ScyllaDB powers real-time AI with low latency, high throughput, and billion-scale data.
Learn More



What is NoSQL?
NoSQL is a non-relational database that does not typically use Structured Query Language (SQL) to retrieve information. NoSQL databases were developed for use cases where a traditional relational database is not sufficient due to the size (volume), type (variety) or speed (velocity) of big data.

Learn about NoSQL at ScyllaDB University
What is SQL?
Structured Query Language (SQL) is a database management language, and currently the most popular method of accessing data from and inputting data to a relational database management system (RDBMS). SQL databases have been around for decades. First invented in 1974, SQL has continued to evolve over the years. Because it is such an important industry standard, it is controlled by the International Electrotechnical Commission (IEC). The latest version is formally defined in ISO/IEC 9075:2016.
SQL databases are comprised of records organized into tables. In a single table, data is organized into rows, labeled with a primary key, and with many columns (columnar databases) to hold values for different kinds of data – typically large data sets. These tables are related to each other through the use of foreign keys, which join together the different tables in the database.
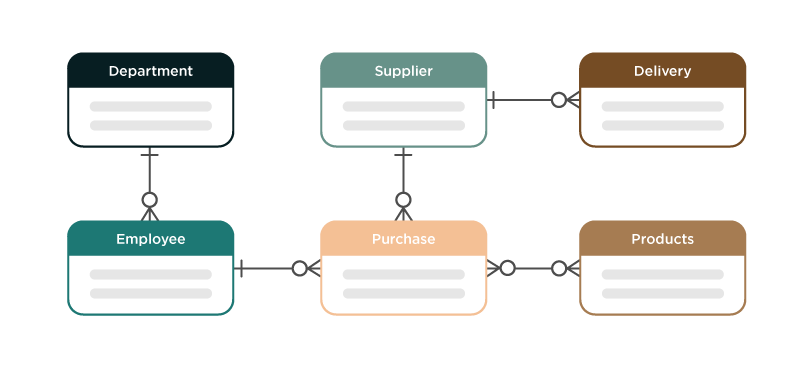
A schema is used to define all of the tables, their composite columns and data types, and the means of joining the tables together. The structure of a relational database can be illustrated by a design referred to as an Entity Relationship Diagram (ERD).
What’s the Difference between SQL and NoSQL?
What is a NoSQL Database?
A NoSQL database (NoSQL DB) is designed to handle massive amounts of distributed data. NoSQL database management systems store and retrieve data in a variety of ways other than the joined tabular models of relational database management systems (RDBMS). These databases can handle different types of data and can accommodate many kinds of data models including key-value stores, document, wide-column and graph formats.
The advantages of using them are for modern applications that need fast horizontal scaling and for those with extremely large, high velocity, distributed datasets. Fully managed NoSQL DBaaS solutions are increasing in popularity for use cases where a team of experts is needed to manage the complexity and upkeep of such databases.
NoSQL Database History
The term “NoSQL” was coined by Carlo Strozzi in 1998. He had invented a form of RDBMS that used a different form of data access than SQL. Note that his database was still a relational database — tables still had joins — but the method of accessing it, using Unix pipes, did not rely on the SQL language.
Modern versions came about a decade later with the advent of massive Internet e-commerce platforms and social media. While in the early Internet and web era many SQL databases were adapted for data applications (such as the use of open source MySQL to power WordPress sites), there were architectural limitations to SQL servers that made it too inflexible and unscalable for entire new classes of problems that needed to be solved. New data models were required. These included massive (but relatively simple) key value stores, highly distributed and highly available wide column stores, and more unique data models such as document based stores and graph databases.
Sometimes NoSQL database programs they are also referred to as “Not only SQL” or “NewSQL” to show that they may actually support Structured Query Language or can work in tandem with a SQL database. A SQL-based interface can still be useful, and these databases support hybrid operations, doing both SQL and Non-SQL related data management.

