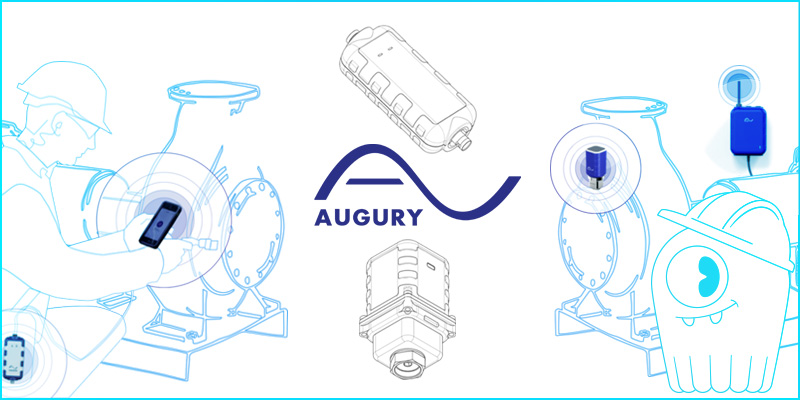
Augury is an industry leading startup in machine health automation with the vision “to develop a world where people can always rely on the machines that matter to them.” They provide Industrial Internet of Things (IIoT) hardware, software and Artificial Intelligence (AI) technology for factories, utilities and other industrial facilities around the world.
Augury has grown dramatically since its founding in 2011, now monitoring tens of thousands of machines, avoiding thousands of predictable failure hours and keeping thousands of pieces of equipment from harm across sites throughout North America, Europe and Israel. All while keeping expensive service truck rolls and unexpected machine repair and replacement costs to a minimum. Augury is also expanding into partnerships, signing deals with companies such as Danish water infrastructure equipment manufacturer Grundfos to provide the intelligence to keep water supplies safe.
Last year we shared the story of how Augury made the transition from MongoDB to ScyllaDB, through their proof-of-concept and into production. At ScyllaDB Summit 2019 Augury’s Senior Data Scientist Daniel Barsky took us deeper into their use case to talk more about the transition, provided an update on Augury’s progress, and gave the audience a glimpse into their future.
Providing Machine Insights
Dan began his talk by noting,“I am passionate about building simple solutions using complex tools,” and the natural interplay of hardware and software. After drawing an analogy to the attendees’ personal experiences with faulty kitchen refrigerators, Dan noted “a machine that’s critical to you breaking down is a massive issue, a massive hassle, one that we are trying to help everybody around us avoid.”
The key to upholding Augury’s vision is to provide actionable and informative insights about the health and condition of their customers’ machines. In order to accomplish this, Augury installs its IIoT devices on industrial equipment.

The small blue devices mounted to the equipment pictured above are Augury Halo Continuous Diagnostics wireless IIoT sensors, which are providing machine health information for pumps in a water treatment facility. Mounted on the wall in the upper left is a Halo wireless gateway node.
“Our sensors basically sample data continuously every hour, every few minutes, or based on an event, uploads that data to the cloud via the gateway that’s mounted on the wall. All of the data streams into our cloud where we apply additional processing — signal processing, time series algorithms, machine learning — and convert those to actionable insights.”
This information is stored in a cloud data platform and then presented back to users through visualization tools enabling them to make the best decisions possible for their equipment.
Besides just preventative maintenance this diagnostic information can also help Augury’s customers to plan the most efficient use of their plant equipment, getting the most productive work out of their machines without overly taxing them.
Augury’s Times Series Data at Scale
Augury collects multi-dimensional time series data per machine. These changing conditions are called a stream setting, which they record every hour, uploading the results to Augury’s cloud, where they perform feature extraction, converting the data into parameters that are indicative of machine health: mechanical or electrical issues. These become rows in a table. These rows are then indexed by machine and where they are on the machine, plus the timestamp when the recording was made.
