This post explores how the IOTA integration with ScyllaDB into its permanode software, Chronicle, to support real-world applications on the Tangle.
Introduction to IOTA
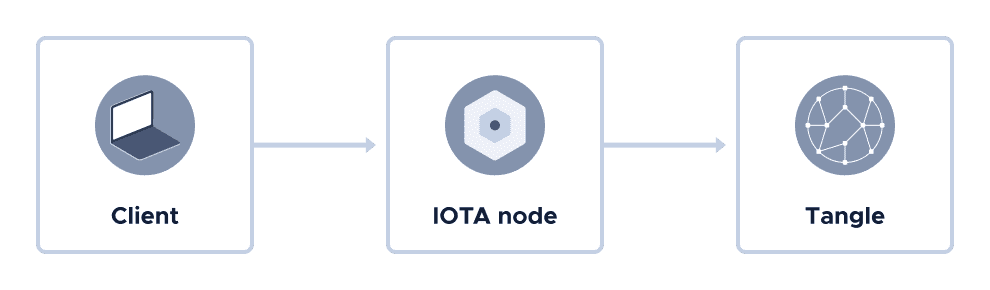
IOTA is an open-source distributed ledger technology (DLT), designed to support frictionless data and value transfer on the Tangle.
The Tangle is the distributed ledger that’s shared across all nodes in an IOTA network. Any client, anywhere in the world, is able to send transactions to any node, and that transaction will be validated and replicated across the rest of the network to form one version of truth.
Differences between the Tangle and blockchains
Blockchains and the Tangle both fall under the same top-level category: DLT. The main difference between the Tangle and a blockchain lies in its data structure, which gives the Tangle the following unique features:
- No transaction fees
- No miners