NoSQL and NewSQL: A Comparison of Distributed Database Systems
NoSQL in 5-Minutes
What are NoSQL Databases Used For?
Many types of NoSQL databases are used for applications with very large datasets and some operate in real time. They are used by enterprises that need features and capabilities more flexible than a traditional database, which can accommodate many kinds of data models in a variety of formats (flexible). A NoSQL database program provides the following data management features not found in relational databases:
- Caching — Improves application response when the same information is being sent to many users. NoSQL storage of data provides a solution without having to maintain a custom cache.
- Highly available, globally-distributed data — With worldwide user bases and demanding requirements for always-on services, data systems cannot just reside in a single internal datacenter. Many support global distribution of servers and automatic replication of data between them. This is called Cross Datacenter Replication.
- Fast access for big data — NoSQL software can handle the massive amounts of data in today’s systems quicker and with less cost than relational databases. “Fast” is often qualified in two ways: latency, which measures the speed of response times, often measured in the range of milliseconds or sub-milliseconds, as well as throughput, which measures the raw amount of data that can be processed, often measured in operations-per-second.
- Consistency — The consistency requirements of many NoSQL databases use cases are less rigid than for relational databases. For instance, when handling ephemeral, transient, rapidly-changing data. In such cases, some data loss is acceptable to maintain system availability. Today, the ACID model is not always necessary when an “eventual consistency” model promotes better performance. Some offer a range of consistency levels to choose from, including “tunable consistency,” where every database transaction may have its own consistency level.
Why Use NoSQL Databases?
The flexible architecture of NoSQL databases is among the top reasons why they are an excellent choice for today’s demanding application requirements. Other advantages for when to use NoSQL are as follows:
- Easier scalability — Can be easily scaled to handle massive amounts of data. Their distributed nature means increases in demand can be met by simply adding servers to the cluster.
- More efficiency — The looser data consistency models of NoSQL databases can result in better efficiency. When new information doesn’t have to be updated across the entire database in real time, resources can be directed to more critical issues.
- Simple documents — Document-oriented NoSQL databases store data as simple documents, which leads to easier data manipulation than the data mapping required in SQL databases.
- Always on — The distributed nature allows them to always remain on for enterprises that require non-stop service.
Why Do We Need NoSQL Database?
NoSQL database systems serve as an alternative to traditional relational or SQL databases. They offer numerous advantages for the right users and are designed to address specific use cases and challenges.
Advantages of NoSQL Databases
NoSQL databases offer flexibility and are most effective when used for scenarios that align with their strengths. SQL databases enforce ACID (Atomicity, Consistency, Isolation, Durability) guarantees and are used where transaction-oriented, schema-based data stores are essential. Some applications use both NoSQL and SQL databases for different use cases.
NoSQL databases offer a number of advantages compared to SQL databases:
Scalability. NoSQL databases typically scale horizontally, which means users can add more servers or nodes to the database cluster to handle increasing loads. This allows them to handle high traffic and data volume easily.
Horizontal partitioning and sharding. On a related note, NoSQL databases support horizontal partitioning and sharding. This allows users to distribute data across multiple servers or nodes to maintain performance as data expands.
Flexibility and schema-less design. NoSQL databases often use a schema-less or schema-flexible data model, allowing users to store data without a fixed schema. This flexibility is especially useful in agile development scenarios where the data structure is evolving or unpredictable and it eliminates extra work for database administrators.
Performance. NoSQL databases are optimized for workloads like read-heavy and write-heavy operations. This specialization can improve performance for particular tasks.
Variety of data models. Intuitively, there are different types of NoSQL or “not only SQL” databases to improve the data modeling and query efficiency for various use cases. For example, MongoDB and CouchDB are document databases, and Amazon DynamoDB and Neo4j are distributed databases, the latter also being a graph database—but they are all NoSQL databases as well.
