In this post we introduce the new ScyllaDB workload prioritization mechanism, explaining the vision behind developing this feature and how it is implemented, and most importantly, we show you test results of how it performs in a real-world setting.
Databases have always been the focal point of the enterprise software stack and the more we modernize with microservices, AI, Analytics and serverless implementation, the more important the database role becomes. With multiple data consumers, the challenge the database faces grows, at times to a level many databases cannot meet.
A common practice in modern stack is to segregate microservices and data services, thus enabling individual SLAs. Spikes and higher demand coming from service A are routed to a dedicated database cluster and would not affect service B, which has its own dedicated cluster.
In a similar way, databases serve conflicting workloads such as Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP). OLTP requires low latency while OLAP requires bulk processing and throughput.
With lack of choice, database users, ScyllaDB users included, had to segregate these workloads too, either to isolated clusters, isolated virtual data centers or time-based segregation (run analytics/reporting overnight). Each of these has associated limitations, risks and/or significant costs.
The analogy is to consider OLAP like freight trucks. Large eighteen wheelers hauling a lot of data. The raw throughput — data volume — is what is important. OLTP, on the other hand, is more like a sports car. Built for data velocity, it is latency-sensitive. Right now what the industry is doing is effectively building one data highway for trucks and another highway for sports cars. It is inherently inefficient. Instead what we propose is to run all traffic on the same highway, and grant some lanes of traffic priority over others.
How can a single cluster successfully handle both classes of traffic? The concept for the mechanism was first presented by ScyllaDB’s CTO Avi Kivity at Distributed Data Summit 2018, and then further expanded upon by ScyllaDB’s Vice President of Field Engineering, Glauber Costa, at ScyllaDB Summit 2018 in his talk entitled OLTP or Analytics: Why Not Both? This blog will show precisely how this feature was implemented in ScyllaDB Enterprise Release 2019.1 as a technology preview.
Goals for Workload Prioritization
ScyllaDB already has internal schedulers and mechanisms to manage CPU, I/O and other resources. Yet as system utilization rises, the database must strictly prioritize what activities get what specific share of resources under contention. The purpose of workload balancing is to provide a mechanism that ensures each defined task has a fair share of system resources such that no single job monopolizes system resources, starving other jobs of their needed minimums to continue operations. The ScyllaDB database has many internal processes that are executed for its own maintenance, from streaming for autoscaling, to repair for replica synchronization and storage compaction. ScyllaDB has long been able to prioritize foreground read/write operations over those background efforts. With Workload Prioritization we’ve taken these building blocks to the next level.
Ideally we would allow the user to define different workloads and prioritizations for them. When resource contentions occur (such as during high load) resources are prioritized as the expected level of service is configured for it.
Examples with and without Workload Prioritization
In this first example, we will host two workloads, load1 and load2. Each workload will be given a different amount of shares. The database cluster cannot meet the overall load of the two and thus will have to prioritize them. It is visible that load2 enjoys a much larger share than load1 as expected from the configuration below.
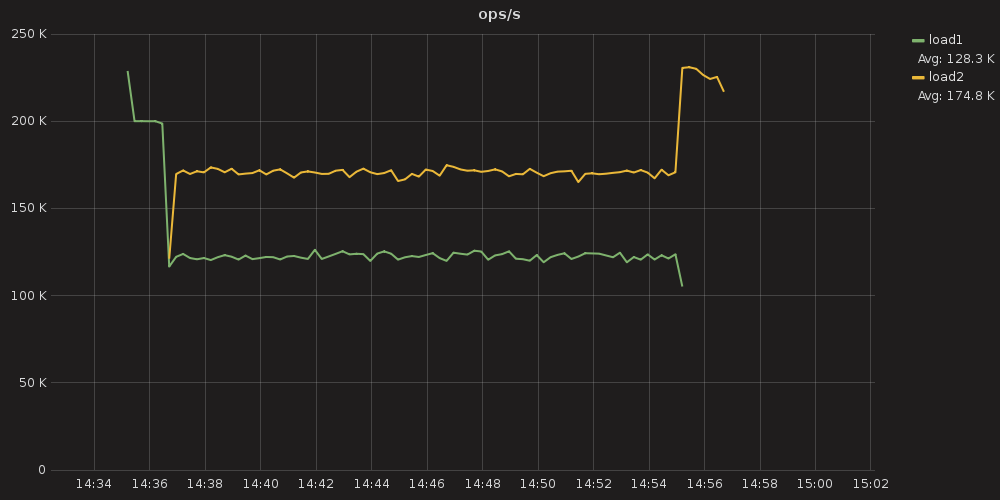
Figure 1: An example of throughput on two different loads utilizing workload prioritization.
Figure 1 above depicts an image from Grafana, where two loads were trying to achieve 200,000 operations per second (ops) on a server cluster that can handle only 290,000 ops. The first task, load1, is initiated at 14:35 and levels off at approximately 200,000 ops. But soon thereafter, at 14:37, load2 is initiated. It rises to approximately 170,000 ops while lowering the performance of load1 to 120,000 ops. This was because load1 was given 200 shares, while load2 was given a higher priority of 400 shares.
The database used the workload prioritization shares to apportion system resources between the two tasks. Note that workload prioritization is only an approximate attempt to balance resources: the shares set (400 : 200) do not have the same proportional ratio as the observed operations per second for the two loads (170k : 120k). An interactive version of this graph can be found here.
