




ScyllaDB is a highly scalable, highly performant NoSQL database. But just how fast can fast get? And what happens when you run it on a bare metal cloud like Packet? We set out to design a test that would showcase the combined abilities of ScyllaDB as a database and Packet’s fastest instances. We’ll spill the beans early: we were able to scan more than 1,000,000,000 rows per second (that’s a billion, with a “b”). Now, if we were only doing a million rows per second per server, that’d need a cluster of 1,000 servers.
We did it with 83 nodes.
That means we were reading over 12 million rows per second per server.
Millies, Billies and Trillies, a Brief History of Benchmarking Scale
Before we get too far into the story of how we hit those numbers, let’s step back a little in history to see other milestones in NoSQL scalability. Not all of these tests are measuring the same thing, of course, but it is vital to see how we’ve measured progress in the Big Data industry. Each of these achievements is like summiting a tall mountain. Once one company or one open source project reached the milestone, it sent others scurrying to summit the peak themselves. And, no sooner was one summit reached than higher performance targets were set for the next generation of tests.
It was only eight years ago, in November 2011, when Netflix shared their achievement on hitting over one million writes per second on Cassandra. They did it with 288 servers (a mix of 4 and 8 CPU machines) grouped in 3 availability zones of 96 instances each. Each server could sustain only about 11,000 – 12,000 writes per second.
Fast forward less than three years, to May 2014, and Aerospike was able to achieve one million transactions per second on a single $5,000 commodity server. There was a key revolution going on in server hardware at the time that enabled this revolutionary advance: solid state drives (SSDs). Aerospike was optimized for Flash storage (SSDs), whereas the Netflix test used hard disk drives (HDD) in the m1.xlarge.
ScyllaDB released the very next year, in 2015. With the Seastar engine at its heart, and being a complete re-write of Cassandra in C++, ScyllaDB proved you could make a Cassandra-compatible database also hit a million transactions on a single server. Wait. Did we say only a million TPS? The very next month, with a bit more optimization, we hit 1.8 million TPS.
Across in the industry more “milly” scale tests pushed new limits. Redis first announced hitting 1.2 million ops on a single instance in November 2014. What’s more, it boasted its latencies were sub-millisecond (<1 msec). It later announced hitting 10 million ops at <1 ms latency with only 6 nodes at the very end of 2017. They’ve since scaled to 50 million ops on 26 nodes (September 2018) and recently 200 million ops on 40 instances (Jun 2019); this last test averaging about 5 million operations per second per server. The key to Redis’ performance numbers is that it operates in-memory (from RAM) for the most part, saving a trip to persistent storage.
As nodes become denser the capability to hit 1 million ops has no longer become an achievement; it’s now more of a database vendor’s basic ante into the performance game. So beyond a “milly,” we can look at the next three orders of magnitude up to the ‘billies;” operations on the order of billions of seconds.
Speaking about in-memory scalability, about a half a year before the Netflix blog, in April 2011, the in-memory OLAP system Apache Druid arrived on the scene in a big way. In a 40-node cluster, they were able to aggregate 1 billion rows in 950 milliseconds — a “billy.” But that pales in comparison to MemSQL [now SingleStore] claiming reading a trillion rows per second in-memory in 2018 — a “trilly.”
Which gets into the next dimension of these tests of scalability. What are you specifically measuring? Are you talking about transactions or operations per second? Are they reads or writes? Or are you talking about aggregations or joins? Separate single row reads or returning multiple rows-per-second results from a single query? Was this on persistent storage or in-memory? While scale is important, it is vital to note these are not all apples-to-apples comparisons. While large numbers are impressive, make sure you understand the nature of what each vendor is testing for. It goes to show that big data headlines claiming “millions,” “billions” and “trillions” all need to be looked at on their own merits.
Basic Methodology: Hiding a Needle in a Haystack
We set forth to create a database that simulated the scenario of a million homes, all equipped with smart home sensors capable of reporting thermometer readings every minute, for a year’s worth of data.
