




Tubi (tubitv.com) is a place where you can watch movies for free. No credit card. No sign up. No subscription. It is an industry leader that found its footing in the market of ad-sponsored video on demand (AVOD). Founded in 2014, Tubi established its niche building relationships directly with studios such as Lionsgate, Paramount, Warner Bros., and MGM that do not have their own streaming services. It has grown its user base to 25 million users — a 25% growth in the past 6 months — while increasing its viewing time 160% year-over-year.
Internet-based over-the-top (OTT) streaming video services have revolutionized the world of home entertainment ever since Netflix began its Internet streaming services in 2007. The push to streaming video accelerated even more with the advent of mobile 4G services beginning in 2009. The past decade has witnessed a revolution, where people have come to expect being able to watch their favorite shows wherever they are, on whatever device they have available, from giant flatscreen TVs at home to their laptops, tablet devices or phones on the go.
The promise of over-the-top services was to enable people to “cut the cord” on their cable provider, due to monthly bills weighing in around $100 per household. However, when all the various available subscriber-based video-on-demand (SVOD) services are combined, the numbers rapidly add up. You could literally spend over $500 a month for the ability “to watch everything.”
This plethora of subscriber-based services today, while giving consumers more choices and more content than ever before, is directly at odds with the fact that 87% of consumers originally cut the cord to save money.
Because of this, the AVOD model — an analog to the same model that sustained commercial broadcast television for decades — has also proven viable as a business for the Internet era. Indeed, industry giant YouTube recently revealed it brings in $15 billion in ad revenue annually, proving without a doubt that users are quite willing to endure the occasional interruption of interspersed commercials to avoid a monthly bill while avidly enjoying their favorite content.
