




At ScyllaDB Summit earlier this year ScyllaDB Software engineer Maciej Zimnoch introduced our audience to ScyllaDB Operator, the production-ready Kubernetes operator for our NoSQL database. Today we’ll highlight that talk and also go over some of the changes since then in this rapidly-evolving project.
ScyllaDB Operator is open source, available under the Apache-licensed. You can find all of the source code on Github, We also provide full documentation and a free course to get started in ScyllaDB University.
ScyllaDB Operator supports Minikube, Amazon Elastic Kubernetes Service (EKS) and Google Kubernetes Engine (GKE). Maciej noted that while these are the platforms against which we run our automated test suites, “Of course you can use Operator on other Kubernetes providers and on-premise deployments.”
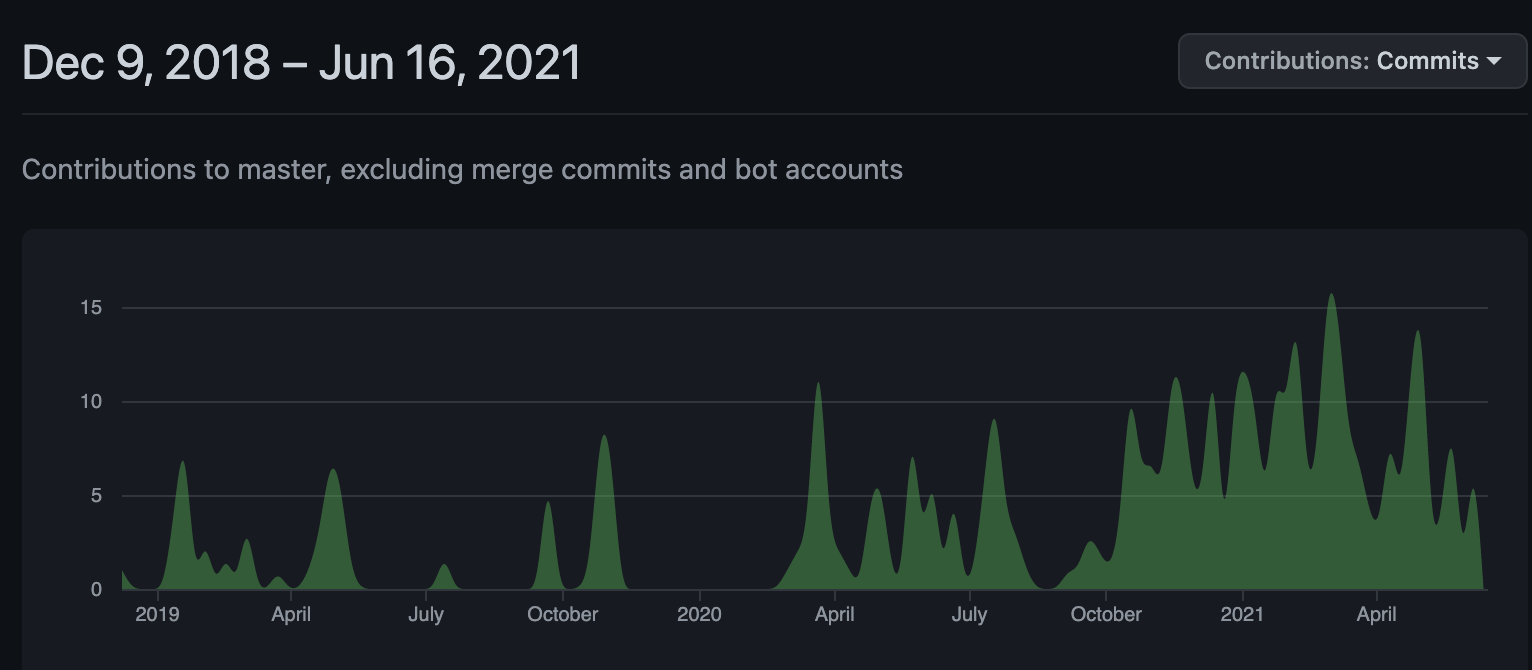
Maciej took time to give credit to Yannis Zarkadas, our open-source community contributor who first introduced ScyllaDB Operator back at the ScyllaDB Summit in 2019. Much has happened since then. Yannis’ original code was brought into its own ScyllaDB github repo, where extensive development has led it to production readiness. This snapshot of commits on Github shows you how activity on the project has ramped up over time:
Diving into the Details
ScyllaDB Operator offers a great deal of functionality.
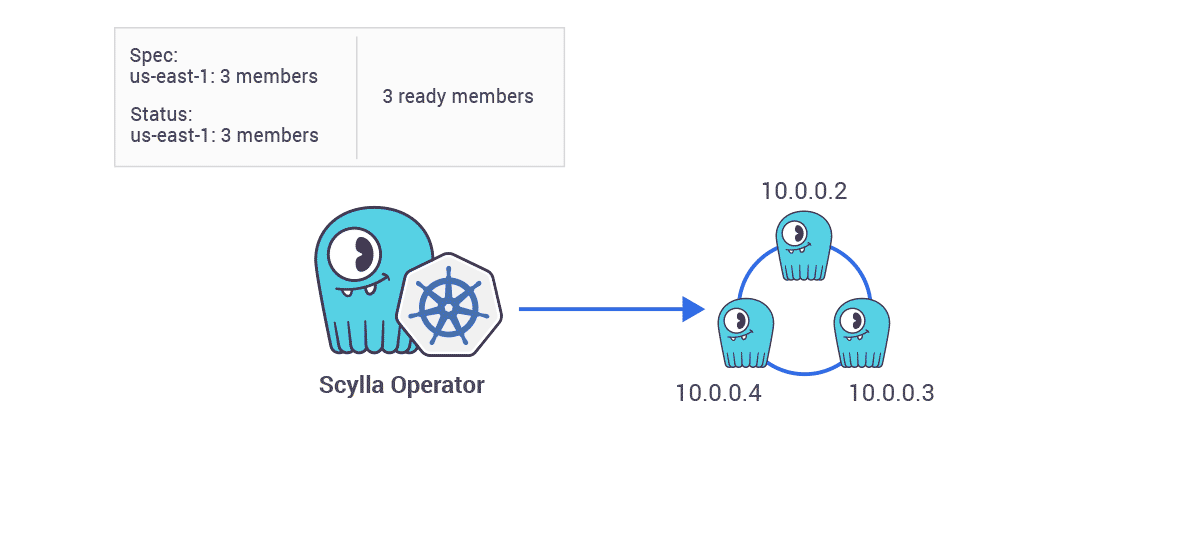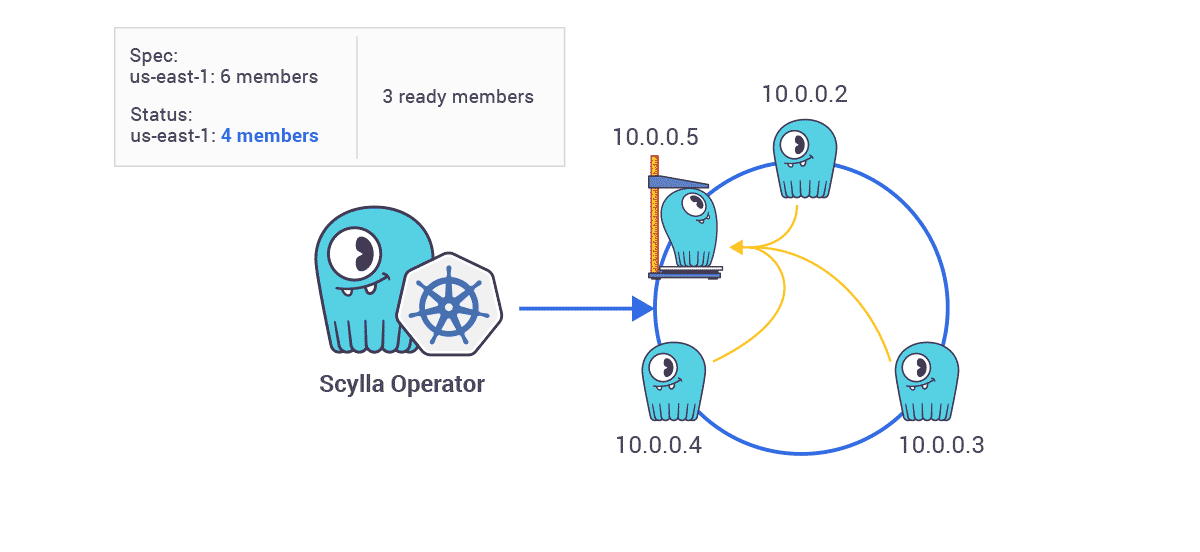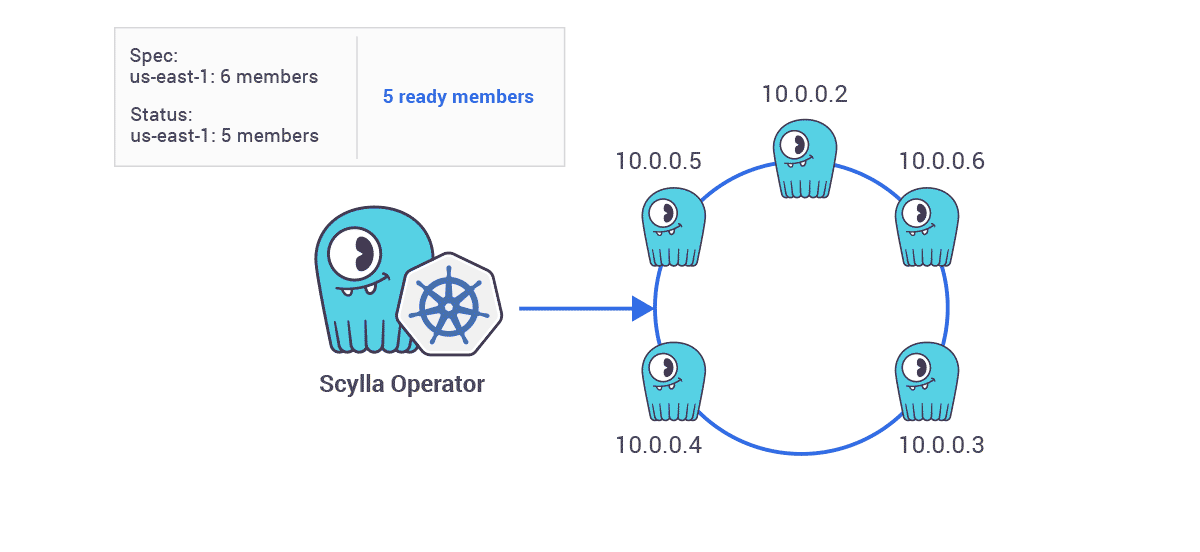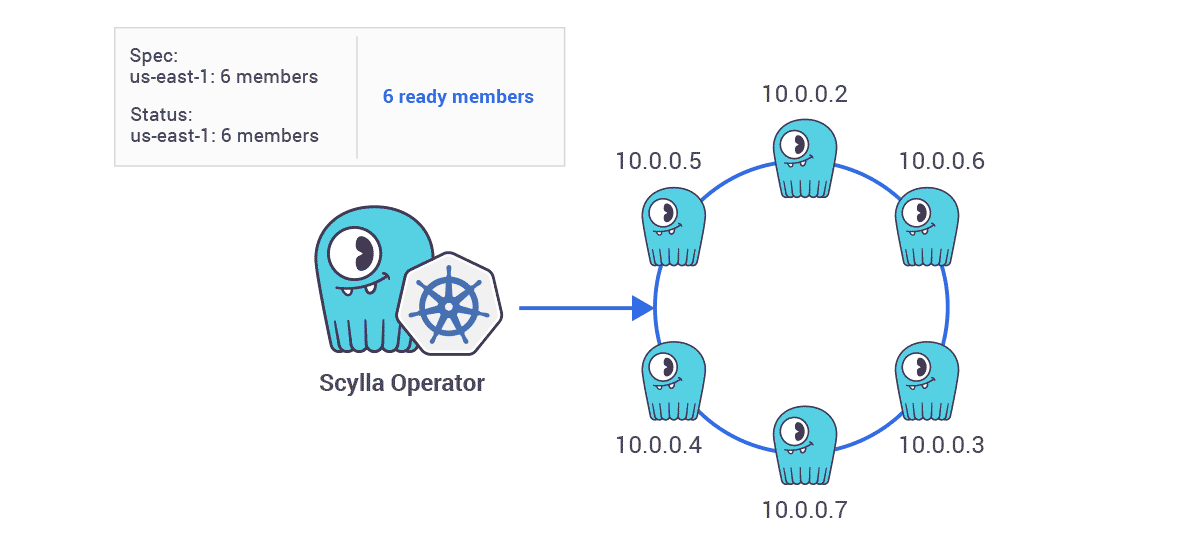
- Scaling Operations — “In this example we already have a single ring cluster containing three ScyllaDB nodes. A user wants to scale it up to have six nodes. This is as easy as changing one number in the ScyllaDB cluster spec. So when the ScyllaDB cluster spec is changed ScyllaDB Operator will begin scaling up the cluster.”
“Existing nodes will keep their unique identity and new nodes are added one by one. The next node is added to the ring only when the previous node declares to be ready to serve traffic. Then the next node joins, one by one, until the desired number of nodes is reached.”
- Automated Configuration Rollouts — Next Maciej described automatic rollout, pointing out how it is “especially useful when configuration changes are introduced. When a user finishes updating his desired configuration he can use
kubectlto restart each node one by one. When the node is restarted configuration is being picked up. Nodes are restarted one by one and each node waits until the previous node is ready.” - Rolling Software Upgrades — In the versions of ScyllaDB Operator prior to 1.0, only patch version upgrades within the same patch release were supported. For example, from ScyllaDB Open Source 4.4.0 to 4.4.1. With ScyllaDB Operator 1.0 and above, users are able to upgrade their select cluster to next minor and major versions. For example, from ScyllaDB Open Source 4.3 to 4.4, or from ScyllaDB Enterprise 2020 to ScyllaDB Enterprise 2021.
“The ScyllaDB upgrade takes care of draining the node to ensure that the upgrade is transparent to ongoing traffic. ScyllaDB Operator backs up the data and system tables to prevent any data loss in case of any failure during the procedure. And once again nodes are upgraded one by one. You may ask what happens when the procedure fails. For version 1.0 ScyllaDB Operator will pause it at the validation step and will require manual intervention. In future versions we plan to implement automatic rollback. The current manual restore procedure can be found in the documentation.”
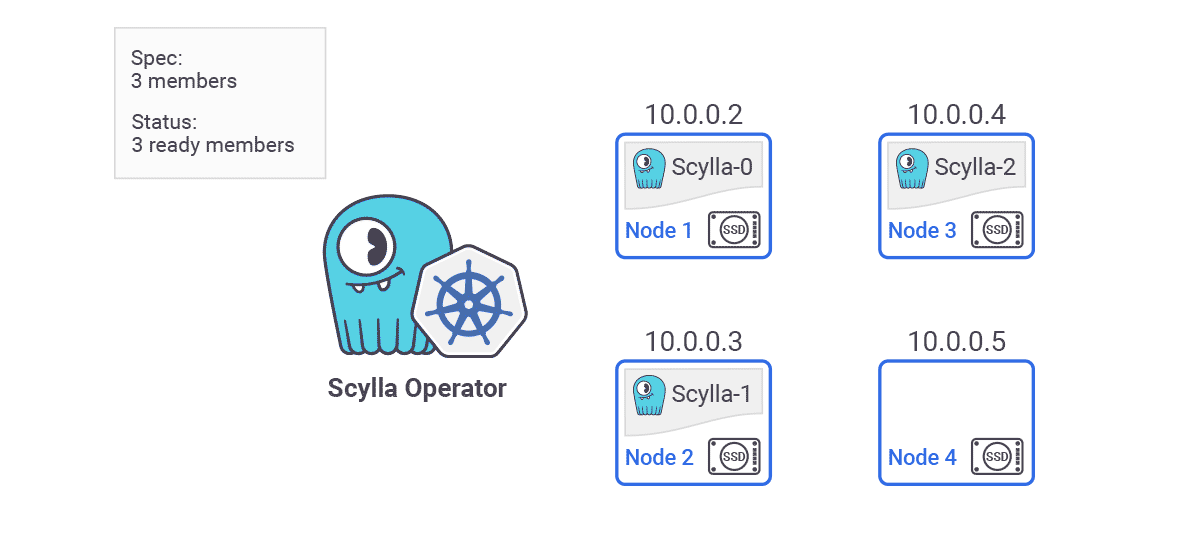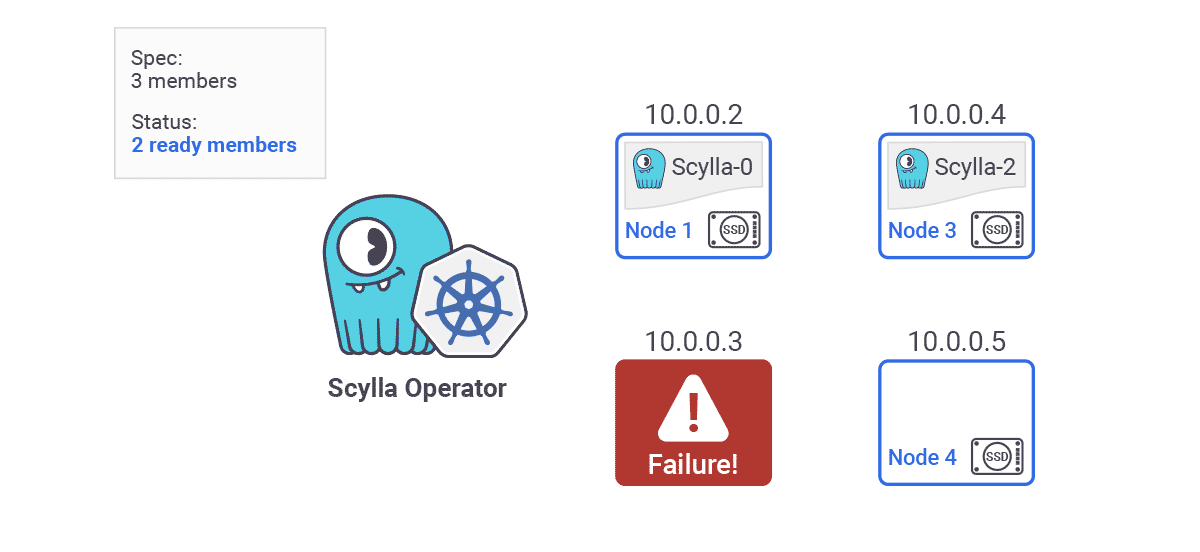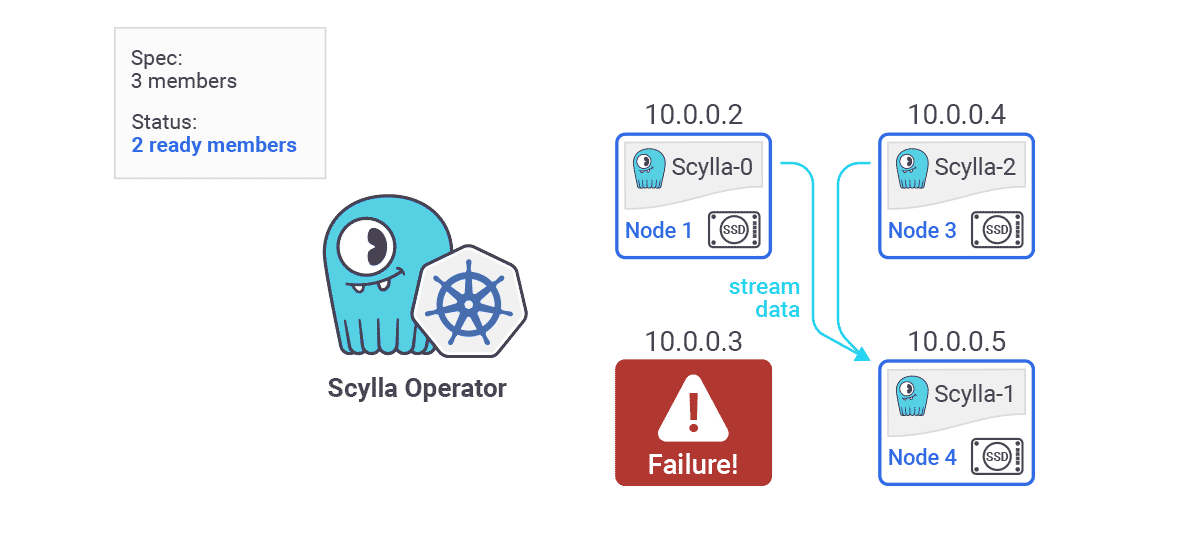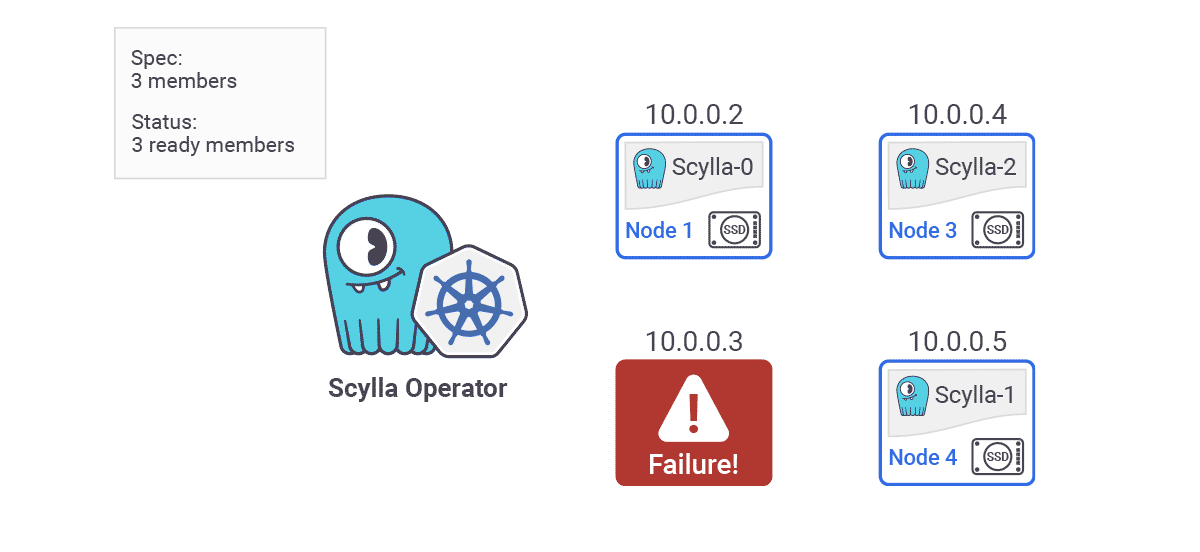
- Auto Healing — ScyllaDB Operator also provides node detection and automatic replacement. “So let’s say we have a three node cluster. Each of them are using local drives. On each of the major cloud providers data on local disk is lost when the instance crashes or if it’s restarted. This means that persistent volume claims attached to each of the pods are bound to specific Kubernetes nodes. When an instance crashes data on that node is lost. ScyllaDB Operator detects such failures and triggers a replace dead node procedure automatically. ScyllaDB Operator will spawn another pod on a different available instance and then the rest of the existing nodes will take care to restream the data belonging to the failed node back to the new node in order to restore the data replication factor. Once the new node is up and running we recommend you run a repair.
- Repairs Integrated with ScyllaDB Manager — “Scheduling repair requires adding a few additional lines to the ScyllaDB cluster definition. You may configure multiple repairs. Each of them have knobs — controlling repair speed, when repair should start, whether it should be recurrent, or maybe you’re interested in repairing only particular keyspaces. ScyllaDB Manager will take care to run this task on your cluster.
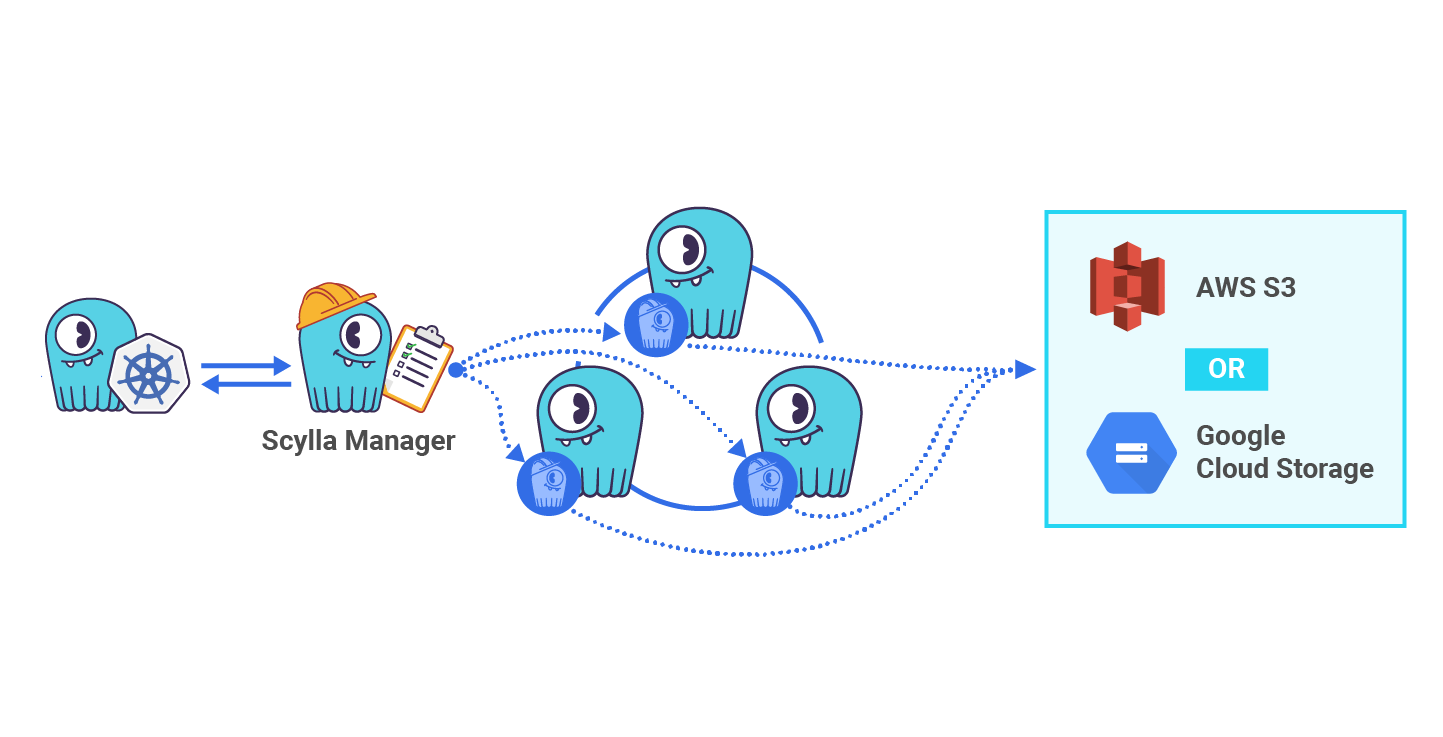
- Automated Backups with ScyllaDB Manager — “The second benefit of integration of ScyllaDB Manager are backups. Configuration is almost the same as repairs. Only the knobs are different. In this example backup is configured to run weekly, have 100 megabytes of maximum upload speed and data is transferred to the Google Cloud Storage bucket. ScyllaDB Manager also supports Amazon S3 and other S3 compatible APIs, like Ceph or MinIO.”
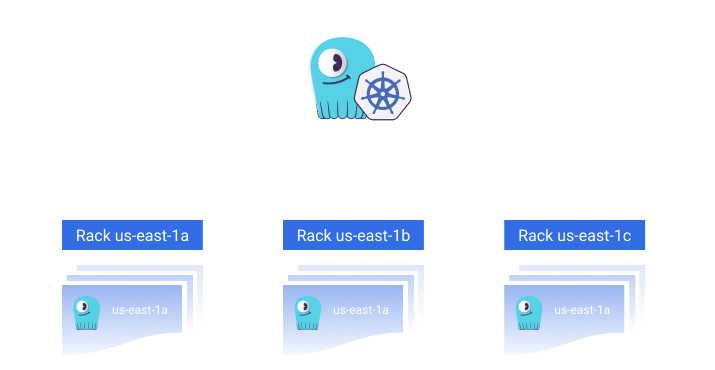
- Multi-Availability Zone (AZ) Support — “Eventually someone will pull the wrong plug and one of the Availability Zones goes down. The ScyllaDB cluster may survive such disasters when it’s configured to use different Availability Zones for each of the cluster racks.”
- Multi-Cluster Support — “ScyllaDB Operator can manage multiple ScyllaDB clusters within the same Kubernetes cluster.”
- Helm Charts — Since ScyllaDB Summit we released three Helm Charts: one for ScyllaDB, one for ScyllaDB Manager, and one for ScyllaDB Operator itself. You can read more about them in this related article, and also in our documentation.
ScyllaDB Operator for Kubernetes Demo
You can watch the following video to see a demonstration of the ScyllaDB Operator in action (this link and the image below will take you right to where the demo begins).
Latest Updates to ScyllaDB Operator
Since Maciej’s ScyllaDB Summit presentation, the ScyllaDB Operator has been updated three times. Today we just released ScyllaDB Operator 1.3 which brings greater security by allowing users to dynamically assign Role Based Access Control (RBAC) roles to Kubernetes pods, amongst other updates and fixes.
Next Steps
If you want to ask about how to get the most out of deploying ScyllaDB on Kubernetes, we invite you to join the #kubernetes channel on our community Slack. Though if you are interested in learning more about the specific development of ScyllaDB Operator, either just to keep abreast of what’s going on in its development, or perhaps to offer your own contributions to this exciting open source project, check out the #scylla-operator channel.
For now, you can get started by downloading the operator and trying it out.