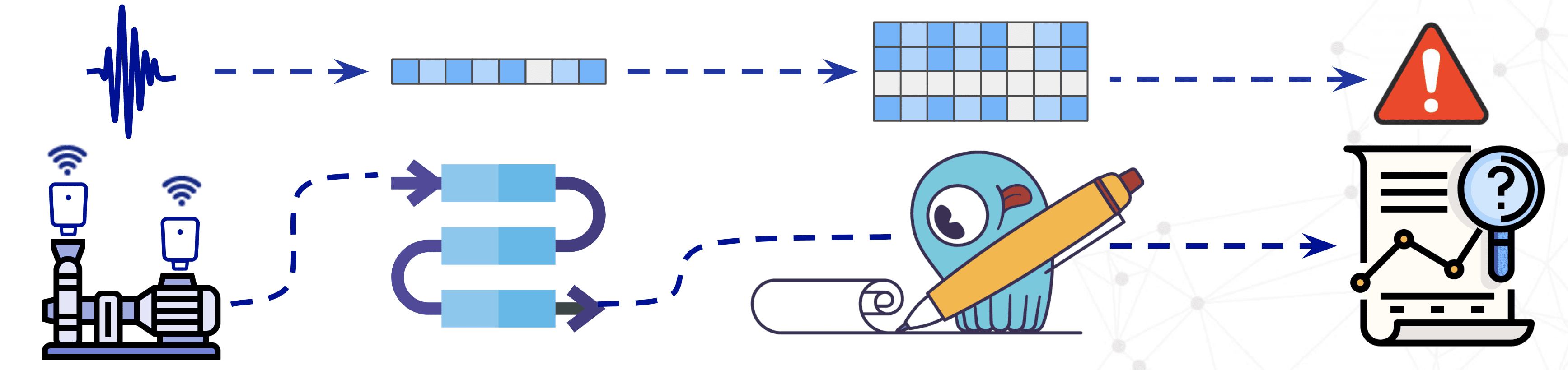
Another use case for Augury is a batch setting, where they need to take a large amount of multivariate time-series data for multiple machines and multiple events from storage, and feed it into a Machine Learning (ML) platform to construct and train models. “We can either do analytics if we want to try to characterize a new feature, a new set of features, if we want to try to classify a new class of machines, or a new condition that we’re trying to capture. Or, if we have enough data and we have the ground truth we can train a model, deploy that into production and then we’re basically going back to the stream setting for the relevant machines.”
By late 2017 Augury began looking for a database solution that would “hit all the marks” in these three categories:
- Streaming flow requirements
- Batch (offline) requirements
- Deployment & maintenance requirements
Daniel emphasized that back then, as a growing startup, the requirement to keep operational overhead low was critical. “We didn’t necessarily have the bandwidth to maintain a very complex piece of infrastructure so we were looking for something that we could roll out and maintain internally in a pretty easy and scalable fashion.
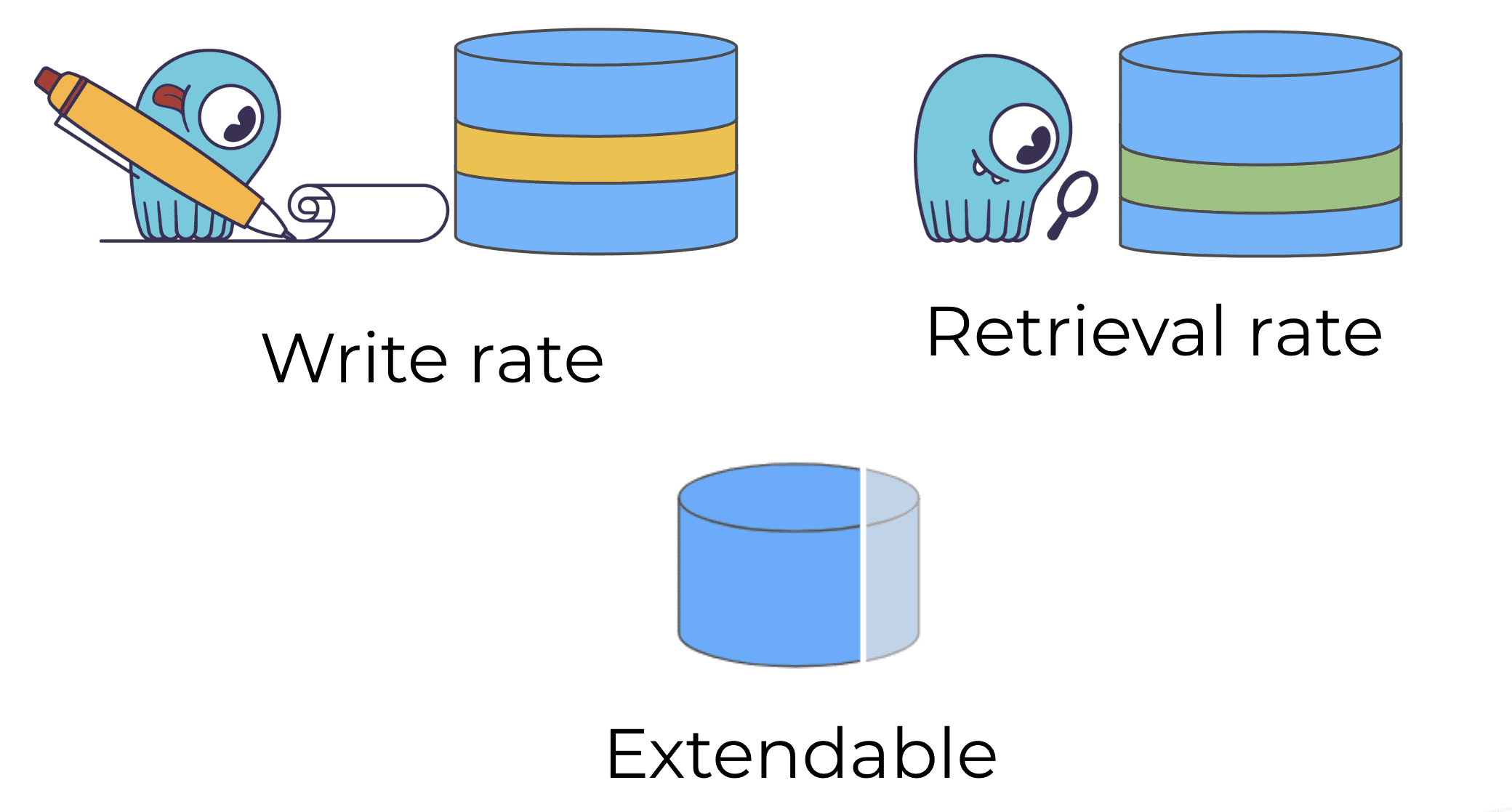
For their streaming flow requirements, Augury needed a system that could maintain high data writes and retrieval (read) rates, both in throughput and latency, plus was extendable. This was tens of thousands of rows per hour, which wasn’t much of a stress for ScyllaDB or its competitors. But the data retrieval rate was two to three orders of magnitude greater.
