




ReversingLabs are in the business of threat intelligence: “Any file. Any location. Any threat.” The only way to keep up with the constant and evolving nature of cybersecurity hazards is to automate at massive scale and to use the fastest, most scalable solutions possible, which ReversingLabs has done with their Titanium platform.
At ScyllaDB Summit 2019, ReversingLabs’ software architect Goran Cvijanovic explained how they integrated ScyllaDB into their Titanium platform to provide file reputation. In his talk, he focused on long-tail latencies, and how he could also optimize ScyllaDB’s compression to get the most out of his infrastructure’s storage.
There are files that are known to be benign. Others that are known to be malign. But what about files that are not yet known and classified? Those need to be analyzed swiftly, entered into the ReversingLabs database of over twenty billion known files, and that knowledge needs to be propagated quickly to catch any instances anywhere in a network or attached system: an email file server, a source code repository, a website, a laptop.
ReversingLabs Titanium Platform
ReversingLabs’ TitaniumCloud platform maintains a list, scoring the individual reputation of billions of goodware or malware files. It can also classify files as “suspicious” (for further investigation) or those whose status is currently unknown (unclassified). Their entire database tracks over 20 billion files, and contains detailed analyses for about half of those.
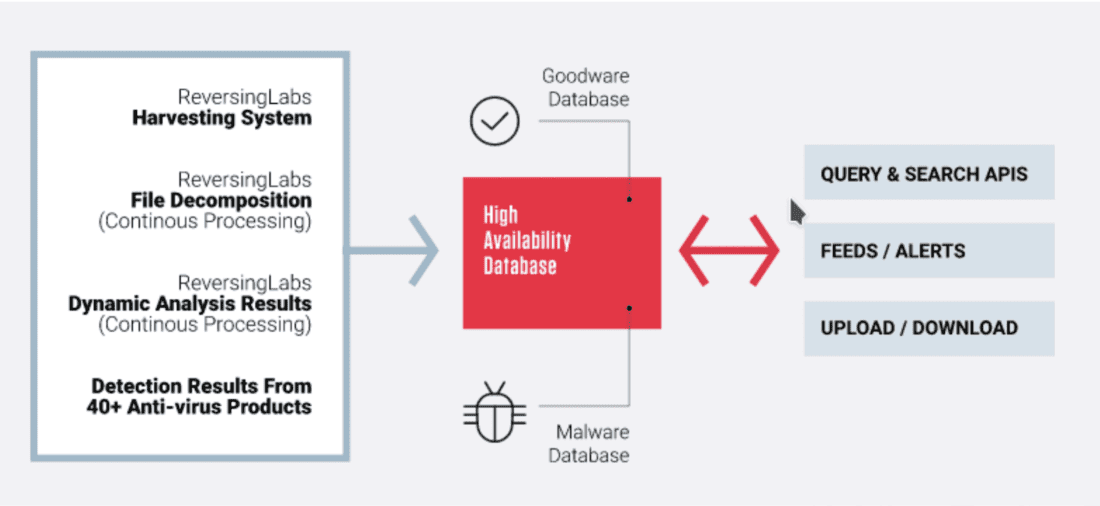 ReversingLabs maintains a database of tens of billions of known “goodware” (benign) and malware files and packages. Its harvesting system then has to determine how to handle new, unknown files using file decomposition and dynamic analysis.
ReversingLabs maintains a database of tens of billions of known “goodware” (benign) and malware files and packages. Its harvesting system then has to determine how to handle new, unknown files using file decomposition and dynamic analysis.
To test files, ReversingLabs does not run them, but performs static analysis — decomposing and reverse engineering them — hence the company name. Beyond that their dynamic analysis can execute files in a secure environment to observe behavior and discern what the file actually does. However, the dynamic analysis is computationally slow — taking minutes or hours of observation in test environments.
On top of these internal analyses, ReversingLabs also aggregates detection results from more than forty other antivirus partner companies. Information about ransomware, Advanced Persistent Threats (APTs), Common Vulnerabilities and Exposures (CVEs), plus financial and retail information sources.
The reputation analyses and metadata are stored in a highly available database system. Plus the actual files — more than one billion malware-infected files — have to be stored securely at ReversingLabs, currently spanning five petabytes of storage. Goran likened their secure storage system to the Ecto Containment Unit from the original Ghostbusters movie. “Who ya gonna call? You will call our APIs!”