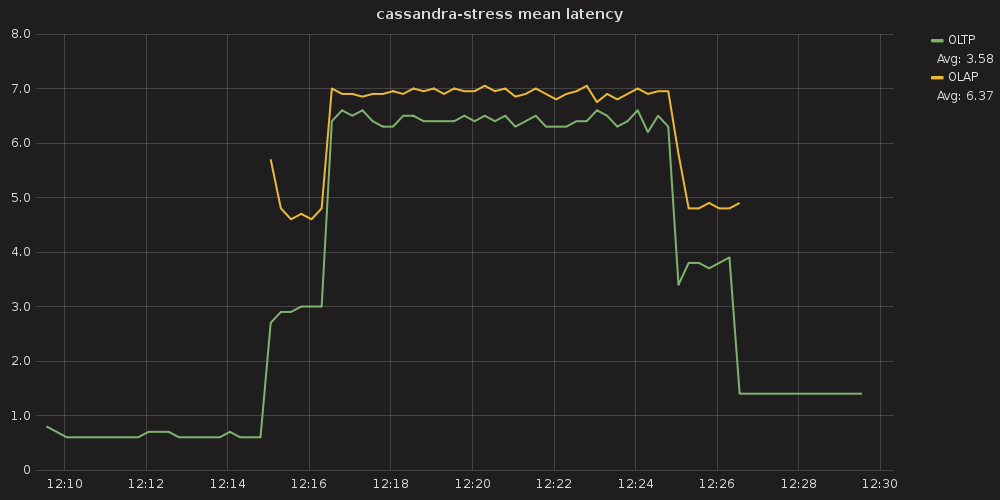
Figure 2: An example of latency impacts on an OLTP workload by an OLAP workload without workload prioritization enabled.
In Figure 2, a cluster without workload prioritization enabled is running an OLTP process with a mean latency of ~0.6ms (shown by the green line). Then an OLAP process begins to run on the system (shown by the yellow line). This causes the OLTP process’ latency to increase by an order of magnitude to ~6.5ms, while the OLAP latency hovers near ~7.0ms. After the OLAP process concludes, latency again improves on the OLTP process, though it does not return to sub-millisecond levels.
An interactive version of this graph can be found here.
Configuring Workload Prioritization in ScyllaDB
To enable this yourself, you would have to first apply Role Based Access Control (RBAC) to establish two roles. The first is load1_user and the other load2_user.
Once you have created the roles, the above result was achieved using only four CQL commands to apply prior to running the load:
CREATE SERVICE_LEVEL 'load1' WITH SHARES=200;
ATTACH SERVICE_LEVEL 'load1' TO 'load1_user';
CREATE SERVICE_LEVEL 'load2' WITH SHARES=400;
ATTACH SERVICE_LEVEL 'load2' TO 'load2_user';The above command sequence creates a service level for each of the workloads with the appropriate amount of shares and then applies this service level to the corresponding roles/users. The settings will take effect across the cluster in short order.
And that is it. You have set up workload prioritization!
To learn more details about workload prioritization configuration, check out our documentation.
So What Are the Problems, Exactly?
In essence, this is an optimization problem where you want to provide a desired Quality of Service (QOS) level for all or some of your clients with minimum investment and waste.
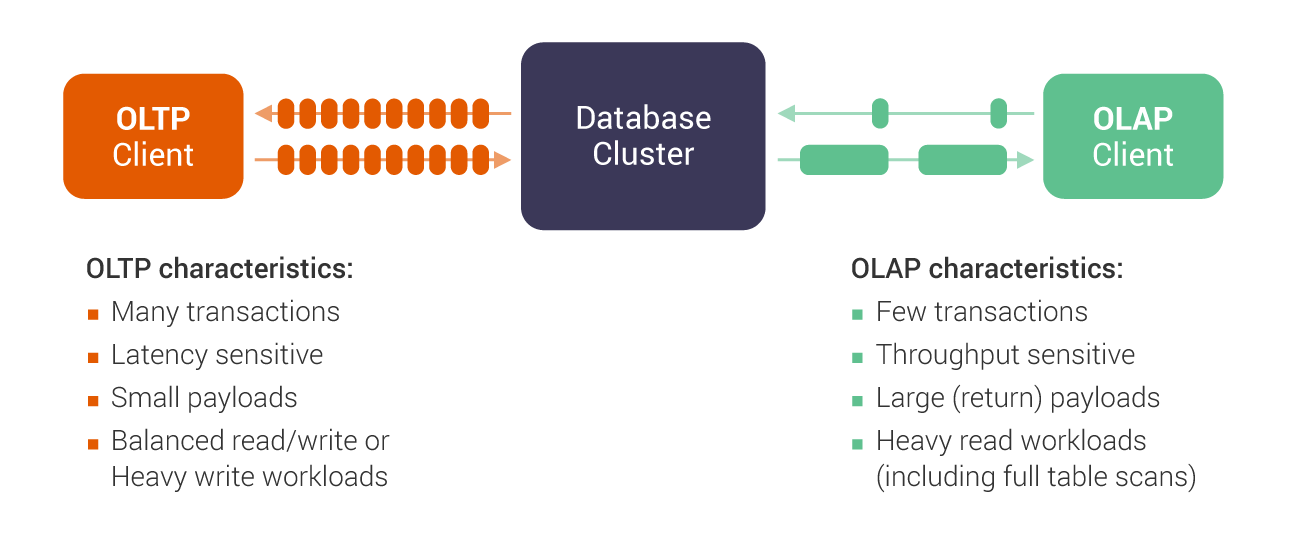
Figure 3: Typical characteristics of OLAP and OLTP.
OLAP and OLTP are general terms used to roughly divide database workloads into two main classes. OLTP describes workloads characterised by a lot of quick transactions with relatively small amounts of data while OLAP stands for the exact opposite: fewer lengthy operations that retrieve/produce large amounts of data. Each workload is thus oriented towards different measurement of performance: OLTP is latency oriented while OLAP is throughput oriented. Designing a system that performs well under both types of operational loads has been the first key architectural hurdle. Without solving this technical challenge, a database cannot address the other issues delineated below.