Tubi Talks Personalization at ScyllaDB Summit
Alexandros Bantis, Senior Backend Engineer at Tubi, spoke at ScyllaDB Summit 2019 in San Francisco, providing insights into the personalization service infrastructure required to support Tubi’s 15,000 titles and tens of millions of users. He began by stating his belief, “I think Scala is awesome. I think ScyllaDB is awesome. And when you put them together, you get awesome squared.”
![]()
“I think Scala is awesome. I think ScyllaDB is awesome. And when you put them together, you get awesome squared.”
— Alexandros Bantis
“Our mission depends on people being able to find the movie that they like.” Citing research from Netflix, Alexandros pointed out consumers will spend only about a minute finding a title they want to watch before they give up. Tubi is not unique in having to cater to the ubiquitous modern “right now” consumer.
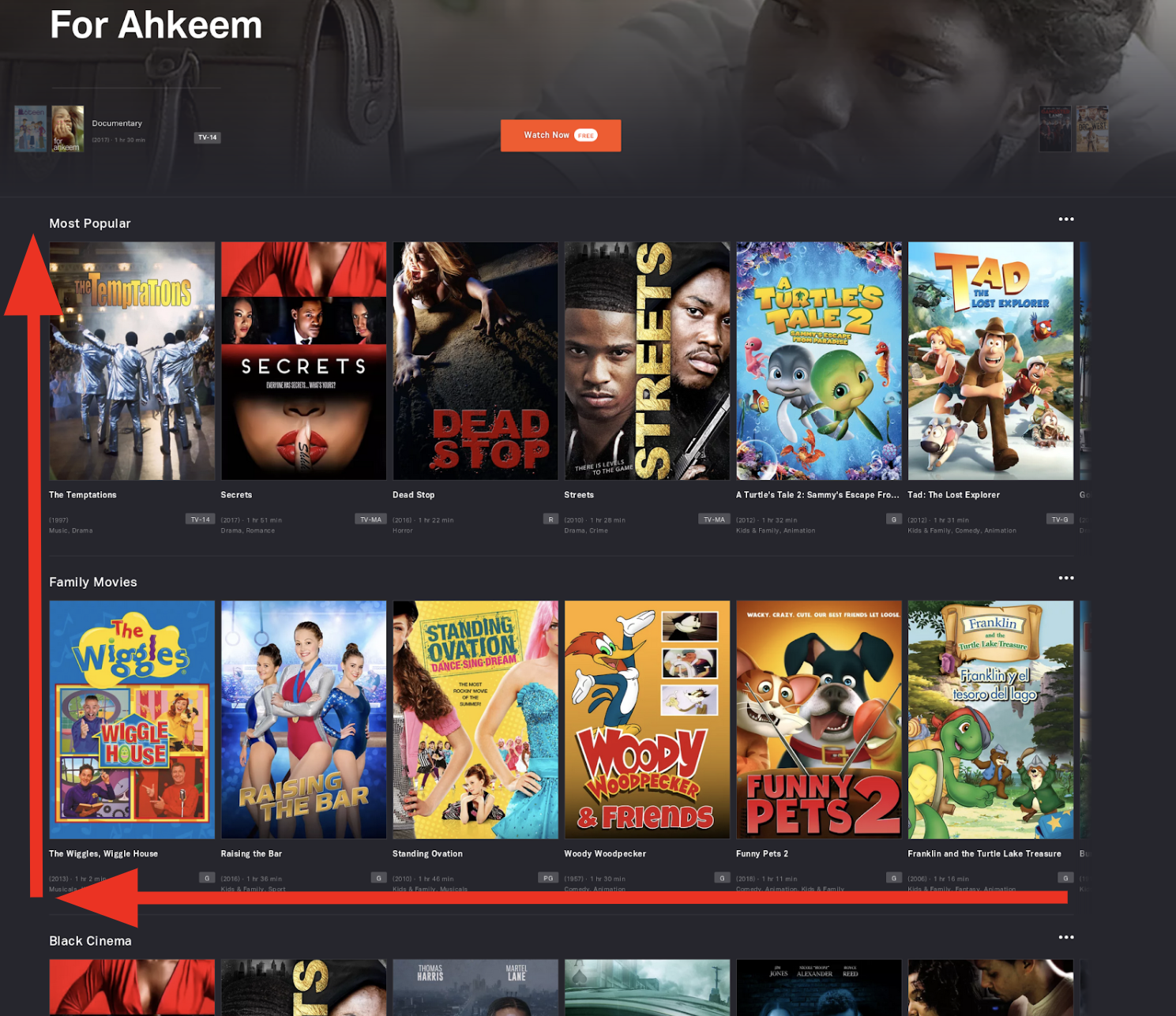
Tubi’s Machine Learning algorithms try to identify the movies the user wants to watch, and shifts them left and up in the user interface so they are the most visible recommendations to the user. The system has less than a second to select, sort and display the top movies for each user out of over 15,000 titles available on Tubi’s ad-supported video on demand (AVOD) service.
The Old Way: Apache Spark and Redis
Alex described what Tubi’s architecture looked like eighteen months prior, when he first began on the project. It was comprised of a monolithic homepage service written in Node.js, plus an analytics service, an experiment service, and a machine learning data pipeline in Apache Spark that fed into a Redis database.
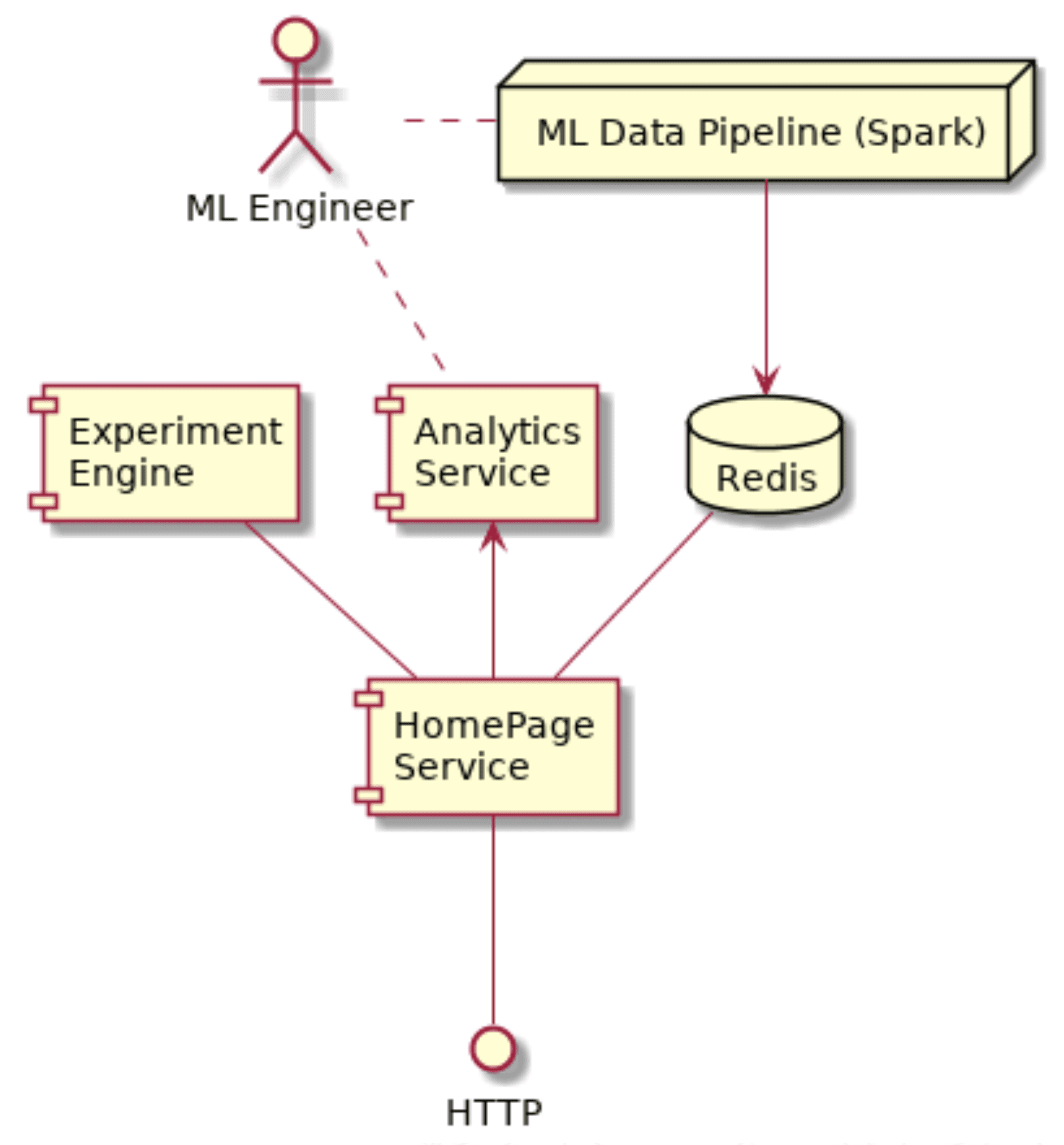
Tubi’s original HomePage Service, written in Node.js, was connected to a Redis database backend that was manually fed by an Apache Spark ML data pipeline.