ReversingLabs allows users to call more than 50 APIs providing information, from broad scans to narrow searches, plus feeds about known “malware in the wild.” ReversingLabs can also tailor specific feeds to different types of customers based on their vertical, such as banking.
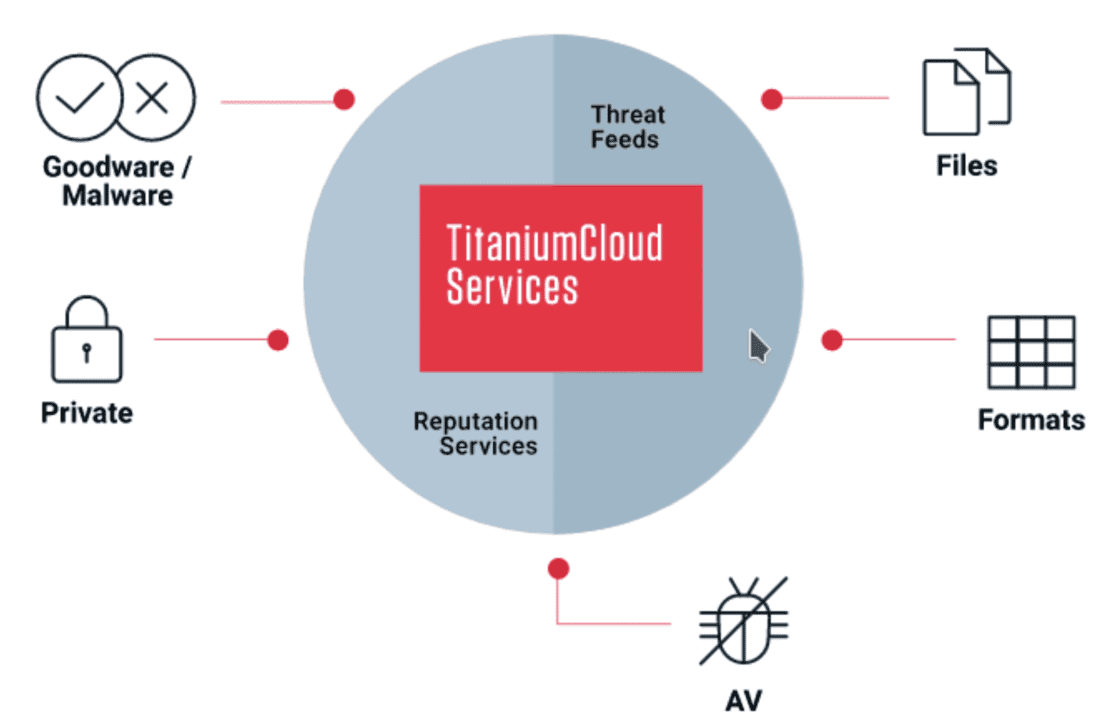
ReversingLabs TitaniumCloud Services provide more than 50 APIs to users, aggregating analysis of tens of billions of files, information from allowing them to build secure applications to detect malware in their own applications and networks.
To store the reputation data and metadata ReversingLabs built their own custom distributed key-value store over seven years ago using LSM trees, and written in C++. It makes more than 3 billion reads and 1 billion writes a day.
Since developing their original system ReversingLabs desired database independence. So they implemented a connection library to allow their applications to be connected transparently with different databases, given the following initial set of requirements:
- Key-value native protobuf format
- Lempel-Ziv 4 (LZ4) compression to reduce storage space
- Latencies <2 milliseconds
- Support record sizes ranging from 1KB to 500 MB
- High availability with replication
Goran noted size was a key issue. Because ReversingLabs deals with records that vary greatly — the “Variety” in the Three V’s of Big Data — they needed a database that could handle the various file sizes without causing significant problems.
From Proof of Concept to Production
ReversingLabs began a proof-of-concept (POC) on an 8-node ScyllaDB cluster to test two APIs. They appreciated the SSTable 3.0 “mc” format, which would save them dramatically on storage space. They also had to play with their chunk size in compression, increasing it to 64KB for large file sizes, which achieved a 49% increase in compression. Finally they tweaked their requirements a bit, to allow for storing data as a blob instead of a protobuf.
To improve performance, their inserts/updates and reads are all done at consistency level quorum (CL=QUORUM). To minimize impacts of repairs, their deletes are done instead with consistency level all (CL=ALL).