The blockchain data structure consists of a chain of sequential blocks, where each block contains a limited number of transactions. As a result, you can attach new transactions to only one place: A block at the end of the chain.
To secure the network against attacks, each block in a blockchain must be mined. Mining requires a lot of computational power, which is why miners are incentivized by transaction fees and block rewards.
Due to this block limitation known as the blockchain bottleneck, blockchain networks often experience slow confirmation times and high transaction fees.
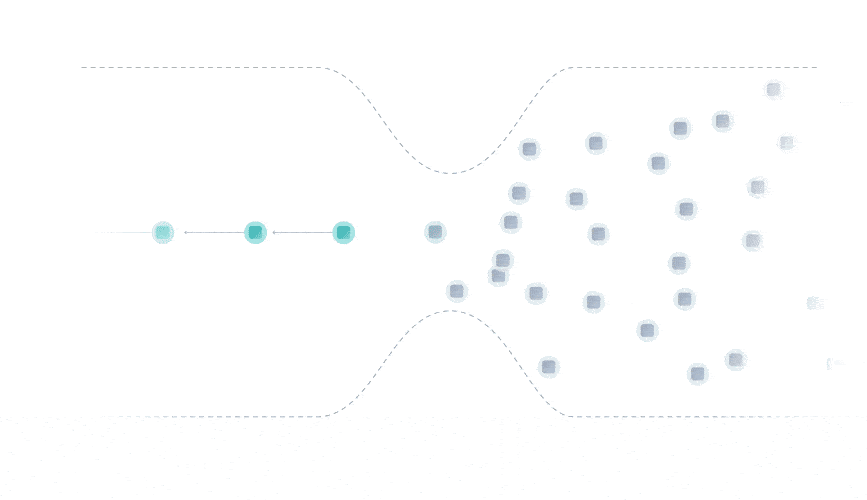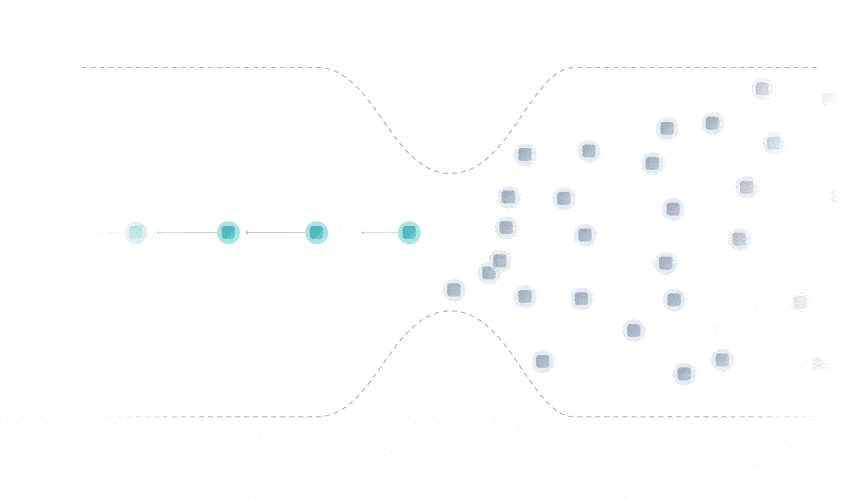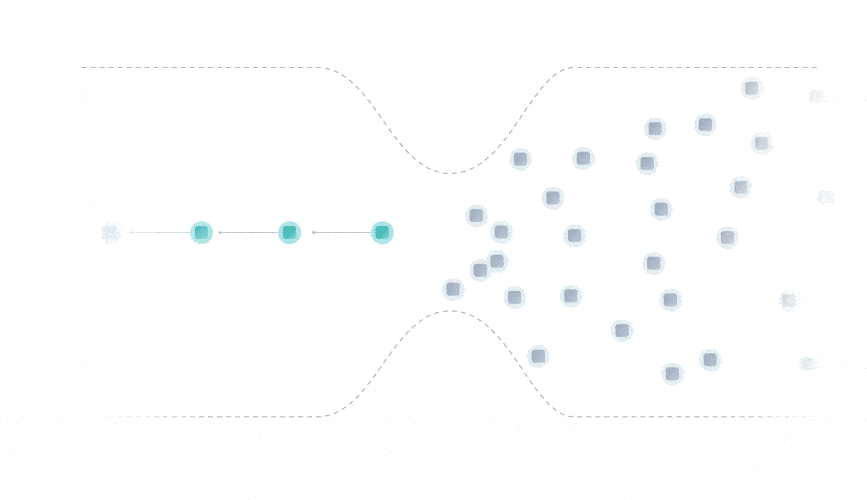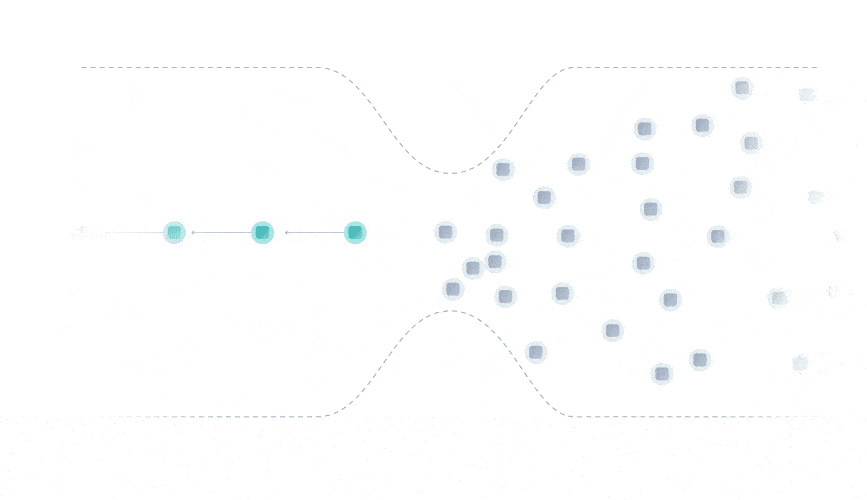
The Tangle data structure is a directed acyclic graph (DAG), where each transaction approves two previous ones.
Rather than being limited to a single place for attaching new transactions, you can attach transactions anywhere in the Tangle, which drastically reduces the limit on confirmation times.