To date data architects often designed dual, redundant systems — one for transactions, and another for analytics — to prevent disruptions to their real-time transaction systems. One example of this is the lambda architecture. While such bifurcated systems are a frequently-encountered configuration, this strategy complicates and can effectively double the price of day-to-day operations.
Possible Solutions
OLAP vs OLTP Solution – Divide and Conquer (Literally)
Since the conflict is on resources, a technically trivial solution (with not-so-trivial implications on costs) can be to simply physically divide the resources. This solution is implemented in practice by having 2 clusters, one for OLAP workloads and one for OLTP workloads. Data still needs to be synchronized between the clusters, but since the OLAP system is generally reserved for read-only jobs, it is a matter of synching data in the OLTP cluster to the OLAP cluster. This solution is as close as it gets to a complete workload isolation. The tradeoff here is cost, the cluster now has to be duplicated, which means up to double the cost. This is fine if the resources are fully utilized but more often than not this is not the case. Analytics, for instance, may only be run at set periods during the day. So here you have a second cluster that sits around doing nothing but costing you money for large periods of time.
Run Analytics during Off-peak Times – Time Division
Another division can be in time domain when OLAP processes run on the same OLTP system, but only at the periods empirically or by some other means found to be less active. There are 2 main problems with this approach:
- What happens to OLTP workloads that occur in those periods? Do they fail? Do they get batched for later processing?
- What if one such period is not enough to complete the analytics work? Do you turn it off part-way through its analysis? Speculatively divide it beforehand? Or just live with the fact that part of the OLAP workload will “leak” into the buisier periods, degrading QOS for the OLTP workload.
The Best of All Possible Worlds – ScyllaDB’s Workload Prioritization
ScyllaDB’s workload prioritization is a mechanism that was built especially for solving the aforementioned problems. It does so by splitting users into groups and prioritizing their resource distribution according to a user-defined ratio. This mechanism kicks in only when there is a conflict about a resource. For example, under extremely high loads.
Although this sounds complicated, ScyllaDB already contains the basic building blocks to do this, and has had them for a long time. At the heart of the solution are ScyllaDB resource schedulers; there are several of them but the basic idea remains the same. We define a number of classes of clients for a specific resource, each class has partial ownership on the resource that dynamically translates to a percentage of ownership on the resource. This idea is very similar to holding some shares of a company in the stock market.
Applying those same concepts to the database, we ask the user to give shares of resources in the database to groups of users. Whenever there is a conflict regarding a resource, some resource is not enough to serve all pending requests, or, more formally, when the tasks pending will need more than 100% of the available system resources to complete, the conflict will be solved by the configured share on the resource. The method described here has the additional benefit that it is only enforced when there is a conflict. This means that when there are no conflicts, a “small shareholder” can have as much of the resource as they need, allowing greedy but less preferred users to get their way in the less active times. The result is that, on the one hand it helps to ensure a certain level of QOS to some (or all) users and, on the other hand, allows for high resource utilization.
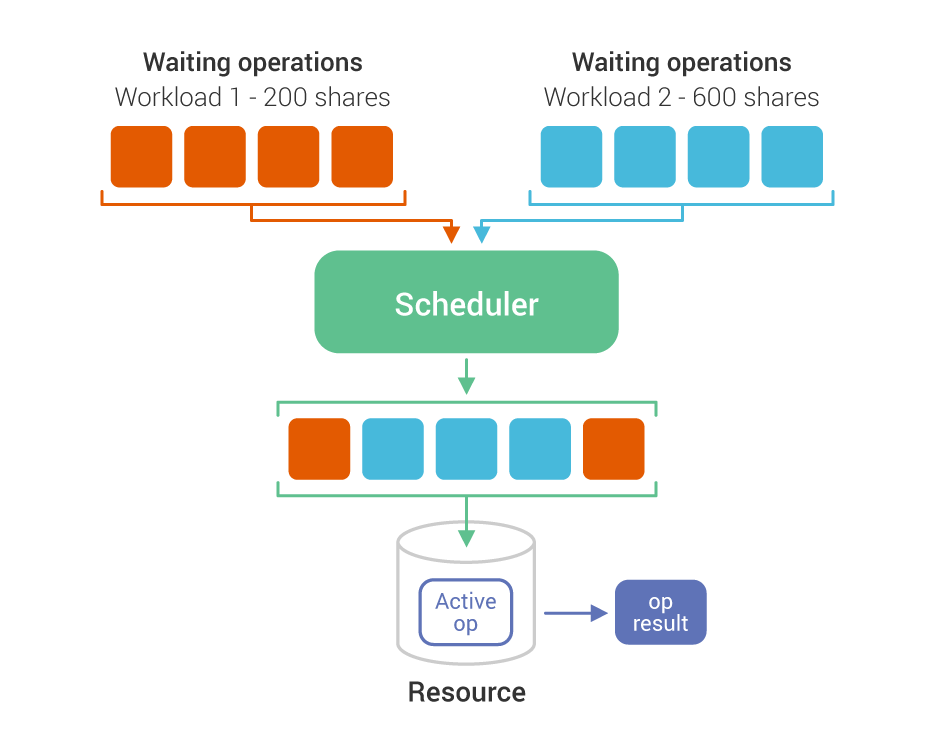
Figure 4: An example of two workloads with different set shares under workload prioritization. Workload1 has 200 shares, while Workload2 has 600 shares. Thus, for every waiting operation that Workload1 gets queued through the scheduler, Workload2 will have 3 operations queued.
Design and Implementation
As mentioned before, the building blocks for the implementation of this feature exists for some time and now, when they have matured we put it all together to form workload prioritization.
