Nodes in a ScyllaDB cluster are symmetric, which means any node in the cluster can serve user read or write requests, and no special roles are assigned to a particular node. For instance, no primary nodes vs. secondary nodes or read nodes vs. write nodes.
This is a nice architecture property. However, there is one small thing that breaks the symmetry: that is the seed concept. Seed nodes are nodes that help the discovery of the cluster and propagation of gossip information. Users must assign a special role to some of the nodes in the cluster to serve as seed nodes.
In addition to breaking the symmetric architecture property, do seed nodes introduce any real issues? In this blog post, we will walk through the pains of seed nodes and how we get rid of them to make ScyllaDB easier and more robust to operate than ever before.
What are the real pains of the seed nodes?
First, the seed node does not bootstrap. Bootstrap is a process that a new joining node streams data from existing nodes. However, seed nodes skip the bootstrap process and stream no data. It is a popular source of confusion for our users since users are surprised to see no data streamed on the new node after adding a node.
Second, the user needs to decide which nodes will be assigned as the seed nodes. ScyllaDB recommends 3 seed nodes per datacenter (DC) if the DC has more than 6 nodes, or 2 seed nodes per DC if the DC has less than 6 nodes. If the number of nodes grows, the user needs to update the seed nodes configuration and modify scylla.yaml on all nodes.
Third, it is quite complicated to add a new seed node or replace a dead seed node. When a user wants to add a node as a seed node, the node can not be added into the cluster as a seed node directly. The correct way to do this is to add the node as a non-seed node, then promote it as a seed node. This is because a seed node does not bootstrap which means it does not stream data from existing nodes. When a seed node is dead and the users want to replace it, they can not use the regular replacing node procedure to replace it directly. Users need to first promote a non-seed node to act as a seed node and update the configuration on all nodes, then perform the replacing node procedure to replace it.
Those special treatments for seed nodes complicate the administration and operation of a ScyllaDB cluster. ScyllaDB needs to carefully document those differences between seed and no-seed nodes. Users can make mistakes easily even with the documents.
Can we get rid of those seed concepts to simplify things and make it more robust?
Let’s first take a closer look into what is the special role of seed nodes.
Seed nodes help in two ways:
1) Define the target nodes to talk within gossip shadow round
But what is a gossip shadow round? It is a routine used for a variety of purposes when a cluster boots up:
- to get gossip information from existing nodes before normal gossip service starts
- to get tokens and host IDs of the node to be replaced in the replacing operation
- to get tokens and status of existing nodes for bootstrap operation
- to get features known by the cluster to prevent an old version of a ScyllaDB node that does not know any of those features from joining the cluster
2) Help to converge gossip information faster
Seed nodes help converge gossip information faster because, in each normal gossip round, a seed node is contacted once per second. As a result, the seed nodes are supposed to have more recent gossip information. Any nodes communicating with seed nodes will obtain the more recent information. This speeds up the gossip convergence.
How do we get rid of the seed concept?
To get rid of seen nodes entirely, you will have to solve for each of the functions seed nodes currently provide:
1) Configuration changes
- The seeds option
The parameter --seed-provider-parameters seeds= is now used only once when a new node joins for the first time. The only purpose is to find the existing nodes.
- The auto-bootstrap option
In ScyllaDB, the --auto-bootstrap option defaults to true and is not present in the scyllal.yaml. This was intentionally done to avoid misuse. It is designed to make the bootstrap process faster when initializing a fresh cluster, by skipping the process to stream data from existing nodes.
In contrast, the ScyllaDB AMI sets --auto-bootstrap to false because most of the time when AMI nodes start they are forming a fresh cluster. When adding a new AMI node to an existing cluster, users must set the –auto-bootstrap option to true. It is easy to forget setting the --auto-bootstrap option to true for AMIs and end up with a new node without any data streamed, which is annoying.
The new solution is that the --auto-bootstrap option will now be ignored so that we have less dangerous options and fewer errors to make. With this change, all new nodes — both seed and non-seed nodes — must bootstrap when joining the cluster for the first time.
One small exception is that the first node in a fresh cluster is not bootstrapped. This is because it is the first node and there are no other nodes to bootstrap from. The node with the smallest IP address is selected as the first node automatically, e.g., with seeds = “192.168.0.1,192.168.0.2,192.168.0.3”, node 192.168.0.1 will be selected as the first node and skips the bootstrap procedure. So when starting nodes to form a fresh cluster, always use the same list of nodes in the seeds config option.
2) Gossip shadow round target nodes selection
Before this change, only the seed nodes communicated within the gossip shadow round. The shadow round finishes immediately after any of the seed nodes have responded.
After this change, if the node is a new node that only knows the nodes listed in the seed config option, it talks to all the nodes listed in the seed option and waits for each of them to respond to finish the shadow round.
