









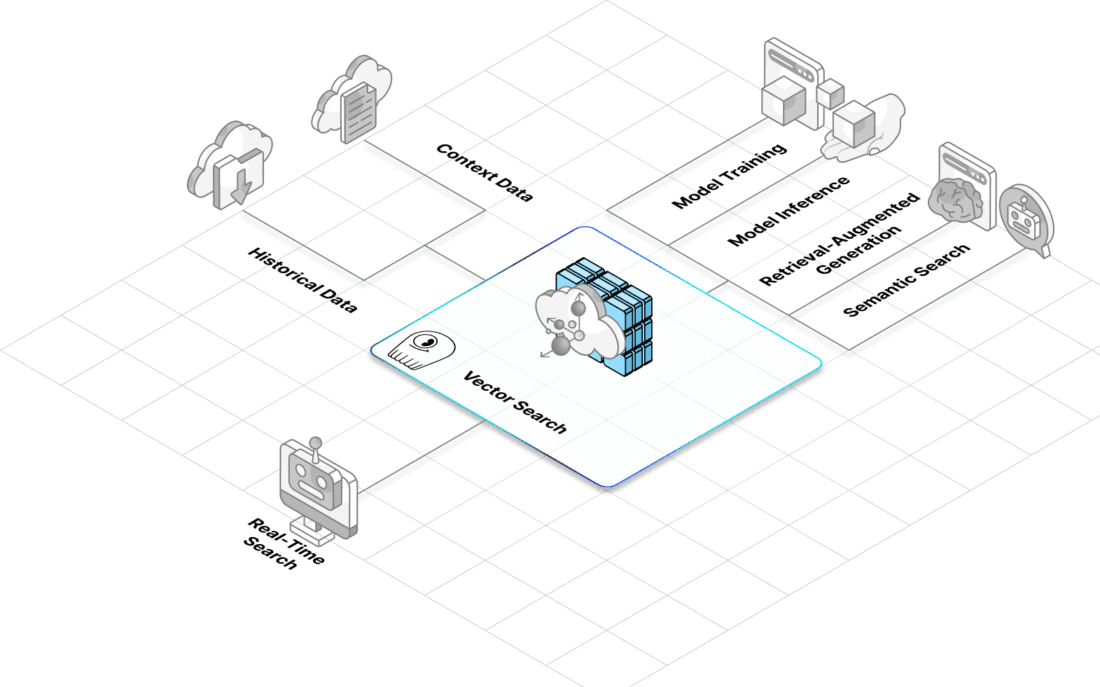

Serving 5 Million Features per Second
Tripadvisor uses ScyllaDB on AWS to power real-time ML personalization. At peak, they handle ~500K ops/sec with P99 latencies of 1-3 ms. Their feature store serves up to 5 million static features/sec and 0.5 million user features/sec.





