




In the first part of this blog we’ve learned a bit about compression theory and how some of the compression algorithms work. In this part we focus on practice, testing how the different algorithms supported in ScyllaDB perform in terms of compression ratios and speeds.
I’ve run a couple of benchmarks to compare: disk space taken by SSTables, compression and decompression speeds, and the number and durations of reactor stalls during compression (explained later). Here’s how I approached the problem.
First we need some data. If you have carefully read the first part of the blog, you know that compressing random data does not really make sense and the obtained results wouldn’t resemble anything encountered in the “real world”. The data set used should be structured and contain repeated sequences.
Looking for a suitable and freely available data set, I found the list of actors from IMDB in a nice ~1GB text file (ftp://ftp.fu-berlin.de/pub/misc/movies/database/frozendata/actors.list.gz). The file contains lots of repeating names, words, and indentation — exactly what I need.
Now the data had to be inserted into the DB somehow. For each tested compression setting I created a simple table with an integer partition key, an integer clustering key, and a text column:
create table test_struct (a int, b int, c text, primary key (a, b)) with compression = {...};Then I distributed ~10MB of data equally around 10 partitions, inserting it in chunks into rows with increasing value of b. 10MB is more than enough — the tables will be compressed in small chunks anyway.
Each of the following benchmarks was repeated for each of some commonly used values for chunk length: 4KB, 16KB, 64KB. I ran them for each of the compression algorithms plus when compression was disabled. For ZStandard, ScyllaDB allows to specify different compression levels (from 1 to 22); I tested levels 1, 3, 5, 7, and 9.
Space
The first benchmark measures disk space taken by SSTables. Running a fresh ScyllaDB instance on 3 shards I inserted the data, flushed the memtables, and measured the size of the SSTable directory. Here are the results.
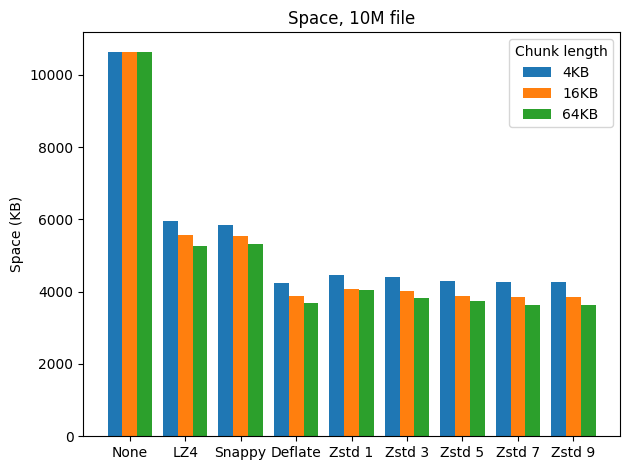
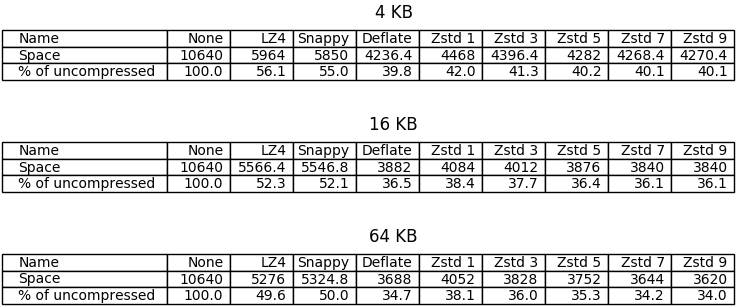
The best compression ratios were achieved with DEFLATE and higher levels of ZStandard. LZ4 and Snappy performed great too, halving the space taken by uncompressed tables when 64 KB chunk lengths were used. Unfortunately the differences between higher levels of ZStandard are pretty insignificant in this benchmark, which should not be surprising considering the small sizes of chunks used; it can be seen though that the differences grow together with chunk length.
Compression speed
The purpose of the next benchmark is to compare compression speed. I did the same thing as in the first benchmark, except now I measured the time it took to flush the memtables and repeated the operation ten times for each compression setting. On the error bar below, dots represent means and bars represent standard deviations.
