We had the pleasure of hosting GumGum’s Keith Sader at our ScyllaDB Summit this year. Keith began by giving some background by drawing from his career, which has spanned the adtech space at GumGum as well as prior stints at the automobile shopping site Edmunds.com and Garmin, the maker of tracking and mapping devices.
GumGum’s Verity Platform
Keith guided ScyllaDB Summit attendees through how GumGum’s advertising systems works. “Verity is our contextual platform. What it does is use Natural Language Processing [NLP] along with computer vision to really analyze the context of a website. This includes not only just strictly looking at the images and contextualizing those but also the images in relation to the rest of the page to get really, really accurate marketing segments to find the correct context for an ad.” This makes GumGum not as reliant on cookie-based matching, which is increasingly being curbed by both privacy regulations and public scrutiny.
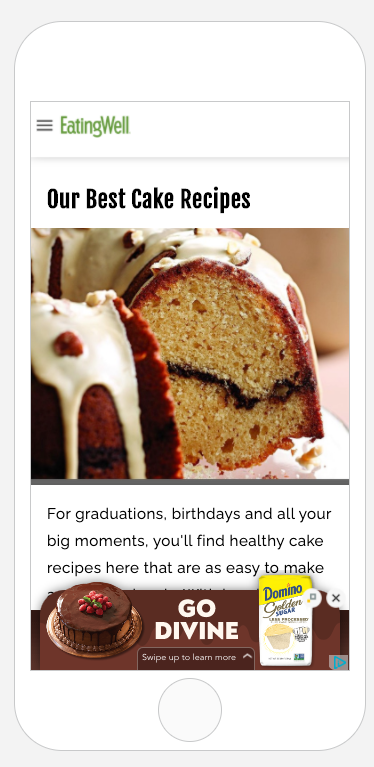
GumGum’s Verity platform is able to not only read and analyze the text of this recipe article but also to understand the image of the cake in order to match it to their ad inventory and propose an ad for sugar, all in less than the blink of an eye.
GumGum’s high scalability ad server platform responds to requests coming from Server Side Publishers (SSPs) and advertisers using a mix of both relational and non-relational datastores. The relational data store tracks the campaigns, ads, targets and platforms. The NoSQL datastores include DynamoDB and ScyllaDB. DynamoDB is used as a cookie store.
“Probably the most important one, and the most relevant to this talk, is our tally back-end which we originally implemented in Cassandra. Tally does some very cool things around ad performance. Originally our Cassandra cluster was 51 instances around the globe — Virginia, Oregon, Japan, Ireland — and they were pretty beefy machines, i3.2xlarge instances. Just the basic cost of that alone was almost $200,000 not including staff time.” The staff time and costs on top of that included two engineers dedicating 20% of their time each in keeping the server running.
“Cassandra is fantastic if you can throw a dev team at it. But we’re not really a Cassandra focused shop. We’re making an ad server with computer vision, which is a different problem almost entirely.” This was the reason behind why GumGum turned to ScyllaDB Cloud instead.
“What Tally records — and honestly this is probably some of the most important things for ad serving — when you are serving an ad you are looking to figure out ‘does it match the slot it’s going into?’ On a page for an ad slot there’s a lot of filtering, a lot of brand awareness, but the other part is ‘have you served this ad already?’ How do you know that? Well Tally knows that because this is where we count everything.”