In order for a Machine Learning engineer to run an A/B experiment, they first had to write the model in Apache Spark, which then wrote the data to Redis. The engineer then had to update the code in the HomePage Service application. However, the ML engineer couldn’t make changes to the production code directly. They had to work with the backend engineering team. When the experiment ran, the engineer also had to update the configuration on the separate Node.js experiment engine, push the changes into production, and restart. And when the experiment ended, the same process needed to be repeated in reverse.
ScyllaDB: Solving for Scalability “Usual Suspects”
Much of this architecture made sense when Tubi was a small startup. But as it scaled the system began to require many of the “usual suspects”:
- Better fault tolerance
- Lower latency
- Higher throughput
- More maintainable code
When Alexandros began working on the project, the time to deliver a personalized page of video recommendations to the user took about 300 milliseconds. Over the course of his re-architecture using ScyllaDB and Scala he was able to get that optimized to about 10 milliseconds for the P95. The code became more stable and more maintainable. However, while reliable speed and performance are usually the main reasons people adopt ScyllaDB for their NoSQL database, that wasn’t Tubi’s primary problem.
Tubi’s Challenge Optimizing Machine Learning
The key issue for Tubi was not just technological, per se. It was the combination of people, process and technology. The ML engineers required many round-trips of manual communications with the backend teams in order to conduct their A/B tests. Every time they wanted to run an experiment, they had to have typical exchanges of “Please” and replies of “I’ll get right on it.” Code changes. Pull requests and PR reviews. Unit tests. Deployments to staging. Staging to production. “It was a very heavyweight process to conduct experiments.”

Tubi’s manual process to implement ML experimentation required multiple back-and-forth cycles between the ML engineer and the backend team. Such process and cycle times were chronically hampering A/B testing implementation.
