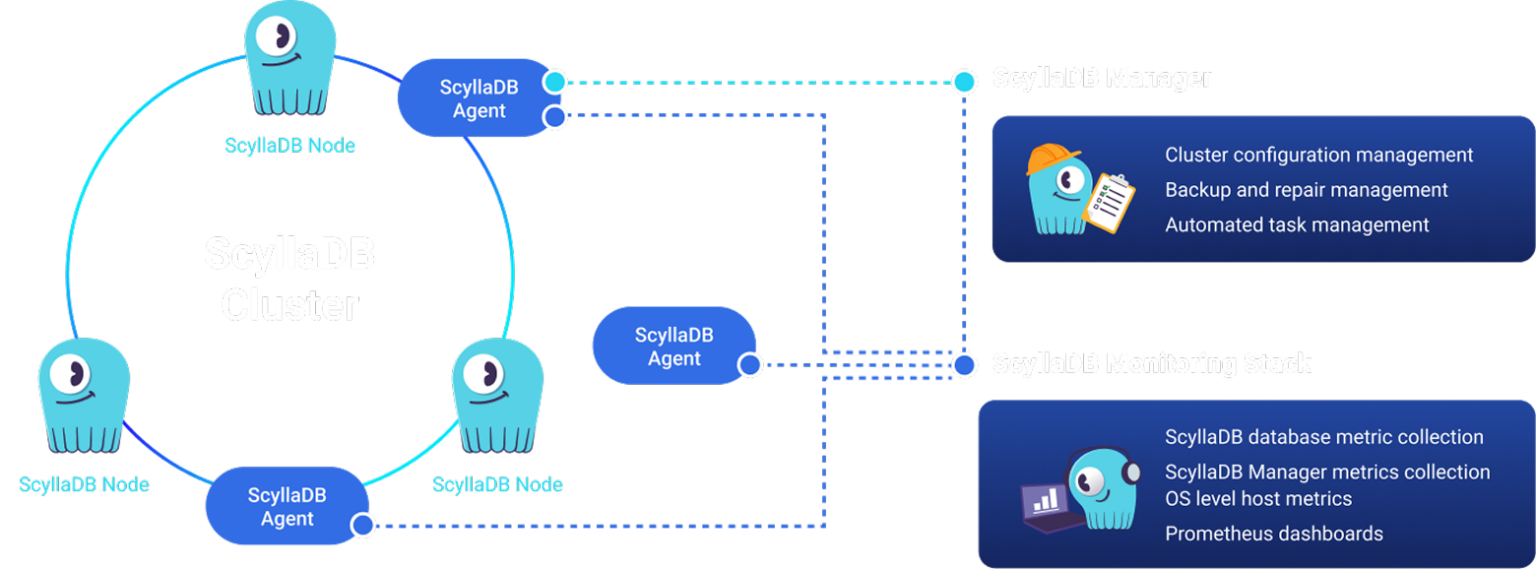
ScyllaDB Monitoring Stack is a bundle of four components based on de-facto industry-standard open-source systems (Prometheus metric collection, Alertmanager, Grafana dashboards, and Grafana Loki log aggregation) that can be deployed as containers or directly onto a host. It also collects aggregated NoSQL performance metrics, logs and events through ScyllaDB Manager. ScyllaDB Monitoring Stack supports ScyllaDB Enterprise and ScyllaDB Cloud customers.
Alertmanager Metric Collector
Grafana Dashboards
Log Aggregation System
The ScyllaDB Monitoring Stack empowers DevOps, infrastructure operations teams, and database administrators to quickly find and fix issues impacting the performance of their ScyllaDB clusters. Teams can drill down from high-level to detailed NoSQL dashboards.