Another aspect of performance ReversingLabs needed to ensure was scaling to meet time-of-day traffic patterns. You can see below how their requests-per-hour more than double, from ~10 million requests per hour in the early morning, to over 26 million in the afternoon peak.
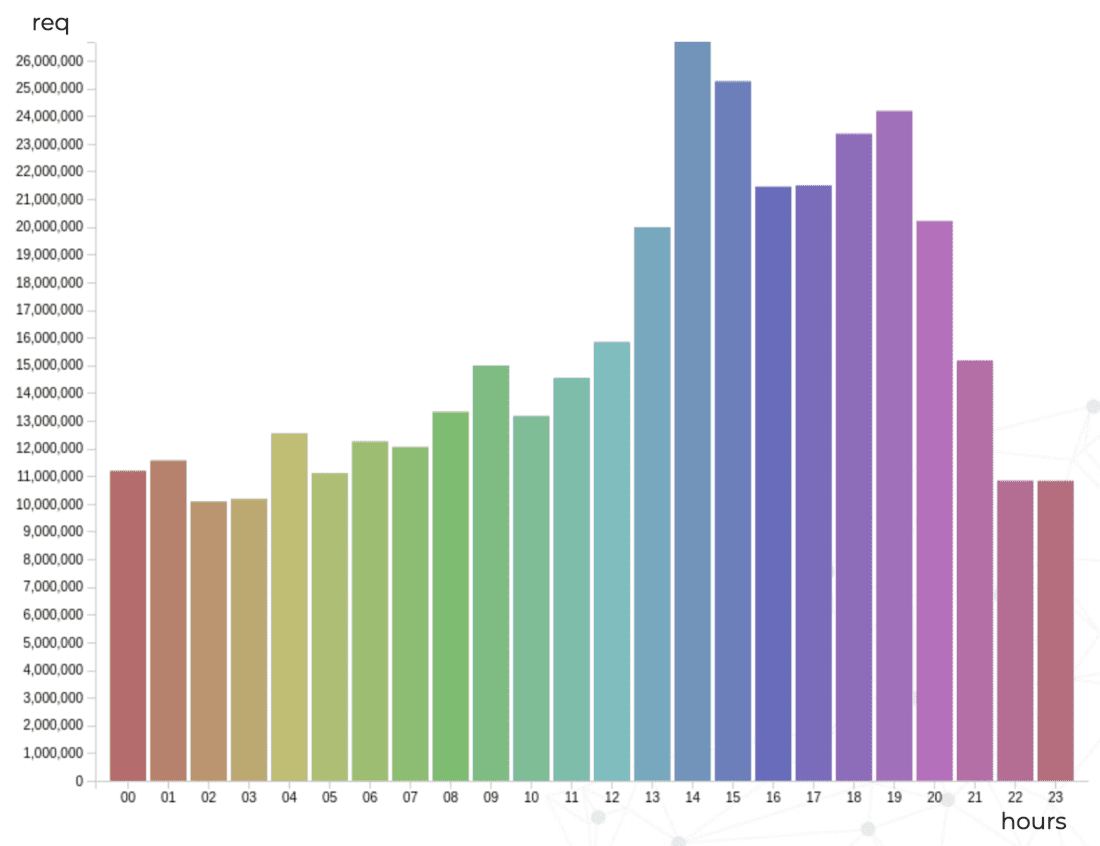
In end-to-end workflow testing (not only the database), average latencies were less than 120 milliseconds, and p99 latencies were 166 milliseconds. This included the user request, authentication process, request validation, the round-trip-time to query the database, to format and then finally send the response to the application, scaled to 32 workers all in parallel. Here were their performance metrics, with the average (p50) and long-tail (p99) latencies highlighted:
Test duration: 0:05:20
Samples count: 81645, 0.00 % failures
Average times: total 0.120, latency 0.120
Percentiles:
┌───────────────┬───────────────┐
│ Percentile, % │ Resp. Time, s │
├───────────────┼───────────────┤
│ 0.0 │ 0.080 │
│ 50.0 │ 0.118 │
│ 90.0 │ 0.135 │
│ 95.0 │ 0.142 │
│ 99.0 │ 0.166 │
│ 99.9 │ 0.232 │
│ 100.0 │ 0.331 │
└───────────────┴───────────────┘Within ScyllaDB itself, Goran was able to show file reputation queries with average writes latencies of <6 milliseconds and sub-millisecond average reads. For p99 (long-tail) latencies, ScyllaDB showed <12 millisecond writes, and <7 millisecond reads.