Distributed and fault tolerant. By distributing data across multiple servers or data centers automatically, NoSQL databases help ensure high availability.
Support for data regardless of structure. NoSQL databases handle unstructured or semi-structured forms of data effectively, including binary data, JSON, and XML.
Cost-effective. NoSQL databases can run on commodity hardware and scale efficiently without additional costly investment.
Use Cases: When to Use a NoSQL Database
There are many industries now that typically choose NoSQL for their business. Here are some specific use cases and verticals for NoSQL databases:
Web and mobile applications. NoSQL databases store and retrieve content in dynamic websites like content management systems (CMS). They also manage sessions, user profiles, and user-generated content in social media apps.
E-commerce. NoSQL databases manage shopping cart data, provide personalized product recommendations, and store and retrieve product information in online stores.
Gaming. NoSQL database systems store player data, scores, and rankings and handle real-time game state and communication between players.
IoT (internet of things). Sensors and IoT devices generate massive amounts of data and event logs that NoSQL databases store, process, and manage.
Big data and analytics. NoSQL databases analyze, store, and process large volumes of data from logs, web servers, applications, and systems for analytics.
Content management and publishing. These databases are used in digital asset management (DAM), news, and media to store and manage multimedia assets like images, videos, and audio and handle content distribution, archives, and user-generated content.
Real-time analytics. NoSQL databases offer dashboards for tracking and analyzing real-time data for operational insights and detecting anomalies and fraud patterns in real-time transactions.
Ad tech. These databases store ad creatives, targeting information, and ad performance data for analysis of user clickstream data and ad targeting.
Healthcare. Healthcare organizations can store and manage electronic health records (EHR) including collecting and analyzing sensitive, real-time patient records and medical data.
Finance. In finance, NoSQL databases offer safe storage for financial and trading data for risk assessment and portfolio management.
Supply chain and logistics. In this vertical, NoSQL databases are used to manage and track inventory levels and supply chain data and optimize delivery routes and logistics operations.
Pros and Cons of NoSQL
Briefly, SQL databases take a traditional approach to data that is best-suited for applications with structured data and a need for strong data integrity. NoSQL databases typically offer improved performance. They take a more flexible approach that is better for applications with data that changes rapidly, high scalability requirements, and flexible data models.
Here is a closer look at some of the pros and cons of NoSQL database management systems:
NoSQL Pros
Continuous availability. NoSQL databases store data across servers, locations, and regions to ensure zero downtime and eliminate any single point of failure.
Query speed. NoSQL databases deliver high performance, real-time query capabilities, especially when working with massive volumes of data.
Agility. NoSQL databases are known for their flexible structure that more readily supports big data. NoSQL databases allow developers to work more easily with a wider range of data types and connect various kinds of data models across many servers.
NoSQL Cons
No standardized language. No standard language (like SQL) means a steeper learning curve for developers in many cases.
Smaller user community. The user community for NoSQL is growing rapidly, but it’s still smaller, which can make solving unknown and undocumented issues and finding expert advice a little harder.
Inefficient for complex queries. Although NoSQL databases can handle these queries, particularly when complex join requirements increase, they become less efficient. This is exacerbated by the lack of a standard interface to connect complex queries.
Lack of consistent retrieved data. NoSQL databases are distributed so they offer very fast performance. However, this comes at the sacrifice of one of the ACID guarantees—for most NoSQL systems that follow a BASE model of eventual consistency, the “C” is the element that changes. Practically speaking, the difference is minimal for most applications.
SQL Pros
ACID compliance. Only SQL databases offer a rigid enough data structure to provide the guarantees of true ACID properties (atomicity, consistency, isolation, and durability). Strict ACID compliance is typically best for applications that demand very high levels of data integrity at all times.
Standardized schema. These databases are best-suited to handle structured data with well-defined schemas.
Large user community. SQL databases are well-established, with a large community of developers, extensive documentation, and a wealth of tools and libraries.
