
Nowadays it is no longer enough to just store data and process it once or twice a day with a batch job. More and more use cases require an almost immediate reaction to modifications occurring in the database. In a fast-moving world, the amount of new information is so big that it has to be processed on the spot. Otherwise, the backlog will grow to an unmaintainable size. We, at ScyllaDB, are aware of these challenges and would like to make it easier for ScyllaDB users to build a streaming data pipelines that allow real-time data processing and analysis. This is why we have been working hard to bring a new feature, called Change Data Capture, to you.
What is Change Data Capture?
Change Data Capture (CDC) enables users to log all the mutations of data in a selected table(s). It does not capture changes on every table in the database but can be enabled on specific tables that a user is interested in observing. For the sake of simplicity, let’s assume for this blogpost that CDC was enabled on a single table. Let’s call this table a Base Table. On a very high level, CDC maintains a log of all changes applied to the Base Table. We call it CDC Log. It is a regular ScyllaDB table created in the same keyspace as the Base Table and it can be accessed using regular CQL interface. Tools like cqlsh or driver libraries will be perfectly good means of accessing CDC Log. This means a user can not only check the log manually but also write a script or an application that can continuously monitor the changes. The content of the CDC Log is configurable in ScyllaDB. The following information can be included:
- The key of the record being changed
- The actual modification
- The state of the record before the change (we call it preimage)
- The state of the record after the change (we call it postimage)
In ScyllaDB Open Source 3.3, only the first three are supported. Postimage has been added into the ScyllaDB Open Source 4.0 major branch. It is best to look at an example to get a better understanding of those concepts. Table used for the example will have the following schema:
CREATE TABLE company.employees (
department text,
last_name text,
first_name text,
age int,
level int,
PRIMARY KEY (department, last_name, first_name)
)Let’s assume that the table already has the following row:
| department | last_name | first_name | age | level |
| Production | Smith | John | 35 | 2 |
If we perform the following operation:
UPDATE employees SET level = 3 WHERE department = 'Production' AND last_name = 'Smith' AND first_name = 'John';then the key of the change is composed of primary key columns (department, last_name, first_name) and in this example is equal to (‘Production’, ‘Smith’, ‘John’). Actual modification is primary key with the actual change. In this example only the level column was changed so the value of the modification is (‘Production’, ‘Smith’, ‘John’, null, 3). Preimage is the state of the changed data so in this case it is equal to (‘Production’, ‘Smith’, ‘John’, null, 2). One thing worth noting here is that column age is null in the preimage because the column was not involved in the operation. Even though it had a value of 35 before the modification. Finally, postimage for this operation is (‘Production’, ‘Smith’, ‘John’, 35, 3). Postimage, in opposition to preimage, always contains all the columns in the row no matter whether they were changed by the operation or not.
To achieve high performance, CDC Log is partitioned into a number of CDC streams. Each CDC stream is identified by a unique stream id and stores all the entries that describe modifications to data stored on a single shard on the ScyllaDB node. The feature is designed this way to minimize the impact of CDC on Base Table write performance. As a result, CDC Log data is co-located with the Base Table data it describes. Co-location is not only in terms of nodes in the cluster but also within shards on the node.
Entries in CDC Log are sorted by the time the change they describe appeared. Because the log is partitioned, the order is maintained only within a stream. It is guaranteed though that all the changes applied to a single row will be in the same stream and will be sorted by the time they occurred.
CDC Log does not store its entries indefinitely. Records are removed using the standard TTL mechanism. By default, rows are removed after 24 hours but it can be configured to a different value. It is important to set this value to something big enough to allow a CDC client to consume all the changes before they disappear from the CDC Log table.
