.
If you’ve found this blog illuminating, please go to the original posted on Medium and give Rohit fifty claps. Meanwhile, if you have more questions about ScyllaDB itself, you can contact us through our website, or drop in and join the conversation on Slack.