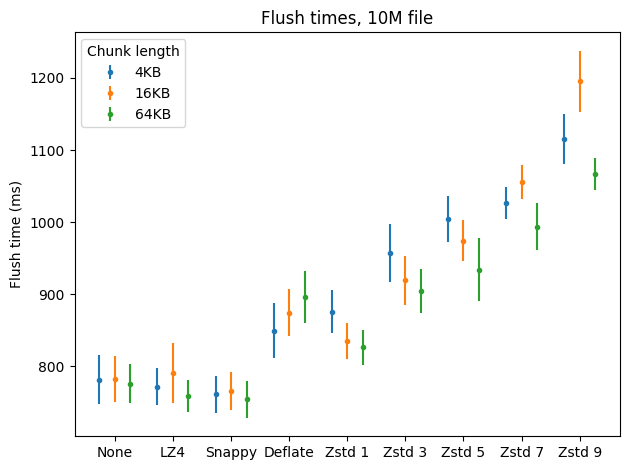
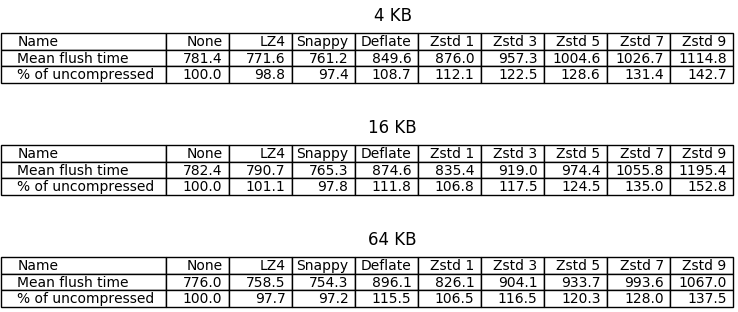
What I found most conspicuous was that flushing was sometimes faster when using LZ4 and Snappy compared to no compression. The first benchmark provides a possible explanation: in the uncompressed case we have to write twice the amount of data to disk than in the LZ4/Snappy case, and writing the additional data takes longer than compression (which happens in memory, before SSTables are written to disk), even with fast disks (my benchmarks were running on top of an M.2 SSD drive).
Another result that hit my eye was that in some cases compression happened to be significantly slower for 16KB chunks. I don’t have an explanation for this.
It looks like ZStandard on level 1 put up a good fight, being only less than 10 percentage points behind LZ4 in the 64KB case, followed by DEFLATE which performed slightly worse in general (the mean was better in the 4KB case, but there’s a big overlap when we consider standard deviations). Unfortunately ZStandard became significantly slower with higher levels.
Decompression speed
Let’s see how decompression affects the speed of reading from SSTables. I first inserted the data for each tested compression setting to a separate table, restarted ScyllaDB to clean the memtables, and performed a select * from each table, measuring the time; then repeated that last part nine times. Here are the results.
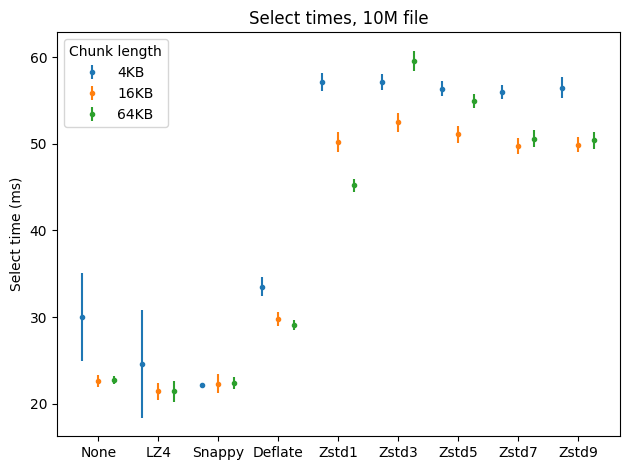
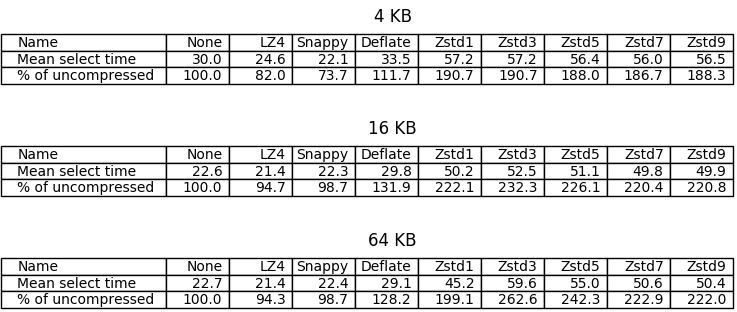
In this case ZStandard even on level 1 behaves (much) worse than DEFLATE, which in turn is pretty close to what LZ4 and Snappy offer. Again, as before, reading compressed files is faster with LZ4/Snappy than in the uncompressed case, possibly because the files are simply smaller.
Interestingly, using greater chunks makes reading faster for most of the tested algorithms.
Reactor stalls
The last benchmark measures the number and length of reactor stalls. Let me remind you that ScyllaDB runs on top of Seastar, a C++ framework for asynchronous programing. Applications based on Seastar have a sharded, “shared-nothing” architecture, where each thread of execution runs on a separate core which is exclusively used by this thread (if we take other processes in the system out of consideration). A Seastar programmer explicitly defines units of work to be performed on a core. The machinery which schedules units of work on a core in Seastar is called the reactor.