SQL Cons
Hardware. SQL databases rely on vertical scaling structures for their hardware, demanding additional redundancy and failover mechanisms and adding hardware costs.
Data normalization. An artifact of high storage costs, relational databases attempt to negate data duplication, so lookups and joins are necessary to connect unique information. At scale this can become a slow process.
Rigidity. SQL databases are not well-suited for storing unstructured or semi-structured data like JSON, XML, or hierarchical data.
Resource-intensive scaling. At massive scale, data storage can become prohibitively expensive in SQL databases, especially when dealing with high traffic and large datasets. Vertical scaling can be limited and excessively costly.
SQL Database Examples
| Db2 | IBM’s relational database, originally released in 1983 and created to run on mainframes; over time it was also ported to Unix and Windows; now supports Linux servers. |
| MariaDB | An open source SQL server, forked from MySQL; was created in 2009 when MySQL was acquired by Oracle. |
| MemSQL | A distributed SQL server designed to run from memory (RAM) for fastest performance. |
| Microsoft SQL Server | Microsoft’s SQL server, originally designed to run on OS/2, became the mainstay of databases to run on Microsoft Operating Systems. In 2017 it was ported to run on Linux. |
| MySQL | An open source SQL server widely adopted by web and application developers. In 2008 it was acquired by Oracle; now available as both open source and proprietary enterprise editions. |
| Oracle | First released in 1979, Oracle became and remains widely adopted in enterprises over the next decades. |
| PostgreSQL | An open source SQL server that grew out of, and eventually replaced, the 1980s Ingres project at UC Berkeley. |
When to Use Relational Database vs NoSQL
Relational database management systems (RDBMs) are ideal for complex, interrelated, structured data. SQL databases store data in tables and rely on well-known structured query language (SQL).NoSQL systems easily manage large amounts of data, and data structure is not important for their use. A NoSQL database vs SQL databases offers flexibility in data models and is schema-less.A NoSQL database structure is flexible enough to allow a wide range of data storage formats, including:
- Key-value pairs
- Columnar databases
- Graph databases
- Document-oriented
- NoSQL databases
One key difference between SQL and NoSQL databases is that SQL databases offer ACID guarantees for data (atomicity, consistency, isolation, durability). Thus, relational databases are typically used for applications with well-defined transactions, such as banking and traditional businesses.
The NoSQL vs relational type of database sacrifices some of the ACID properties in favor of better scalability and distributed processing. NoSQL is often the first choice for real-time analytics, content management systems, IoT applications, and scenarios where flexible performance is critical.
Here are some general tips for when to use NoSQL vs SQL:
Use SQL vs NoSQL databases when:
- The data has a well-defined structure with complex relationships;
- There is a need for transactions with ACID properties;
- Strong consistency and data integrity are required;
- The application has relatively low scalability requirements.
Use NoSQL vs SQL database management systems when:
- The type of data is unstructured or semi-structured, and its schema may evolve over time;
- There is a need to scale horizontally, and handle massive amounts of data and high throughput;
- Flexibility in data modeling is more important than strict consistency;
- A goal is building real-time applications that demand low-latency access to data;
- A goal is storing and processing diverse data types efficiently.
NoSQL vs SQL Performance Comparison
In terms of NoSQL vs SQL performance, scaling, and other benchmarks, these databases have different characteristics and trade-offs. Ultimately their performance and advantages will depend on the user’s workload and goals.
Relational databases typically excel in handling complex SQL queries involving joins and aggregations—but this is especially true when the data volume is not excessively large. They optimize for transactional consistency and ACID properties, which can sometimes impact performance under high load.
In terms of NoSQL vs SQL speed, the former are generally designed for high-performance, low-latency access to data. They prioritize horizontal scalability and can handle massive volumes of read and write operations distributed across multiple nodes. However, the performance may vary based on the specific data model and workload.