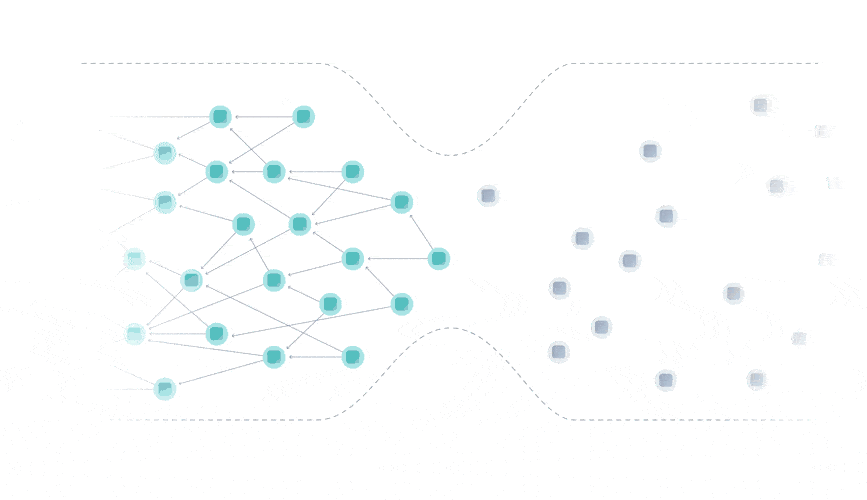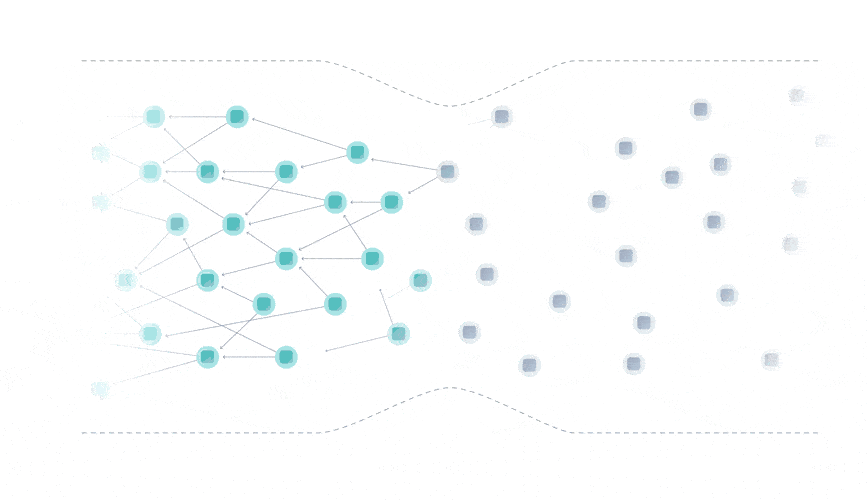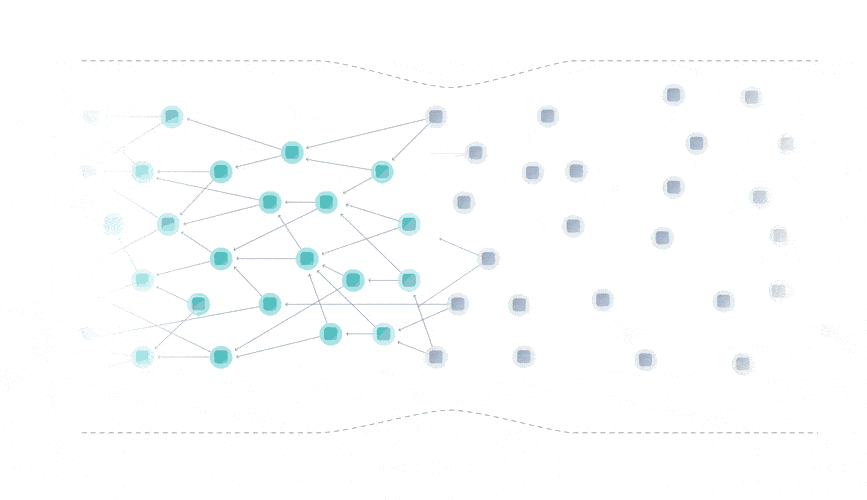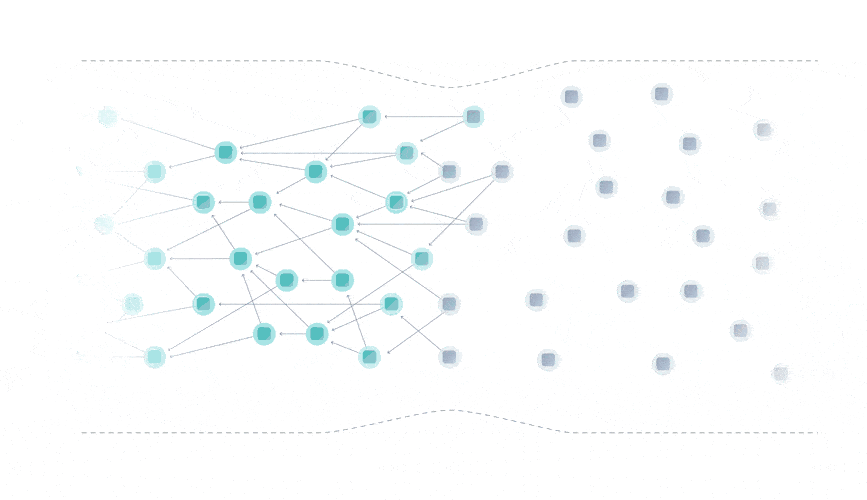
Instead of having miners, the Tangle is secured by a temporary finality device called the Coordinator that decides which parts of the Tangle are valid and should be confirmed.