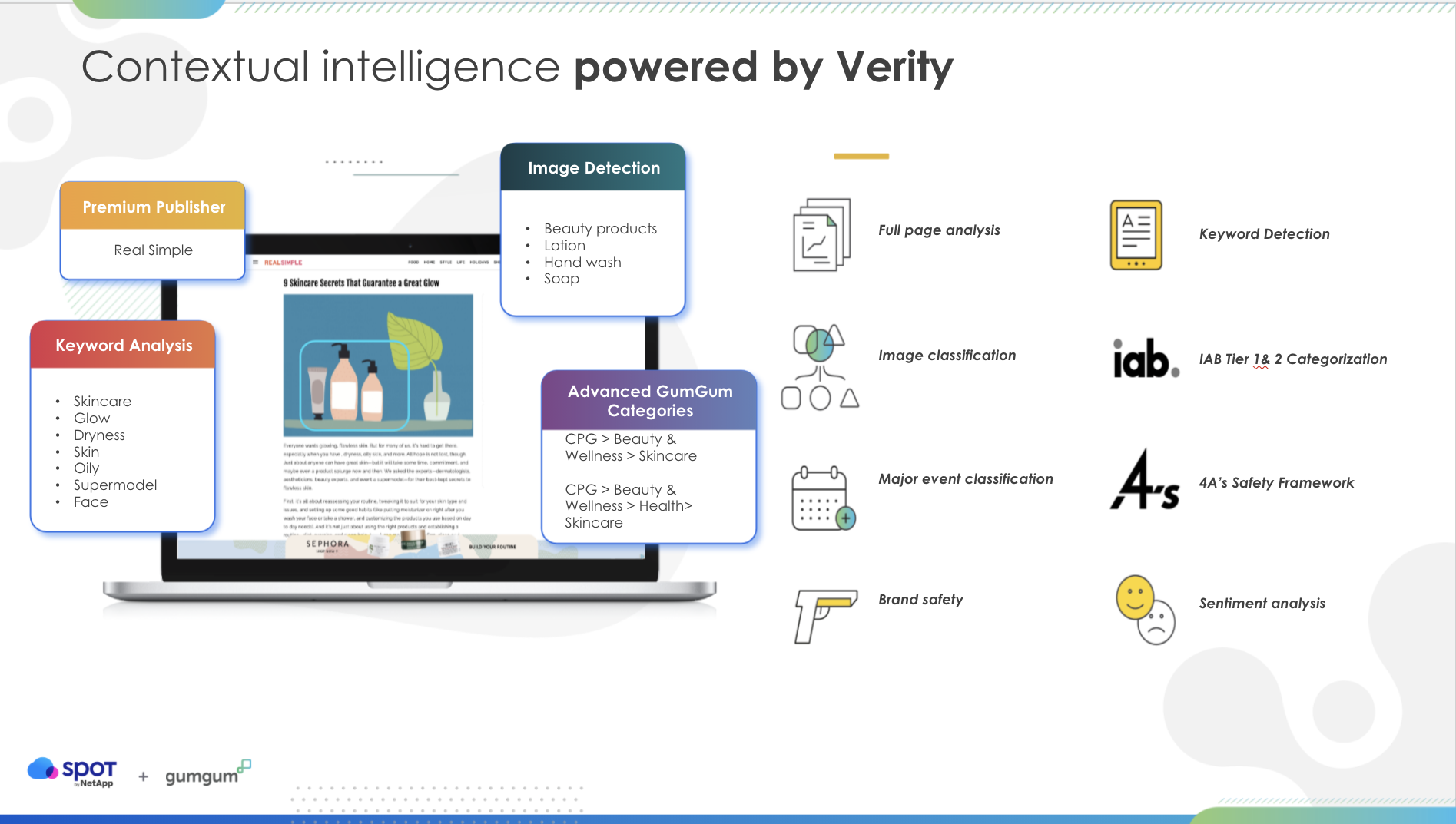
“What ScyllaDB via Tally does is help us count all the impressions, all the views, all the clicks, all the revenue, all the video streams, and play percentages along the way in the course of serving advertisements. What this tells us is when we can actually stop serving an ad when it’s fulfilled its campaign goal and serve something else. Or we can compare two different ads just to serve in a slot and determine ‘Okay based upon this one’s proportions of impressions to this one’s proportions of impressions what makes the most sense for us to serve now?’”
Whether or not GumGum was able to bid on and serve an ad, where and how it was placed in the context of a page, and whether or not the viewer could see it and click on it, or whether a video plays and how far a viewer got through it all determines the success or failure of ad placement. Keith explained how GumGum can take data collected in Tally and report back factually to the advertiser, whether that means “by the way people are only watching ten percent of your video ad” or “Hey this ad, this video plays 100%. It’s a fantastic campaign!’”
GumGum uses third party-data providers to ensure Tally stays current and accurate. These jobs start off the data and continue throughout the course of the day. As Keith explained, “We adjust it based upon the best and most accurate knowledge we have at the time to determine whether or not we should serve another ad.” This means Tally isn’t precisely real-time, “but we’re pretty darn close.”