See this post for more about NoSQL vs SQL performance benchmarks.
SQL vs NoSQL Advantages and Disadvantages: What to Consider
When you consider why use NoSQL vs SQL databases, there are a few standout advantages and disadvantages of each type to be aware of:
Advantages of SQL vs NoSQL databases
Data integrity. Relational databases enforce ACID guarantees, ensuring data integrity and reliability, especially in transactional systems.
Mature technology. Relational databases offer robust features, mature tooling, and widespread support in the industry.
Powerful query language. SQL offers a standardized means for manipulating data, and enabling complex queries, joins, and aggregations.
Schema enforcement. Relational databases rigidly maintain data consistency and facilitate data validation.
Comprehensive indexing. Relational databases support various indexing techniques, allowing efficient retrieval of data based on different criteria.
Disadvantages of relational databases
Scalability limitations. Relational databases may be challenged by massive volumes of data or high-throughput workloads, particularly in distributed environments.
Schema rigidity. Modifying the database schema can be complex and may require downtime or schema migrations, making it less suitable for agile development and evolving data requirements.
Performance overhead. The overhead of maintaining ACID properties and enforcing relational constraints can impact performance, especially in write-heavy applications.
Vertical scaling. Relational databases typically require adding more resources to a single server to scale, which can be costly and have practical limits.
How NoSQL vs SQL Advantages Impact the Choice
What are the advantages of NoSQL databases over RDBMS? Most of this is dictated by the user’s specific goals and workload, but there are a few general benefits of NoSQL vs SQL:
Flexible data model in NoSQL vs SQL: when to use
This is among the key NoSQL vs SQL differences, because relational databases enforce a rigid schema that requires upfront design. Any changes to it can be cumbersome and may require downtime or schema migrations.
Greater flexibility in data modeling, and data querying and storage in various formats without predefined schemas are among the main advantages of using NoSQL databases. This flexibility makes them suitable for agile development, denormalization, and applications with evolving data requirements.
Consistency and availability in relational database vs NoSQL database
Relational databases vs NoSQL databases prioritize strong consistency, but maintaining it across distributed systems can be challenging and may introduce latency. The trade-off in favor of eventual consistency is among the advantages of NoSQL, because it makes this kind of database better suited for distributed and fault-tolerant architectures.
SQL vs NoSQL scalability
Relational databases traditionally scale vertically, meaning that improving performance requires upgrading hardware resources like CPU, RAM, and storage on a single server, a cost-limited approach.
Horizontal scaling is another of the advantages of NoSQL vs SQL, because it allows users to add more servers or nodes to distribute the workload and accommodate growing data volumes. This allows for better scalability and fault tolerance, although it may require more complex distributed systems management.
Disadvantages of NoSQL databases
Lack of ACID transactions
Many NoSQL databases sacrifice strong consistency and ACID guarantees for better scalability and performance, which may not be suitable for all use cases.
Limited query capabilities
Some NoSQL databases offer querying capabilities that are relatively limited compared to SQL-based relational databases. This can make complex data analysis and reporting challenging.
Learning curve
NoSQL databases often require users to learn new concepts and programming languages.
Eventual consistency
NoSQL databases often rely on eventual consistency models, which can cause inconsistencies in data in distributed systems. This requires careful application design, strong developer chops, and may take extra time in the error handling process.
SQL vs NoSQL security
In contrast to SQL databases, NoSQL databases tend to be less secure. Because they are less structured to allow faster access to data, they usually have fewer native security features and lack confidentiality and integrity attributes. Users also can’t segregate permissions in the same ways because NoSQL databases lack a fixed and well-defined schema by design.
Limited query capabilities
Some NoSQL databases offer querying capabilities that are relatively limited compared to SQL-based relational databases. This can make complex data analysis and reporting challenging.
How is Data Structured in a Relational Database vs NoSQL Database?