Extensibility was not just in terms of raw quantity of data, but to add columns, or a new set of features they were tracking for a new type of fault. “We wanted to make sure that we’re able to add those seamlessly without having to do a massive migration of all of our data. That we wouldn’t have stuff breaking because we changed the schema, basically.”
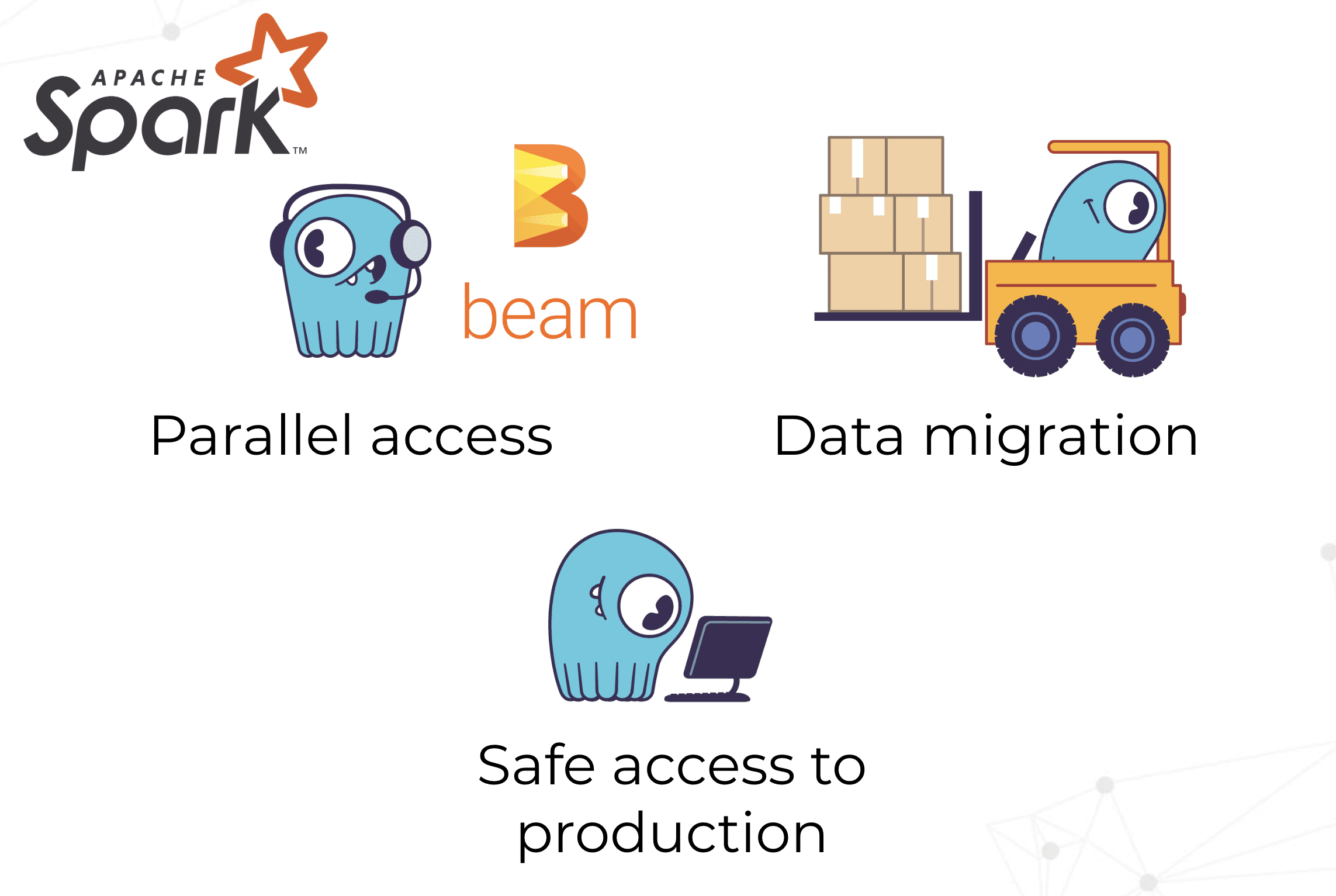
For Augury’s batch processing requirements via Apache Spark or Apache Beam, “we also wanted to make sure we’re able to ingest the data in a massively parallel fashion.” For data migration, Augury wanted to be able to narrow down to a set of machines, or to just a set of columns associated with all or a set of machines. They wanted to be able to do this without rewriting the entire object or recalculate the features from all the raw data they have to process.
