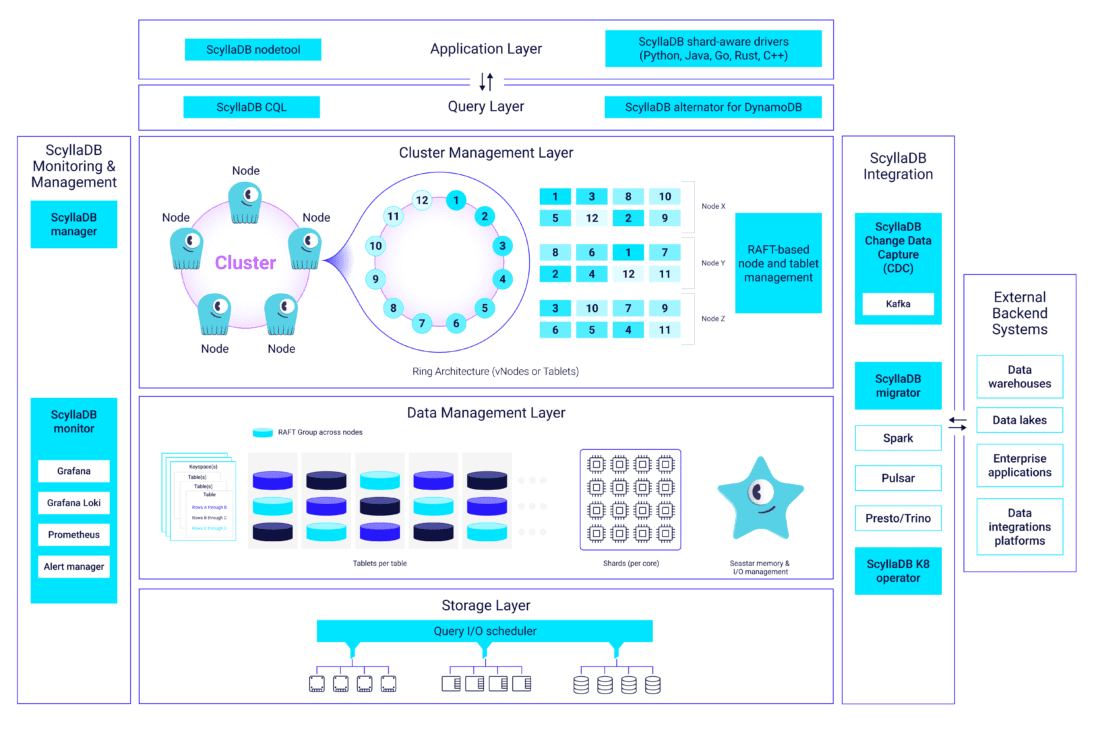
| Data Model |
ScyllaDB’s data model has led to its being called a “wide column” database, though we sometimes refer to it as a “key-key-value” database to reflect the partitioning and clustering keys. It is synonymous with Cassandra’s data model, and parallels can be drawn to the DynamoDB data model. Compatibility and extensions for all CQL commands can be found here in the Developer’s documentation. |
| Keyspace |
The top level container for data defines the replication strategy and replication factor (RF) for the data held within ScyllaDB. For example, users may wish to store two, three or even more copies of the same data to ensure that if one or more nodes are lost their data will remain safe. |