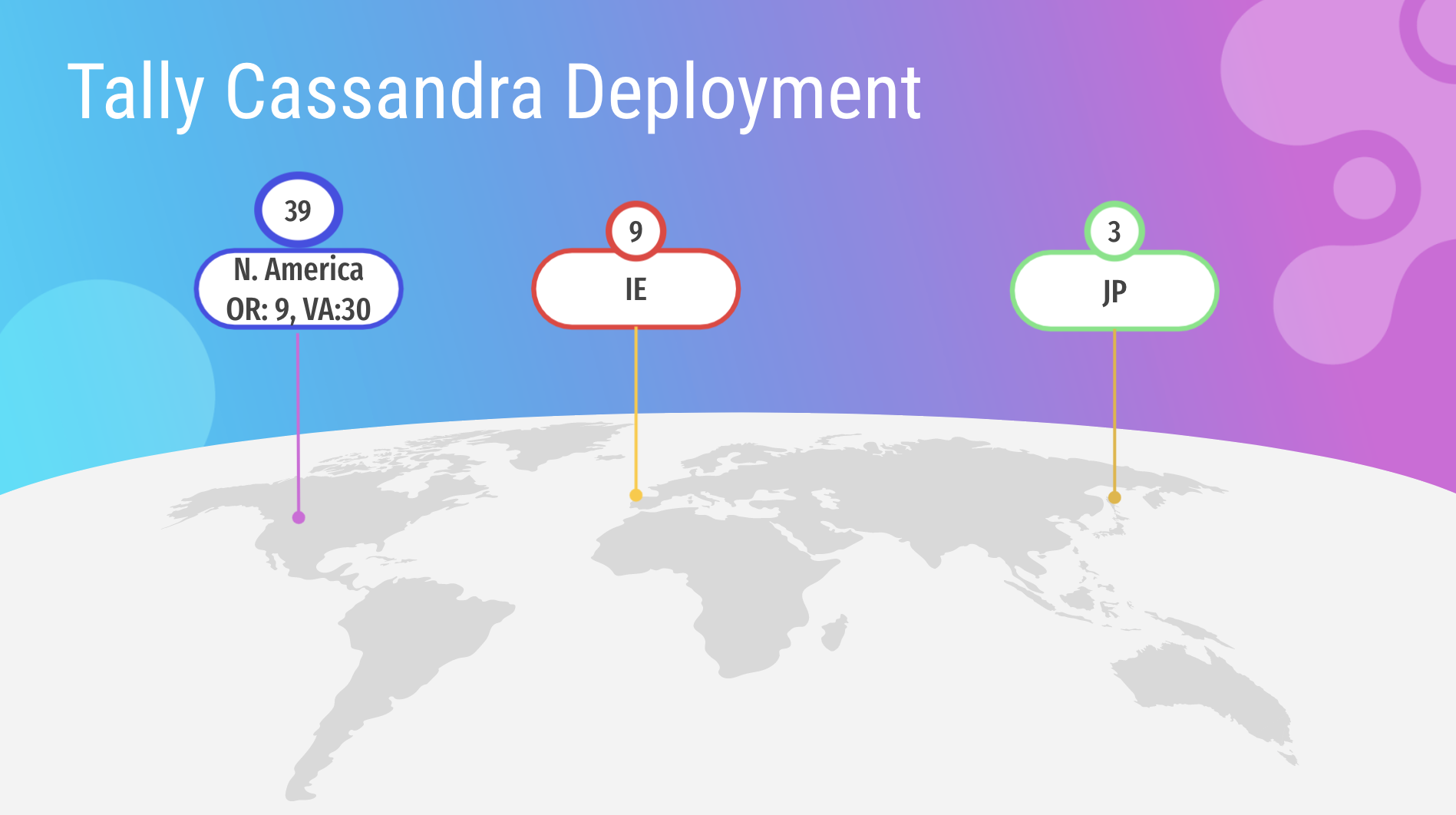
Keith showed the prior deployment of 51 nodes of Cassandra, with the bulk of them, 39, in North America; 30 in Virginia, and 9 in Oregon. “This was our original Tally deployment.” You can see we had most of our instances in North America where we advertised. We had nine of them in Ireland and three of them in Japan. As GumGum is a worldwide company we had to have relative data across the globe. This will become important later.”
However, GumGum was having issues. “Cassandra wasn’t really performing under our high loads and we’re not a Cassandra engineering place. We sort of struggled with that. Adding nodes for us was also really manual procedure. It was tough to go in and add nodes because we always had to tweak some configuration or do something else to make Cassandra work for us.”