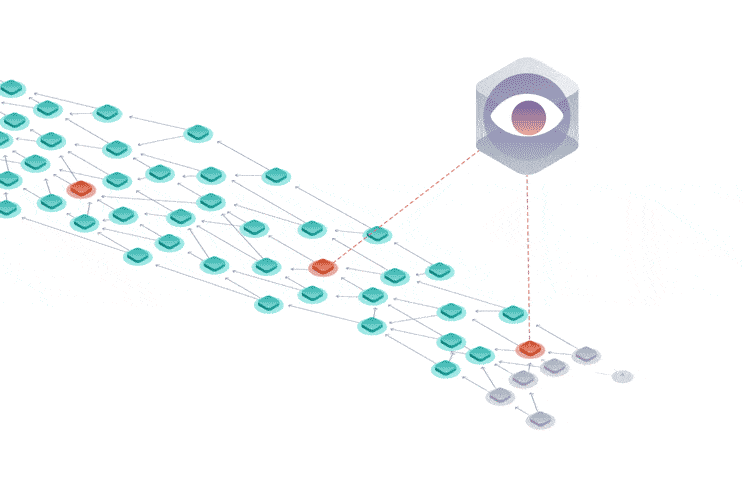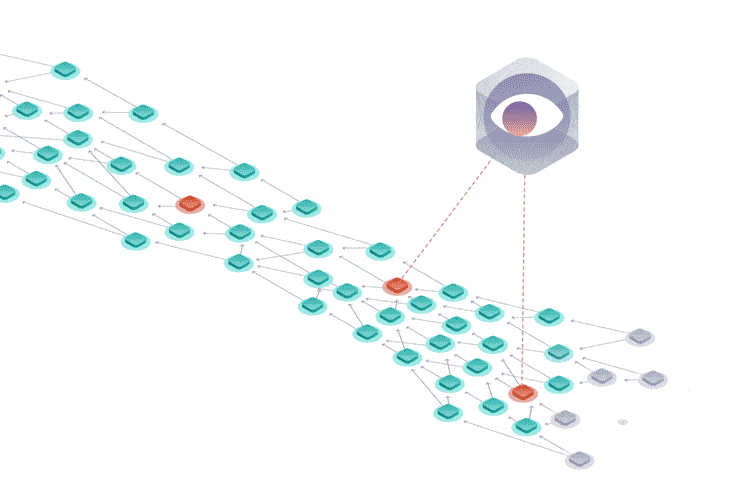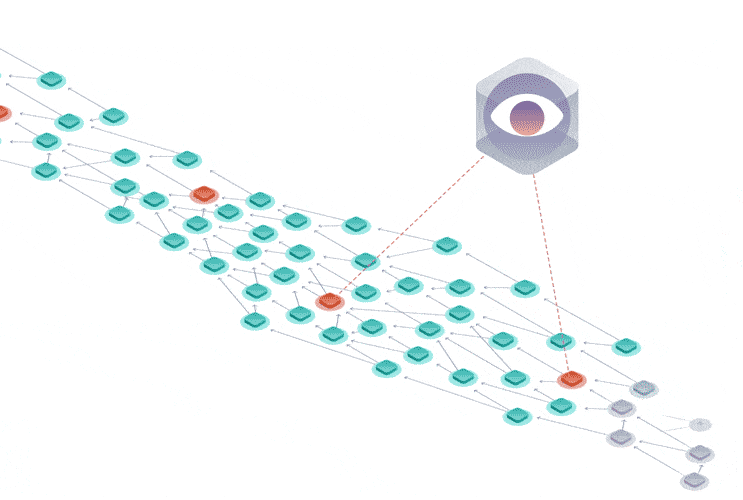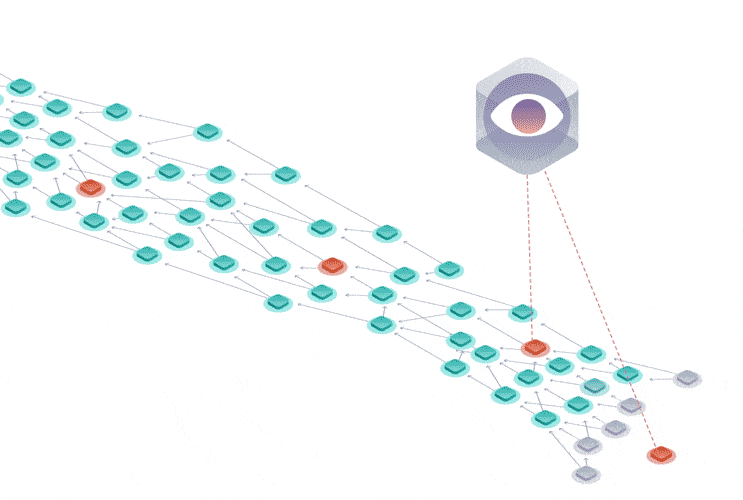
This device is set to be removed in a project called Coordicide to make the Tangle completely decentralized.