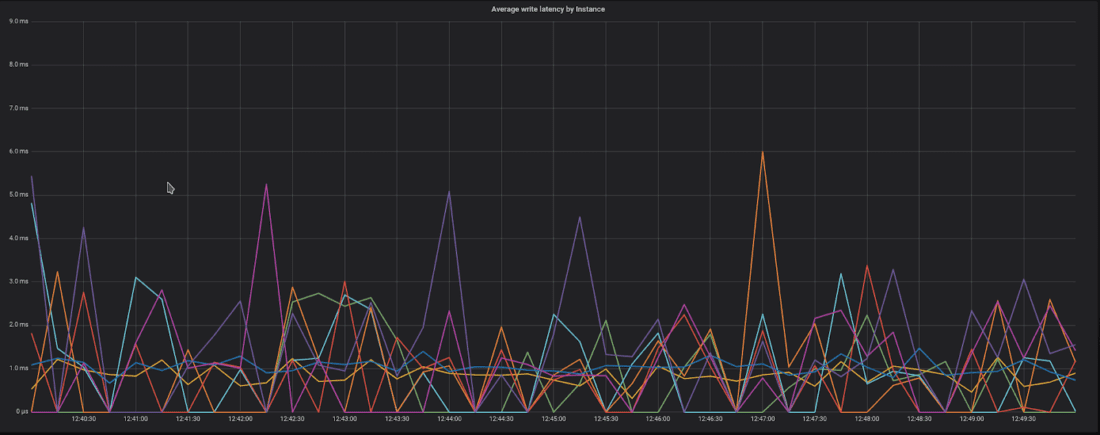
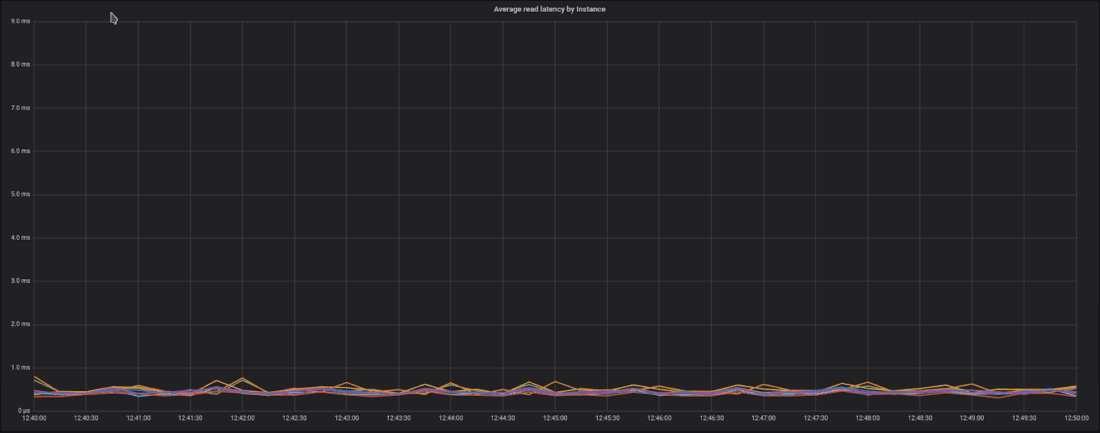
ScyllaDB Monitoring Stack graphs showing average write latencies (top) and reads (bottom), proving ScyllaDB more than capable of serving as a production-ready database for ReversingLabs.
These performance results proved ScyllaDB’s capabilities, and ReversingLabs shifted workloads onto ScyllaDB as a production system.
Lessons Learned
Goran advised users to “know your data,” and to test compression, with different chunk_size settings to get optimal storage savings balanced against performance. In their case, they were able to save on 49% of storage. (Find out more about compression in ScyllaDB in our blog.)
He also noted that repairs can impact cluster performance, so the way they implemented consistency level quorum allowed them to get fast reads and writes, and the deletions with consistency level all meant that they had less of a performance hit when it came time to conduct repairs. (Find out more about repairs in this course in ScyllaDB University.)
Goran also recommended NVMe disks in RAID0 configuration, a point ScyllaDB’s Glauber Costa reinforced in his talk on this and other tips for How to be Successful with ScyllaDB.
Lastly, we encourage you to view Goran’s talk in full below, and check out his slides on our Tech Talks page.