The 3 key features we built upon were:
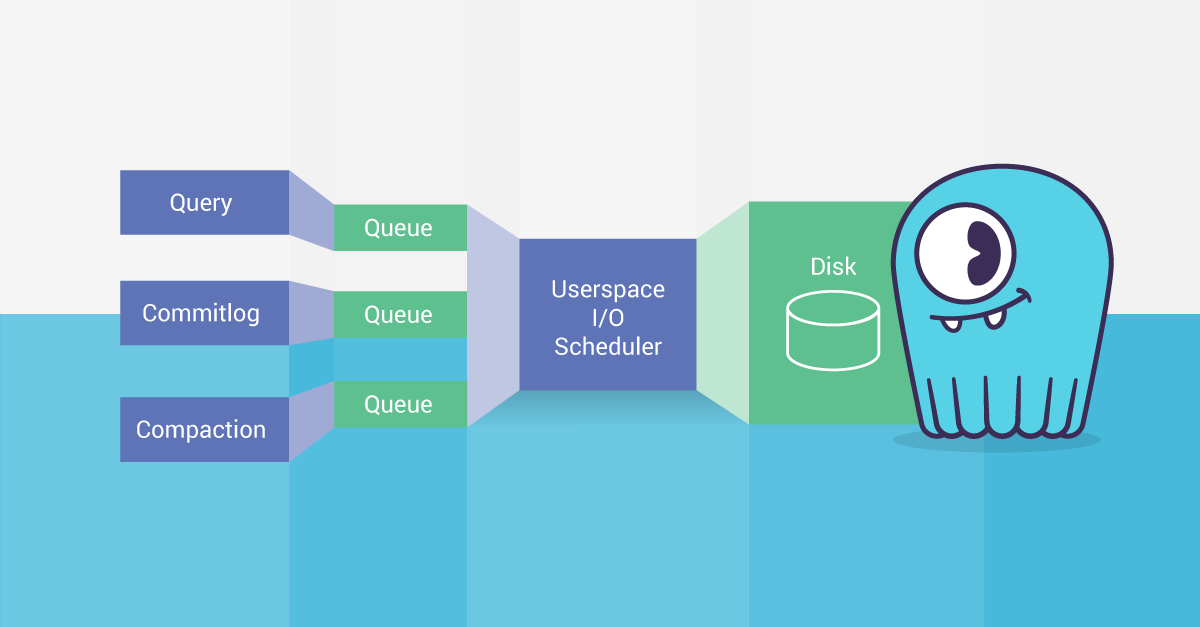
- Resource Schedulers – we leveraged our underlying CPU and IO schedulers for this feature. In fact, the schedulers are the main component in making the prioritization happen; they all work with the “shares” concept. Schedulers can create the appearance of several parallel queues where each queue gets served with different QOS. (For details, you can study more about ScyllaDB’s IO Scheduler in this three part blog series: Part 1, Part 2, and Part 3.)
- Seastar’s Remote Procedure Call (RPC) isolation cookies – allowing priority information to propagate across network boundary, this means that even operations that are performed on different nodes inherit the priority of the current workload.
- Role Based Access Control (RBAC) – this made two things possible, the first is the ability to identify user or a group of users and the other is to build hierarchy of roles. The latter is important because otherwise the service level would need to be configured for each user and not just a role that is attached to several users.
We implemented a controller which is in charge of setting up the different schedulers and RPC isolated connections for each configured service level. This controller is also using the role based access control system for figuring out what service level each user should receive.
The configuration itself is done by CQL queries.
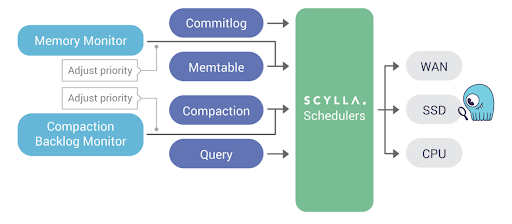
Figure 5: This block diagram shows how ScyllaDB’s internal schedulers can have priority adjusted. It already does so internally and automatically to prevent compaction processes hampering transactions. Now that same mechanism is available for users to define their own roles and classes of priority.
Limitations of Assigning “Shares”
In early discussions and presentations this feature was referred to as “per-user Service Level Agreement (SLA).” However, that nomenclature was imprecise and later abandoned in favor of the more accurate term “workload prioritization.” The share-based implementation gives only weighted priorities to different user roles (based on RBAC). It does not guarantee a specific service level, such as various average or tail latency (p95 p99, p999) guarantees or any explicit transactions-per-second guarantee.
Further, shares are established for overall system resources. Workload prioritization does not allow (nor require) granular tuning or allocation for different system attributes, such as the specific amount of RAM, disk IO or network IO for different tasks.
This is in-line with ScyllaDB’s design principles for managing such decisions automatically, and not putting undue administrative burden on the administrator. The administrator just sets the shares, and the system self-manages the exact methods for workload prioritization underneath.
Test Results: Three Simple but Useful Use Cases
1. OLAP vs OLTP
- The OLTP load is stimulated by low concurrency (200) that tries to reach 60K ops
- The OLAP load is stimulated by high concurrency (1800) that is unbounded (bombing the database with requests in order to keep the queues full and get high throughput).