| Table |
Within a keyspace data is stored in separate tables. Tables are two-dimensional data structures comprised of columns and rows. Unlike SQL RDBMS systems, tables in ScyllaDB are standalone; you cannot make a JOIN across tables. |
| Partition |
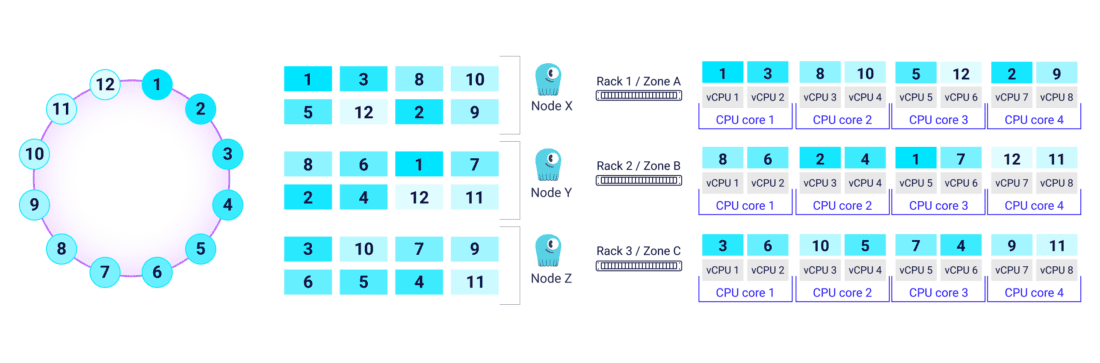
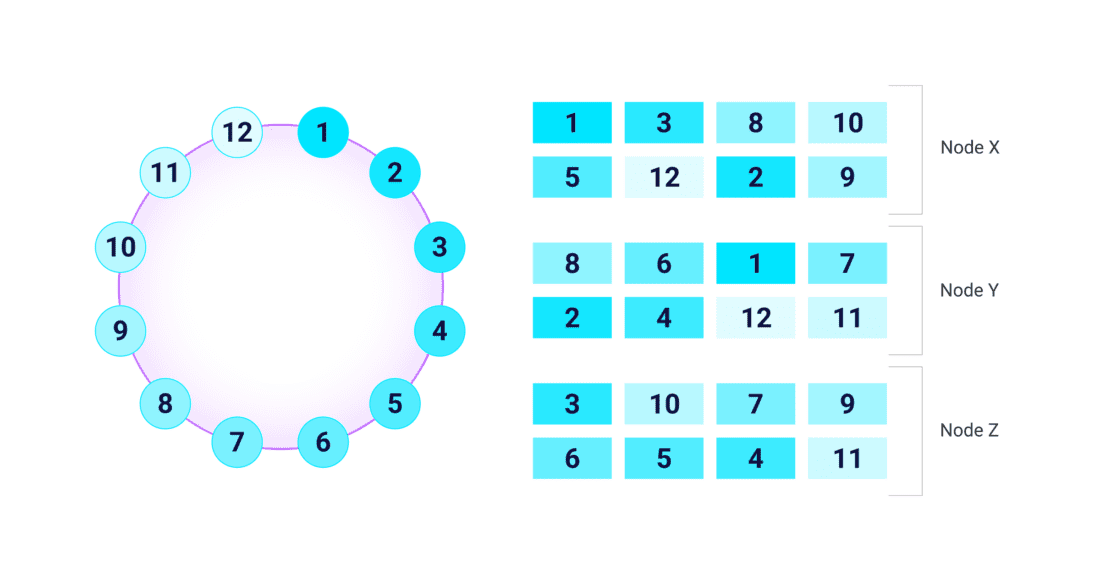
Tables in ScyllaDB can be quite large, often measured in terabytes. Therefore, tables are divided into smaller chunks, called partitions, to be distributed as evenly as possible across shards (vNodes or Tablets). With vNodes, these distributions are static and only established at bootstrap. However, with Tablets, these distributions can be continually adjusted to ensure proper balance and avoidance of hot spots. |