Lastly, they wanted to have safe access to production. To be able to run their analytics jobs and train their models without impacting the production system, either by overloading it or corrupting the underlying data.

Augury wanted a solution that their small but growing team would be able to set up and manage easily, whether that was on a developer’s laptop or in a cloud test or production environment. They wanted something that would be easy to scale up, especially if it needed to hit certain marks on performance. Plus, something that was easy to back up and maintain over time.
They considered a few alternatives, including Apache Cassandra, Google Cloud Bigtable, InfluxDB and ScyllaDB. Here were the pros and cons of each of their considerations:
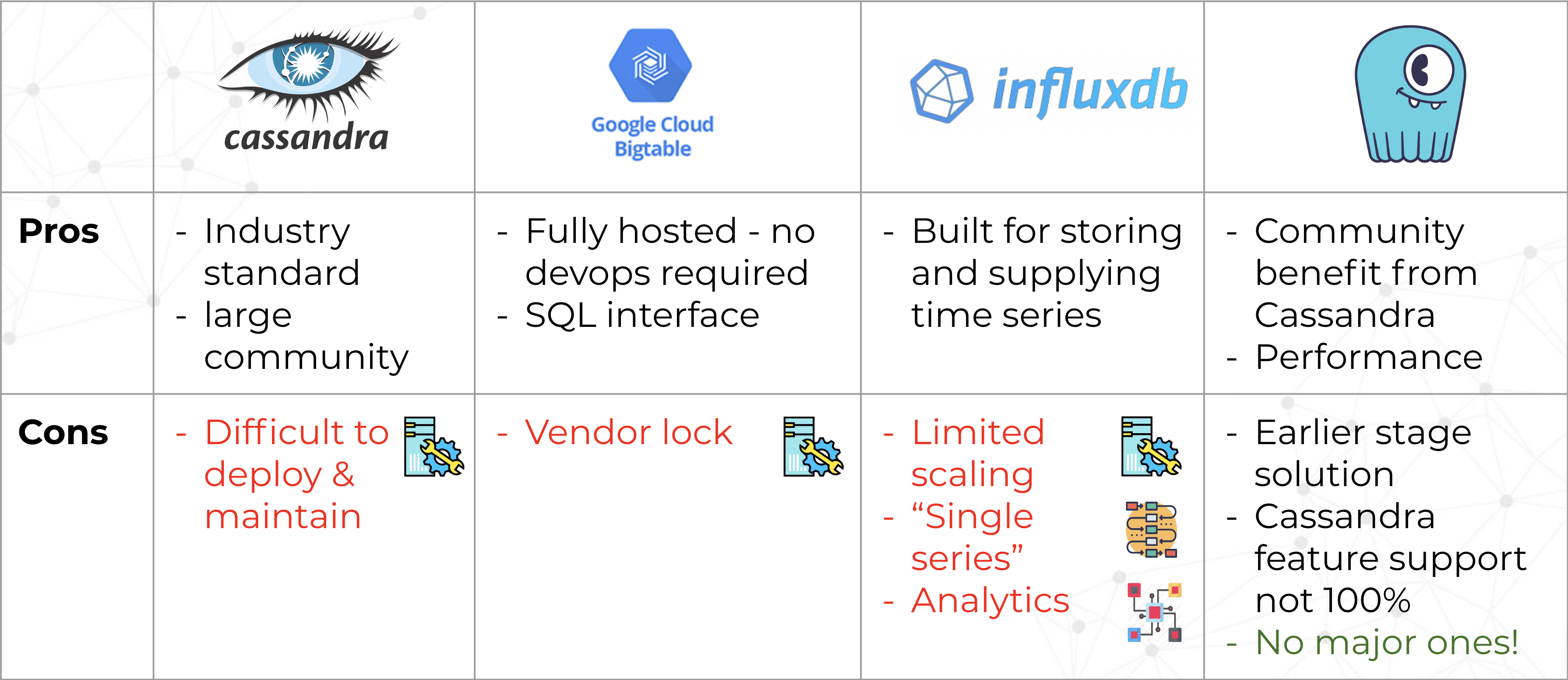
Daniel commented on each. “The main takeaway that we got from evaluating Cassandra was that it was pretty difficult to deploy and maintain. There’s a lot of knobs to tweak. And we didn’t necessarily have the resources in the company to venture into that.”
For Google Cloud Bigtable, he said, “It’s a good solution. It’s hosted. It’s very convenient. But we were very concerned about being vendor-locked. Which is why an Amazon solution would be equally risky for us.” Daniel pointed out that being vendor-locked might not make sense for certain geographies around the world where there are different prevalent cloud vendors.