First, let’s see what happens without workload prioritization enabled:
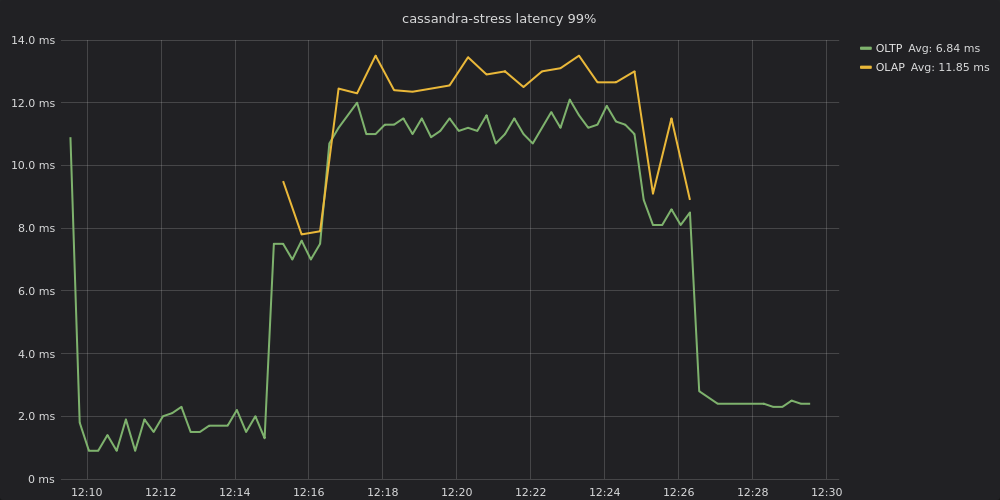
Figure 6: Latency between OLAP and OLTP on the same cluster before enabling workload prioritization.
Note in Figure 6 that latency for both loads nearly converges. OLTP processing began at or below 2 ms for p99 up until the OLAP job is begun at 12:15. When OLAP was enabled OLTP p99 latencies shot up to 8 ms, then further degraded, plateauing around 11 – 12 ms until the OLAP job terminates after 12:26. These latencies are approximately 6x greater than when OLTP ran by itself. (OLAP latencies hover between 12 – 14 ms, but, again, OLAP is not latency-sensitive.)
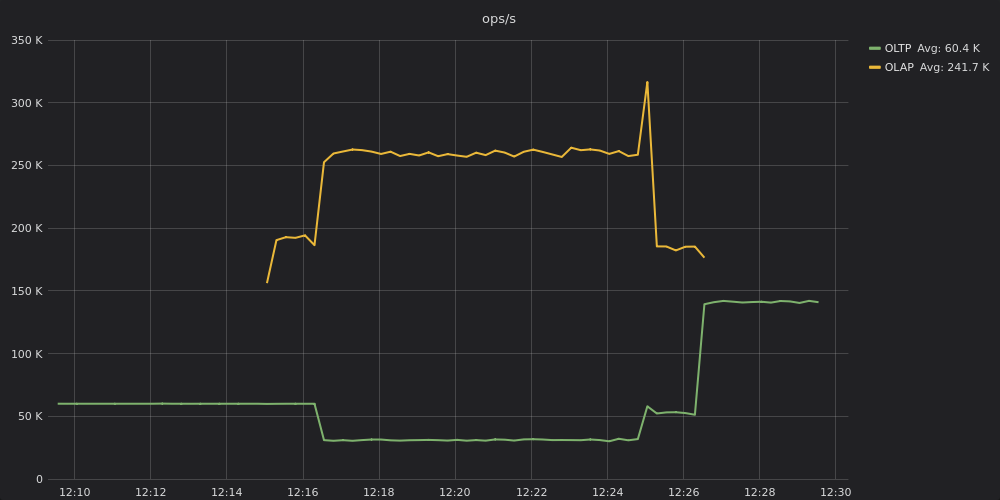
Figure 7: Comparative throughput results for OLAP and OLTP on the same cluster without workload prioritization enabled.
In Figure 7 throughput on OLTP sinks from around 60,000 ops to half that — 30,000 ops. You can see the reason why. OLAP, being throughput hungry, is maintaining roughly 260,000 ops.
An interactive version of these graphs can be found here.
Bottom line: OLTP suffers; users experience slow replies. While the latency chart shows basically the same performance, throughput shows that OLAP is basically dominating the system. In many real-world conditions, such OLTP responses would violate a customer’s SLA, both for latency as well as throughput.
Now, let’s try enabling workload prioritization.
We set up the workload prioritization with the following CQL commands:
CREATE SERVICE_LEVEL 'OLTP' WITH SHARES=1000;
ATTACH SERVICE_LEVEL 'OLTP' TO 'OLTP_user';
CREATE SERVICE_LEVEL 'OLAP' WITH SHARES=10;
ATTACH SERVICE_LEVEL 'OLAP' TO 'OLAP_user';Using the exact same workloads we got:
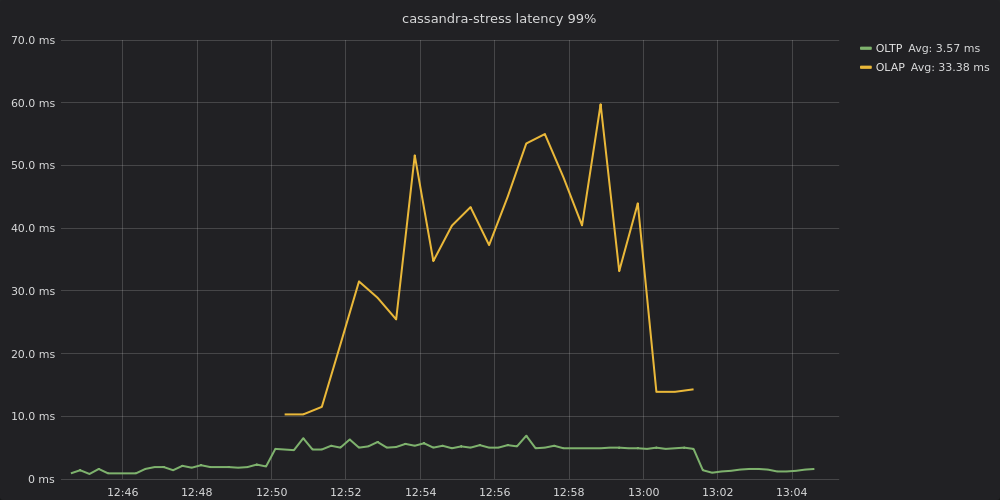
Figure 8: OLAP and OLTP latencies with workload prioritization enabled.