Grafana Dashboards
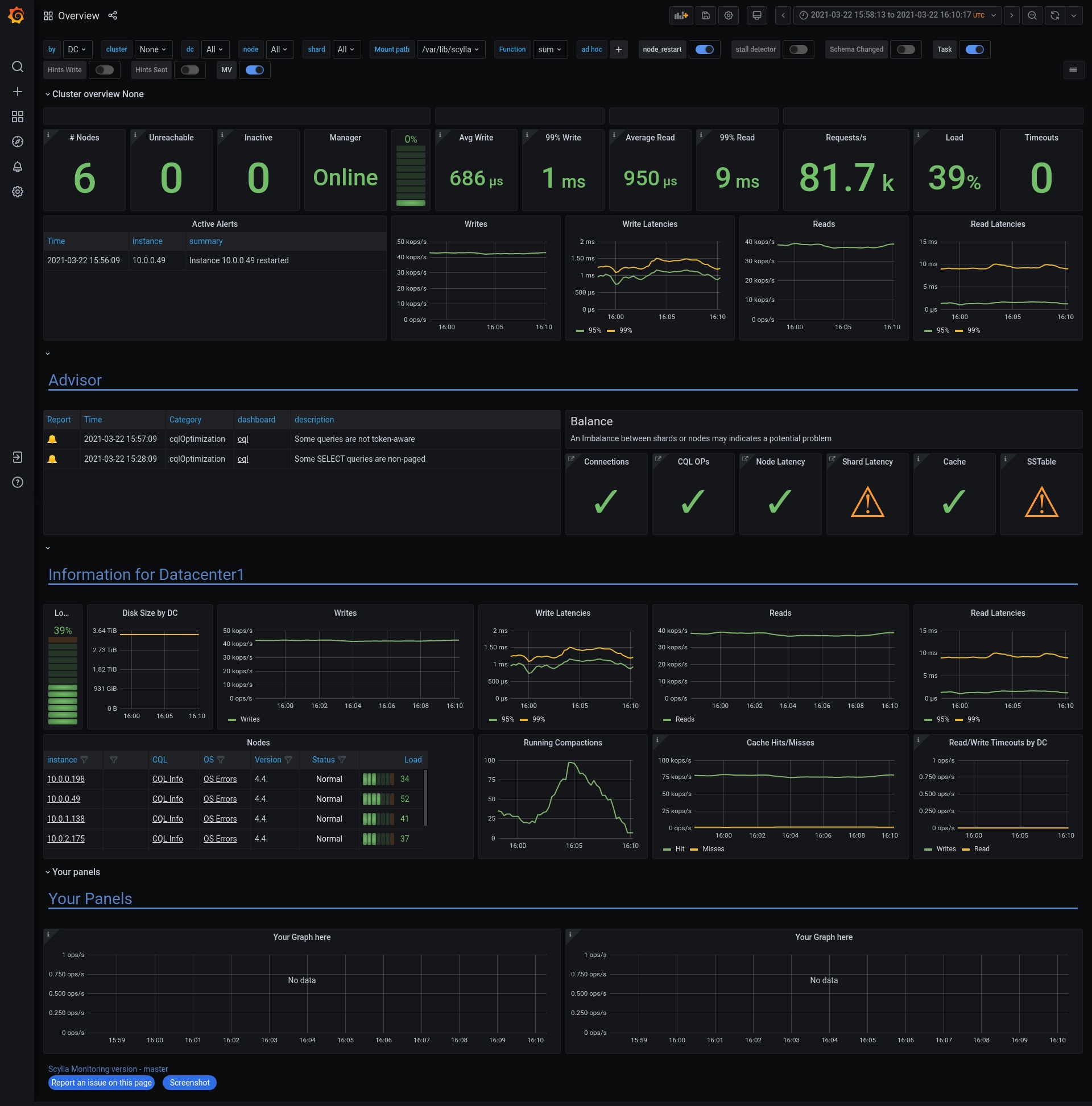
ScyllaDB Monitoring Stack includes a set of pre-built dashboards to monitor your ScyllaDB cluster in real-time. Hundreds of different NoSQL metrics populate dashboard components for your operations team to review historical trends and identify anomalous behavior in your cluster.
Overview – General overview of cluster health
Advanced –In-depth detailed look at IO queues, task groups, and internal errors at the cluster level
Detailed – In-depth detailed look at reads/writes, timeouts and errors, replicas, cache, materialized views, lightweight transactions, change data capture, memory and compactions at the cluster level
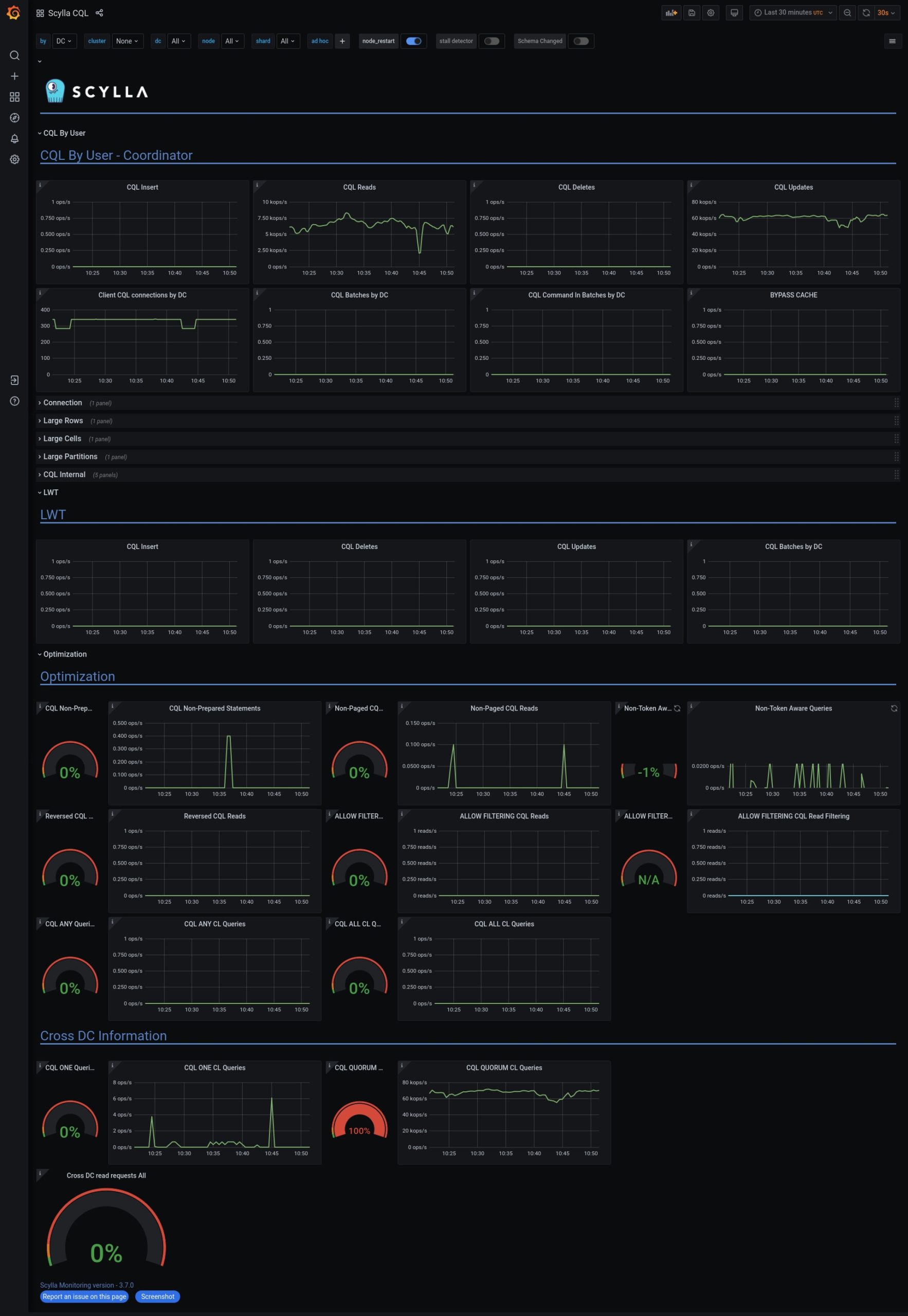
ScyllaDB CQL – Detailed CQL metrics pointing out trouble areas and optimizations such as shard-aware drivers, non-paged queries, etc.
OS Metrics– Metrics reported by the node_exporter agent, such as storage and network
Alternator – Track usage of ScyllaDB’s DynamoDB-compatible API
Tips and Tricks for Maximizing ScyllaDB Performance
A Guide to Getting the Most from Your ScyllaDB Database
The ScyllaDB CQL dashboard helps teams identify query issues, poor data models, and unexpected driver behavior. Teams can quickly see, for example, if their cluster is being hit by a lot of heavy queries with full table scans where “ALLOW FILTERING” is enabled.
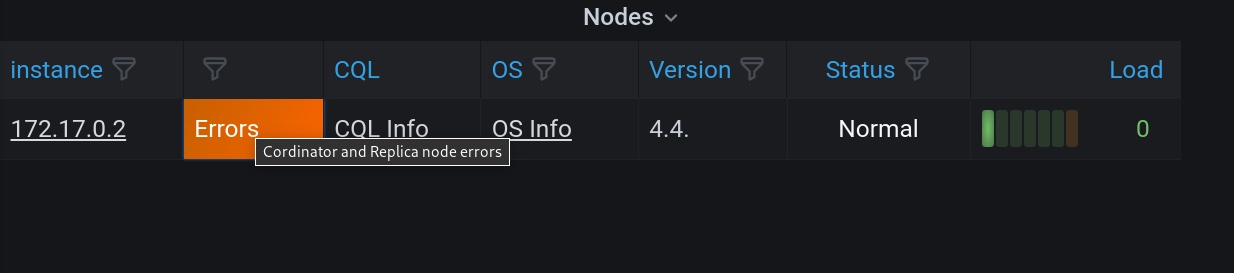
Cluster Health
Quickly identify nodes in your cluster and drill down to detailed OS-level metrics such as CPU utilization, IO, and Errors. Teams can quickly decide if nodes need to get rebooted or if the team needs to perform a rolling upgrade on nodes running old versions.
Alerting
Set conditional alerts for your ScyllaDB cluster within the alert manager so your team knows when incidents arise. Out-of-the-box alert triggers are included for conditions such as:
Low free disk space on the root partition
Node status changes availability status
CQL availability on a node
Chart Annotations
Database administrators are able to annotate heavy tasks such as backup or repair start and finish times. This helps cross-functional teams visually understand why there may be additional latency or reduced throughput at particular times.
Advisor
The Advisor is a new concept in ScyllaDB Monitoring. It identifies potential problems and notifies you of them. The Advisor section in the Overview dashboard has two parts. One is for various issues detected, like unprepared statements. The second is an indication of how balanced the system is. When the cluster works properly, all nodes and shards should act the same. An outlier shard could be a result of a problem. For example, if the number of CQL connections per shard varies between shards, it indicates a driver configuration issue.
Resources
Learn More about Combining the Power of ScyllaDB and Kubernetes
documentation
ScyllaDB Monitoring
Read the documentation for additional information to get started.