“Also after the initial installation we lost whatever little bit of vendor support we had. We were out in the weeds and also stuck on an old version of Cassandra 2.1.5. I’m sure it was great at the time it was released. It wasn’t really supporting our growth.” Readers will note that Cassandra 2.1.5 was released in 2015.
Keith lamented about the common problem many companies trying to run their own Cassandra clusters face, “We didn’t have an engineering department to throw at it.” He described the “classic too many cooks in the kitchen” issues they’d face. “We’d have product engineering, data engineering and operations all come in and manage our Cassandra cluster with not exactly unpredictable results — but not results we wanted.”
GumGum Moves to ScyllaDB Cloud
“We thought about replacing this and we went through a bunch of different vendor selections. Originally we looked at DataStax. Great. A little pricey. Looked at DynamoDB. Not really right for us in terms of cost of performance. Plus we have to change the entire Tally backend. Redis? We’re pretty read heavy and we need some consistency in our writes. So redis wasn’t quite it.”
By comparison, “ScyllaDB was a drop-in replacement. It was also a managed system so we could really lay off a lot of the operational items to someone else that wasn’t us. And we could focus on making relevant contextual ads and serving them. So we dropped in ScyllaDB and it was great.”
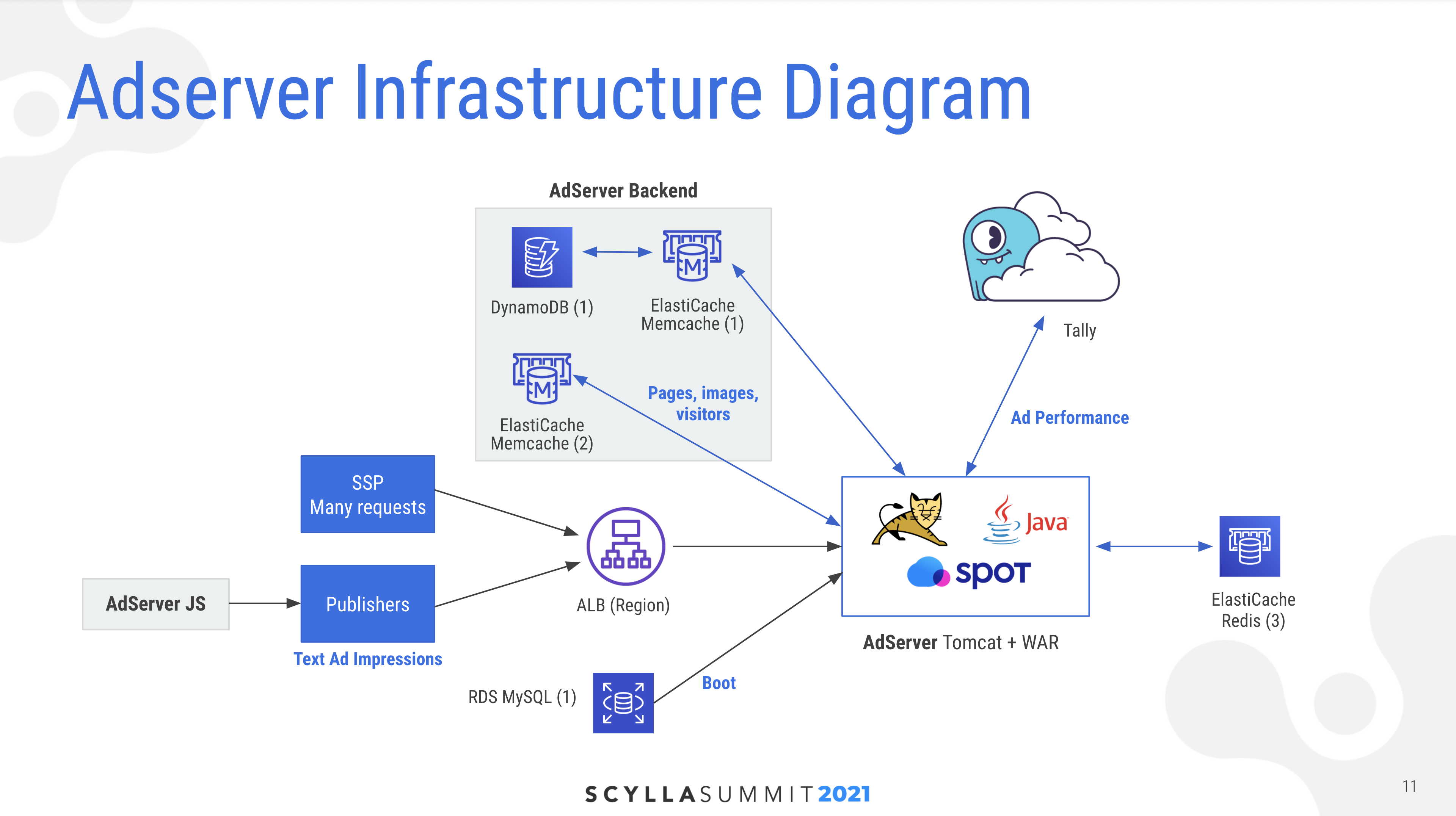
GumGum’s heterogeneous data environment uses a combination of SQL and NoSQL systems. Originally they used Apache Cassandra for their Tally engine; in time it was replaced by ScyllaDB.