CDC Log format
For the example table mentioned above, CDC Log would have the following structure:
CREATE TABLE company.employees_scylla_cdc_log (
cdc$stream_id blob, cdc$time timeuuid, cdc$batch_seq_no int,
cdc$operation tinyint, cdc$ttl bigint,
department text,
first_name text,
last_name text,
age int, cdc$deleted_age boolean,
level int, cdc$deleted_level boolean,
PRIMARY KEY (cdc$stream_id, cdc$time, cdc$batch_seq_no)
)It will be automatically created in the same keyspace as the Base Table and its name will be the name of the Bast Table with a ‘_scylla_cdc_log’ suffix. It contains 3 groups of columns. The first group is a copy of all the columns from the Base Table:
CREATE TABLE company.employees_scylla_cdc_log (
cdc$stream_id blob, cdc$time timeuuid, cdc$batch_seq_no int,
cdc$operation tinyint, cdc$ttl bigint,
department text,
first_name text,
last_name text,
age int, cdc$deleted_age boolean,
level int, cdc$deleted_level boolean,
PRIMARY KEY (cdc$stream_id, cdc$time, cdc$batch_seq_no)
)Their names and types are exactly the same as in the employees table. For each of these columns that are not part of the primary key, CDC Log contains a boolean column that is used to indicate whether a given column has been deleted in a given operation. Names of those columns follow the pattern cdc$deleted_. Those columns form the next group:
CREATE TABLE company.employees_scylla_cdc_log (
cdc$stream_id blob, cdc$time timeuuid, cdc$batch_seq_no int,
cdc$operation tinyint, cdc$ttl bigint,
department text,
first_name text,
last_name text,
age int, cdc$deleted_age boolean,
level int, cdc$deleted_level boolean,
PRIMARY KEY (cdc$stream_id, cdc$time, cdc$batch_seq_no)
)Finally, there is the last group of columns that are not related to the columns in the Base Table. Three of them form the primary key of the column. cdc$stream_id is a specially selected partition key that leads to a co-location between a row in the Base Table and corresponding CDC Log records. Both in terms of servers in the cluster and shards on the node. Next there are two columns that compose a clustering key: cdc$time and cdc$batch_seq_no. cdc$time is the time of the change. It is represented as TimeUUID to avoid clashes of two operations that happened at the same time. cdc$batch_seq_no is a column that allows each operation to create multiple records in CDC Log. All records created for a single operation share cdc$stream_id and cdc$time but differ in cdc$batch_seq_no value. Another important column is called cdc$operation. It reflects the type of the operation that caused the addition of a given CDC Log record. At the moment there are following operation types:
| 0 | PREIMAGE |
| 1 | UPDATE |
| 2 | INSERT |
| 3 | ROW DELETE |
| 4 | PARTITION DELETE |
| 5 | RANGE DELETE INCLUSIVE LOWER BOUND |
| 6 | RANGE DELETE EXCLUSIVE LOWER BOUND |
| 7 | RANGE DELETE INCLUSIVE UPPER BOUND |
| 8 | RANGE DELETE EXCLUSIVE UPPER BOUND |
| 9 | POSTIMAGE |
PREIMAGE and POSTIMAGE are used to store records for those two special types of information. UPDATE, INSERT, ROW DELETE and PARTITION DELETE are self explanatory but options 5-8 might not be that clear. Those can be created with a range deletion like this:
DELETE FROM employees WHERE department = 'Production'
AND last_name >= 'A' AND last_name < 'C';The last column that has not been described yet is cdc$ttl. It is used to capture the TTL used with the operation recorded in CDC Log.
When can Change Data Capture be useful?
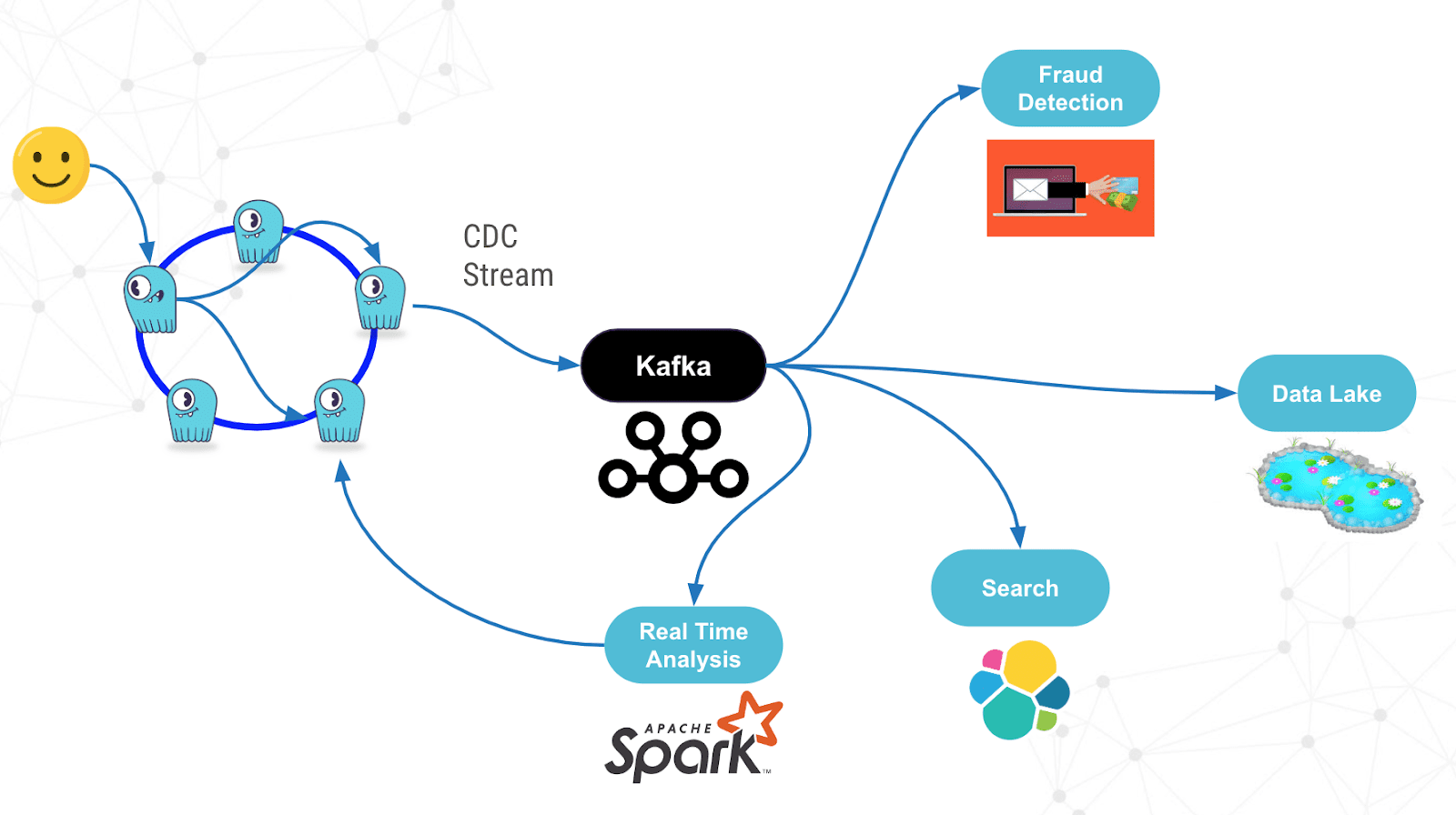
Change Data Capture can be used in multiple use cases. Most of them can be grouped into two categories: integration with other systems and real-time processing of data. Real-time processing can be done for example with Kafka Streams or Spark and is useful for triggers and monitoring. For example, it might be desirable to send an sms to a user if a login attempt is performed from a country the user does not live in. Change Data Capture is also useful to replicate data stored in ScyllaDB to other systems that create indexes or aggregations for it.