The IOTA Foundation
The IOTA Foundation is a non-profit that collaborates with the IOTA community and partners to deliver sustainable, real-world impact.
The goals of the IOTA Foundation are to:
- Research and implement the IOTA protocol
- Standardize the protocol to ensure its widespread adoption
- Develop production-ready open-source software
- Educate others about IOTA technologies and promote their use cases
The IOTA community
The IOTA community is made up of 250,000 members who play an active role in the development and adoption of IOTA technology.
Some notable community projects include:
About permanodes
Permanodes are devices that are designed to store the entire history of the Tangle. To do so, they do not validate transactions. Instead, their one goal is to take transactions from IOTA nodes and store them in a separate distributed database for others to query.
The case for a permanode
For IOTA nodes with limited storage, the Tangle can quickly fill up their database. This presents a problem for mobile devices, and even moreso, the Internet of Things, where IOTA is working on integration with low-level, resource-constrained devices. To combat this problem, nodes come with a feature called local snapshots that allows them to delete old transactions and keep their local copy of the Tangle small.
However, for many business use cases, data in transactions need to be stored for long periods of time. For example, financial data must be stored for 10 years in some cases, and identity data needs to be kept for at least the lifetime of the identity (in some cases your identity may need to survive even beyond your lifetime).
In order to enable these business use cases without putting a burden on nodes, the IOTA Foundation developed a permanode called Chronicle.
Why ScyllaDB
Chronicle uses ScyllaDB as a default distributed storage solution because it provides the following important features:
Fault tolerance: Users can set a replication strategy to determine how to replicate data to avoid a single-point of failure
- Data consistency: Users can set a consistency level to determine whether a read or write operation is successful
- Fast and efficient data queries: ScyllaDB uses LSM-based storage with high write throughput
- Time to live: Users can define the lifetime of their data
- Low operating costs: Licenses (including free and enterprise licenses) and operating costs are very favorable compared to other solutions
How ScyllaDB integrates with Chronicle
Chronicle is a framework for building permanode services that receive transactions from an IOTA network and store them in a ScyllaDB cluster. Originally written in Elixir, it has now been ported fully to Rust to support interoperability with other IOTA projects, like Bee, and to provide a more secure programming environment.