Relational databases structure data in tables. Each table is organized into rows and columns defined by a schema, which specifies the data types stored in the table and any constraints or relationships with other tables. Primary and foreign keys also establish relationships between tables and maintain data integrity.
There are several kinds of NoSQL databases, each with its own data model and structure:
Column-family stores such as ScyllaDB organize data into columns grouped into families. Each row can have a different number of columns, and columns are stored to enable efficient read and write operations for sparse data sets. Column-family stores are well-suited for analytical workloads and time-series data.
Document-oriented NoSQL databases such as MongoDB collect data in documents, with each capable of a different structure, and fields within documents capable of variance. Documents may be organized into collections or buckets.
In offerings such as Redis, data is stored in key-value pairs, and may be any type, such as strings, numbers, or complex objects. Each key is unique and maps to a corresponding value. Key-value stores offer high performance for simple read and write operations but may lack advanced querying capabilities.
Graph databases such as Neo4j represent data as a network of nodes and their relationships. Queries typically involve complex relationship analysis of connections between nodes.
NoSQL vs SQL Examples and Use Cases
Here are some common SQL vs NoSQL use cases:
NoSQL vs SQL for ecommerce. In terms of transactional systems, SQL databases are more common in this space. This is because of the need for applications where ACID transactions are critical, such as banking systems, e-commerce platforms that store customer information, and inventory management systems.
Business applications. Complex data relationships, reporting, and ad-hoc queries, such as customer relationship management, enterprise resource planning, and HR systems.
Data warehousing. Aggregating, transforming, and analyzing structured data from multiple sources for business intelligence and decision-making.
Regulatory compliance. Strict regulatory requirements for data integrity, audit trails, and access controls, such as in healthcare, finance, and government.
NoSQL database use cases include:
NoSQL vs SQL for analytics. For big data SQL vs NoSQL the latter is better-suited, and is optimized for big data analytics and real-time processing applications that require high throughput, such as IoT, sensor data processing, and log analytics. Certainly there are techniques for speeding queries in SQL systems, but there is no question whether it is more advantageous to choose NoSQL or SQL for big data.
Content management and personalization. NoSQL databases are ideal for social media platforms, recommendation engines that require flexible data models, and other systems that demand rapid development and scalability to handle dynamic, personalized content.
High-volume web applications. NoSQL databases are commonly used for social networks and gaming platforms that demand horizontal scalability, low-latency access to data, and sufficient fault tolerance for multiple concurrent users and unpredictable workloads.
Agile teams. NoSQL databases are better for rapidly evolving data, where developers need the flexibility to iterate quickly without rigid constraints.
Geospatial and graph applications. NoSQL databases, particularly graph databases, are used in applications that involve complex relationships and require efficient traversal of graph structures.
Combination of SQL and NoSQL Databases
Using SQL and NoSQL together allows for the strengths of both to address different aspects of data management:
Adopt a polyglot persistence approach. For example, use a relational database for complex queries and a NoSQL database for high-volume, flexible data models.
Replicate data between types of databases. This maintains consistency and enables different types of queries. Implement data replication mechanisms or custom synchronization scripts to keep data current between databases.
Design applications as loosely coupled microservices. Some microservices can use relational databases for transactional data management, while others might use NoSQL systems for specialized processing or caching.
Implement the Command Query Responsibility Segregation pattern. This separates the read and write operations into different data stores. Use a relational database for handling write operations (commands) and a NoSQL database optimized for read-heavy workloads for query operations (queries).
Perform hybrid queries or aggregations. Combine data from relational and NoSQL databases at the application layer. Fetch data from multiple databases and perform joins or transformations in the application code to fulfill complex query requirements.
Adopt a data lake architecture. A NoSQL database may be ideal for storing structured and unstructured data centrally, while a relational database may be best for handling data warehousing and analytics.
Use event sourcing. Capture and store all changes to the application’s state as a series of immutable events in a NoSQL database optimized for high write throughput and use a relational database for materialized views or snapshots to support query operations.