That equates to:
1,000,000 * 24 * 60 * 365 = 525.6 billion data samples for a single year.
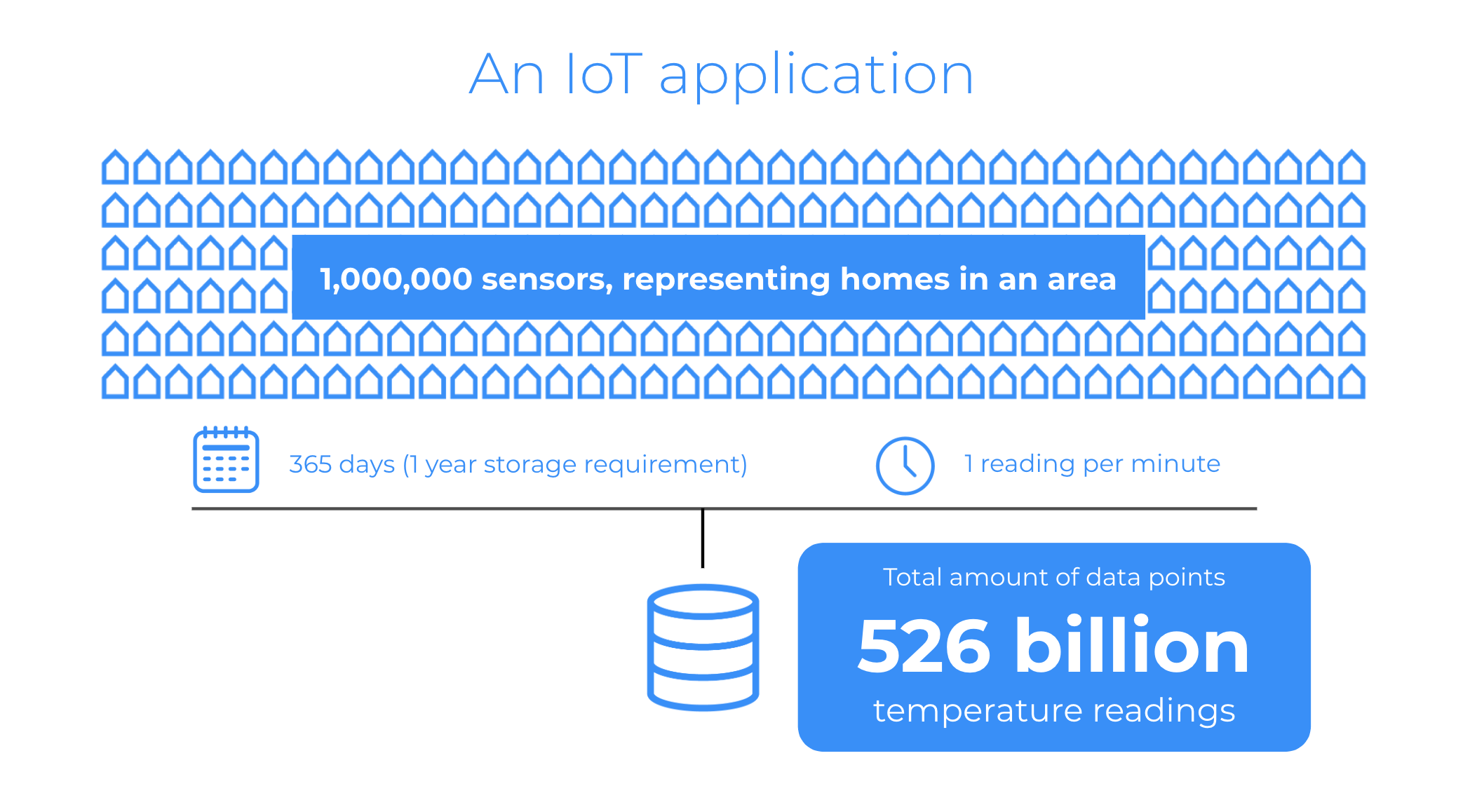
To give an idea of how much data that is, if you were to analyze it at one million points per second (a “milly”), it would till take over 146 hours — almost a week — to analyze.