To make Chronicle extensible, it is divided into the following components:
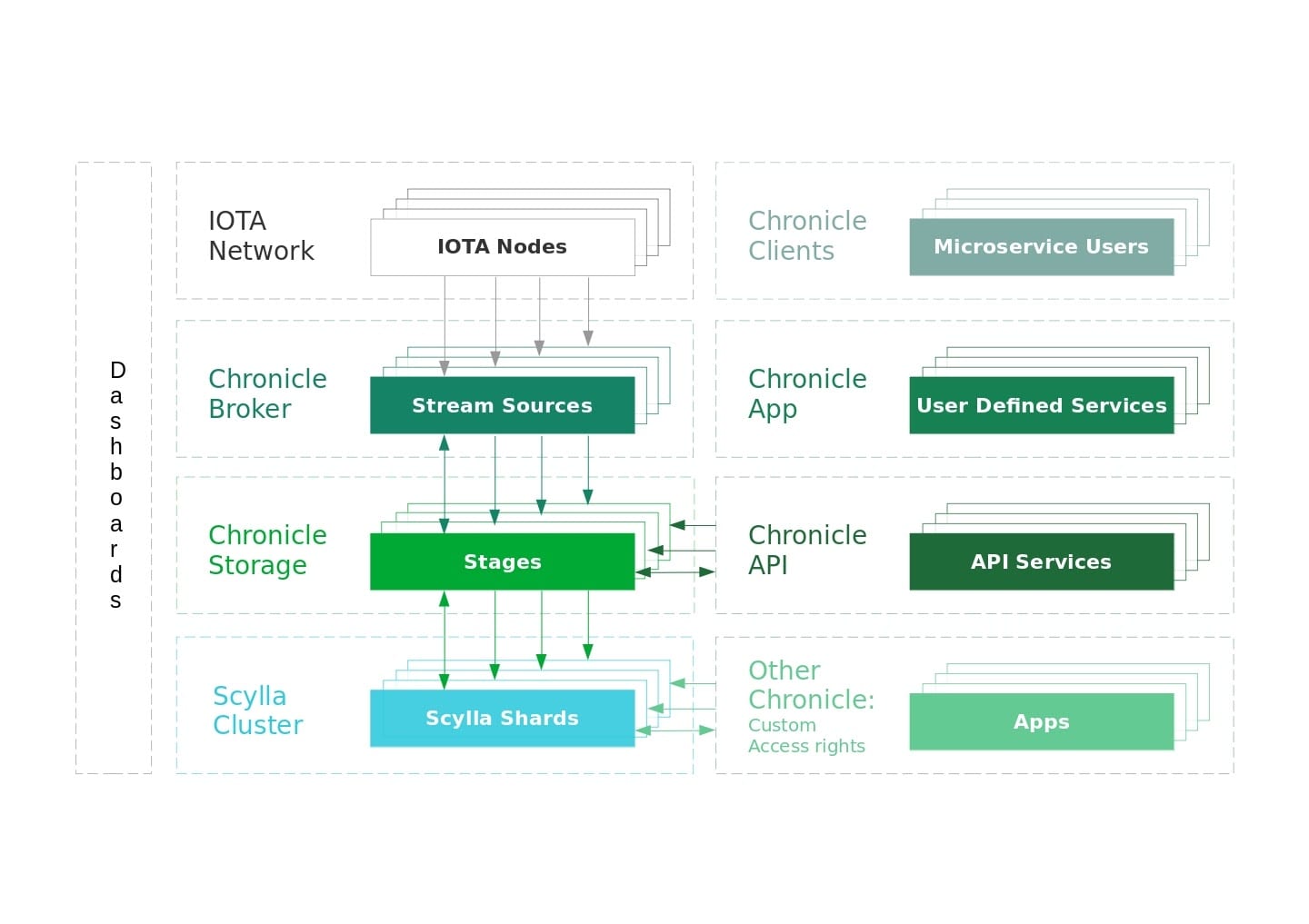
Dashboard
This component is an application for managing and monitoring components such as adding or removing ScyllaDB nodes without downtime or connecting to new IOTA nodes in the Chronicle Broker.
Chronicle Broker
This component receives and processes transactions from IOTA nodes through an event API such as MQTT and provides useful utilities to import historical data.
At the moment, Chronicle Broker uses MQTT to receive transactions and persist them, using the shard-aware strategy in Chronicle Storage.
Chronicle Storage
This component provides access to the datasets and the physical ScyllaDB nodes in a cluster, called a ring.
Chronicle Storage starts by initializing the dashboard and query engine.
The query engine is made up of stages, which handle requests for transactions from each shard in a given ScyllaDB node. The stages are controlled by stage supervisors, which in turn are controlled by node supervisors that maintain the cluster topology.