| Rows |
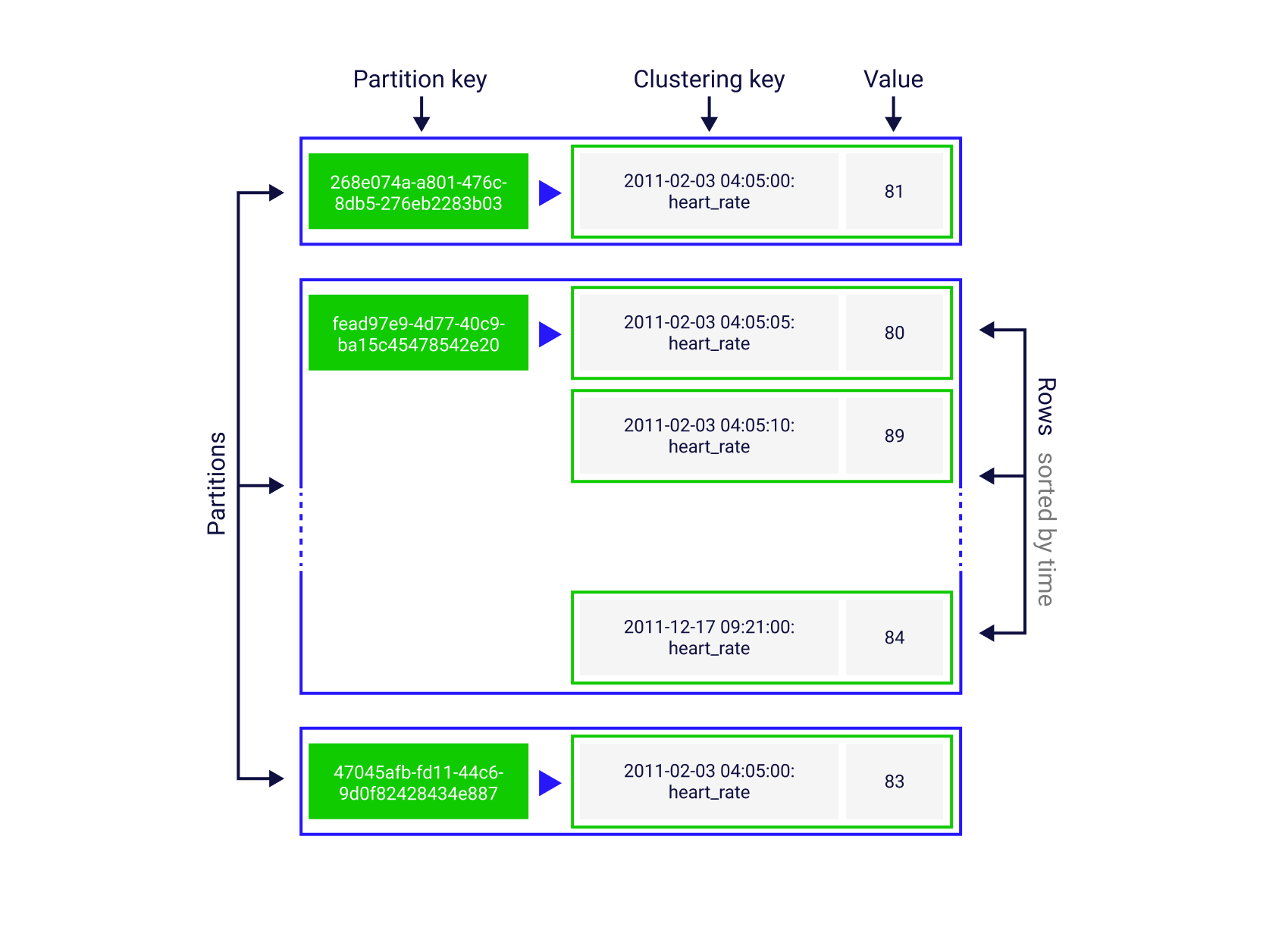
Each partition contains one or more rows of data sorted in a particular order, making ScyllaDB more efficient for storing “sparse data.” |
| Columns |
Data in a table row will be divided into columns. The specific row-and-column entry will be referred to as a cell. Some columns will be used to define how data will be indexed and sorted, known as partition and clustering keys. |
| Cell |
Each Row holds the data in Cells, a cell for each column. A Cell can be of any datatype, like TEXT or Integer, or a Collection of basic data types or other collections. Users can also create User-Defined Datatypes, enriching the table scheme further. |