The New Way of Machine Learning and NoSQL: Scala & ScyllaDB
In their new architecture everything having to do with personalization was extracted out into a new application named Ranking Service, with ScyllaDB as an embedded component, and a new experiment engine named Popper. Both were written as Scala/Akka applications.
![]()
In this new method the ML engineer still creates the model in Apache Spark. It automatically gets published to the application via AWS Kinesis and Apache Airflow. The engineer doesn’t have to do anything else code-wise other than create his model. Instead there is a UI in the Popper Engine to schedule the experiment to run in the future. The job will automatically start running at that appointed date and time, and similarly automatically end when scheduled.
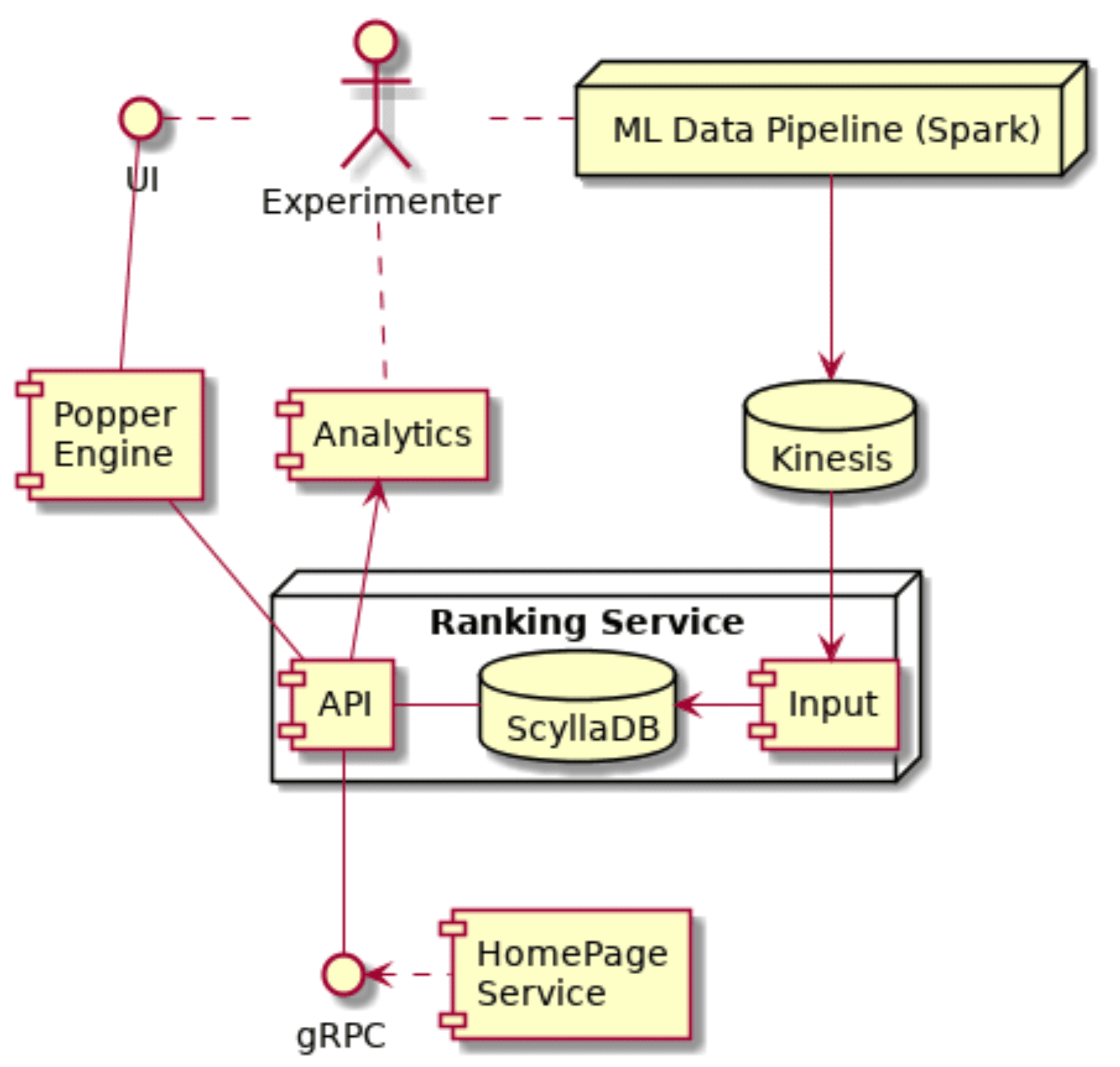
Tubi’s new Ranking Service, which embeds ScyllaDB, communicates to its ML Popper Engine via Lightbend’s Scala/Akka platform. Meanwhile, ML data pipelines in Apache Spark are deployed to ScyllaDB via AWS Kinesis and Apache Airflow.