Daniel noted InfluxDB was not really a good fit. It is tailored around a single time-series, but Augury’s use case has multiple different time-series that required correlation between them. Daniel was also concerned about integration with analytics platforms, such as Apache Spark.
Augury chose instead to go with ScyllaDB. It provided the same community benefits of Cassandra, since it could leverage the same ecosystem and integrations, with an added benefit of superior performance. While ScyllaDB was relatively younger than Cassandra, and at the time did not support the full set of Cassandra’s features, none of the gaps were major enough to hold up adoption.
Augury’s Data Model
“The context of a typical query is a single machine,” Daniel explained. “It could be all of the data for a machine in a time range, or data from a specific point on the machine. So that was the guiding principle behind our data modeling. In terms of the partition key we chose the Machine ID, the unique identifier for the machine and a Quarter. The reason we added a Quarter, as I am sure most of you are doing is to have bounded sized partitions, or expectable sized partitions. The added benefit there is that we had a coarse-grained way to parse the time series data on the machine. We could just take the time range query and divide that into the few quarters that we needed and that gave us coarse-grained data access.”
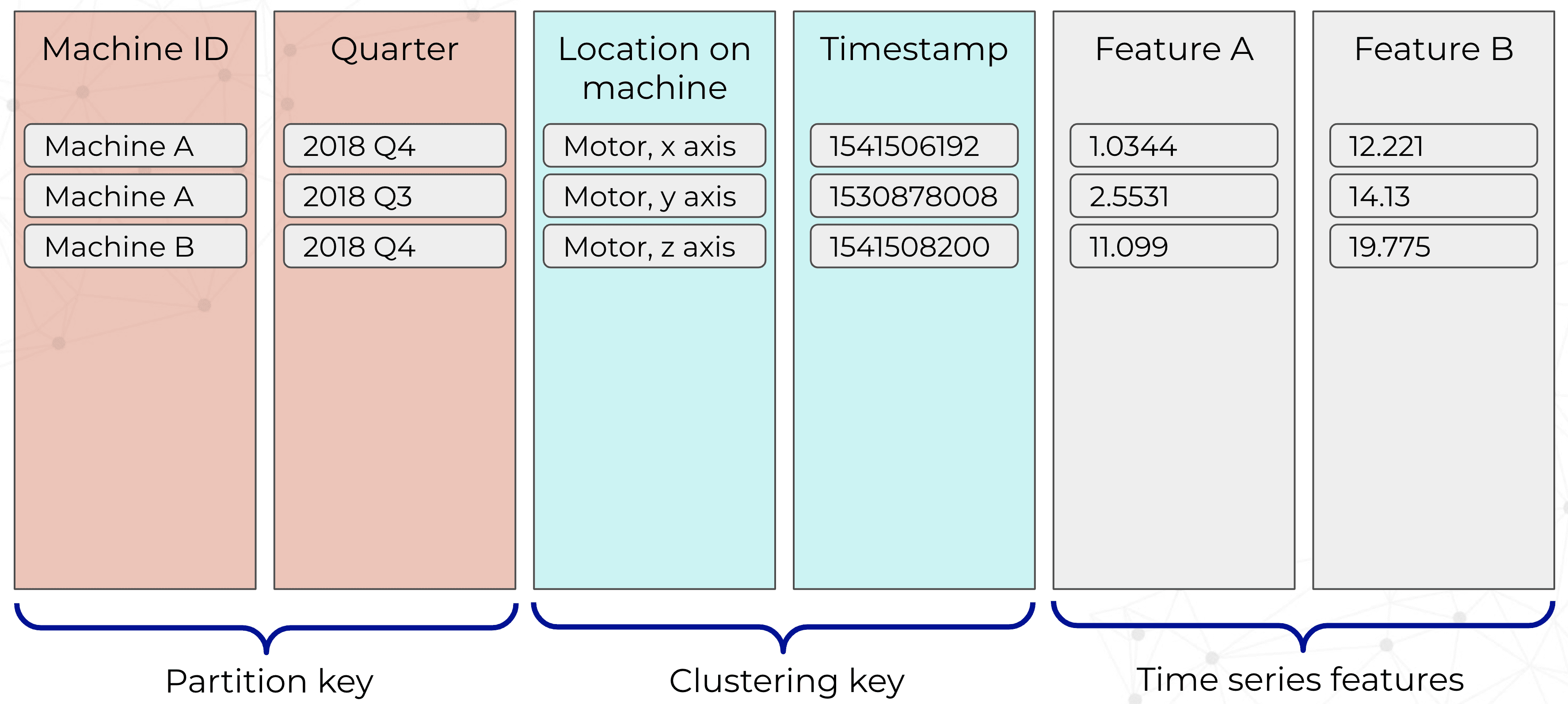
Daniel then went on to describe the rest of the schema. “When we’re talking about the clustering key, we added the location — the specific location on the machine — such as the sensors on the motor, the x-axis vibration sensor, etc. And we also added the time stamp so we would have far more fine-grained data access. And finally, all of the features are regular columns in the database.”