Use polyglot object-relational mappers. These support multiple database backends, allowing unified interaction with both relational and NoSQL databases through a single interface. This approach simplifies development and maintenance by abstracting away the differences between database types.
NoSQL Database Comparison
The NoSQL database structures include the following classifications:
Key-value stores — Each item is stored as a “key” (unique identifier) along with its value. This is the most simple version of a NoSQL database program. Examples include Redis and Aerospike.
Document databases — Each key is paired with a structured data “document” (data structure). Documents can contain many different key-value pairs in a nested, hierarchical format, such as Javascript Object Notation (JSON).
Wide-column stores — Designed to handle large dataset queries. Data is stored in columns instead of rows, which makes it more efficient to query data in frequently-referenced columns, and to store sparse data (where rows may have only a few data values spread across the many columns). Examples include such as Apache Cassandra, HBase and Scylla.
Graph stores — Hold social connections and other networks of data information. Examples include Neo4J and Giraph.
In general, this type of database has active communities of developers who contribute to open source, and thus technically offering free NoSQL databases. Many of these also provide a commercial, enterprise NoSQL database that add additional features, as well as production support. A free NoSQL database program typically only provides community support, with no guarantee that issues will be fixed or new features added in a timely fashion. Small projects can generally begin development on a free open source NoSQL database, and then upgrade to an enterprise version once the project achieves traction.
Free NoSQL is typically available to run locally, on a developer’s machine but also can be hosted and managed in the cloud. Many NoSQL database providers also provide free NoSQL hosting that runs in the cloud as database-as-a-service (NoSQL DBaaS) offerings. Developers can easily find a free NoSQL database online as well as free NoSQL database hosting from a range of providers.
Using SQL and NoSQL Together
Modern enterprises do not view SQL and NoSQL as an either/or proposition. A survey at the latest DeveloperWeek conference found that 44 percent of organizations use multiple databases. Among those, 75 percent use a combination of SQL and NoSQL databases.
Many organizations take advantage of the ways that these two databases can complement each other. Each brings its own strengths, making the sum greater than each part.
SQL databases handle structured data and standardize how elements relate to one another. NoSQL databases are popular when flexibility is a concern. They can create unique data structures that include documents, graphs or columns.
How is Data Modeled in a NoSQL Database?
Schemas are often exhibit a more flexible design without enforcing the normalized data forms and pre-defined schemas and structures common in SQL databases.
One benefit is the ability to easily transition from simple key-value stores to complicated graph databases when integrated with a graph database.
Since this is an emerging technology, solutions for NoSQL data modeling are still being developed. As more enterprises utilize NoSQL database programs features, the design will mature with the following benefits:
- Reusable data model design patterns for more efficient application development.
- An inventory of unified NoSQL data models that can support different NoSQL products.
- Automated data model extraction from application source code.
- Automated code-model-data consistency validation.
- Strong control for application and data model change management.

Masterclass: Data Modeling for NoSQL Databases
Looking for extensive training on about data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
Data Migration in NoSQL Databases
NoSQL data migration refers to the process of transferring data from relational databases (SQL) to NoSQL databases or between different NoSQL systems. It’s a critical task for organizations transitioning to more flexible, scalable databases that handle unstructured or semi-structured data, especially for cloud applications, big data, or real-time processing.
Key tasks for NoSQL data migration include understanding data structures, assessing database compatibility, and ensuring data consistency across databases.
Challenges in SQL to NoSQL migration involve data transformation, as relational databases follow structured, tabular formats, while NoSQL databases like MongoDB or Cassandra support more dynamic data types like documents, key-value pairs, or wide-column stores. Data integrity and downtime risk are additional concerns during the migration process.
Planning for data consistency, employing tools for automated migration, and performing incremental data transfers can mitigate these risks.
Are NoSQL Databases Faster than SQL Databases?
