



Data Model FAQs
What is a Data Model?
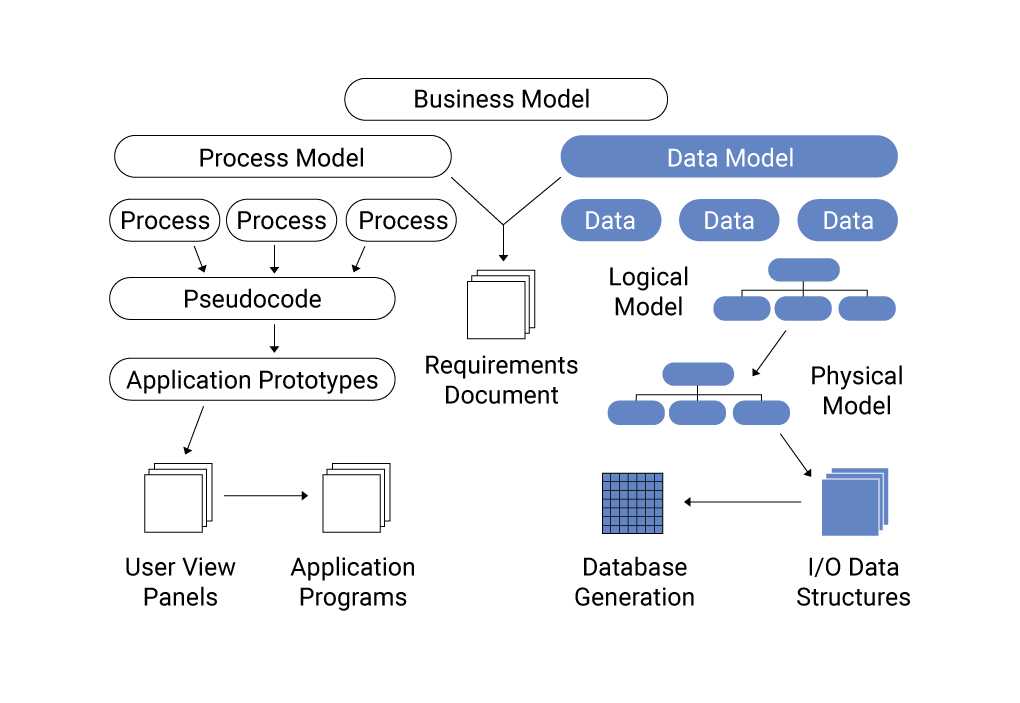
A data model determines the structure of data elements within an information system. A data model documents the relationships between data elements and how data is retrieved and stored. Data models often display the flow of data through a graph or data model diagram. This visual representation helps facilitate communication between software and business teams: business teams can identify the data and data formats needed for business functions, and software teams can build the responses needed for those requests.
To answer the question “what is a data model,” it’s helpful to understand a few key terms used in the data model definition.
A data model identifies:
- Entities: the data components, including associated metadata, raw data and processed data
- Associations: the relationships between data components
- Requirements: the anticipated uses of the data, especially future uses
- Technology assessment: the strengths and weaknesses of the hardware and software used in the project
Types of Data Models
Conceptual Data Model
A conceptual data model identifies the entities that describe the data and relationships between them. Conceptual data models only show the highest-level relationships between entities, not attributes or primary keys within the data model.
Physical Data Model
A physical data model identifies the table structures that will be built in the database, including all tables, columns, primary keys and foreign keys used to identify the relationships between tables.
Relational Data Model
A relational data model is the basis for SQL databases. Relational data models have a fixed schema and deal with structured data. In a relational database management system, or RDBMS, the database is the outermost container that has data associated with an application.
Non-relational Data Model
A non-relational data model offers a flexible schema design and can handle unstructured data—its storage model can be optimized to meet the requirements of the type of data being stored. Non-relational data models are used in non-relational databases, also called NoSQL databases.
Dimensional Data Model
A dimensional data model is used in data warehouse design. Dimensional data models analyze numeric information (such as balances or values) in a data warehouse. By contrast, relational data models update, add or delete data in real-time information systems.
Enterprise Data Model
An enterprise data model incorporates an industry perspective to give an unbiased view of how data is stored, sourced and used across an organization. Enterprise data models are useful for addressing the specific business needs of an enterprise.

Data Modelling Techniques
While data modelling techniques will vary depending on the type of database your organization uses, there are a few data modeling best practices to keep in mind in the data modelling process:
- Start with the data modelling basics: ask business teams what results they need from the data, and organize the data model around those requirements
- Build a draft data model with entities and relations, and test the model with best-case and worst-case scenarios
- Take database queries into account: you should know what your data looks like and what it contains, but also how you intend to query it
- Assess hardware requirements since servers working with huge datasets can soon run into problems of computer memory and input-output speed.
- Validate the data model: verify each action (such as your choice of primary key) before moving on to the next step
What are Some Data Modeling Tools?
There are a number of data modeling tools available. Popular data modeling software includes:
- Toad Data Modeler
- MySQL Workbench
- MagicDraw
- ERwin
- Enterprise Architect
- ER/Studio
- PowerDesigner
- Oracle SQL Developer
- IBM InfoSphere Data Architect
Data Modeling for Big Data
IT organizations that need to manage huge numbers of users and data often rely on NoSQL databases. NoSQL databases are non-relational, distributed databases designed for high availability and big data workloads. NoSQL databases are the ideal database for data modelling for big data because they allow big data applications to archive massive volumes of any types of data, to easily scale horizontally to handle influxes of new users (such as a social media app) and to evaluate and respond to data instantly (such as in advertising).
NoSQL Data Modeling
Because NoSQL databases support flexible schemas, data models can be modified after loading data into the database. Any type of unstructured data can be loaded to a NoSQL repository without a pre-defined schema and modeled later. In comparison, data modelling occurs at the ingest phase in a relational database. Flexible schemas enable NoSQL databases to support huge volumes of data and adapt to changing business requirements in real-time. As developers require new features form the database, they can add them without interacting with centralized administrators or operators, and without requiring wholesale reorganization of the dataset.
Masterclass: Data Modeling for NoSQL Databases
 Looking for extensive training on about data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
Looking for extensive training on about data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
You can access the complete course here.
Does ScyllaDB Offer Solutions for Big Data Modeling?
ScyllaDB offers an open source NoSQL database. ScyllaDB is the monstrously fast and scalable NoSQL database, a drop-in replacement for Apache Cassandra that powers higher performance and lower latency at a fraction of the cost of most NoSQL databases. ScyllaDB’s new approach to NoSQL data store design is optimized for modern hardware. ScyllaDB runs multiple engines, one per core, each with its own memory, CPU and multi-queue NIC. ScyllaDB uses a shared-nothing model called Seastar: an advanced, open-source C++ framework for high-performance server applications.