Cluster Deployment
Augury is entirely cloud-based, running in Google Cloud. Their production cluster consists of six nodes, with three nodes in a research datacenter. The production datacenter was for ingestion of the incoming time-series data from each of their customer’s devices, and the research datacenter was more for analytics, Machine Learning, and offline work.
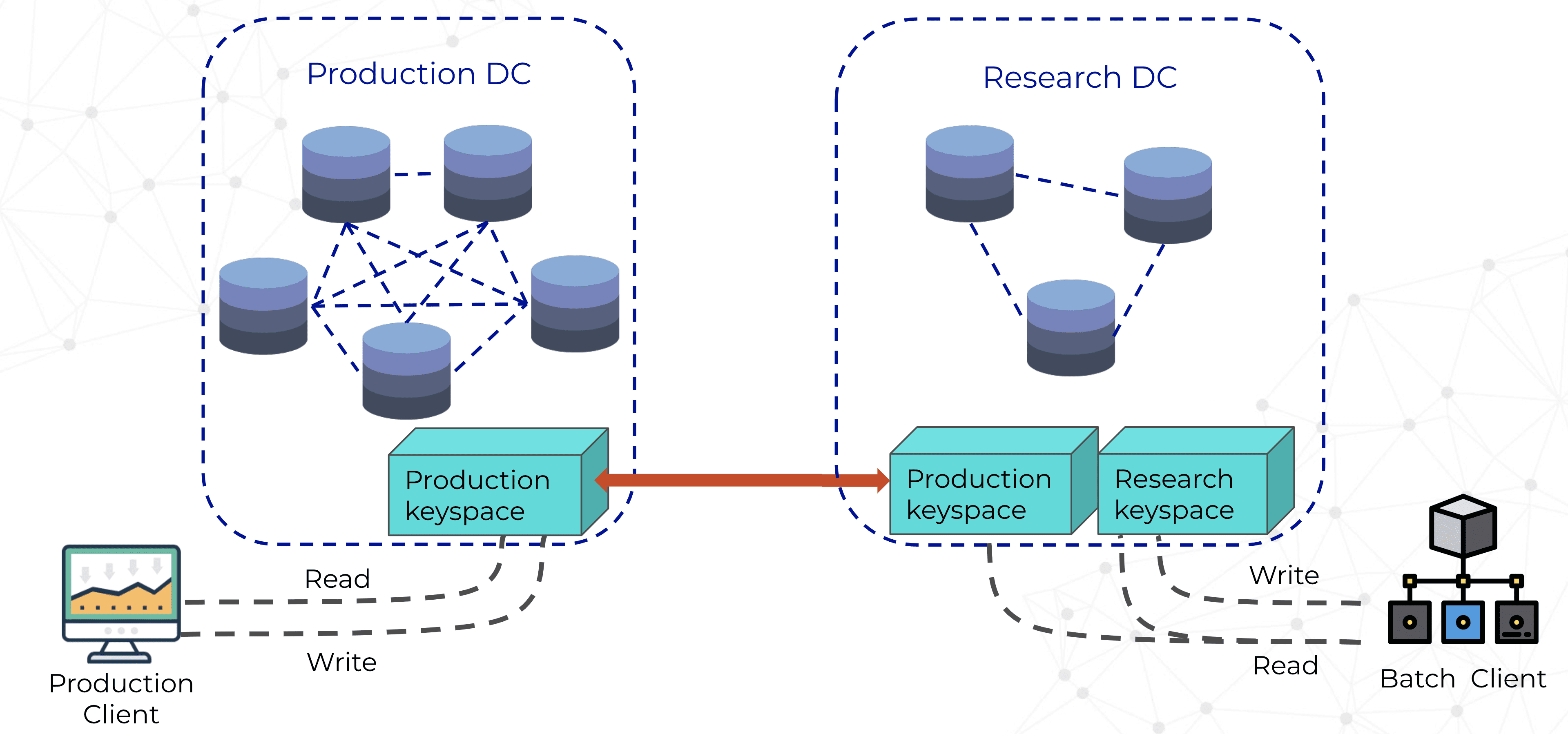
The production keyspace is replicated in the research keyspace through multi-datacenter replication. They also established a research keyspace that existed only in the research datacenter. This is more of an ephemeral datastore in case Augury’s data scientists wanted to store intermediate tables for offline analytics.
Read and write access is granted via authentication to the production clients. But on the research datacenter, batch clients are given only read access to the production keyspace. This achieves the objective of safe access to the production data.
Batch clients also have read and write privileges to the research keyspace.
Additional Benefit: Machine Trend Dashboard
While they had satisfied their immediate needs for analytics, Augury also realized they could use ScyllaDB for a new use case: a machine trend dashboard. This dashboard would be an immediate way to view data, providing deep introspection while maintaining sub-second load time responsiveness.