Keith was more than a tad ironic after showing the updated slide. “This is magic. We dropped it in. Put it in the diagram. We’re done, right? Maybe not.”
“Let’s talk about architectures for a little bit. Cassandra by itself allocates thread and processor pools to handle a request and this is all scheduled by the OS. Great. It’s pretty easy to set up but you’ve got a couple problems. One is that this OS allocation can starve certain resources that need to read from your data store, or need to write to your data store.”
Keith pointed out that your OS can starve your request coming in. Or obfuscate some poor keyspace setup which users might have had. “You know Cassandra. Easy to get going. Hard to really operate.”
By comparison, “Sylla has an architecture that’s shard per core. A shared-nothing architecture. There’s a single thread allocated to a single core plus a little bit of RAM to actually handle a request for a data segment.”
While this is great because Keith didn’t have to worry about thread and processor allocations, “part of the downside of this architecture, which we ran into, is it can run hot and unbalanced from time to time. That can be based upon how you divvy up your keyspace.” Which in turn is based upon just how user requests come in.
“We had some pretty good initial results — we’ve dropped it in. We didn’t really have to change much in our query to the Cassandra [CQL] protocol. That was fantastic. Yet we’d still experience issues when the system was under load. We would get timeouts during reads lacking consistency. That was a little disconcerting for us.”
Looking into the issue, Keith noted “part of that was because we were using an old legacy Cassandra driver. The old drivers don’t have this awareness of how the underlying infrastructure works — the shard per core element I talked about. The new driver does.”
If you are interested, you can read more about what goes into making a ScyllaDB shard aware driver in this article, and see the difference it can make in performance here. You can also see what goes into supporting our new Change Data Capture (CDC) feature in this article.
Another issue was discovered moving from Proof of Concept (POC) to production. “Our initial POC wasn’t quite size proportional. We under-allocated what we needed in terms of nodes to move to ScyllaDB.” Another problem was that they originally set a replication factor of five for three availability zones, so there was a mismatch when trying to allocate servers across disparate datacenters. “I’ll let you do the math, but you should have those things match.”
For the hot partitions, Cassandra would just allocate additional threads and cores to obscure the imbalanced data problem. “We had to wind up modifying our schema inquiries for tables that return over 100 rows. We just had to figure out how to really shard our keyspace better.”
Another issue they uncovered was properly setting consistency levels on queries. For example, they had initially asked for a consistency level ALL on a global basis. “That slowed things down.” They set the consistency level to LOCAL_QUORUM instead. Keith’s pro tip was that when you move from Cassandra to ScyllaDB, you check your queries and understand how your sharding is working.