This new data architecture means the ML engineer doesn’t have to talk to anyone or go through manual permission cycles and schedules. No code changes. No PRs. No unit tests. No staging. As Alexandros noted, “It just works.”
When Ranking Service now wants to create a home page for a user, it asks “Is this page under experimentation?” If it is, then it goes to the Popper Engine to gather the necessary information to conduct the experiment. “Do I do the A? Or do I do the B?” Though if it’s not under experiment, it can resolve the page directly. After creating the page for the user, an event is published to analytics.
Beyond ScyllaDB and Kinesis, what made the difference for this new system was testing tools: Ammonite for Scala scripting, Docker and Akka itself. Plus use of gRPC and protobufs.
Alexandros then turned to talk about data and domain modeling. Scala is built on top of the JVM. So while it is a different programming language, it shares the same runtime platform. For often fast-moving startups, Alexandros recommended, “a good place to slow down is in your data model.” While getting it right is not easy, the payoff is huge.
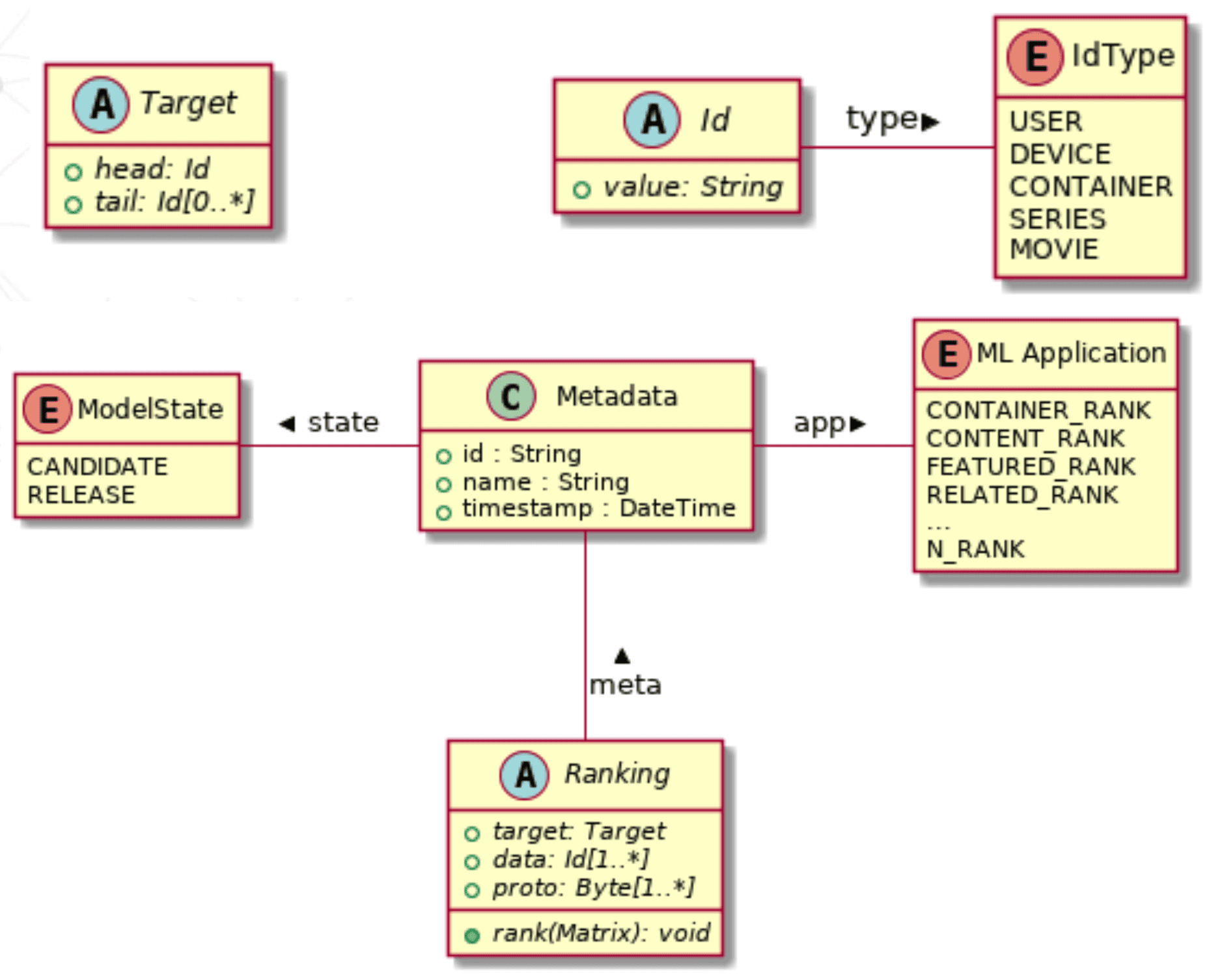
Tubi’s data model for its Ranking Service.