To generate the data, we used the IoT Temperature example application, available in the ScyllaDB Code Examples repository. The application mimics an IoT application that stores temperature reading from many sensors that are sent to the database every minute, for a total of 1440 points per day. Each sensor has a sensor_id, that is used as part of a composite partition key together with a YY-MM-DD date. The schema is as follows:
CREATE TABLE billy.readings (
sensor_id int,
date date,
time time,
temperature int,
PRIMARY KEY ((sensor_id, date), time)
)This is a pretty standard schema for a time-series workload that allows for efficient queries that query a specific point in time for a sensor by specifying the entire primary key, and also queries for an entire day by specifying just the partition key components (sensor_id and date)
Aggregations are also possible by iterating over all possible sensor_id and date, if the dataset is non-sparse, or by means of a full table scan if the dataset is sparse (There is also a Full-table scan example in the ScyllaDB Code Examples repository.)
We used the populator binary from our application to generate 365 days of data coming from 1,000,000 sensors. This is a total of 525 billion temperature points stored.
To create the data set we launched two dozen loader / worker nodes to generate temperatures for the entire simulated year’s worth of data according to a random distribution with minor deviations.
We then manually logged into the database and poisoned one of the days by inserting outlier data points that don’t conform to the original distribution. These data points serve as an anomaly that can be detected. In specific, we put in a pair of extreme temperatures that are far above and below normal bounds in the same house on the same day at nearly the same time. Such extremes could indicate either a malfunction in a house’s temperature sensor, or real-world emergency conditions (for example, going from freezing cold to very hot might indicate a power failure followed by a house fire).
Really, though, it just served as a “needle” to find in a “haystack” worth of data. Because finding this anomaly without prior knowledge of the partition it was stored in requires scanning the entire database.
We wanted to minimize network transfer and do as much work as possible in the server to highlight the fact that the consistent hashing algorithms used by ScyllaDB excel at single-partition accesses. For each partition we then executed the following query:
SELECT count(temperature) as totalRows , sum(temperature) as sumTemperature , min(temperature) as minTemperature, max(temperature) as maxTemperature from readings where sensor_id = ? and date = ?`To read the data we then executed the reader binary distributed with the application, connecting to 24 worker / loader machines. A twenty-fifth machine was used as the system monitor and coordinator for load daemons.
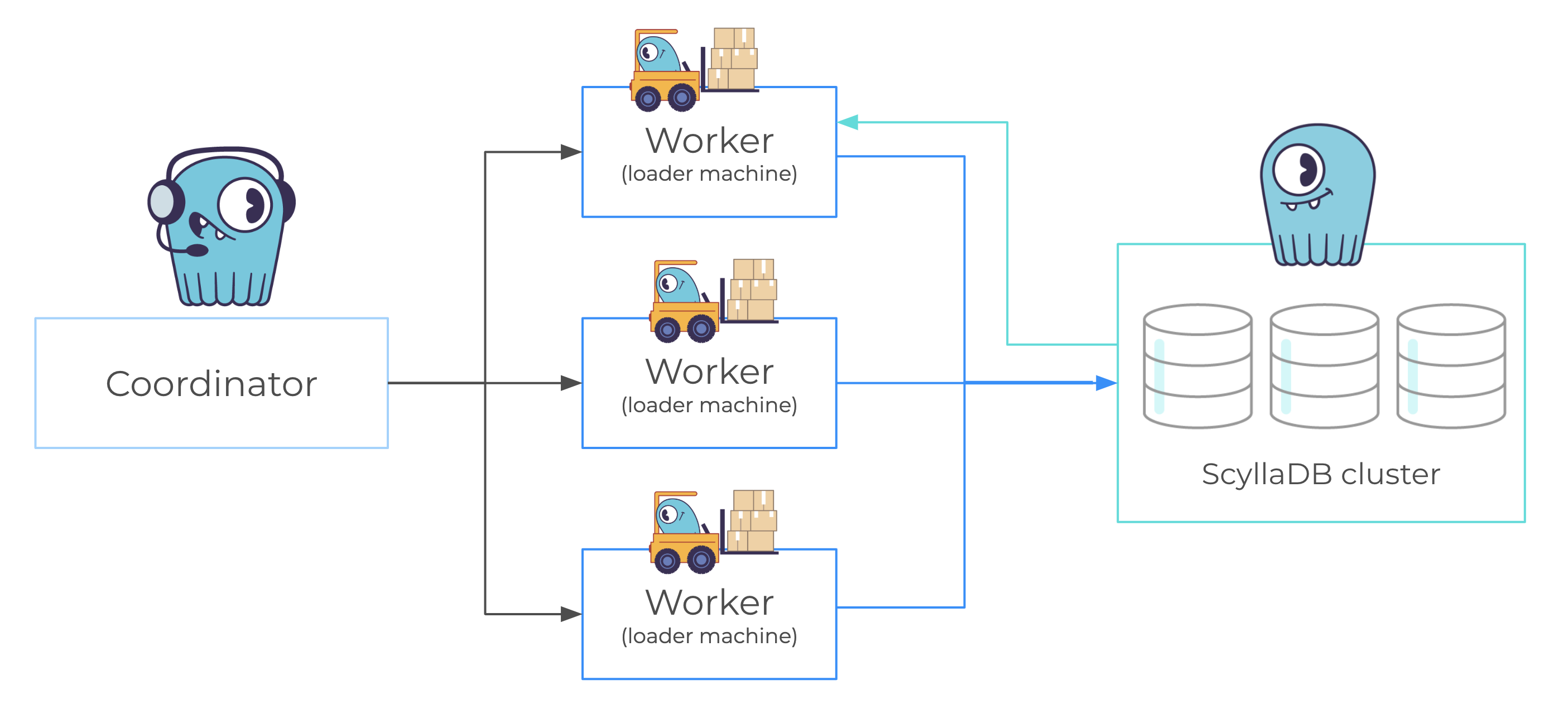
Our “Billy” test setup: the coordinator sends a batch of partition keys to each worker (in our execution, a batch contains 25,000 partition keys). The worker sends a query to ScyllaDB for each partition to compute the number of rows, sum, max and min for each of those partitions and returns to the coordinator the total number of rows, sum, max and min for the entire batch. The coordinator then does the same for all workers and formats the data. In the process of doing that, we report the sensor id for which the max and min temperature were seen.
First Test: Scanning 3 Months of Data
Let’s assume the anomaly we’re looking for took place in a three-month period between May 1st and August 31st of 2019. Since the database stores data for an entire year and those dates are not the most recent, it is therefore unlikely to be frequently queried by other workloads. We can reasonably presume a significant fraction of this data is “cold,” and not resident in memory (not cached). For 1 million sensors each with 3 months worth of data that results in a scan of more than 130 billion temperature points!
Due to ScyllaDB’s high performance all the 130 billion temperature points are scanned in less than 2 minutes. This averages close to 1.2 billion temperature points read per second. The application’s output tells us the greatest temperature anomalies (an extremely low minimum and extremely high maximum temperature) in that interval were recorded on August 27th by SensorID 473869.
# ./read -startkey 1 -endkey 1000000 -startdate 2019-06-01 -enddate 2019-08-31 -abortfailure -hosts /tmp/phosts.txt -step 25000 -sweep random
Finished Scanning. Succeeded 132,480,000,000 rows. Failed 0 rows. RPC Failures: 0. Took 110,892.91 ms
Processed 1,194,666,083 rows/s
Absolute min: 19.71, date 2019-08-27, sensorID 473869
Absolute max: 135.21, date 2019-08-27, sensorID 473869
And since a picture is worth a billion points, it’s even easier if we plot the output temperatures into a graph. It becomes obvious that something odd was going on that day!
