Along with a countless number of other industry events we recently heard the news that Core C++ 2020 was postponed due to the Novel Coronavirus. With all of the tumultuous news in mind, and wishing the entire open source and C++ developer communities our best, we thought we’d take time to look back at last year’s Core C++ event hosted at the Academic College of Tel-Aviv-Yaffo, where our CTO Avi Kivity presented. As an added bonus, we’d like to share the presentations of community contributors who attended Seastar Summit 2019.
Unlike other talks at the conference Avi was not speaking about features of C++ directly but about the Seastar framework, which lies at the heart of ScyllaDB. It was written in C++ and takes advantage of low-level C++ capabilities. Seastar requires a minimum of C++14, also works with C++17, and even uses some features of C++20.
The case for asynch: thinking of disk I/O and CPU-level communications as networks
Avi began by showing an SSD. He pointed out that 20 µseconds, a typical time needed to communicate with an SSD on a modern NVME device, is a relatively long age. Time enough for the CPU to execute 20,000 instructions. Developers should consider it as a networked device, but generally do not program in that way. Many times they use an API that is synchronous, which produces a thread that can be blocked. When that happens the thread has to be switched out, then eventually switched back in by the kernel, all of which is very expensive. Avi argued no one would use blocking calls with an ordinary networked device. Everything in networking is done asynchronously.
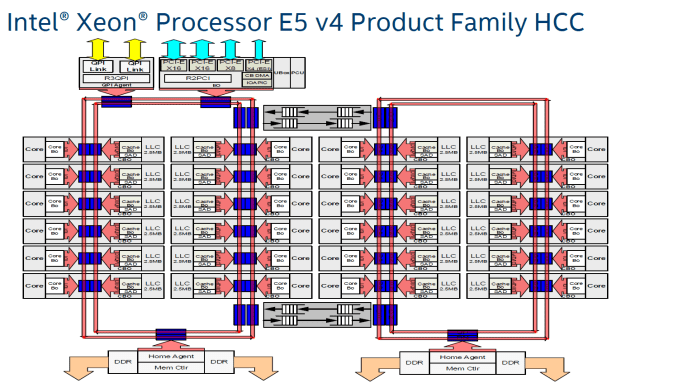
Next Avi presented the image of the logical layout of an Intel Xeon Processor. “This is also a networked device,” he asserted. He pointed out the cores are all connected by what is essentially a network — a dual ring interconnect architecture. There are two such rings and they are bidirectional.
Beyond that, if you have multiple multicore CPUs, they will intercommunicate over another external network. Still most programmers do their inter-core communication work synchronously, locking data and releasing locks. While this doesn’t present much of a problem on a small scale, when done at a large scale all of those locks translate to messages on the internal network that take time to propagate, the basis of cache line contention.
When you try to take a lock and don’t succeed, you then have to repeat the step. Only the kernel puts the thread trying to take the lock to sleep to schedule another thread in its place. Later it is again woken up when the lock is released. This all takes a lot of work and a lot of network messages.
Everything that is difficult around multi-core programming is even harder when you have multiple processors because each of them also has its own memory through Non-Uniform Memory Architecture (NUMA). So if you have one core from one socket trying to communicate with memory attached to another socket, that can take up to 400 cycles to get access to that memory — ages in terms of processing time. By the time you get the response back you could execute hundreds of instructions.
Avi then presented comparisons of how the Seastar framework, which heavily utilizes asynchronous communications between cores, developers can write applications in ways that take advantage of today’s large multicore servers. He compared a Seastar-based implementation of memcached versus stock memcached, as well as ScyllaDB, a C++ rewrite of Cassandra that runs on top of the Seastar framework.
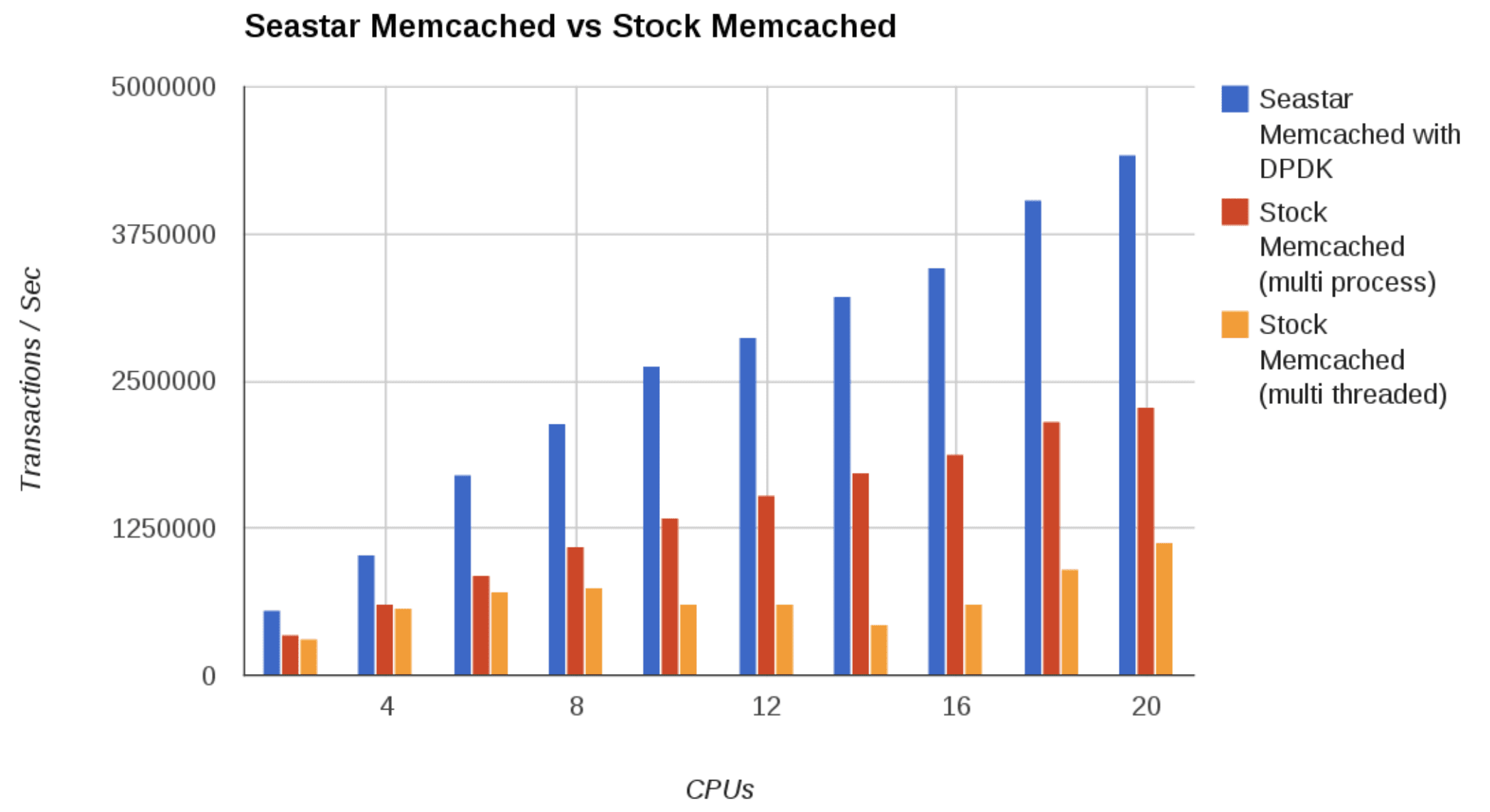
The Seastar framework, which uses asynchronous communications, outperforms stock memcached in both mutli-threaded and multi-process performance.
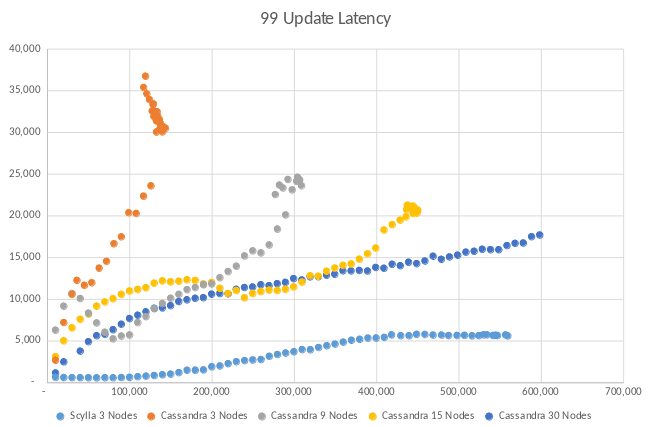
In this comparison of ScyllaDB vs. Apache Cassandra, the horizontal axis measures operations per second (ops) and the vertical axis measures latencies in µseconds. A ScyllaDB server on three nodes was able to maintain roughly the same number of transactions per second as a 30-node Cassandra database, but with latencies about a third of Cassandra’s.
In a traditional multi-threaded application threads are multiplexed onto a number of cores. If you have a very large number of threads then the kernel has to switch in and out of threads so that each will get its share of CPU time on the core. This switching, putting threads to sleep and then waking them again, is expensive. It induces latency. Oppositely, if you have too few threads, then a core won’t have a thread to execute and the machine will be idle. Because of this, on large multi-CPU, multi-core machines it is common to only see 30% or 40% CPU utilization.
In the Seastar model you have one thread per core so that you have the exact balance of operating processes to hardware. Avi noted “You never have a situation where a core doesn’t have a thread to run.” Nor would you ever have a situation where the core has to multiplex multiple threads.
As Avi observed, “so we solve the problem of assigning threads to cores but of course we gained a number of problems about how those threads can do different tasks that we usually assigned to different threads.”
“We partition the machine into a bunch of replicas which are called shards and each of them run the same code in parallel. Because of that the amount of communication between the shards is minimized. Each of them operates stand-alone yet they have means to communicate with each other via a point to point queue. There is a task scheduler whose role is to provide the abilities we lost when we enforced the one thread per core design.”
Instead of having a large number of threads, each of which perform a single task or a single process, all of the work is multiplexed, controlled via a task scheduler that picks the next task to execute. Avi described it as a shared-nothing run-to-completion scheduler “basically a class with a single virtual function… It takes a queue of tasks and just picks the next one to run and executes it.” While it runs as a first-in-first-out (FIFO) queue, there is also a bit of extra logic for task prioritization to allow different tasks to run at different times.
Shard per logical core architecture
While Avi was referring to “cores,” he noted that technically ScyllaDB is sharded per “logical core,” that is, a hyperthread in the parlance of Intel, or, more generally, simultaneous multithreading (SMT) if speaking about a modern AMD chipset.
With ScyllaDB, each of these virtual cores is assigned its own system memory as well as a shard of data (a range of partition keys). When a core needs to access data assigned to another core, rather than it asking to access it directly, it sends a message to the other virtual core to perform an operation on the data on its behalf.
“This is how we avoid locking,” Avi explained. “There’s only one thread accessing each piece of data. All of the costly locking instructions are avoided. Also, locking becomes much simpler because everything is serialized by the remote core. This avoids all of the internal networking operations that the CPU has to perform under the covers in order to move the data to the cores that execute the operations. Instead of moving the data we move the operation.”
The Seastar APIs are all composable. When you have a networking operation and a disk operation, and remote core operations you can combine them in different ways as enabled by the API. Avi noted this usually isn’t the case. “Usually if you have an asynchronous networking stack but synchronous disk access and synchronous memory access based on locks they don’t combine well. As soon as you take a lock you have to complete everything and then release it otherwise you’re going to cause other threads to contend.” For instance, if you take a lock and then perform a disk operation you will hit a contention. Seastar solves that by making everything asynchronous.
Futures, Promises and Continuations
The building block in Seastar is a Future, Promise and Continuation (FPC) model. Most of the attendees of Core C++ 2019 were familiar with the concept. It was invented back in the 1970s and recently came back into fashion with Node.js. If you want to familiarize yourself more with the concepts, you can read a good blog about it here.
C++ has futures and promises in the standard library. Avi explained, “it’s a very good way to compose different activities. In Seastar it’s even more than a result of some computation; it’s also a result of IO.
Watch the Full Video
Speaking about continuations, all of the above was covered in just the first fifteen minutes of Avi’s hour-long talk. If you want to learn more about the role of futures, promises and continuation in ScyllaDB, and take a deep dive into the technology that lies at the heart of ScyllaDB watch the full video below:
Also feel free to download the slides.
DOWNLOAD AVI KIVITY’S CORE C++ 2019 PRESENTATION
Presentations from Seastar Summit 2019
Avi Kivity was not the only one speaking about Seastar last year. Concurrent with last year’s ScyllaDB Summit, we hosted our first Seastar Summit. Speakers from ScyllaDB, Red Hat, Vectorized and others who are leveraging Seastar to build their own asynchronous distributed applications gathered together to share progress in their work and lessons learned. You can browse their presentations via the links provided below:
Seastar Summit 2019 Keynote — Avi Kivity, ScyllaDB
If you would like to participate in the Seastar development community, feel free to join our Slack and check out the #seastar channel.