The Id (center top box in the illustration above) is the atomic unit of Tubi’s ranking service. A target (upper left) can be specified as many different things, such an individual user, or a target demographic, such as all users of a certain device type in a zip code. A ranking (bottom) is data and metadata associated with a model and application associated with a target. The ModelState (lower left) states whether a ranking is a release (in production) or a candidate (for purposes of experimentation). So experimentation is a first class citizen of the data model.
With this data model in place, this is what the gRPC message looks like:

This is what the Scala code looks like:
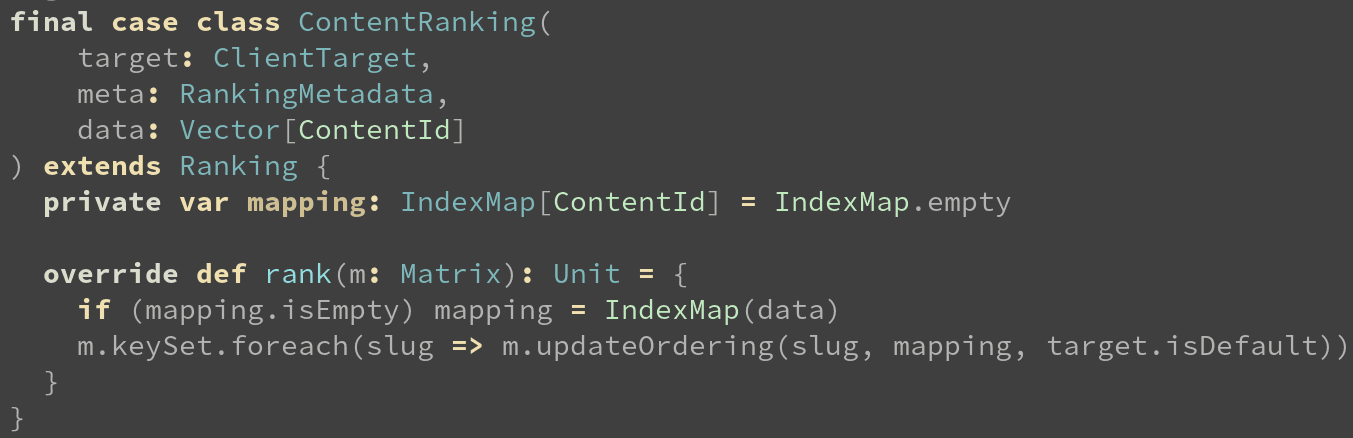
And this is what the ScyllaDB CQL table schema looks like:

So once they have the schema in place, everything flows together. It allows Tubi to leverage the type system in Scala, allowing extensions and changes to be very low cost in terms of additional development.
Hard Problems Solved by ScyllaDB NoSQL and Scala: Distribution and Concurrency
In terms of the Popper engine (also written in Scala/Akka), Alexandros noted concurrency is “super hard,” citing the following quote by Mathias Verraes:
There are only two hard problems in distributed systems: 2. Exactly-once delivery 1. Guaranteed order of messages 2. Exactly-once delivery.