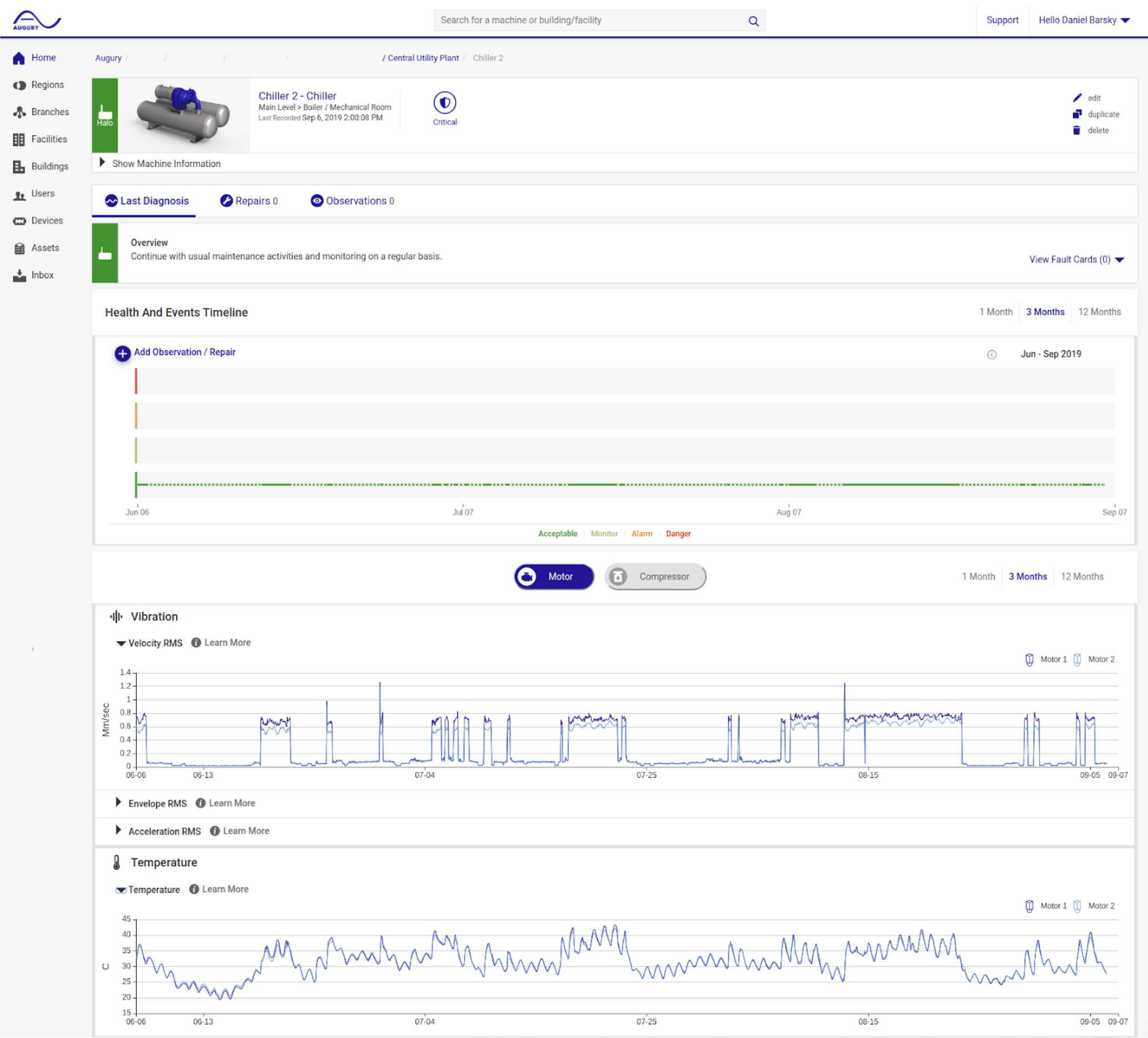
“If we give an alert we want the customers to be able to go into the dashboard and see on the trend graph where the fault occurred. Where the deterioration occurred. If we have an explainable model we want to be able to show that on the data for the customer to actually act on our recommendation. If you tell a customer a machine is going to break down, some will actually fix it. Some will take their time and wait. If you show it on the data, if you show the trend graph deteriorating, they’re much more likely to take action. That’s what we want as the stakeholders of their machines.”
Using the same architecture, the same data model, Augury was able to integrate the web dashboard directly to the data written by the algorithm streams.
“We’re getting really good performance there,” Daniel observed. Sub-second batch reads for one or two years of data per machine or for multiple features and multiple locations on a machine. “The latency added by the query is negligible compared to the actual graphics elements on the page, which is where we wanted to be in this case.”
Next Gen Architecture
Augury had been running a microservices architecture with an asynchronous interface between them. But that didn’t scale as well as they hoped as the number of machines and the data rate got larger. Nor was it an optimal use of their research pool.