Each stage includes the following lightweight processors:
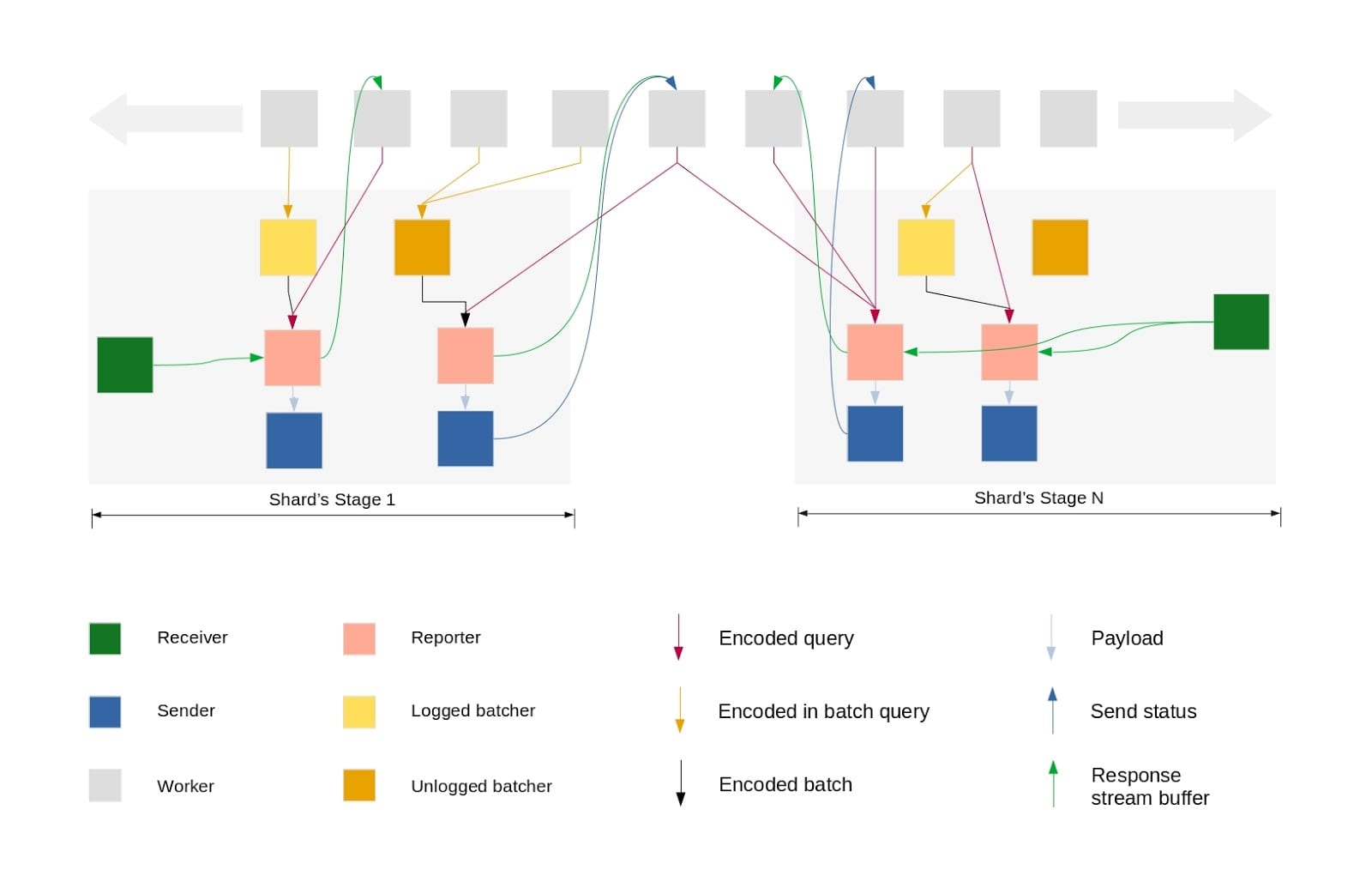
Workers represent requests such as from API calls or the MQTT worker.
When a worker receives a request, it sends it to the corresponding reporter of the shard.
The reporter then sends the request to its sender, which handles sending the request to the shard socket.
The receiver then takes the responses from the shard and passes it to the reporter, who passes it back to the worker to pass onto the client.
To use Chronicle Storage, applications must implement the worker trait and access the local ring to send requests to the corresponding stage.
The ring provides a subset of useful send strategy methods:
send_local_random_replica(token, request): Selects a random stage within the same datacentersend_global_random_replica(token, request): Selects a random stage in any datacenter
CQL schemas
The current Chronicle data model uses the following tables:
- Transaction table: Stores transaction hashes and fields
CREATE TABLE IF NOT EXISTS mainnet.transaction ( hash varchar, payload varchar, address varchar, value varchar, obsolete_tag varchar, timestamp varchar, current_index varchar, last_index varchar, bundle varchar, trunk varchar, branch varchar, tag varchar, attachment_timestamp varchar, attachment_timestamp_lower varchar, attachment_timestamp_upper varchar, nonce varchar, milestone bigint, PRIMARY KEY(hash, payload, address, value, obsolete_tag, timestamp, current_index, last_index, bundle, trunk, branch, tag, attachment_timestamp, attachment_timestamp_lower, attachment_timestamp_upper, nonce) );
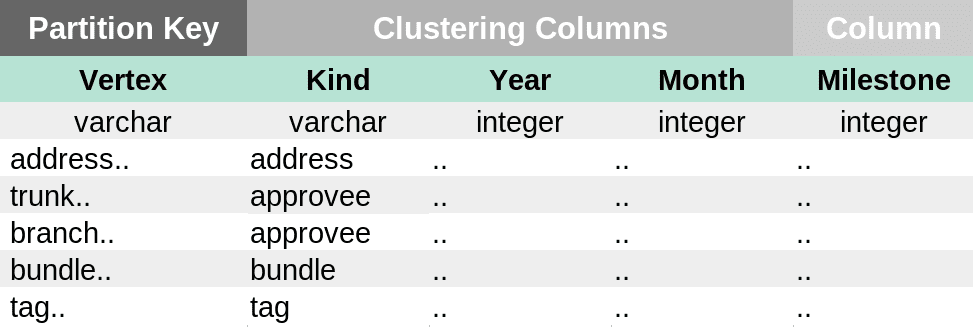
- Hint Table: Stores the sharding information for a given vertex
CREATE TABLE IF NOT EXISTS mainnet.hint ( vertex varchar, kind varchar, year smallint, month tinyint, milestone bigint, PRIMARY KEY(vertex, kind, year, month) ) WITH CLUSTERING ORDER BY (kind DESC, year DESC, month DESC);
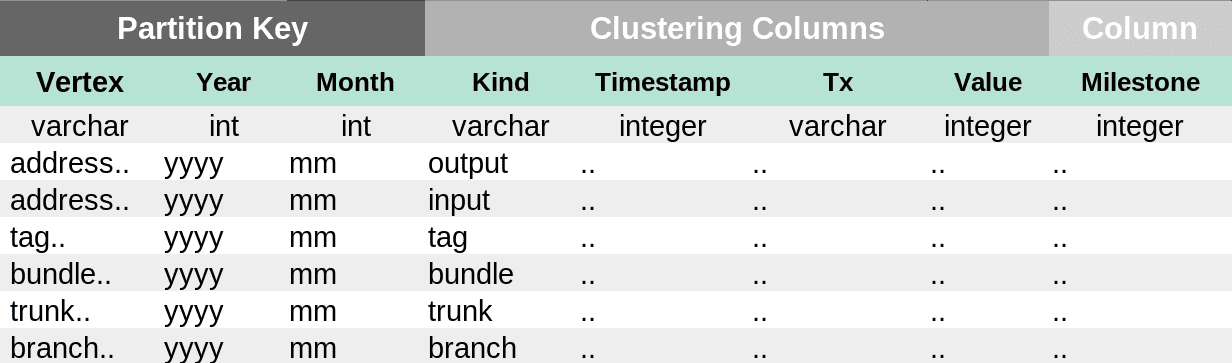
- Data table: Stores the relations to a transaction, and can only be used if we have the sharding info for a given vertex, which can be queried from the hint table
CREATE TABLE IF NOT EXISTS mainnet.data ( vertex varchar, year smallint, month tinyint, kind varchar, timestamp bigint, tx varchar, value bigint, milestone bigint, PRIMARY KEY((vertex,year,month), kind, timestamp, tx, value) ) WITH CLUSTERING ORDER BY (kind DESC, timestamp DESC);
What’s next
Chronicle’s roadmap includes some exciting improvements:
- A UI dashboard for managing Chronicle components
- Transaction solidification to allow Chronicle to know if it is missing any transactions in the Tangle
- Selective permanode service for storing only transactions that you are interested in
In the meantime, see the documentation for steps on getting started with Chronicle.
If you want to contribute, the source code is all open source, so take a look at the following resources:
- Chronicle GitHub repository for the Chronicle source code
- X-Teams GitHub repository for participating in Chronicle projects with other community members
- Discord for discussions with Chronicle developers and other community members