— Mathias Verraes
Alexandros made the analogy, “Thinking about concurrency is like thinking about distributed systems. Most of everybody here who’s using ScyllaDB works with distributed systems but you don’t have to think about it because ScyllaDB has abstracted that out for you.”
Similarly, in Alexandros’ view Scala provides nice abstractions for Java concurrency. Even with those abstractions, it is very hard. However, just as you don’t need to worry about distributed systems because ScyllaDB has abstracted that complexity, you don’t need to worry about concurrency with Scala because it has done the hard work for you.
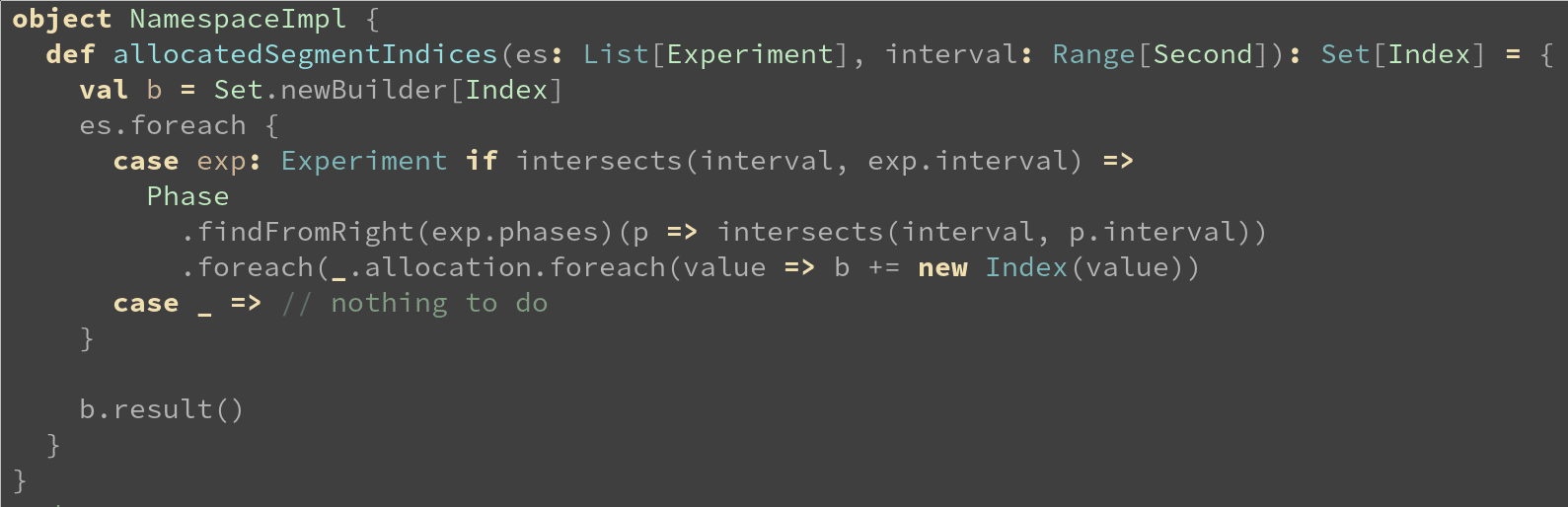
Looking at the Namespace for the Popper Engine, he noted that it has mutable state, both for experiments (running and scheduled), and segments, which can be owned by experiments.

A simple example of what an object-oriented Namespace in the Popper Engine can look like.
Normally in Java to maintain state you would obtain a lock, have multiple threads, and put it in a queue waiting for its turn to access the state, during which time it is eating up CPU.
Alexandros notes how Scala, being a polyglot language — supporting functional, object-oriented, or actor-model programming paradigms — means that you can quickly end up with “spaghetti code” if you try to mix all of those together.
So he splits out different design patterns. In the example above he has an object with state and methods to operate on the state.
Yet Popper also has functions, which have no side effects and referential transparency:
An example of a function in the Popper Engine written in Scala.