How are we different than Cassandra?
We took a completely different approach to Change Data Capture than the one used in Apache Cassandra. Cassandra’s implementation is very simple and pushes a lot of the work to the CDC client. Cassandra copies segments of commit log into a separate directory and that’s pretty much all that’s done. To consume Cassandra’s CDC, a user has to start a special agent on every machine in the cluster. Such an agent has to parse commitlog-like segments stored in the special directory and after it’s finished with processing the data, it has to clean up the directory. This approach, although simple to implement, causes multiple problems to the user. First, data is usually replicated to multiple nodes in the cluster and the user agent working on a single node knows nothing about the other replicas. This leaves the problem of conflict resolution and data reconciliation unsolved and pushed onto a user. Another problem is that if the agent does not process the data fast enough, the node can run out of disk space.
At ScyllaDB, we think that for Change Data Capture to be useful it has to solve those problems and provide users with a familiar access method that takes care of all the peculiarity related to the internal workings of the database. Thus, our CDC Log is a regular table accessible with CQL protocol and all standard tools. It means our implementation is more complex and has to deal with all the problems caused by the fact that ScyllaDB is a distributed system but we feel that it wouldn’t be ok to push our problems to users.
Performance
We have only very preliminary results of Change Data Capture performance testing. Initial results are very promising though. We compared ScyllaDB write performance in three variants: with CDC disabled, with CDC capturing key and actual modification, and with CDC capturing key, actual modification and preimage. The results for i3.4xlarge machines are shown in the table below:
| No CDC | Keys + modification | Keys + modification + preimage | |
| Throughput (ops) | 196,713 | 122,243 (-37%) | 63,463 (-67%) |
| Mean latency (ms) | 4.2 | 6.6 (+57%) | 12.6 (+199%) |
| 99th percentile latency (ms) | 8.4 | 12.4 (+47%) | 23.6 (+180%) |
It is apparent that CDC has a cost to it. With CDC you are essentially doubling the writes, and with a preimage, you must first read a record (to know what it had been set at), then modify it, and then write the results (original as well as new values) to the CDC table. You should take these throughput and latency effects into account when capacity planning.
Early preview in ScyllaDB — Give it a try!
The early preview of the CDC was first released with ScyllaDB Open Source 3.2, and improved for ScyllaDB Open Source 3.3. We encourage you to play with the new feature and let us know what you think about it. Any questions and feedback are very much appreciated. The best way to reach us is ScyllaDB mailing list (https://groups.google.com/forum/#!forum/scylladb-users on the web, or via email at scylladb-dev@googlegroups.com) or through our ScyllaDB Users Slack (https://scylladb-users.slack.com).
Important Note: Change Data Capture in ScyllaDB Open Source 3.x and 4.x is still an experimental feature. It is under heavy development and some of its details, including user-facing API, may change before CDC is complete. It may be required to disable CDC on all tables before upgrading to the newer version of ScyllaDB. We believe that the version included in ScyllaDB Open Source 4.0 release should be very close to the final shape of the solution. With the release of ScyllaDB Open Source 4.0, the CDC user API present in ScyllaDB 3.2 and ScyllaDB 3.3 is deprecated. Further, with the release of ScyllaDB Open Source 4.0, and ScyllaDB’s policy of only maintaining the two most current releases, ScyllaDB 3.2 will no longer be supported. We plan for CDC to be GA in ScyllaDB Open Source 4.1.
Want to learn more about Change Data Capture in ScyllaDB? Hear more from our team talking about the feature in our on-demand webinar.