For one unit of work to start, the previous unit of work has to finish; there is no preemption happening as in classical threaded environment. It is the programmer’s job to keep units of work short — if they want to perform a long computation, then instead of doing it in a single shot, they should perform a part of it and schedule the rest for the future (in a programming construct called a “continuation”) so that other units have the chance to execute. When a unit of work computes for an undesirably long time, we call that situation a “reactor stall”.
When does a computation become “undesirably long”? That depends on the use case. Sometimes ScyllaDB is used as a data warehouse, where the number of concurrent requests to the database is low; in that case we can give ourselves a little leeway. Many times ScyllaDB is used as a real-time database serving millions of requests per second on a single machine, in which case we want to avoid reactor stalls like the plague.
The compression algorithms used in ScyllaDB weren’t implemented from scratch by ScyllaDB developers — there is little point in doing that. We are using the available fantastic open source implementations often coming from the authors of the algorithms themselves. A lot of work was put into these implementations to make sure they are correct and fast. However, using external libraries comes with a cost: we temporarily lose control over the reactor when we call a function from such a library. If the function is costly, this might introduce a reactor stall.
I measured the counts and lengths of reactor stalls that happen during SSTable flushes performed for the first two benchmarks. Any computation that took 1ms or more was considered a stall. Here are the results.
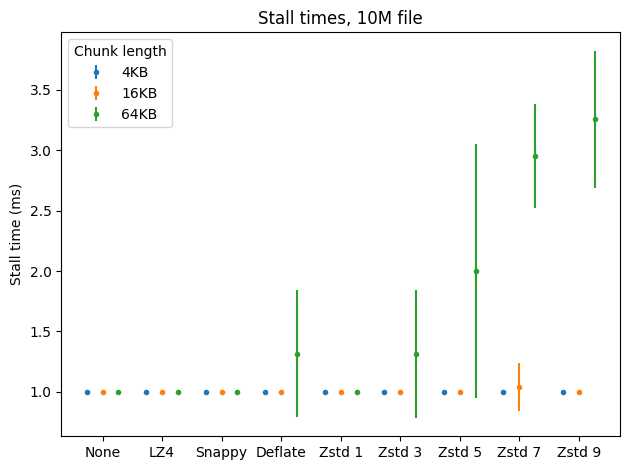
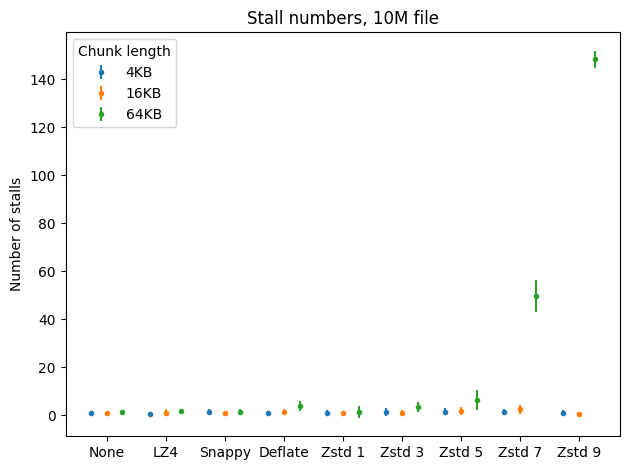
Fortunately reactor stalls aren’t a problem with the fast algorithms, including ZStandard on level 1. They sometimes appear when using DEFLATE and higher levels of ZStandard, but only with greater chunk lengths and still not too often. In general the results are pretty good.
Conclusions
Use compression. Unless you are using a really (but REALLY) fast hard drive, using the default compression settings will be even faster than disabling compression, and the space savings are huge.
When running a data warehouse where data is mostly being read and only rarely updated, consider using DEFLATE. It provides very good compression ratios while maintaining high decompression speeds; compression can be slower, but that might be unimportant for your workload.
If your workload is write-heavy but you really care about saving disk space, consider using ZStandard on level 1. It provides a good middle-ground between LZ4/Snappy and DEFLATE in terms of compression ratios and keeps compression speeds close to LZ4 and Snappy. Be careful however: if you often want to read cold data (from the SSTables on disk, not currently stored in memory, so for example data that was inserted a long time ago), the slower decompression might become a problem.
Remember, the benchmarks above are artificial and every case requires dedicated tests to select the best possible option. For example, if you want to decrease your tables’ disk overhead even more, perhaps you should consider using even greater chunk lengths where higher levels of ZStandard can shine — but always run benchmarks first to see if that’s better for you.