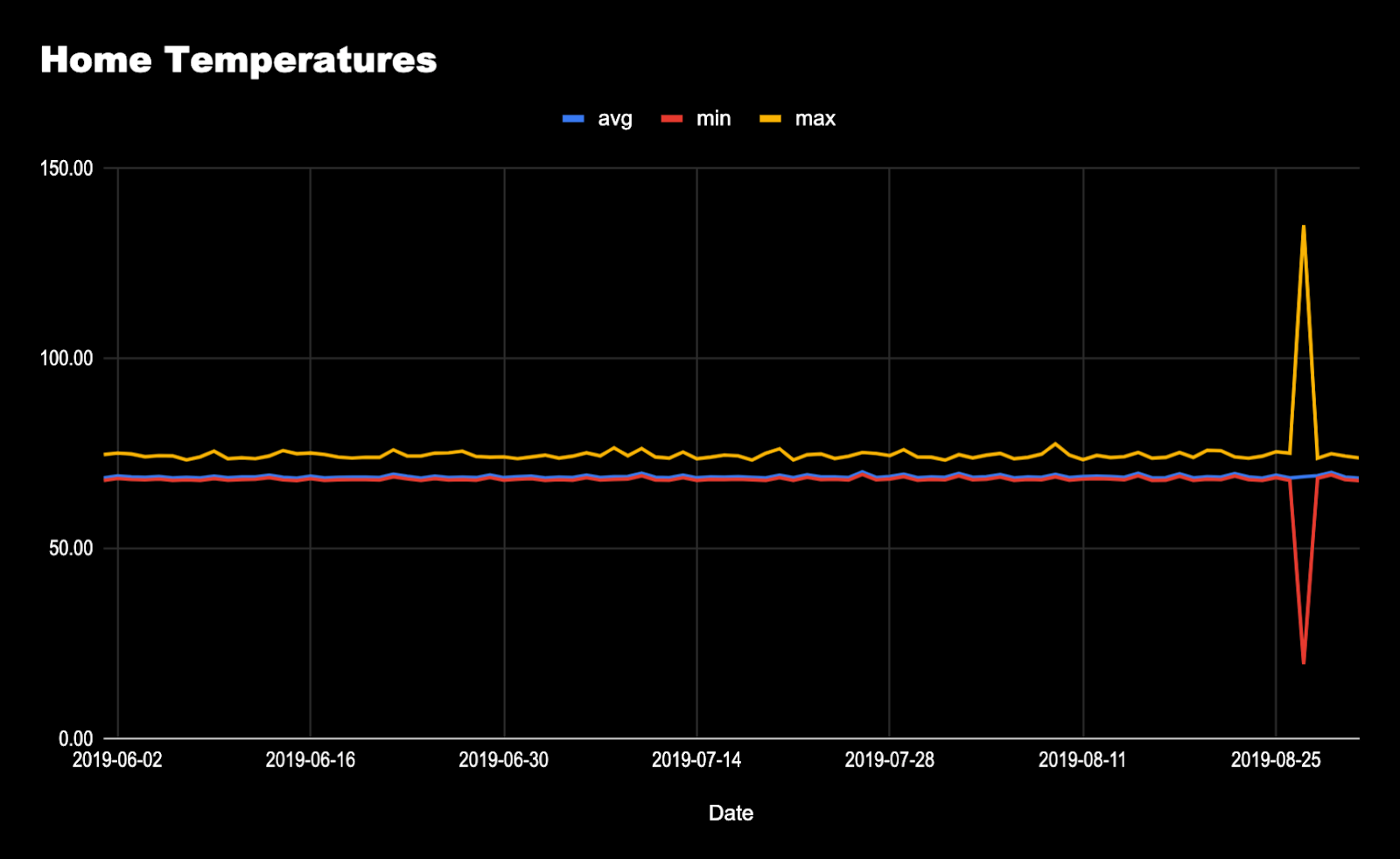
Graph of the daily averages, minimum and maximum temperatures (in fahrenheit) from our sample data clearly show when sensor 473869 had an anomaly on a day in late August 2019.