If the node is an existing node, it will talk to all nodes saved in the system.peers, without consulting the seed config option.
3) Gossip normal round target nodes selection
Currently, in each gossip normal round, 3 types of nodes are selected to talk with:
- Select 10% of live nodes randomly
- Select a seed node if the seed node is not selected above
- Select an unreachable node
After this change, the selection has been changed to below:
- Select 10% of live nodes in a random shuffle + group fashion
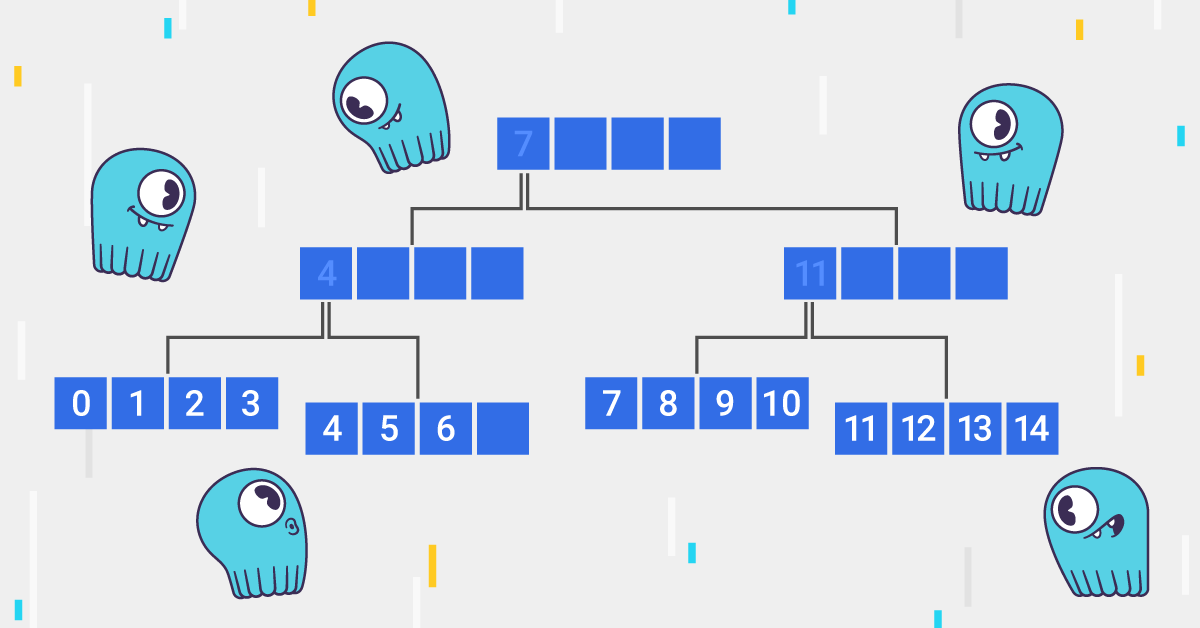
For example, there are 20 nodes in the cluster [n1, n2, .., n20]. The nodes are first being shuffled randomly. Then they are divided into 10 groups so that each group has 10% of live nodes. In each round, nodes in one of the groups are selected to talk with. When all groups have talked once, the nodes are shuffled randomly again and divided into 10 groups. This procedure repeats. Using a random shuffle method to select target nodes is also used in other gossip implementations, e.g., SWIM.
This method helps converge gossip information in a more deterministic way so we can drop the selection of one seed node in each gossip round.
- Select an unreachable node
Unreachable node selection is not changed. It is communicated in order to bring back dead nodes into the cluster.
4) Improved message communication for shadow round
Currently, ScyllaDB reuses the gossip SYN and ACK messages for the shadow round communication. Those messages are one way and are asynchronous which means the sender will not wait for the response from the receiver. As a result, there are many special cases in gossip message handlers in order to support the shadow round.
After this change, a new two way and synchronous RPC message has been introduced for communications in the gossip shadow round. This dedicated message makes it much easier to track which nodes have responded to the gossip shadow round and waits until all the nodes have responded. It also allows requesting the gossip application states that the sender is really interested in, which reduces the message size transferred on the network. Thanks to the new RPC message, the special handling of the regular gossip SYN and ACK message can be eliminated.
In a mixed cluster, the node will fall back to the old shadow round method in case the new message is not supported for compatibility reasons. We cannot introduce a gossip feature bit to decide if the new shadow round method can be used because the gossip service is not even started when we conduct a shadow round.
Summary
Getting rid of the seed concept simplifies ScyllaDB cluster configuration and administration, makes ScyllaDB nodes fully symmetric, and prevents unnecessary operation errors.
The work is merged in ScyllaDB master and will be released in the upcoming ScyllaDB 4.3 release.
Farewell seeds and hello seedless!
LEARN MORE ABOUT SCYLLA OPEN SOURCE