Key-value systems often have far simpler schemas, and thus, they tend to be faster than SQL systems. SQL databases tend to allow for more complex queries, exemplified by making JOINs across tables. Naturally, there is a computational cost, and time required, for such complexity. There are many additional architectural factors that go into a specific database’s performance, such as the use of in-memory tables or RAM caches, various data structures that can help efficiency (such as bloom filters) and so on. Even the programming language a database is written in can affect system performance, as it may allow for, or prohibit, low-level hardware optimization. Thus it is not possible to categorically say that NoSQL databases are always faster than SQL databases (or vice versa). Users need to create and conduct realistic tests to see how various databases perform under specific conditions, data models, and querying patterns.
How are NoSQL Databases Indexed?
They are indexed with keys that correspond with the location of an associated piece of data. The most common indexing methods are B-Tree, T-Tree, O2-Tree, as well as Log Structured Merge (LSM) tree indexing.
B-Tree Indexing – Allows a variable number of child nodes, which results in more unused space and less tree balancing. The B+Tree is a popular version of B-Tree indexing where every key must reside in the leaves.
T-Tree Indexing – Features three kinds of nodes: A T-Node that has a right and left child, a leaf node with no children, and a half-leaf node with only one child. Each node stores multiple tuples, or lists. The use of binary search results in more efficient storage.
O2-Tree Indexing – Created to enhance existing indexing methods by placing tuples within each leaf node. Advances the concept of a Binary-Search tree.
Log Structured Merge (LSM) Tree Indexing – Creates an in-memory hash table (or memtable), and periodically write these structures to disk in immutable form, known as a Sorted Strings Table (SSTable). Over time, these SSTables are merged in a process known as compaction.
NoSQL Database Use Cases
The most used NoSQL databases are for high performance speed and volume. Big data and NoSQL databases are a good match because of flexible design that allows for a many kinds of datasets in many different formats.
The trade-off for speed within a large dataset is less consistency. While SQL databases provide the highest level of verification, NoSQL databases do not promise total data consistency.
But with companies like Amazon where each transaction requires a tremendous amount of read-write activity, a SQL database would not be able to match the amount of speed and scaling required for millions of real-time transactions. That is why NoSQL ecommerce and NoSQL for transactional data are vital for applications that serve high volumes of customers in real time.

Learn the Difference Between Data Modeling for NoSQL and Data Modeling for SQL
SQL Database Examples
The NoSQL database examples include the following:
| Database | NoSQL Data Models | Description |
|---|---|---|
| Aerospike | Key-value | A flash-optimized and in-memory open source NoSQL database |
| Amazon DynamoDB | Key-value, Document | Cloud-based database only offered on AWS |
| Apache Cassandra | Column Time series |
An open source highly scalable and distributed database created at Facebook to handle massive amounts of structured data. |
| Apache CouchDB | Document | Open source and web-oriented database. |
| Apache HBase | Column | Open source and column store database developed as a part of Hadoop. |
| Google Bigtable | Column | A compressed, high performance, proprietary data storage system. |
| JanusGraph | Graph | An open source, distributed graph database under The Linux Foundation; works on top of ScyllaDB or Apache Cassandra. |
| Microsoft Cosmos DB | Document Columnar Graph |
Proprietary, schema-agnostic and horizontally scalable. |
| MongoDB | Document | Document-oriented database by MongoDB. |
| Neo4j | Graph | ACID-compliant and transactional graph database with native graph storage and processing. |
| Oracle NoSQL Database | Key-value | Scalable, distributed NoSQL database, designed to provide highly reliable, flexible and available data management. |
| Redis | Key-value Document Time series |
Data structure server with keys can contain strings, hashes, lists, sets and sorted sets. |
| ScyllaDB | Key-value Column Time series |
Enterprise and open source database which is a drop-in alternative to Apache Cassandra offering higher performance, lower latency and reduced cost. |