In Figure 8, after workload prioritization is enabled, the OLTP workload similarly starts out at sub-millisecond to 2 ms p99 latencies. Once an OLAP workload is added performance degrades on OLTP processing, but with p99 latencies hovering between 4 – 7 ms, that is about half of the 11-12 ms p99 latencies when workload prioritization was not enabled. (The OLAP workload, not being as latency-sensitive, has p99 latencies that hover between 25 – 65 ms.)
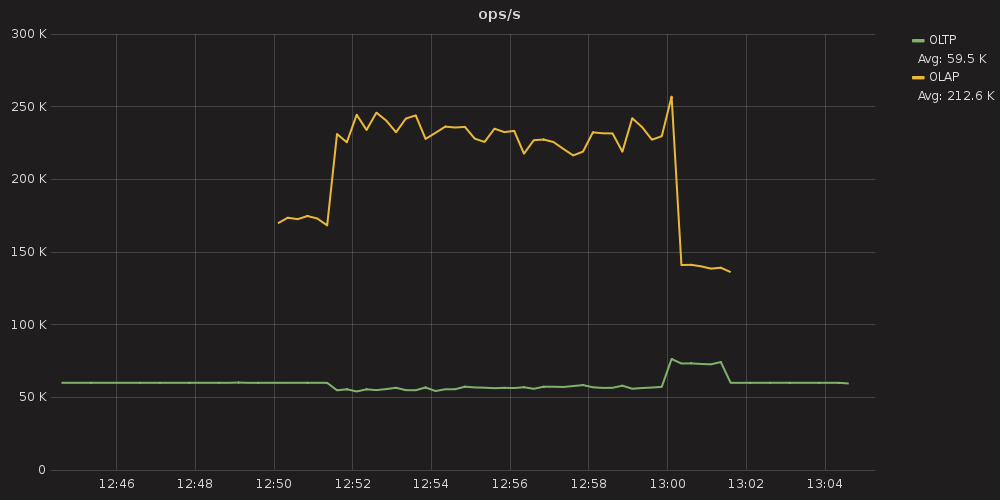
Figure 9: OLAP and OLTP load throughput with workload prioritization enabled.
In Figure 9, OLTP traffic is a smooth 60,000 ops until the OLAP load is also enabled. Thereafter it does dip in performance, but only slightly, hovering between 54,000 to 58,000 ops. That is only a 3% – 10% drop in throughput. The OLAP workload, for its part, hovers between 215,000 – 250,000 ops. That is a drop of 4% – 18%, which means an OLAP workload would take longer to complete. Both workloads suffer degradation, as would be expected for an overloaded cluster, but neither to a crippling degree.
An interactive version of this graph can be found here.
2. General Purpose Two-Workload Prioritization
Here we show another use — generally prioritizing workloads. This test would apply if, for example, you were running two or more transactional microservices on the same cluster.
We use here 2 service levels the first with 200 shares and the second with 800. Both clients have parallelism of 900 and they try to achieve 200K ops. The database can only process ~270K ops so there is a conflict on resources.
Configuration:
CREATE SERVICE_LEVEL 'load1' WITH SHARES=200;
ATTACH SERVICE_LEVEL 'load1' TO 'load1_user'
CREATE SERVICE_LEVEL 'load2' WITH SHARES=800;
ATTACH SERVICE_LEVEL 'load2' TO 'load2_user'
Here is what we got:
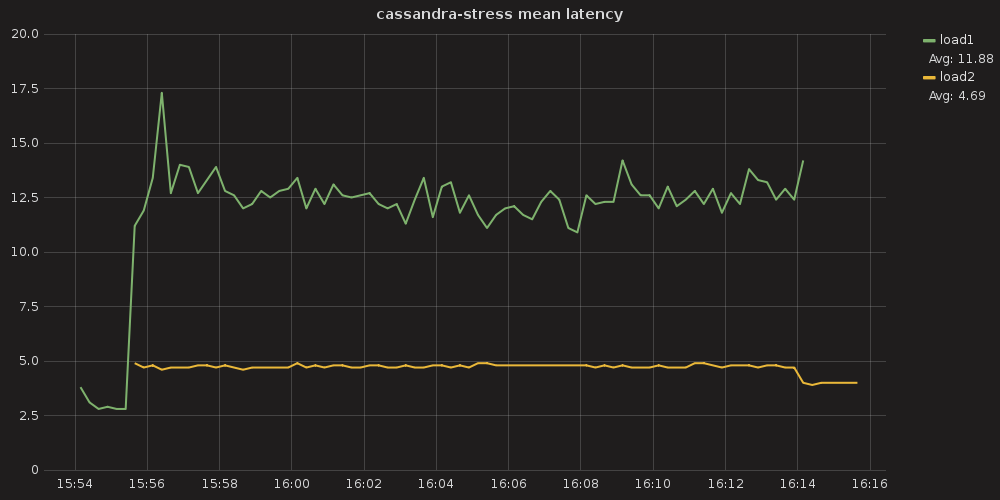
Figure 10: In this example, load1 (in green) is given 200 shares and load2 (in yellow) is given 800 shares. Note that because of this, load2’s mean latency hovers near a very reliable 5 ms level, while load2, being of lower priority, sees latencies that generally hover between 10 – 15 ms.