But Scala also supports an Actor context, where you can pretend all of your code is running in a single thread:
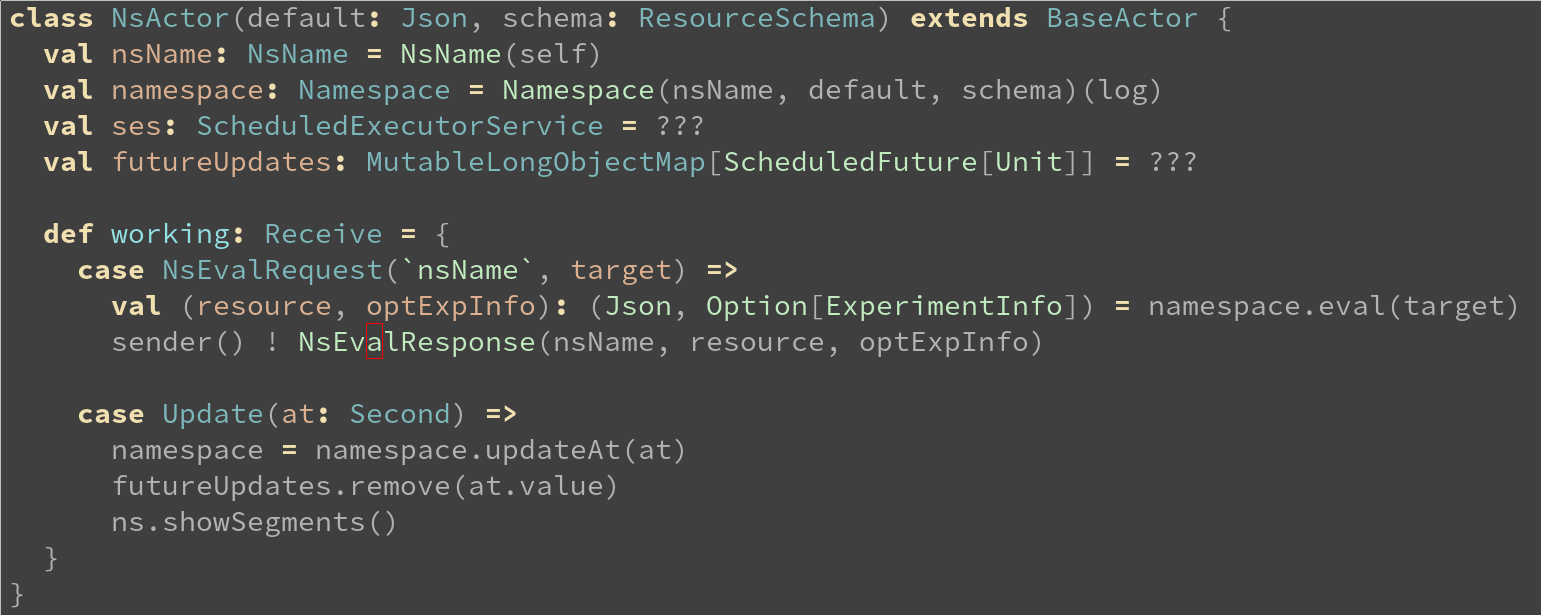
Actor context for the Popper Engine, also written in Scala.
To effectively use these different design paradigms, developers should want to keep them in different namespaces and leverage the type system to model a domain.
Developers will also need to understand the JVM and its proclivities, such as Garbage Collection. But, Alexandros pointed out, you may at times also need to drop down to mutable states and primitives. You can do a lot with Scala, so it is best to know and set your boundaries.
ScyllaDB on AWS
Tubi runs its server cluster on 4x i3.4xlarge instances with a replication factor of 3. This is connected to two clients supporting its Popper and analytics API, and two supporting data input from Kinesis. All four of these clients run on c5.2xlarge instances.
One of the many things that Alexandros appreciates about ScyllaDB is its lack of JVM. “I know how to do JVM tuning but I don’t want to spend my time doing this. I want to spend my time building applications.”
“I know how to do JVM tuning but I don’t want to spend my time doing this. I want to spend my time building applications.”
— Alexandros Bantis
Another aspect of ScyllaDB he appreciated was the read latency at peak. Tubi is often getting bursty traffic. Even during those peak times he was seeing sub-millisecond average latencies and P99s of 4 to 8 milliseconds. “So it’s super fast.”
Tips from Alexandros
Alexandros left the audience with a series of “tips from the trenches.” But if you want to find out what they were, you’ll have to watch the full video. Feel free to view it below, or check out his talk and his slides on our Tech Talks page.