By looking at our monitoring data, we can indeed see that a significant fraction of our dataset is served from cold storage:
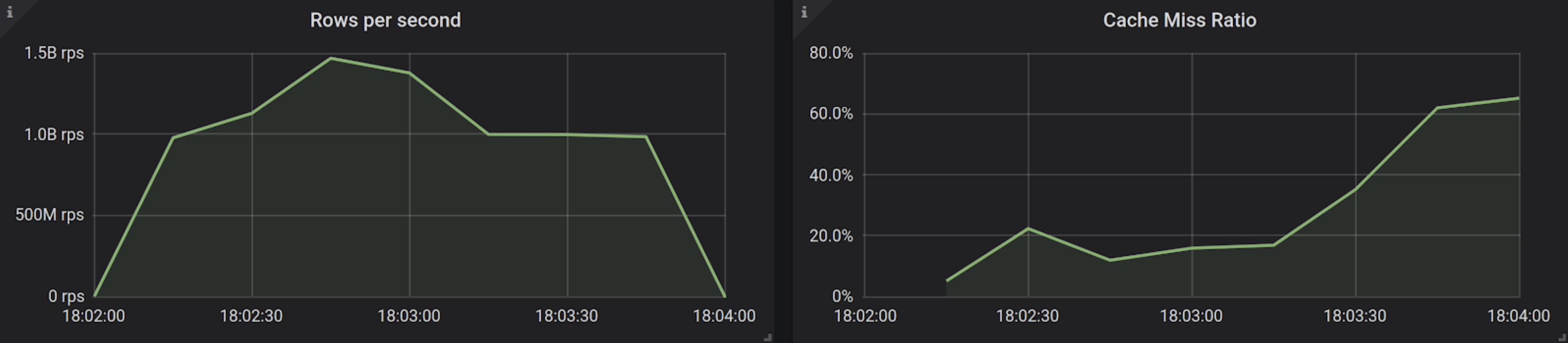
A normal workload, where some rows are cached while some are not. The point-in-time request-rate depends on the cache hit rate, but overall 132 Billion rows are read in 110 seconds, averaging 1.194 Billion rows per second
Now we must ask ourselves: were there any other similar though lesser temperature anomalies anywhere that day? To find that out, we can run the application again, this time excluding the already-flagged SensorID. Because a similar scan just took place the data is now all cached and we now take less than one second to scan all 1.5 billion temperature points for that day – 1.5 billion data points per second.
# ./read -startkey 1 -endkey 1000000 -startdate 2019-08-27 -enddate 2019-08-27 -abortfailure -hosts /tmp/phosts.txt -step 25000 -sweep random --exclude=473869
Finished Scanning. Succeeded 1,439,998,560 rows. Failed 0 rows. RPC Failures: 0. Took 938.84 ms
Processed 1,533,812,721 rows/s
Absolute min: 68.38, date 2019-08-27, sensorID 459949
Absolute max: 75.75, date 2019-08-27, sensorID 458027
But what about the rest of the year? Inspired by the results of the first run, we are not afraid of just scanning the entire database, even if we know that this time all of the data will be cold and served from storage. In fact, we now have miss ratios of essentially 100% for the majority of the workload, and are still able to scan close to 1 billion temperature points per second.
# ./read -startkey 1 -endkey 1000000 -startdate 2019-01-01 -enddate 2019-12-31 -abortfailure -hosts /tmp/phosts.txt -step 25000 -sweep random -exclude=473869
Finished Scanning. Succeeded 525,599,474,400 rows. Failed 0 rows. RPC Failures: 0. Took 542,191.31 ms
Processed 969,398,554 rows/s
Absolute min: 68.00, date 2019-05-28, sensorID 82114
Absolute max: 79.99, date 2019-03-19, sensorID 152594
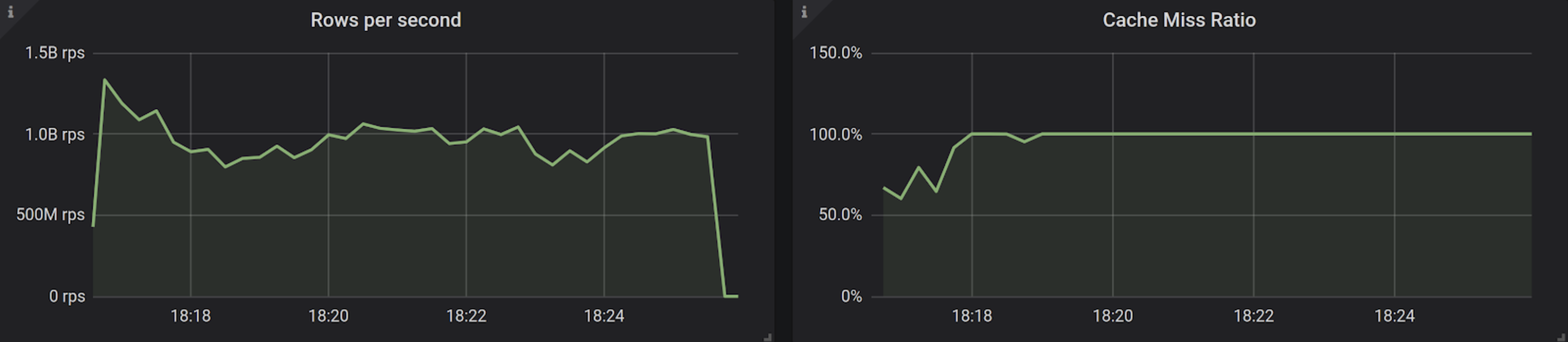
To do a complete data set scan at the “billy” scale (nearly a billion rows per second) took 542 seconds – just over 9 minutes.
The Infrastructure
To run this test at scale required a partner with hardware that was up to the challenge. Enter Packet, who provided the bare metal server test bed for our analysis. The database itself ran on their n2.xlarge.x86 nodes. These machines have 28 Intel Xeon Gold 5120 cores running at 2.2 GHz, 384 GB of RAM, and 3.8 TB of fast NVMe storage. With 4x 10 Gbps NICs, we wanted to make sure that the test was not bounded by network IO. Against this, the worker cluster comprised 24 c2.medium.x86 servers. These sport 24 cores running at 2.2 GHz using the AMD EPYC 7401p chip, plus 64 GB RAM and 960 GB SSD.

See the presentation from our ScyllaDB Summit keynote here, beginning at 4:09 in the video:
Next Steps
We’ve now reached a new summit in terms of scale and performance, but there are always more mountains to climb. We are constantly astonished to hear what our users are accomplishing in their own networks. If you have your own “mountain climbing” stories to share, or questions on how address a mountain of data you are trying to summit yourself we’d love to hear them!
Also, to help you reach your own scalability goals you might want to view a few talks from our recent ScyllaDB Summit. First, we showed at ScyllaDB Summit some even more efficient ways to write applications like the test presented above using upcoming new features in ScyllaDB Open Source 3.2 including CQL PER PARTITION LIMIT, GROUP BY and LIKE.
For ScyllaDB Enterprise users, you might also be interested in our ScyllaDB Summit session on workload prioritization. This feature, unique to ScyllaDB, allows you to put multiple workloads on the same cluster, such as OLTP and OLAP, specifying priorities for resource utilization to ensure no single job starves others entirely. Because while it is important to design tests to show the maximal lab-condition capabilities of a system, it is also vital to have features to prevent bringing a production cluster to its knees!
Lastly, make sure you check out how to use UDFs, UDAs and other features now committed into the ScyllaDB main branch. This talk by ScyllaDB CTO Avi Kivity explains how you will eventually be able to use these to shift functions and aggregations directly to database server itself, offloading your client from having to write its own coordinator code.




