




This is the second part of a presentation given by Alexys Jacob, CTO of Numberly at the virtual Europython 2020 Conference in July, entitled A deep dive and comparison of Python drivers for Cassandra and ScyllaDB. He also gave the same talk, updated, to PyCon India; we’ll use slides from the latter where they are more accurate or illustrative.
If you missed Part 1, which highlights the design considerations behind such a driver, make sure to check it out!
Alexys noted the structural differences between the Cassandra driver and the ScyllaDB driver fork. “The first thing to see is that the token aware Cassandra driver opens a control connection when it connects for the first time to the cluster. This control connection allows your Cassandra driver to know about the cluster topology: how many nodes there are, which are up, which are down, what are the schemas, etc. It needs to know all this. So it opens a special connection, which refreshes from time to time.”
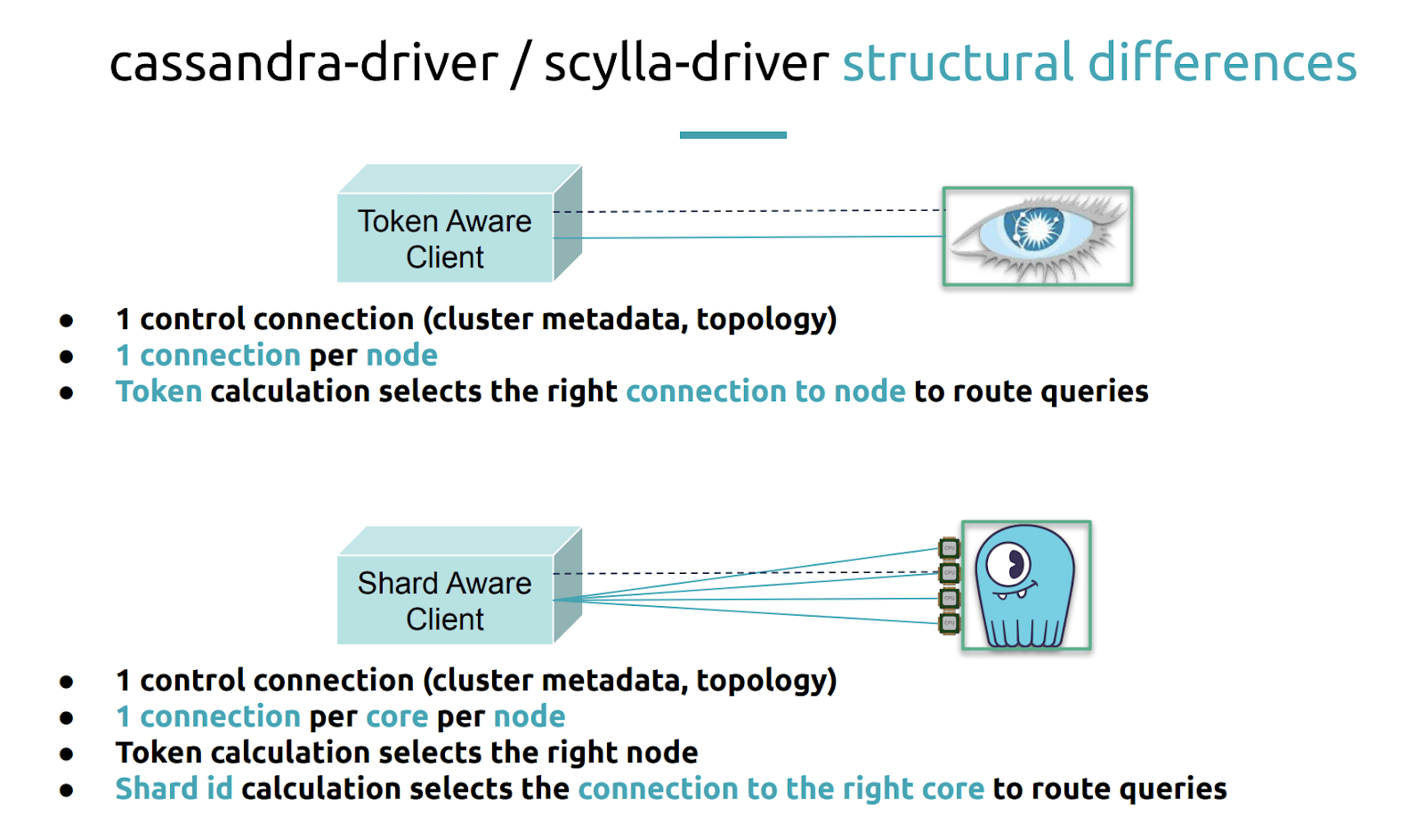
“Then it will open one connection per node because this is how the token aware policy will be applied to select the right connection based on the query.”
For ScyllaDB, you still need to know about the cluster topology, but instead of opening one connection per node, we will be opening one connection per core per node.
“The token calculation will still be useful to select the right node from the token perspective but then we will need to add a Shard ID calculation because we need to go down to the shard or the CPU core.”
Alexys then turned this into the following “TODO” list to create the shard-aware driver:

“The first thing is since we will be using the same kind of control connection we just use this as-is. There’s nothing to change here.”
“We will need to change the connection class object because now, when we are going to open a connection per core per node we will need to be able to detect if we are talking to a ScyllaDB cluster or to a Cassandra cluster.”
Alexys noted that, for the ScyllaDB driver, “we want it to retain maximum compatibility with Cassandra. So you can use the ScyllaDB driver to query your Cassandra cluster as well.”
“The HostConnection pool will use those shard-aware connections and open one connection to every core of every node. The token calculation that selects the right node will be the same. we will just use the vanilla and already existing and efficient token aware policy. But then we will need to extend it and add in the cluster when you issue the query. We will need the Cluster class to pass down the routing key to the connection pool. Then we will apply the shard id calculation and then implement the logic based on the shard id of selecting the right connection to the right node and to the right shard.”
Okay, Sounds like a plan! Let’s do this.
Before Alexys went any further, he introduced ScyllaDB’s own Israel Fruchter, who was in the virtual audience that day, and thanked him for the work he put in on the shard-aware driver code, especially his work on CI testing.
“Now we’ll get down into the code.”
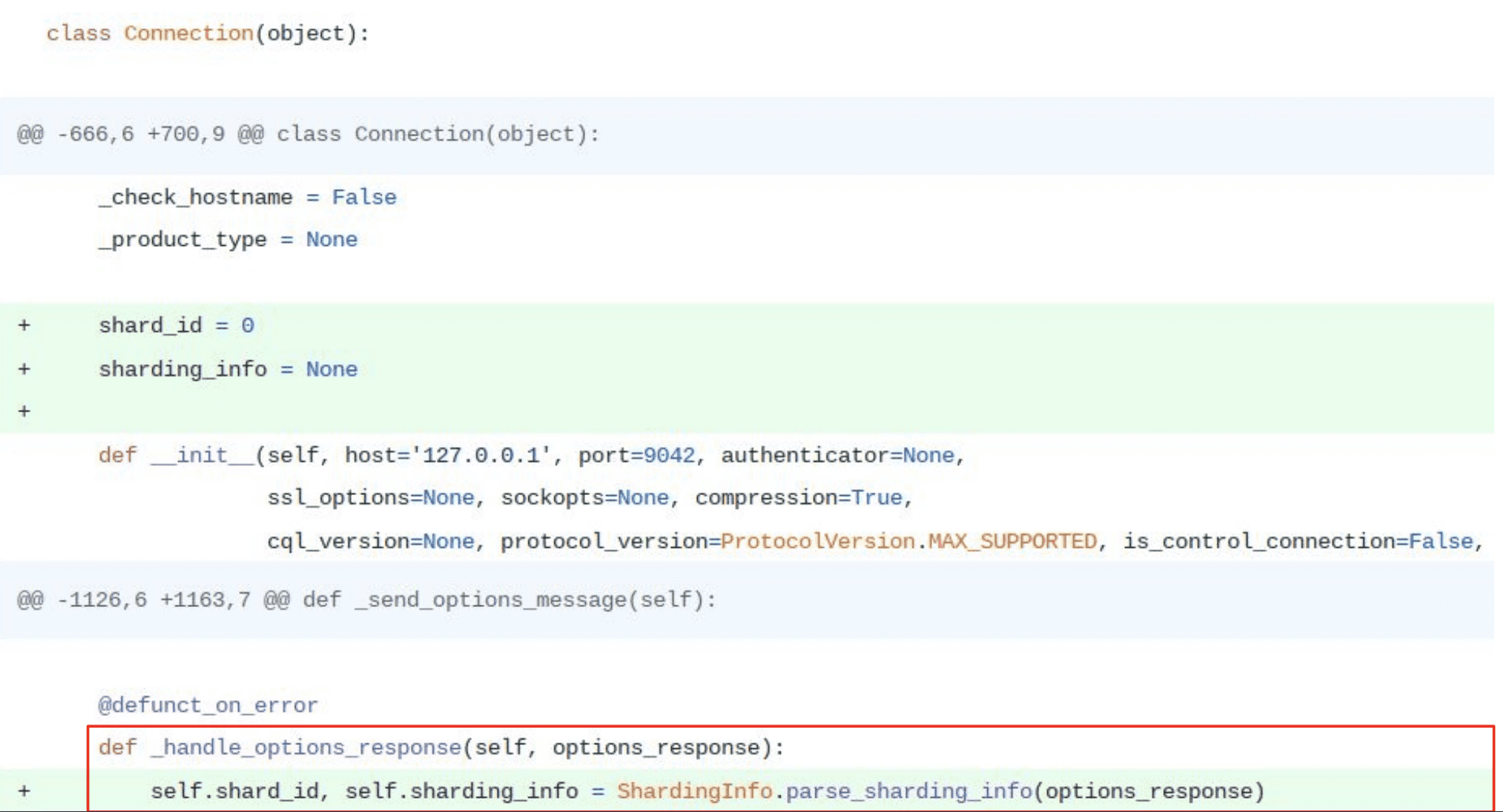
“So the first thing that needed to be done is to add the shard information to the connections. So a connection now has a shard_id assigned to it and sharding information. This sharding information comes from the server responses when we issue a query.” (You will see that in the red square in the image above.)
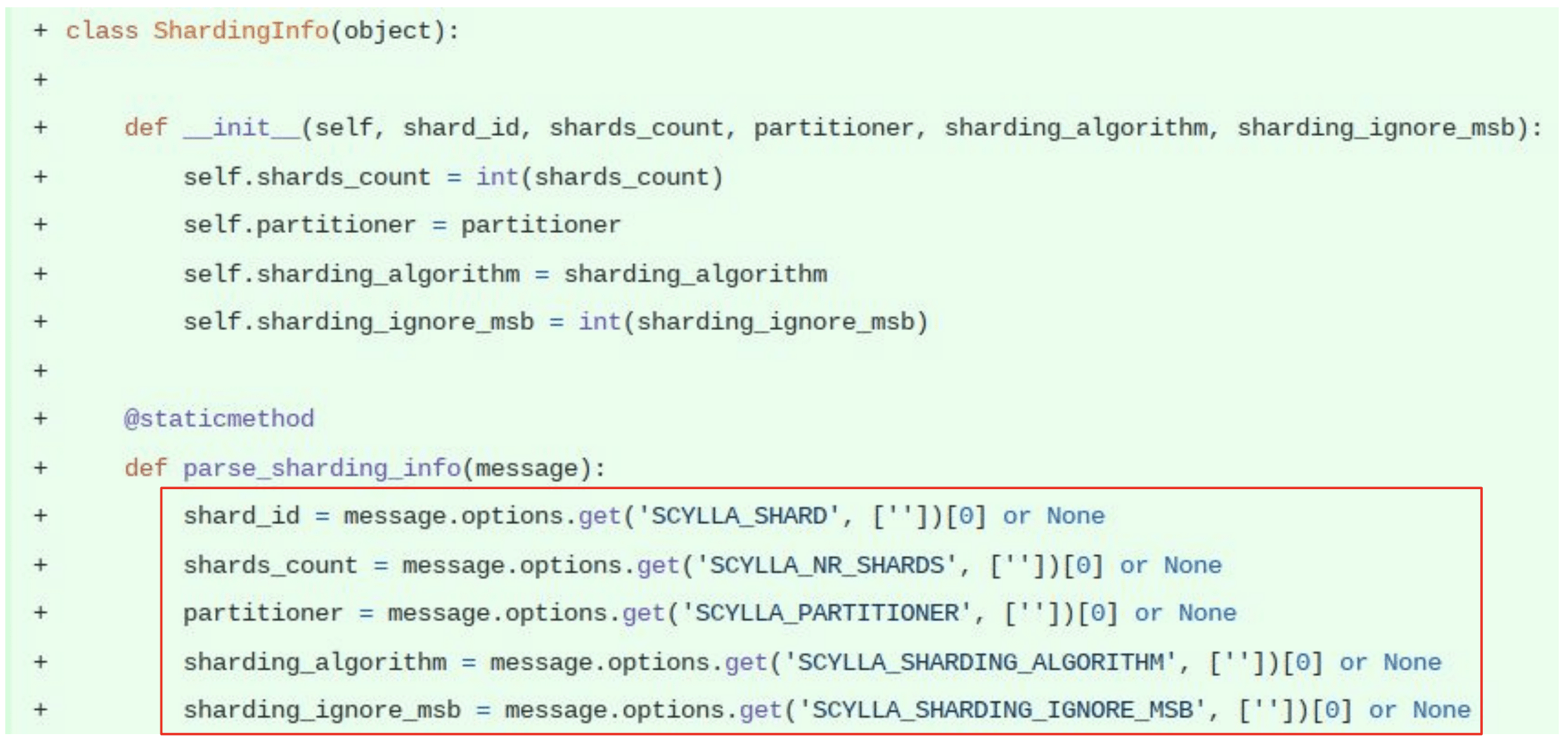
This is what the logic looks like. “What’s interesting to note is that the Cassandra protocol allows only for connection message options being passed on the server response. This means that when the client initially connects to Cassandra or ScyllaDB it has no way of passing any kind of information to the server. So we are dependent on the server’s response to know about shard information or whatever it is that we need.”
“If we look at the the message options that we get back after we have connected to the server the first one is one of the most interesting for us, because the ScyllaDB shard information
tells us which shard_id or core was assigned to the connection by the server.”
“Since we have no way of asking anything when we connect we are dependent on the server shard allocation to the connection that we open. This is a protocol limitation.”
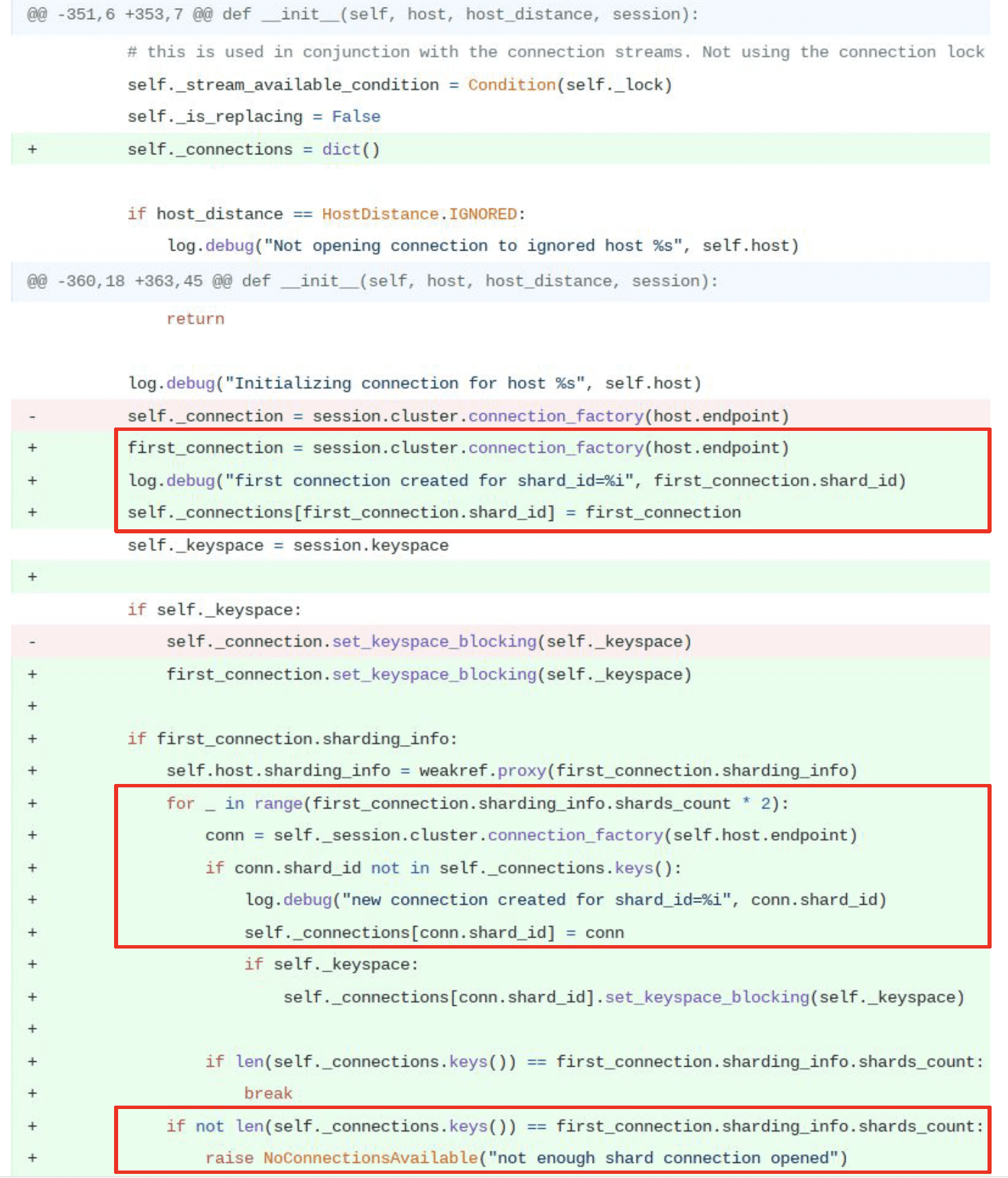
“Now we are going to change the host connection pool class. We need to get the connection object for every core of the node. We got rid of the single connection that we had before and replaced it with a dict where the keys are the shard_id and the values are the connections that are bound to the specified shard.”
“The first time we connect as you can see in the first rectangle, the first connection allows us to detect if we are connecting to a shard-aware cluster. A ScyllaDB cluster, for instance. This is where we get the first glance at the sharding information and we store it.”
“This second part here with the four _ in range we can see that we are doing a synchronous and optimistic way to get a connection to every core. We open a new connection to the node and store shard_id plus connection object on the dict. We will do this twice as many times as there are cores on the remote node until we have a connection to all shards. Maybe.”
“Because if you remember the client, when it connects, cannot specify which shards it wants to connect to. So you just happen to connect to the server and you get a shard assigned . That’s why the initial implementation was trying and saying ‘okay let’s try twice as much as there are cores available on the remote node and hopefully we’ll get a full connection and a connection for every shard.’ If we were lucky, fine. Keep on moving. If not we would raise an exception.”
Not Acceptable!
“Noooo! The first time I saw this I understood this flow in the client not being able to request a specific shard_id because of the protocol limitation. So there is no deterministic and secure way to get the connection to all remote shards of a ScyllaDB node. Connecting also synchronously means that the startup of our application would be as slow as connecting to (hopefully) all shards of all nodes. Not acceptable.”

“The second thing that came to my mind was, ‘Hey, this also means that all the current shard-aware drivers, since it’s the protocol limitation it’s not bound to Python. It’s not python’s problem. It’s a flaw or a lacking in the protocol itself.”
“That means that all the current shard-aware drivers are lying. Since none of them, even today, can guarantee to always have a connection for a given routing key. All of this is opportunistic and optimistic. You will eventually get one, but not all your queries will be able to use the direct connection to the right shard.”
“So I wrote an RFC on the ScyllaDB dev mailing list to discuss this problem and the good news is that the consensus to a solution was recently found. It will take the form of a new shard allocation algorithm that will be placed on the server side. That will be made available as a new listening port on ScyllaDB.”
“Since we want ScyllaDB and Cassandra on their default port to retain the same behavior if we want to change a bit and add on the server a new kind of port allocation we need to do it on the new on your new port. It will be a shard aware port. It will just use a sort of modulo on the client’s socket source port to calculate and assign the correct shard to the connection. It means that the clients on the side will just have to calculate and select the right socket source port to get a connection to the desired shard id.”
“This is work in progress. It’s not done yet. So I worked on implementing a softer, optimistic and asynchronous way of dealing with this problem.”
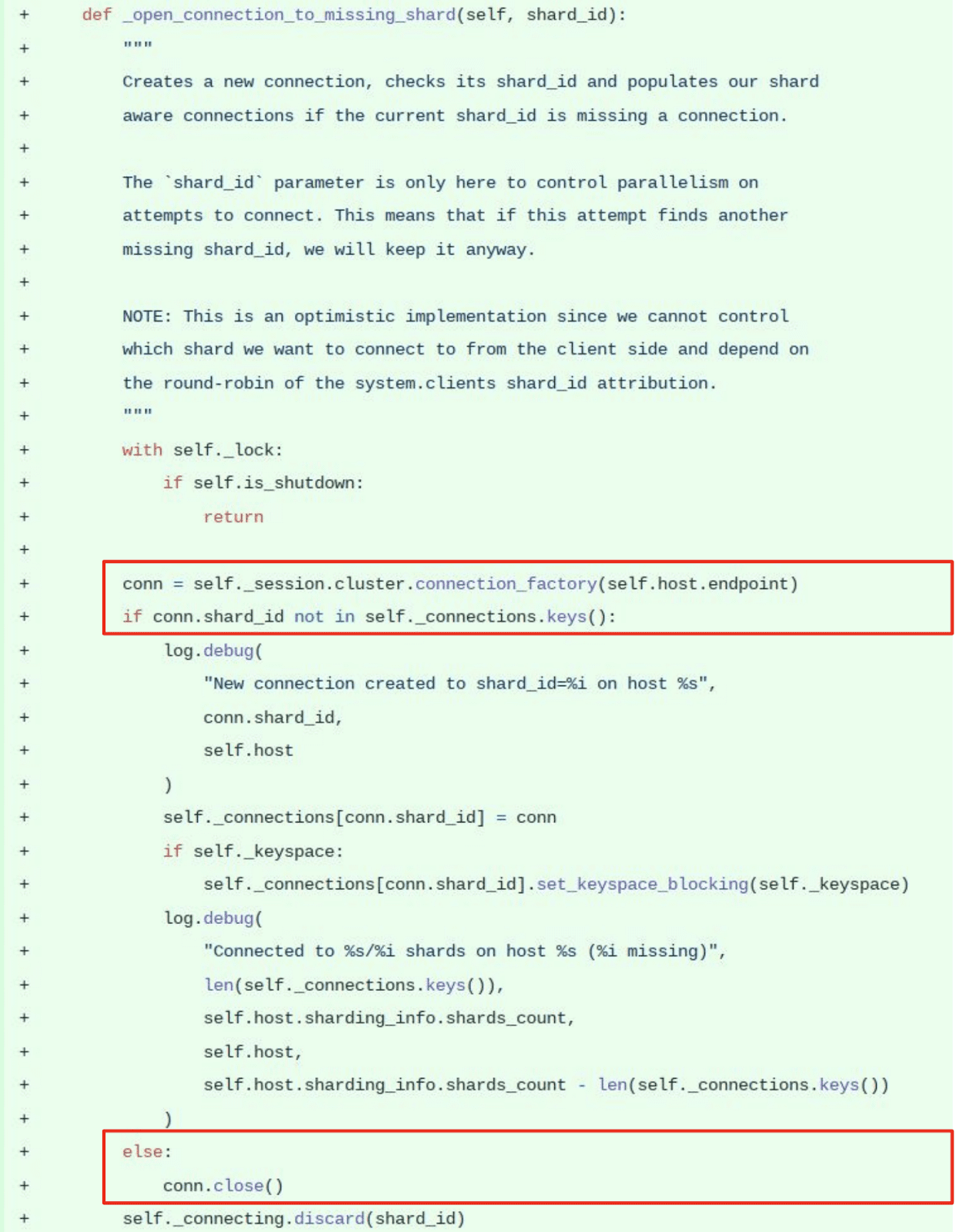
“I wrote two functions. The first one is the optimistic one. It tries to open a connection and only stores it if the reported shard_id was not connected before. Else we close it. So we are only interested in keeping connections to missing shard_ids. We just open it and if it works good; if it doesn’t we’ll see later.”
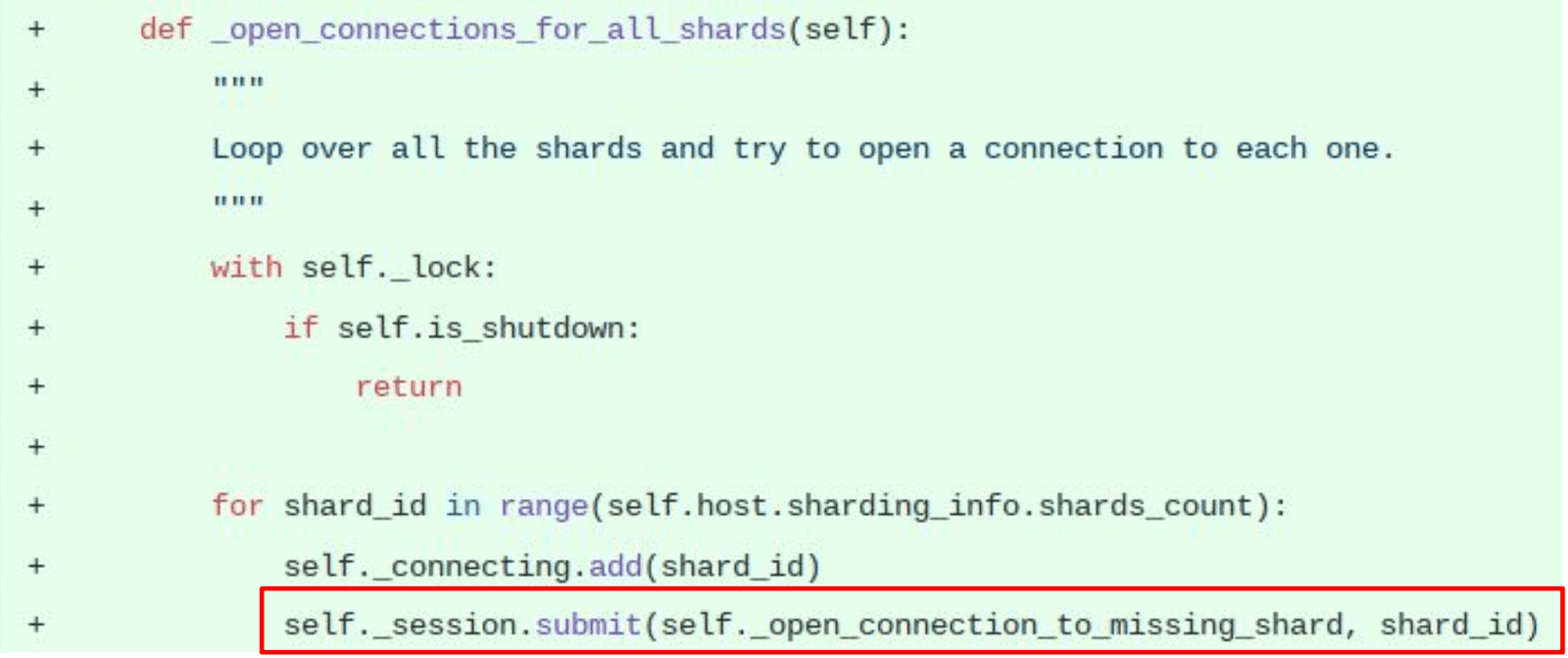
“Then I switched the startup logic to schedule as many of those optimistic attempts to get a connection to a missing shard_id as there are shards available on the remote node. For example, when you start connecting if you have 50 cores on your remote server you will issue and schedule asynchronously 50 attempts to get a connection to shards. Maybe 25 of them will give you different and unique shard_ids connected. Maybe two of them. Maybe 50 of them. (Lucky you!)”
“But now we don’t care. It’s optimistic, asynchronous, and it will go on and on again like this as we use the driver. The result is a faster application startup time. As fast as the usual Cassandra driver and with non-blocking optimistic shard connections.”

“The cluster object should now pass down the routing key as well to the pool. You can see here that when you issue a query using the query function and the cluster object looks up for a connection we added the routing key so that we could apply the shard_id calculation. This shard_id calculation is a bit obscure. Lucky me, Israel was there to to implement it in
the first place.”
Optimizing Performance with Cython
“However, the first time I tried to use this pure Python implemented shard_id calculation it was very bad in driver performance. We were slower than the Cassandra driver.”

“What Israel did is to move this shard_id computation to Cython because actually the Cassandra driver is using a lot of Cython in the background when you install it. He managed to cut its latency impact by almost 7x. Kudos again Israel. It was a very impressive move. It made the difference from the driver perspective.”
Wrapping It Up
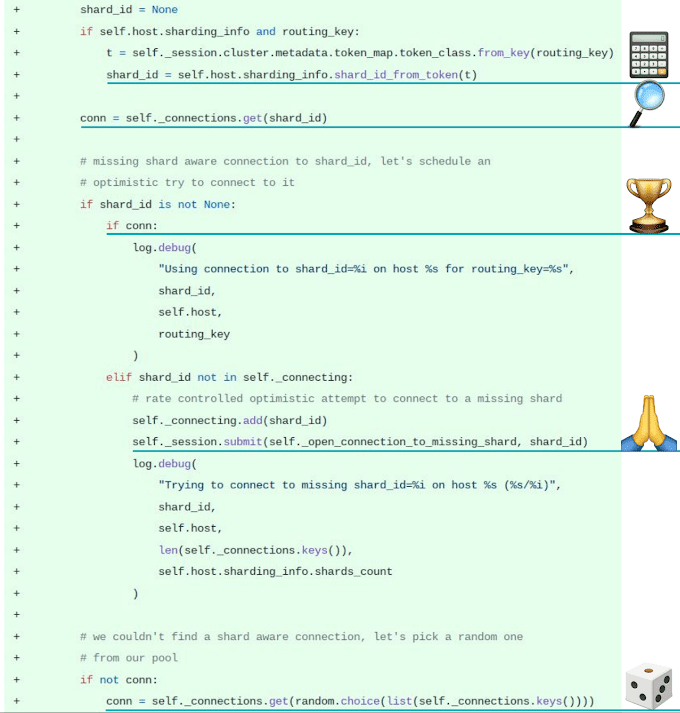
“In the main shard awareness logic, in the host connection pool, this is basically where the connection selection happens and everything is glued together. If we are on a shard-aware communication with a cluster we will calculate the shard_id now from the routing key token. Then we will use the routing key, the shard_id, and we will try to look up in our connection dict if we happen to have a connection to this direct shard_id, to this direct core. If we do? Triumph! We will use this direct connection and route the query there.”
“That’s the best case scenario. If not, we will pray and asynchronously issue a new attempt to connect to a missing shard. Maybe it will be the shard we were trying to look at before. Maybe it will be another one. But that means that as you issue more queries to your cluster, the more chance you get to have a connection to all shards and all cores. If you don’t have one, we will just randomly pick an existing connection. So at worst we would behave just as if we were using the Cassandra driver.”
Performance Results
“Does the ScyllaDB driver live up to our expectations? Is it fast? How did it work in production? Because to you and to me the real value must be taken from production? So let’s see.”
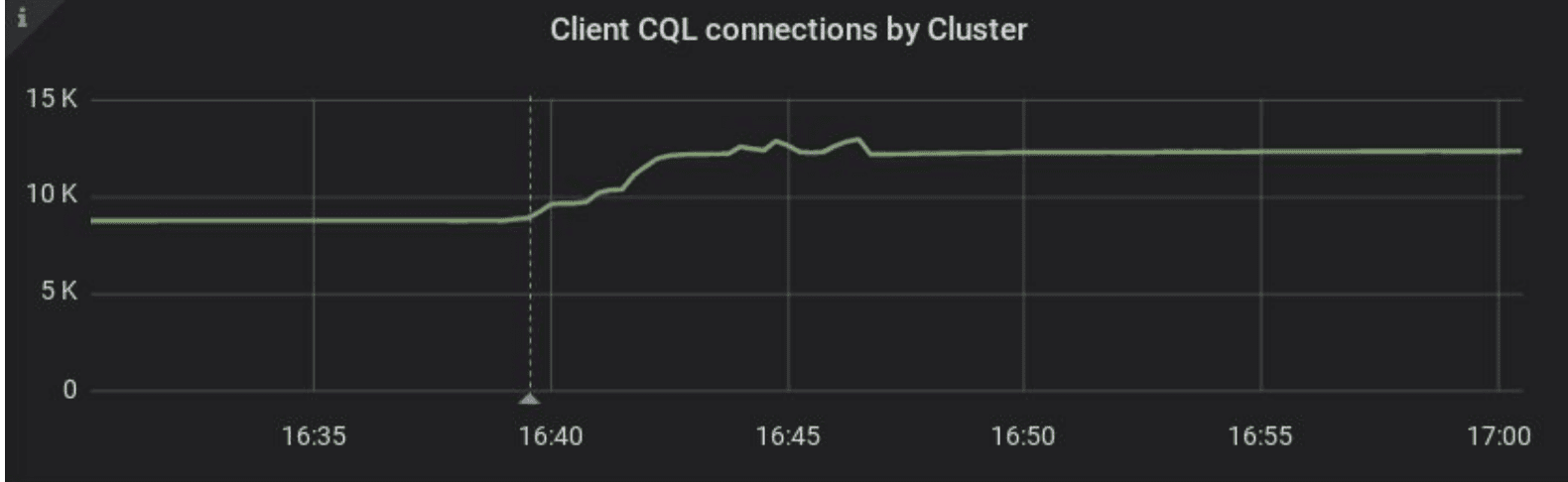
“The first expectation we checked was if there was an increase in the number of open connections from the cluster? Because now that we are opening not only one connection to each node but one connection to each core of each node we expected to see this increase. When we deployed the ScyllaDB driver we saw this increase.”

“The second one was also an expectation to have more CPU requirements because you open more connections meaning that your driver and your CPU have to handle more connections, keep alives, etc. We saw that we had to increase the limits on our Kubernetes deployments to avoid CPU saturation and throttling.”
“What about the major impact we wanted? We want faster queries. Lower latencies. Right? This is how that work graph looked like:”
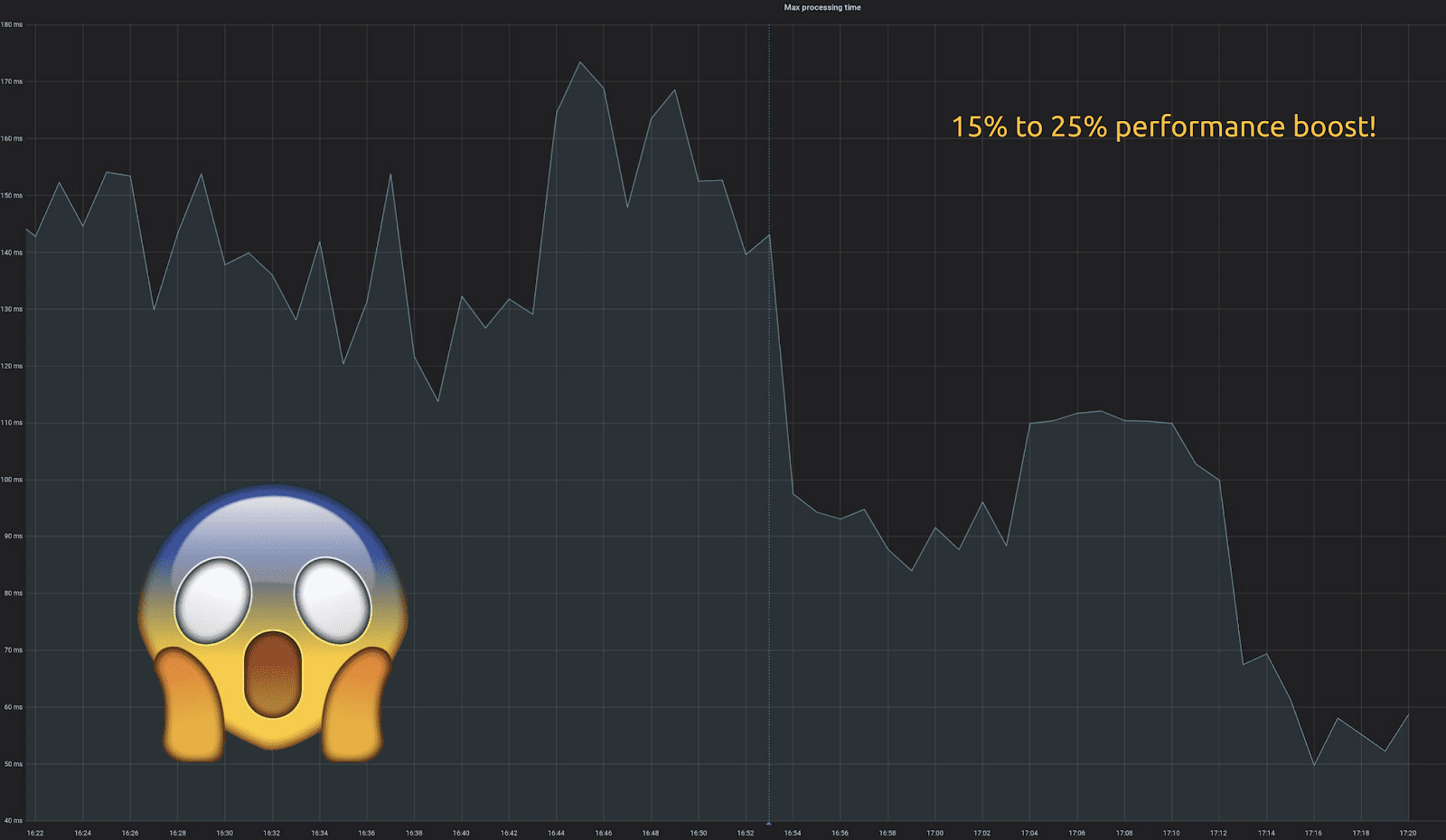
“It’s amazing! We gained between 15% and 25% performance boost. At Numberly we like to look at our graphs on the worst case scenarios possible. That means that this is the max of our processing. This is the worst latency that we get from our application perspectives.”
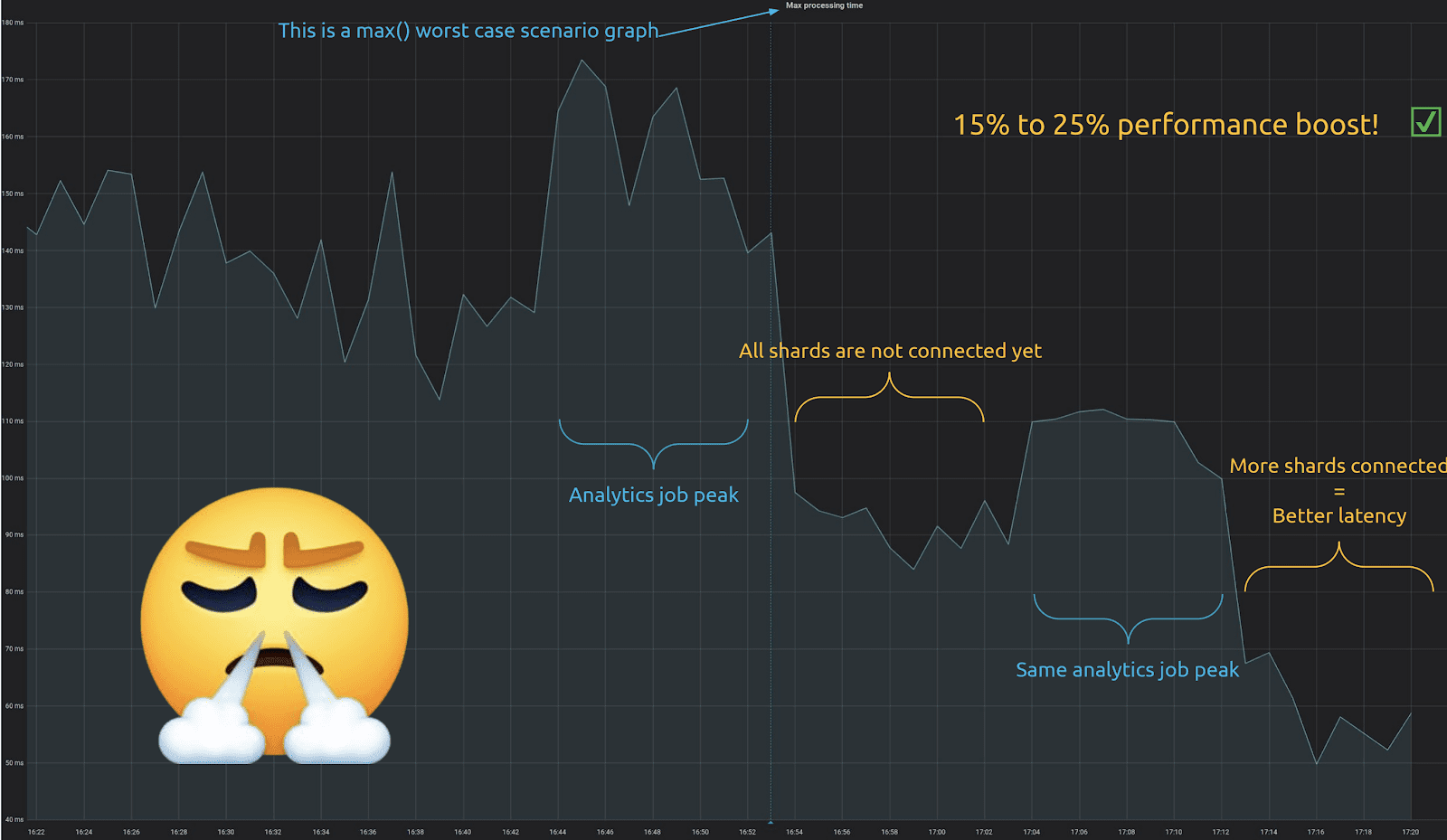
“What’s interesting to note is that the performance boost is progressive. Since we connect to shards in the background in an optimistic fashion the longer our application runs the more chance it has to have a connection to all shards, then the lower the latency gets. Because we begin to always have the right connection to the right core for every query.
“You can see that right after the deployment we already got a fair amount of performance boost. But the longer time passes the more shards connected, and the better the latency. That was very interesting to see.”
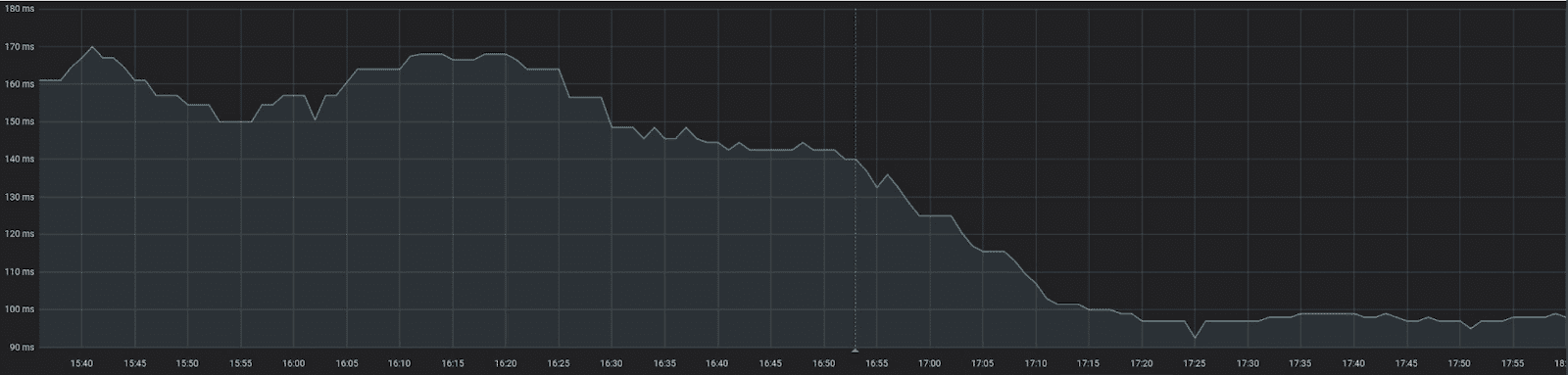
“If we apply a moving median on another power-hungry process you can clearly see the big difference that the ScyllaDB shard-aware driver has made in our production applications.”
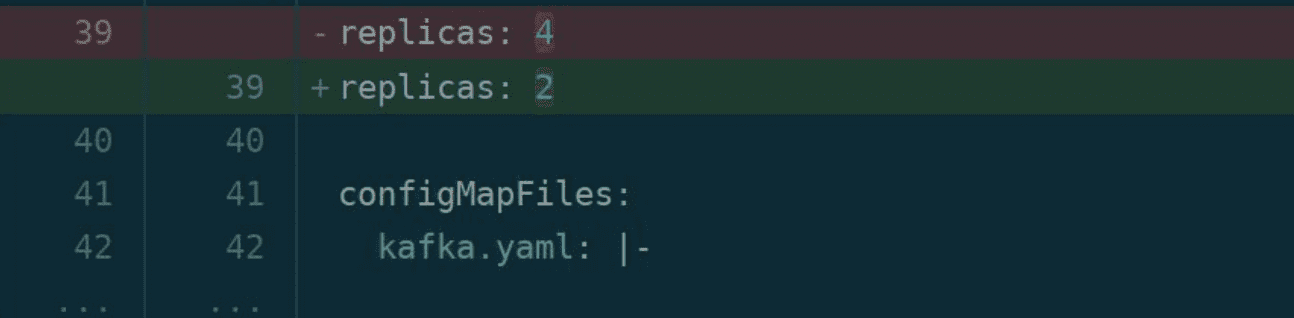
“From this we also got an unexpected and cool side effect. Since the cluster load was reduced and the client’s latency was lower for the same workload we could cut by half the number of replicas on our deployment [from 4 to 2]. So we saved actual resources on our Kubernetes cluster.”
“Recent additions that we’ve done on the driver: we added some helpers to allow you to check for shard-awareness, and to check for opportunistic shard-aware connections, so you can actually see how fully connected you are or are not. When it becomes available we also will be changing the driver to deterministically select this time the shard_ id when it connects. There are two open pull requests already for this.
“We’re going to still work on improving the documentation. And since it’s a Cassandra driver fork we will rebase the latest improvements as well.”
Watch the Video
If you’d like to see Alexys’ full presentation, you can view his slides online, and check out the full video here.
Try it for Yourself!
Alexys then invited the audience to try the ScyllaDB driver. “It’s working great. It’s in production for us for almost almost a month now, with the great impact that you’ve seen.”
- Github: https://github.com/scylladb/python-driver
- PyPi: https://pypi.org/project/scylla-driver/
- Documentation: https://scylladb.github.io/python-driver/master/index.html
- ScyllaDB Slack channel: https://slack.scylladb.com/ (#Pythonistas)