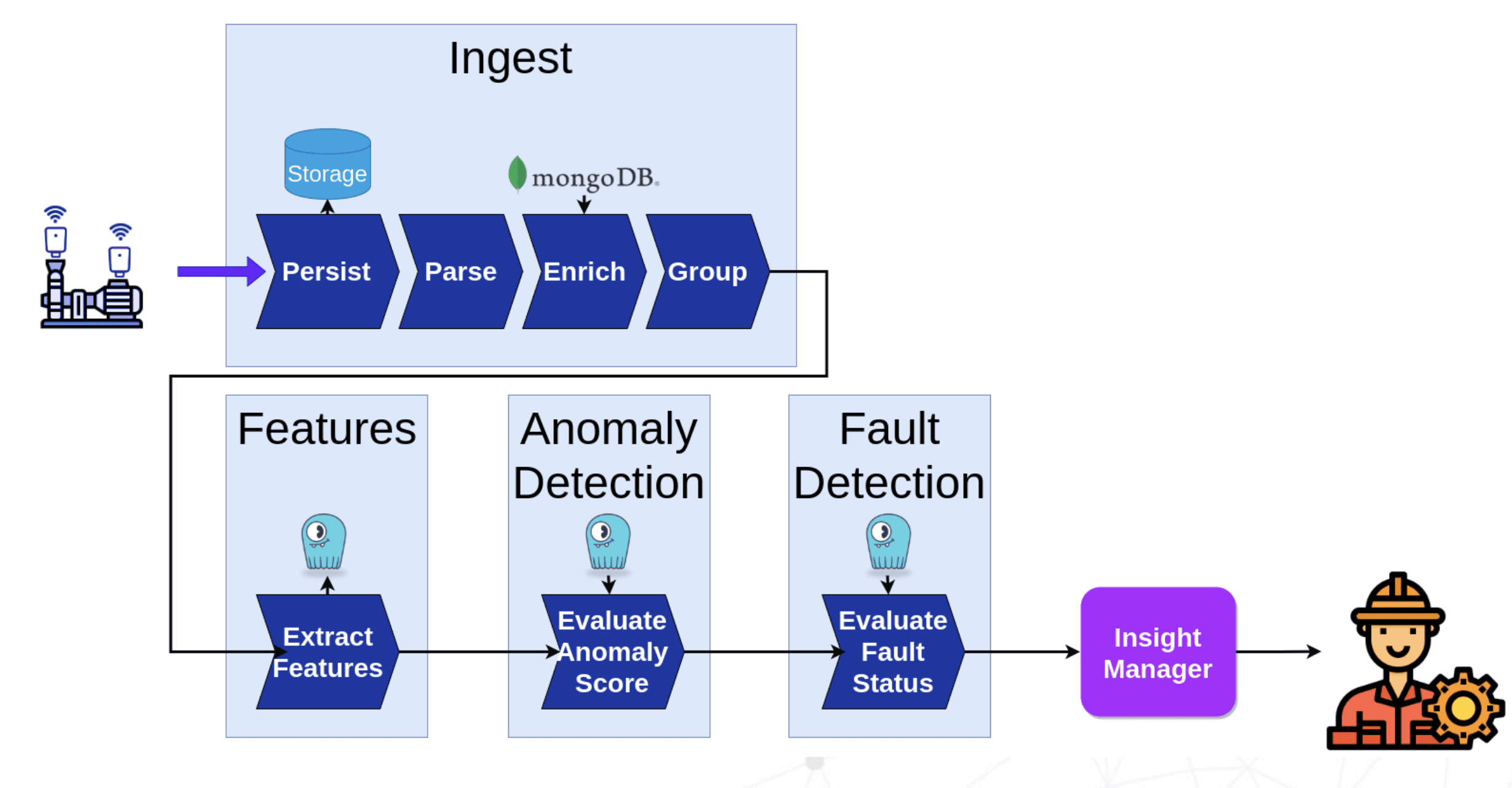
So Augury made the decision to move to a data pipelining architecture, such as Apache Beam or Google Dataflow, and were already in the midst of that transition. “The principle there is to decouple the logic from the resource allocation.” For example, their new ingest pipeline receives all the data from the field, does some enrichment, adds metadata, groups recordings from the same machine at the same time together, and sends them onwards to additional processing.
After that, they do feature extraction that takes all these raw data recordings and converts them to relevant features. Then anomaly detection, fault detection and machine learning pipelines. And those ultimately make an API call to generate an alert to the customer when and if something is detected.
Daniel noted that a key element of the architecture is a serialization layer in between distinct pipelines. A protocol that one would write into and the other would ingest. “For us ScyllaDB was a very good fit for that. Basically, it served as a buffer between the feature extraction, which writes the features, and the elements downstream, which consume them, and helped us decouple and divide the work — divide and conquer.” Augury did not need to do any changes to the data modelling or infrastructure to make it work.
Next Steps
Feel free to watch the entire presentation below or check out Daniel’s complete slide deck on our tech talks page. And if you want to learn more about ScyllaDB, the monstrously fast and scalable NoSQL database, and how it might revolutionize your own Big Data architecture, make sure to contact us directly, or join the discussion on our public Slack channel.