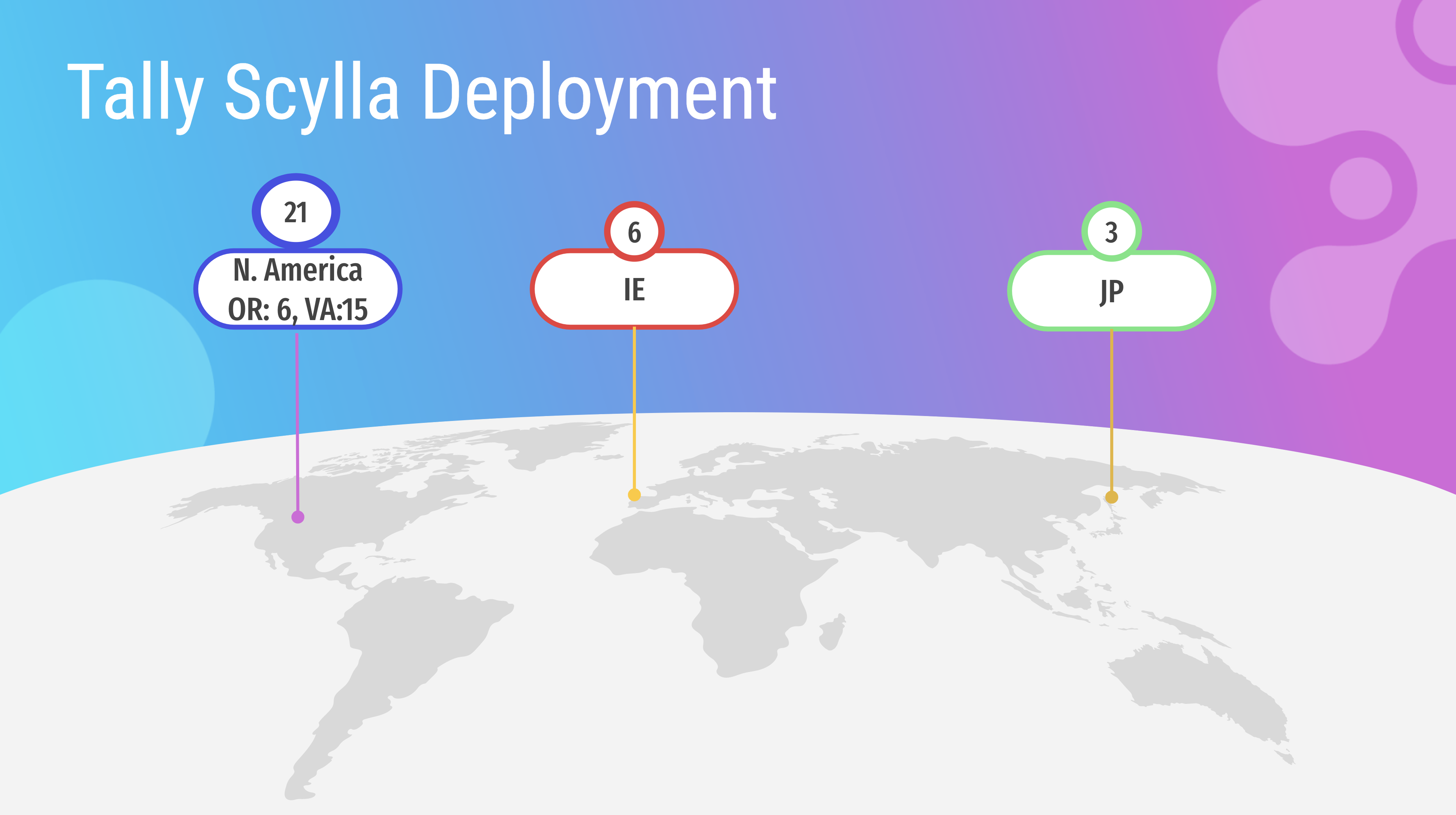
By moving to ScyllaDB Cloud, GumGum was able to cut its server count in Europe by a third, and their US cluster nearly in half.
In the end, GumGum ended with a lower amount of overhead and higher throughput. They reduced their cluster count from 51 instances to only 30 — 21 in North America (15 in Virginia, 6 in Oregon), 6 in Ireland and 3 in Japan.
The cost of licensing and servers for ScyllaDB Cloud was slightly higher than Cassandra, but this included support and cluster management, which they were able to offload from their team, which meant an actual savings of Total Cost of Ownership (TCO).
“To basically take 20 percent of two people’s staff time and an entire load off of our system — this was the big win for us. For just 13 grand we got a much better and more performant data system around the globe.”
Discover ScyllaDB Cloud
If you’d like to discover ScyllaDB Cloud for yourself, we recently published a few articles about capacity planning with style using the ScyllaDB Pricing Calculator, and getting from zero to ~2 million operations per second in 5 minutes.
It all begins with creating an account on ScyllaDB Cloud (NoSQL DBaaS). Get started today!