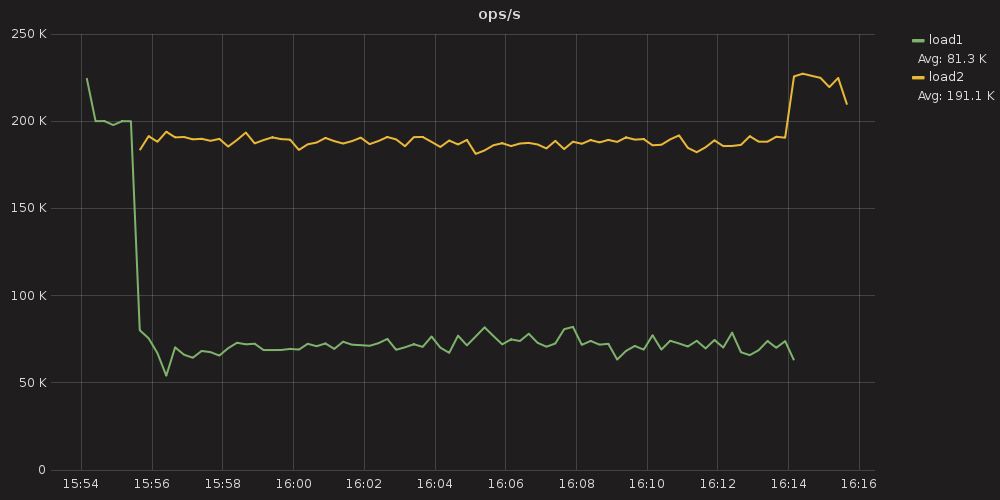
Figure 11: Throughput for the same configuration. Note that load1, with only 200 shares, has a throughput that hovers around 70k ops. Whereas load2 hovers around 190k ops.
An interactive version of these graphs can be found here.
We can observe two things:
- The less preferred workload (load1) gets its 200k ops when it is the only workload at the system.
- When a “major shareholder” (load2) kicks in creating a resource conflict, load1 immediately gets throttled up to a point that the ratio between the ops per second of both workloads is very close to the shares ratio.
3. General Purpose Three-Workload Prioritization
For the final example we will use the same setup as the previous example but this time with 3 distinct workloads:
- load1 – 200 shares
load2 – 400 shares
load3 – 800 shares
As always the configuration is very simple, this time we will do it by altering the previous example configuration:
First we will change the load2 service level to have only 400 shares:
ALTER SERVICE_LEVEL 'load2' WITH SHARES=400;Now we will add load3 with 800 shares and attach it:
CREATE SERVICE_LEVEL 'load3' WITH SHARES=800;
ATTACH SERVICE_LEVEL 'load3' TO 'load3_user'Running the 3 loads gives us:
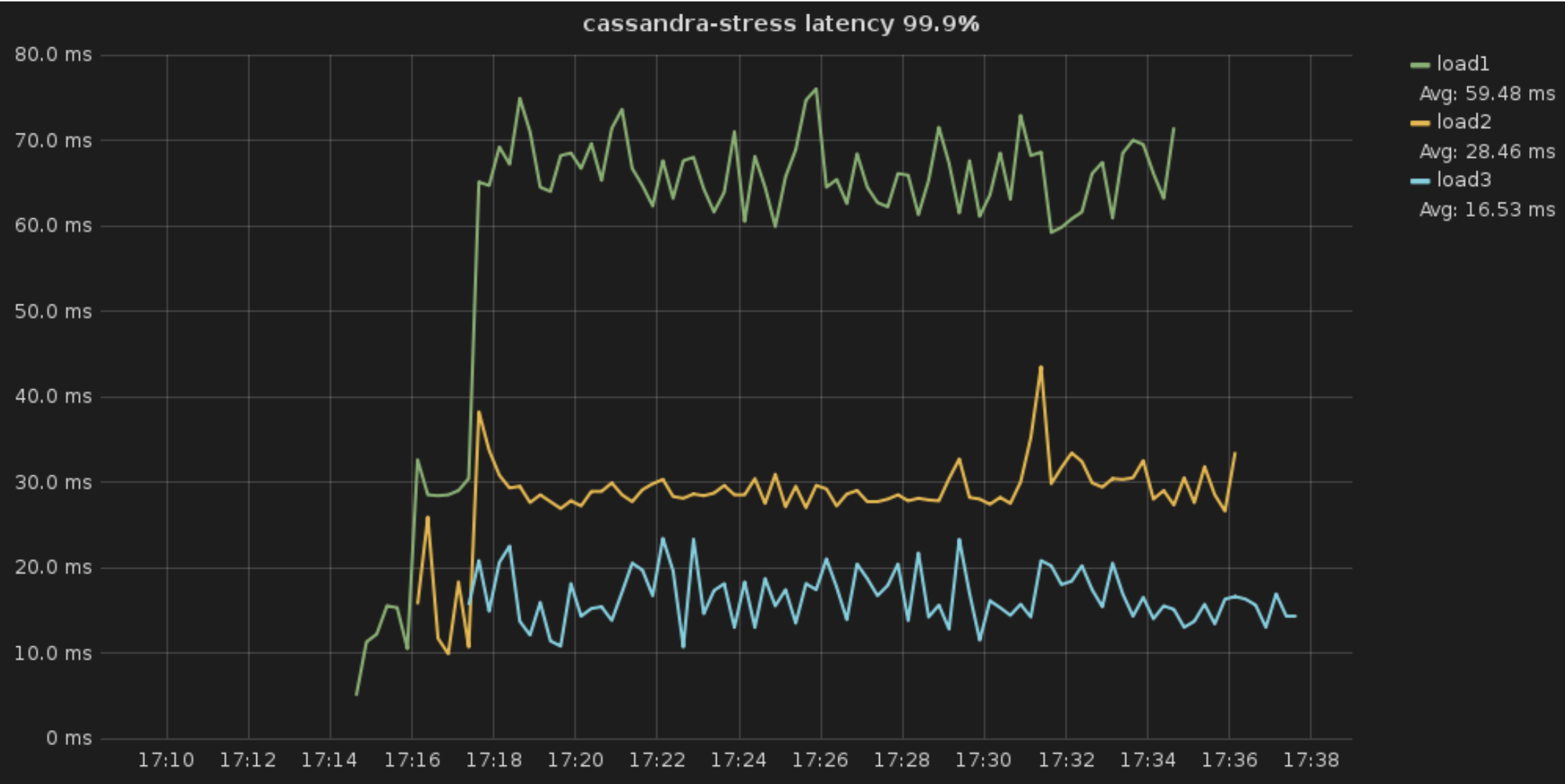
Figure 12: In this example of three loads running on the same cluster, the system does its best to prioritize load3, which is set to 800 shares. It then apportions resources to load2, which has 400 shares. But it still tries to accommodate load1, which is set to 200 shares. The resultant p99 latencies hover between 60-80 ms for load1, around 25 – 40 ms for load2, and 10-24 ms for load3.
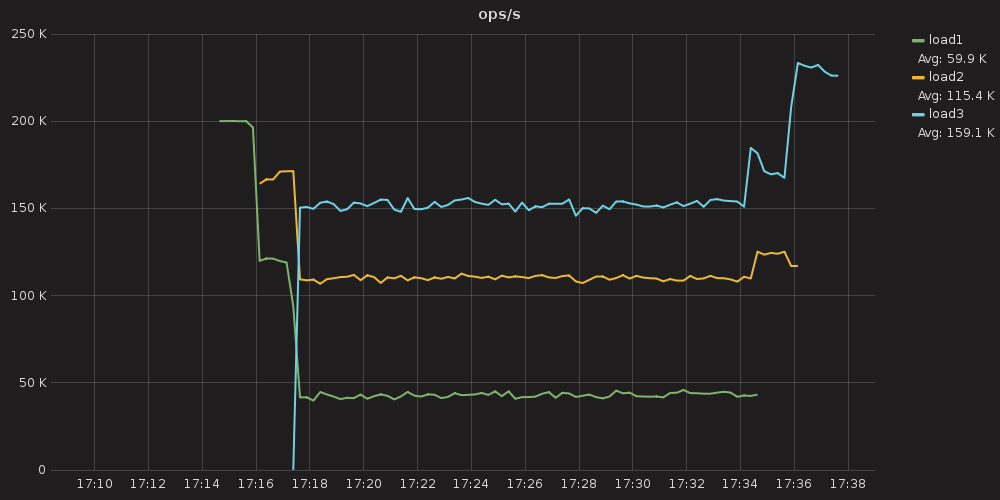
Figure 13: Using the same configuration of 800 shares for load3, 400 shares for load2, and 200 shares for load1, throughput remains quite linear during the operational period: load1 maintains 45k ops, load2 maintains around 110k ops, and load3 maintains around 150k ops.
An interactive version of these graphs can be found here.
Conclusion
Finally multiple workloads can co-exist on the same cluster with the user determining their prioritization. Workload prioritization is the first feature in a future family of Service Level Agreement (SLA) guaranteeing jobs.
In our tests we were able to show how, without workload prioritization, an OLTP job was impacted severely when an OLAP workload came online. The OLTP workload saw a drop of 50% throughput and experienced a sharp, 5x and more increase in P99 latency which may render it unacceptable and require a complete duplication of the hardware setup.
With workload prioritization enabled, OLTP performance was minimally affected (5%-10% throughput drop) while P99 latency hovered at an acceptable 5 ms. In parallel, the massive, deprioritized OLAP workload continue to make good progress with 100s of thousands of requests per second, only 10% below the previous level of throughput. Its latency rose sharply as expected but it is satisfactory for an OLAP job. Thus the mission of co-hosting OLAP and OLTP was successfully accomplished.
In other tests of two and three similar workloads ScyllaDB was able to apportion system resources based upon their allotted shares. These example tests would pertain, for instance, to multiple microservices running off the same cluster.
In all of our tests, the system fairly ensured no one workload would starve the others, and thus our implementation has met our design criteria.
Next Steps
Workload Prioritization is now available as a technology preview in ScyllaDB Enterprise 2019.1. While you can cautiously use it in a production environment, we suggest first conducting tests in a development environment and to monitor cluster performance closely. By the way, a great place to conduct those tests is in ScyllaDB Cloud.
We would love to hear your experience and feedback to improve the feature. Please feel free to drop us a line, or tell us about your experience in our Slack channel.
Appendix: Test Configuration
All machines used for creating the scenarios are AWS EC2 machines.
Hardware
- Database nodes – 3 x i3.4xlarge
- Loader nodes – 3 x c5.4xlarge
Preconfiguration
- The default scylla.yaml was used and only one line was added to it at the end:
authenticator: PasswordAuthenticator - The database was prefilled with 50M default cassandra stress records using:
cassandra-stress write no-warmup cl=QUORUM n=50000000 -schema 'replication(factor=3)' -port jmx=6868 -mode cql3 native user=cassandra password=cassandra -rate threads=900 -pop seq=1..50000000
Loads
- OLTP load (ran on one loader machine):
cassandra-stress read no-warmup cl=QUORUM duration=20m -schema 'replication(factor=3)' -port jmx=6868 -mode cql3 native user=OLTP_user password=OLTP_user -rate threads=200 throttle=60000/s -pop 'dist=gauss(1..50000000,3)'
- OLAP load (ran on two loader machines):
cassandra-stress read no-warmup cl=QUORUM duration=10m -schema 'replication(factor=3)' -port jmx=6868 -mode cql3 native user=OLAP_user password=OLAP_user -rate threads=900 -pop 'dist=gauss(1..50000000,3)'
- Generic Load (each load ran on one loader machine):
cassandra-stress read no-warmup cl=QUORUM duration=20m -schema 'replication(factor=3)' -port jmx=6868 -mode cql3 native user=loadx_user password=loadx_user -rate threads=900 throttle=200000/s -pop 'dist=gauss(1..50000000,3)'- Note:
xis a variable; in operation it is replaced by the load number.
- Note: