





Based on our record attendance and your feedback, our first online ScyllaDB Summit has been a rousing success! First, if you missed it, make sure you read the blog about Day One of ScyllaDB Summit 2021.
Yesterday, Tuesday, January 12th was the second day of presentations, and included talks from ScyllaDB CTO and Co-Founder Avi Kivity, who spoke about the challenges of Big Data with ScyllaDB, Confluent’s Tim Berglund, who spoke on combining the power of Apache Kafka and ScyllaDB’s new CDC capabilities, and a range of sessions from ScyllaDB and Seastar users and ScyllaDB engineers.
Also, before we get further into the details, we want to give you a timely reminder:
Don’t Miss Our Training Day!
Our free, live and online is happening today, January 14th 2021, from 8:30 – 11:30 AM PST.
Our Training Day includes separate tracks for developers and administrators. So whether you are more interested in designing a well-distributed data model, or learning how to manage your clusters using Kubernetes, we’ll have sessions right up your alley. If you’re new to NoSQL or ScyllaDB in particular, we even have a getting started course so you can embark on a whole new career path.
REGISTER FOR SCYLLA SUMMIT 2021 TRAINING DAY
The entire Training Day curriculum, like the rest of ScyllaDB Summit, is free and open to all attendees, so register now! But if you can’t make it at this time, don’t worry! You can always register for ScyllaDB University, which also provides free online self-paced lessons for all ranges of skills and interests. It also serves to reinforce any skills you’ll learn at our Training Day.
GET STARTED IN SCYLLA UNIVERSITY
Avi Kivity: Meeting the Challenges of Big Data
Avi in his keynote began by reiterating the characteristics and initiatives brought together under the umbrella of Project Circe, which we announced the day before.
The first characteristic Avi focused on was performance because it has a direct correlation with the cost of running your database and sustaining your workload. “It directly relates to your expenses. If the database is twice as fast, then your costs are halved. This is the main reason to pick ScyllaDB for your big data.”
Though there’s more to it than just that. “Performance is also the ability to maintain your workload while it is undergoing maintenance operations. Scaling up and down.” Avi noted the importance of maintenance operations not interfering with your main workloads. “So the feature here is performance isolation.”
Isolation also applies to different data types. Simple inserts are very different, in terms of performance costs, than full scans, reading via various indexes, filtering, or reading large partitions. “We are working to improve our support of more and more query types so there are fewer performance-related surprises while using the database.”
Avi also pointed out how we are working on supporting dense nodes. “The more storage your node has, the fewer nodes you will need. And that reduces operational costs of maintaining the database. There are fewer things that can fail. Fewer things to maintain.” To Avi, continuing to make the most out of your hardware is ScyllaDB’s “bread and butter” — utilizing all cores, all memory for caching, and making good use of fast solid state drives (SSDs).
He also pointed out some recent improvements: use of B+tree in cache (instead of a red-black tree), reactor stall eliminations, and the implementation of C++ coroutines.
The B+tree improves the memory footprint of objects in cache, “so we can pack more partitions into cache and increase the hit rate.” It also reduces the cycle cost of reading and inserting into cache, which allows loading more objects per second.
To solve reactor stalls requires breaking down tasks into smaller and smaller pieces that can be preempted. C++ coroutines, a feature of C++20, “allow us to reduce the number of allocations needed to service a query.” And, besides, it’s fun to play with nifty new code. “We enjoy that.”
These are just highlights from the beginning of Avi’s presentation. He ranged onwards to other topics including elasticity, the use of Raft in ScyllaDB, Change Data Capture (CDC), Kubernetes, our partnership with AWS Outposts and more. We will bring you the video and slides of his whole half-hour keynote, as well as all the sessions that delved into each of these individual topics shortly after the Summit concludes.
CDC and Streaming Data from ScyllaDB to Kafka
Speaking about CDC, right after Avi we had two back-to-back sessions that showed users a new paradigm of how to leverage their big data in ScyllaDB using Change Data Capture, which is now a GA feature with the release this week of ScyllaDB Open Source 4.3.
First up was ScyllaDB’s Calle Wilund, who explained best practices for Change Data Capture in ScyllaDB. CDC is enabled in ScyllaDB per table. When enabled it creates a CDC log, which is just another CQL table that records the changes to the base table. It can record all the deltas, as well as the pre- and post-images.
The CDC log is stored distributed on nodes across the cluster, with rows ordered by timestamp and batch sequence. The topology will match the source table — the CDC log is collocated with, and its partition scheme will match the base table. Also, CDC data is transient. It has a Time to Live (TTL) which defaults to 24 hours, but is user-configurable, to ensure that it does not expand unbounded over time.
After Calle next up was Tim Berglund of Confluent, who gave a practical example of how you can harness the power of ScyllaDB’s CDC feature with Apache Kafka. ScyllaDB’s under-development Kafka source connector is built on top of open source Debezium.

With it, you will be able to share data from ScyllaDB CDC tables straight out to Kafka topics. And, along with the Kafka ScyllaDB Connector that serves as a sink connector, you are now able to use ScyllaDB as both a source and a destination in a complete data ecosystem with Apache Kafka.
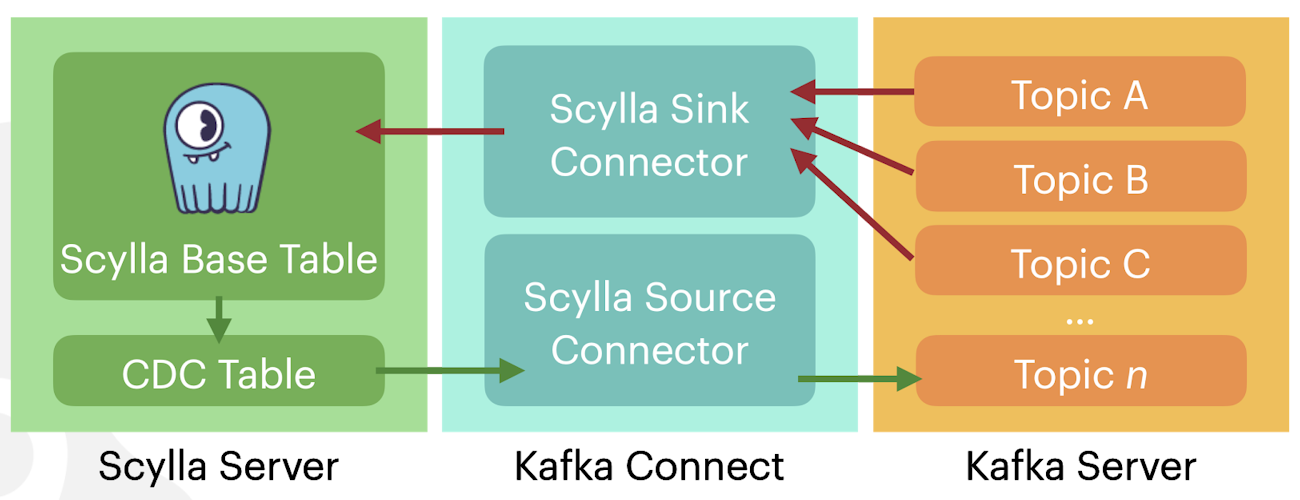
Tim’s presentation went step-by-step through how the connector works, from setting it up, to showing how data flows from CQL tables to JSON in Kafka topics. For now, the connector only supports delta operations. Preimage and postimage will be added in the future, which Tim pointed out will match nicely with the “before” and “after” fields of Debezium.
A Full Agenda
With each other session being about 10 to 12 minutes long, the rest of the day was filled with the equivalent of “lightning talks” comprised of a mix of ScyllaDB engineers and users/customers.
- Numberly: Getting the ScyllaDB Shard-Aware Drivers Faster — Numberly’s CTO Alexys Jacob is no stranger to the ScyllaDB Summit stage. One of our all-time favorite speakers, this year he described the work that went into improving the performance of ScyllaDB’s shard-aware Python driver. In case you missed it, make sure you read our earlier articles, both part one, which describes the basic goals and methods of making a shard-aware driver, and part two, which covers the implementation. His talk went beyond those earlier posts, covering performance optimizations.
- ScyllaDB Performance Enhancements: Year in Review — ScyllaDB’s Tomasz Grabiec took attendees deeper into the performance improvements Avi touched upon in his keynote. These internal improvements make ScyllaDB faster than ever before: handling large partitions, SSTable index caching, eliminating stalls, B+trees in cache for even faster lookups, and an improved I/O scheduler.
- Mail.Ru: High-Load Storage of Users’ Actions with ScyllaDB and HDDs — Mail.Ru’s Kirill Alekseev had a unique solution for storing petabytes of data, optimizing for best price over performance by employing spinning media — HDDs — while still maintaining single-digit latencies.
- The All-New ScyllaDB Monitoring Stack — ScyllaDB’s Amnon Heiman showed off the new capabilities of ScyllaDB Monitoring Stack, including its integration of Grafana Loki, the new advisor section, overview and CQL dashboards, and log collection analysis.
- Expedia: Our Migration to ScyllaDB — Expedia Group explained why they moved from Apache Cassandra to ScyllaDB, including an analysis of ScyllaDB’s faster software release cycles and clear roadmap, to TCO, to benchmarks showing lower latencies and greater throughput. For Expedia, over and over again, ScyllaDB won hand’s down.
- How We Made ScyllaDB Maintenance Easier, Safer and Faster — ScyllaDB’s Asias He described the efforts behind making ScyllaDB more elastic and even more maintainable. With ScyllaDB Open Source 4.3, we removed the concept of seed nodes (read more in this article). He also spoke about how our improvements in row-level repair led to our repair-based node operations (RBNO), providing a single mechanism for all node operations, from repair, to bootstrapping, replacing, rebuilding, to decommissioning and removing nodes. He also revealed how we will implement a new more resilient “safe mode” feature for removenode, and a redesigned replace operation.
- IOTA: How IOTA Uses ScyllaDB to Store Unbounded Flow — IOTA is a distributed ledger technology, known as The Tangle. It is radically different from blockchains by being minerless and feeless. IOTA Foundation’s Louay Kamel described how they use ScyllaDB and the Rust CQL driver in their architecture to persistently store unbounded flows of data.
- Developing ScyllaDB Applications: Practical Tips — This great session by Kamil Braun focused on application developers. “The way you write your clients can make or break your whole operation. If you want to know how to make clients that keep the cluster healthy, the system performant, and highly available, you’re in the right place.” True story: as Kamil spoke, Numberly’s Alexys Jacob and ScyllaDB’s Israel Fruchter, who collaborated on making the Python shard-aware driver, had such a revelation about adding backoffs they immediately opened a Github issue for a TODO to improve on their existing design!
- Broadpeak: Building a Video Streaming Testing Framework with Seastar — Nicolas Le Scouarnec showed how Broadpeak is using Seastar, the underlying highly-asynchronous engine at the heart of ScyllaDB, to solve a radically different problem: testing a streaming video framework at scale. This was not a server, but a client application — a benchmarking tool focused on network I/O and using the Chromium browser to emulate HTTP Live Streaming (HLS) and Dynamic Adaptive Streaming over HTTP (DASH) players.
- Redpanda: A New Streaming Storage Engine for Modern Hardware — Vectorized CEO Alex Gallego also showcased a unique application of the Seastar framework. Redpanda is a complete open source, from-the-ground-up redesigned streaming engine compatible with Apache Kafka. Analogous to how ScyllaDB resulted in 10x performance gains, Redpanda offers 10x performance over Kafka, and 44x better p99 latencies. It uses a thread-per-core architecture, async scheduling, and Raft. Sound familiar?
- Ola’s Journey with ScyllaDB — The last session of the day was from Ola Cabs. Ola, India’s ride hailing giant, has been a customer of ScyllaDB’s from the 1.x days. Anil Yadav took users on a tour of Ola’s use case and data pipeline, and explained the performance they’ve been able to achieve.
Thank You
ScyllaDB Summit 2021 was created with the labor of dozens of speakers, and with the hard work of many behind the scenes staff to put on our first major live virtual event. Without them, the event would not even have been possible. We’d like to thank everyone who helped put on such a successful event.
Yet ultimately, it was the enthusiasm and interest of you — our loyal ScyllaDB database users and customers, and the broader NoSQL community of interest — that made this event so much of a success. Thank you for attending, and giving us your frank and honest feedback, your questions — whether from the newest beginners to the zingers from the experts in the crowd — and, most of all in this busy day and age, your generous time and attention. We’re very happy you enjoyed the event, and grateful for your attendance.
Here’s to a great 2021!
Editor’s Note: This event is now in the past, but you can watch all of the sessions on-demand:














