




At the virtual Europython 2020 Conference in July, Alexys Jacob, CTO of Numberly gave a talk entitled A deep dive and comparison of Python drivers for Cassandra and ScyllaDB. (He also gave the same talk, updated, to PyCon India; we’ll use slides from the latter where they are more accurate or illustrative.)
We’ll break Alexys’ great talk into two parts. In this first part, Alexys covers how ScyllaDB works, and makes the case for a shard-aware driver. In Part 2, Alexys will describe the actual implementation and the performance results.
Alexys is a perennial champion of Python, ScyllaDB, Gentoo Linux and open source overall, having spoken at numerous conferences, including our own past ScyllaDB Summit events. Known across the industry as @ultrabug, Alexys began his Europython talk by promising the audience “diagrams, emojis, Python code, and hopefully some amazing performance graphs as well!”
He also took a moment at the start of his talk to note that Discord, the very platform Europython had chosen to host the community discussion component of the online conference, was a ScyllaDB user, and directed users to check out how Mark Smith described Discord’s own use of ScyllaDB.
Data Distribution in ScyllaDB and Cassandra, A Primer
Alexys noted that this session was for advanced users. So if users needed the basics of consistent hashing, he referred them to his prior talk at Europython 2017 on the topic.
Even for users who were not entirely familiar with the concept he offered a basic primer on how ScyllaDB and Apache Cassandra’s token ring architecture works.
First, both Apache Cassandra and ScyllaDB organize a cluster of nodes (or instances) into a ring architecture. The nodes on a ring should be homogenous (having the same amount of CPU, RAM and disk) to ensure that they can store and process the same relative quantity of information on each.
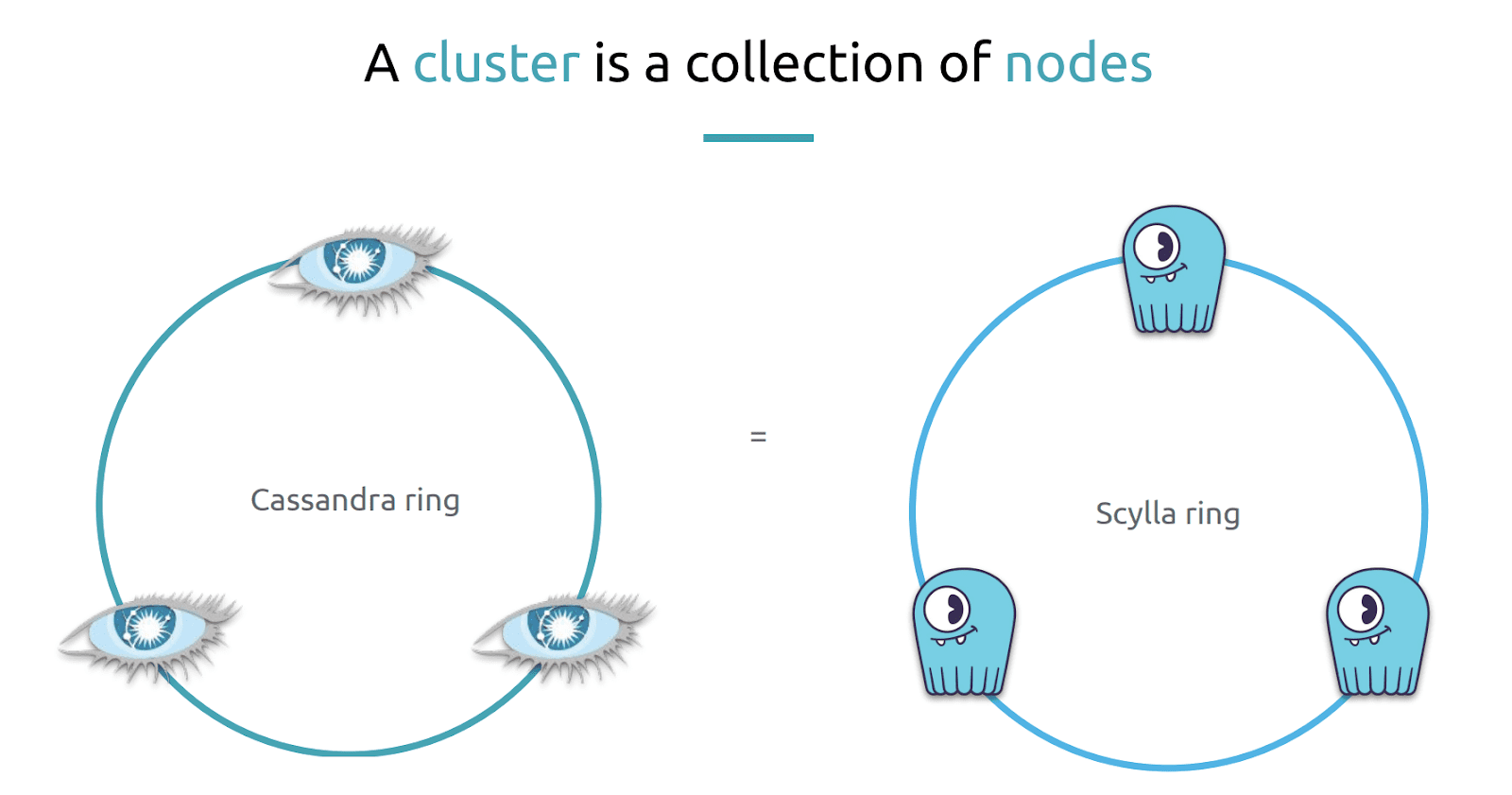
Further, each node is equivalent in importance. There is no leader or primary node. No node has a special role, and thus, no single node to be a point of failure. “They all do the same thing.”
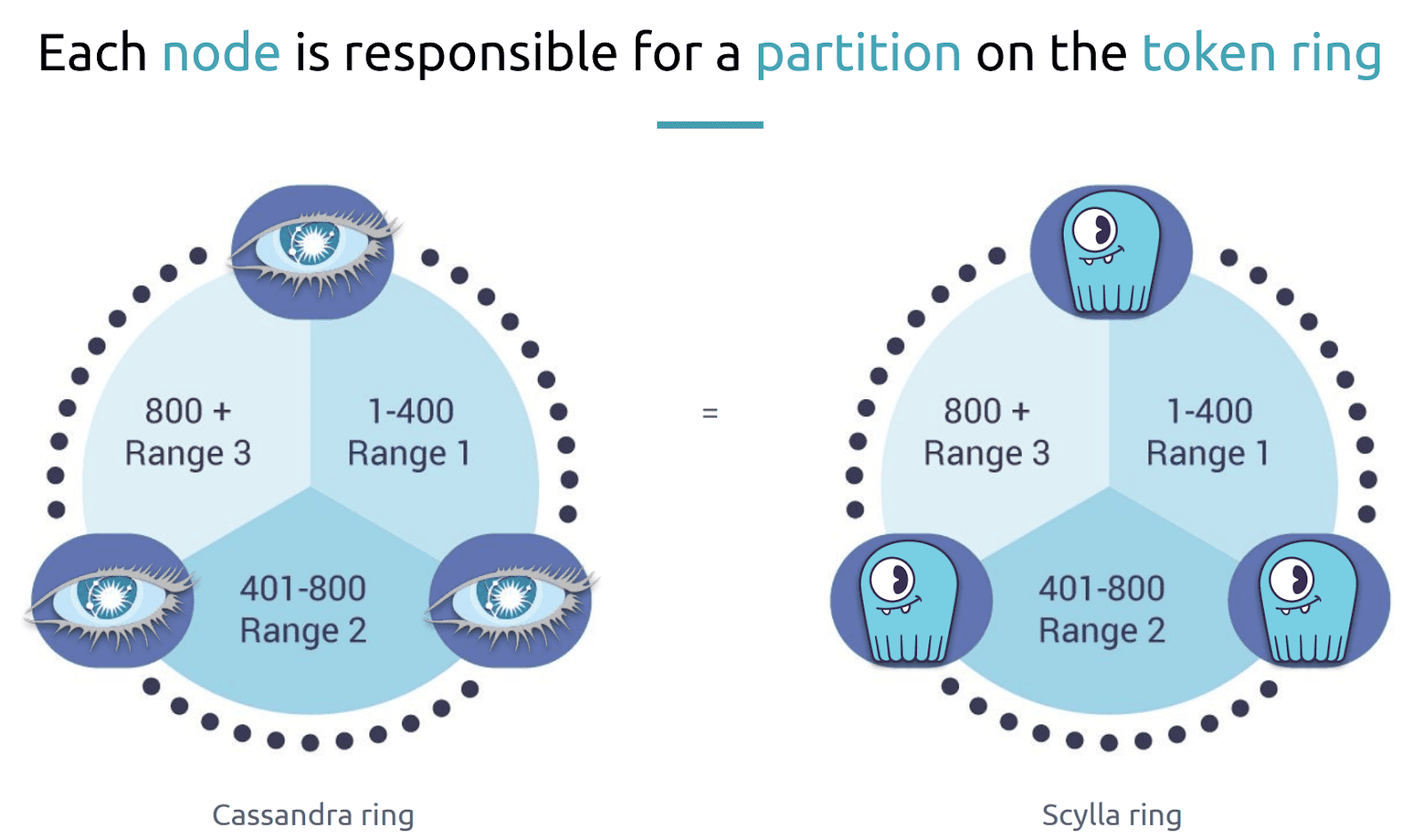
This topology is called a “token ring” because each node in the cluster is responsible for roughly the same number of tokens, each of which represents a partition of data, a subset of data stored on the node. A partition appears as a group of sorted rows and is the unit of access of queried data. This data is usually replicated across nodes thanks to a setting that is called the replication factor.

The replication factor defines how many times data is replicated on nodes. For example a replication factor of 2 means that a given token or token range or partition will be stored on two nodes. This is the case here where partition 1 and 2 is stored on node X. Partition 2 is also stored on Node Y, while partition 1 is also stored on Node Z. So if we were to lose Node X we could still read the data from partition 1 from Node Z.
“This is how high availability is achieved and how Cassandra and ScyllaDB favor availability and partition tolerance. They are called ‘AP’ on the CAP Theorem.” This kind of token ring architecture helps with data distribution among the nodes. Queries should in theory be evenly distributed between nodes.
Alexys noted there are still ways to get an imbalance of data, especially if certain nodes had more frequently-accessed data, or if certain partitions were particularly large. “To counter this effect that we are calling a ‘hot node’ or ‘hot partition’ we need to add more variance in partition to node allocation.This is done using what is called ‘virtual nodes’ (vNodes) so instead of placing physical nodes on the ring we will place many virtual instances of them called virtual nodes.”
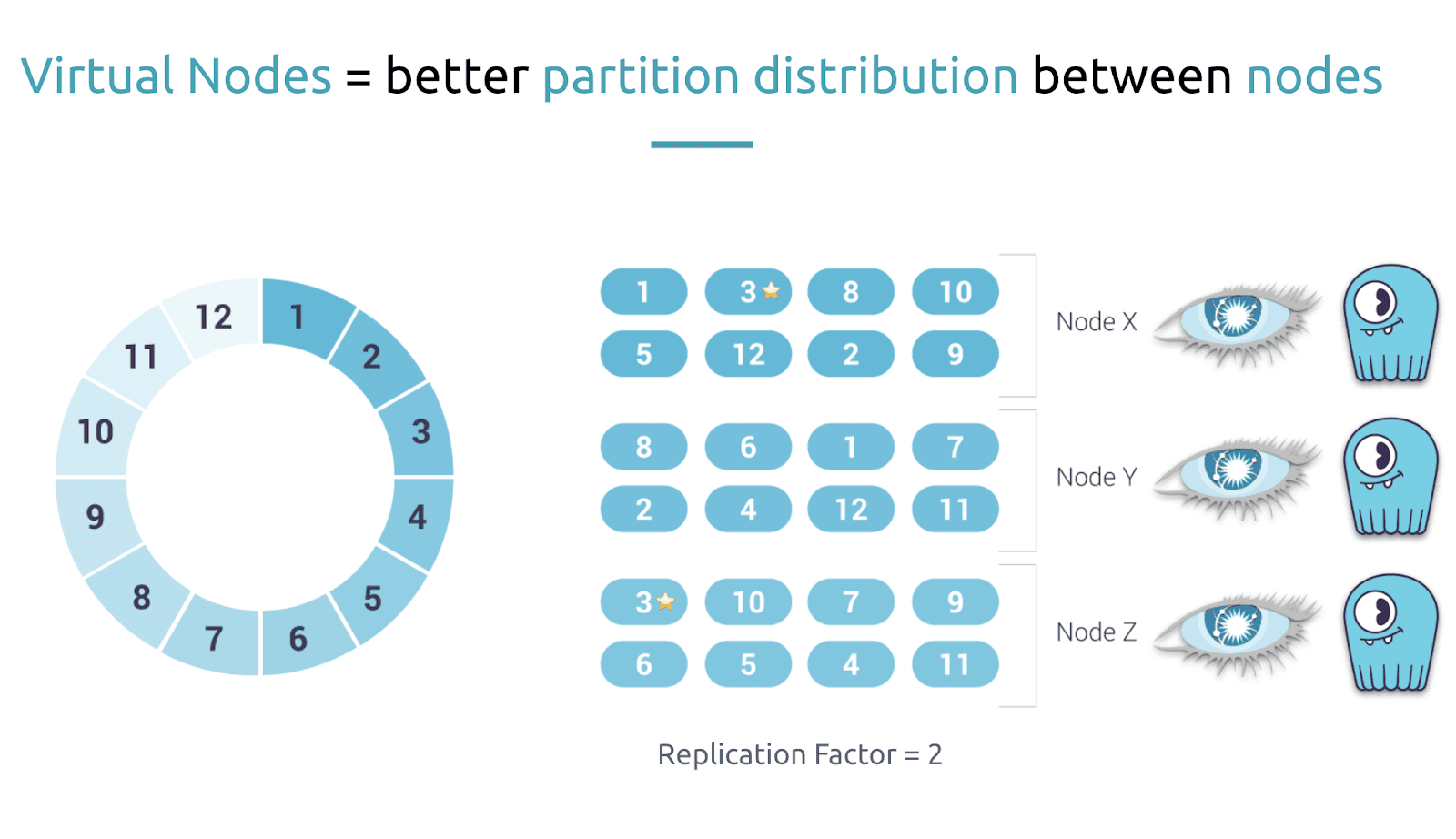
“A virtual node represents a contiguous range of tokens owned by a single node so it’s just a smaller slice of a partition but,” Alexys noted that the way the data was shuffled between nodes was more balanced. “So if you look at how now the partitions are distributed among nodes you see that there is more variance into this which will end up in distributing the query better.”
You can learn more about how data is modeled and distributed in ScyllaDB in our ScyllaDB University course, and also some pro tips for how to do it from our Tech Talk on Best Practices for Data Modeling in ScyllaDB.
At this point, everything said was the same between ScyllaDB and Cassandra, but Alexys noted that here the two systems began to diverge. “ScyllaDB goes one step further. On each ScyllaDB node tokens of a vNode are further distributed among the CPU cores of the node. These are called shards. This means that the data stored on a ScyllaDB cluster is not only bound to a node but can be traced down to one of its CPU cores.”
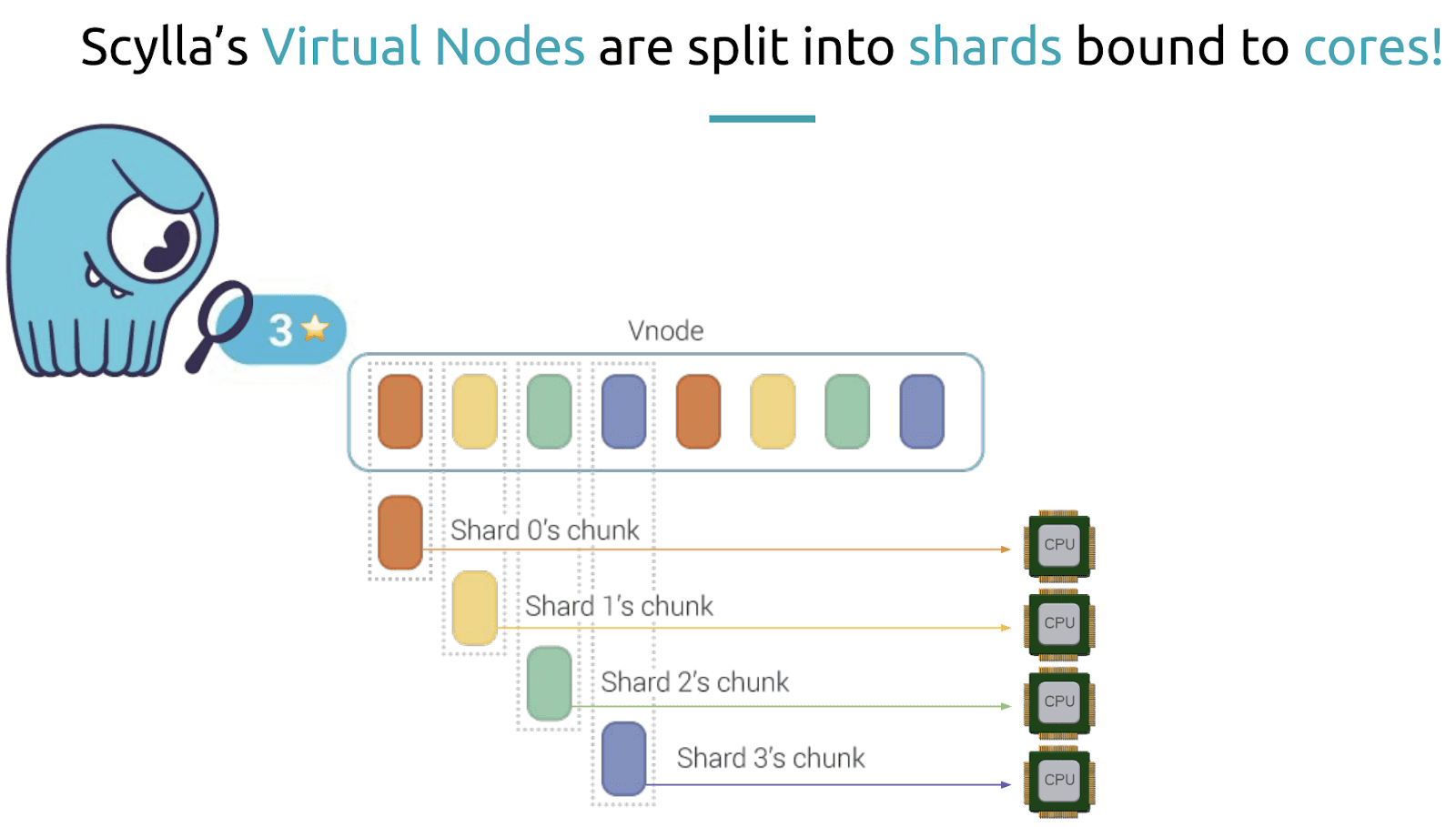
“This is a really interesting architecture and low level design. This is the feature that we will leverage in the Python shard-aware driver later on.”
Now that we understand how data is stored and distributed on the cluster, Alexys explained how it’s created by clients on the physical layer. A partition is a unit of data stored on a node and is identified by a partition key. The partitioner or the partition hash function using the partition key will help us determine where the data is stored on the given node in the cluster.
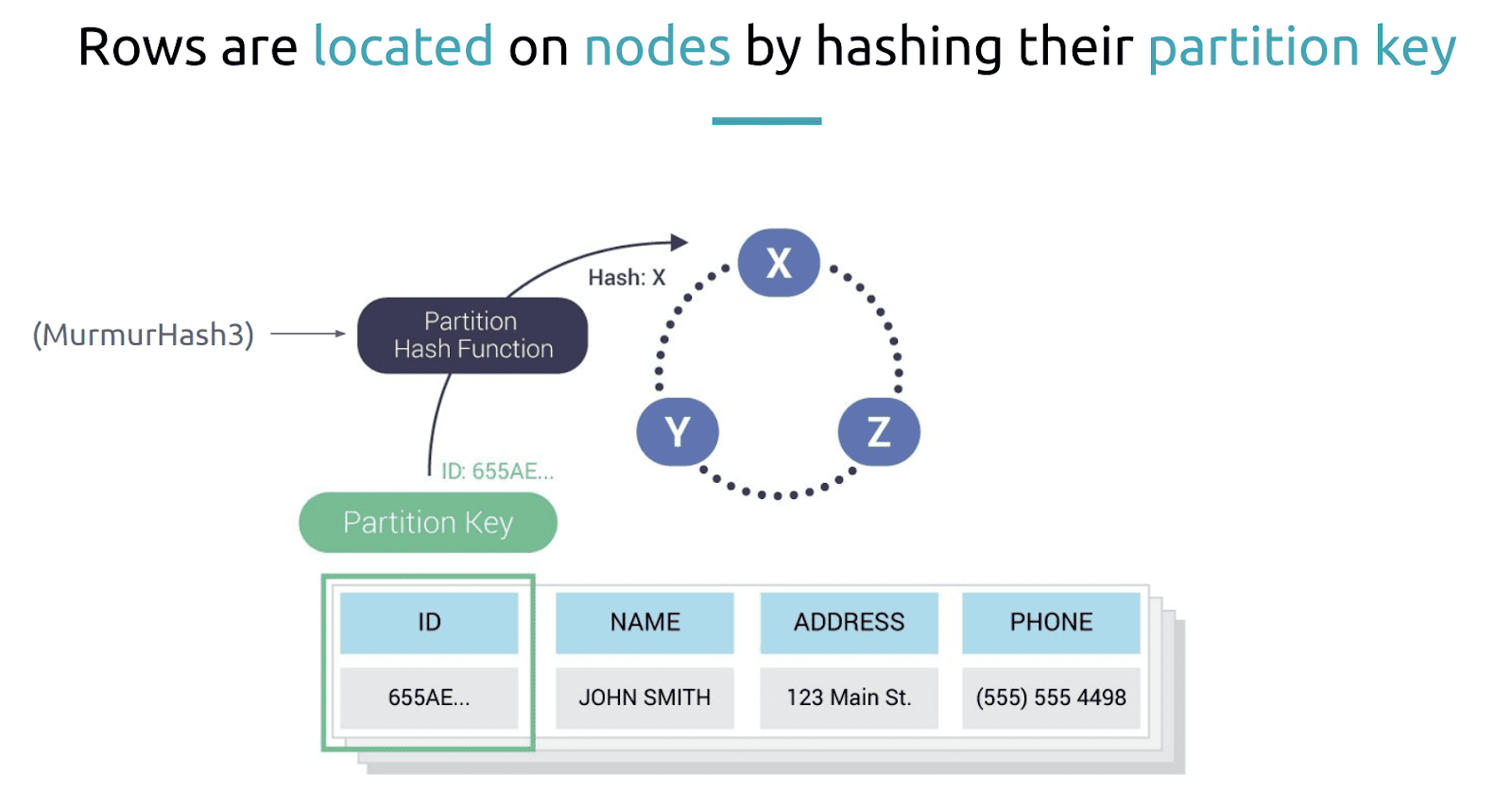
In this case a partition key will be derived from column ID. A hash function, which by default on Cassandra and ScyllaDB is a Murmur3 hash, will be applied to it. This will give you a token that will be placed on the token ring. The token falls into a vNode – a contiguous range of tokens owned by one of the nodes; this is the node that the token will be assigned to.
The main difference was that this partitioning function would be shard-per-node on Cassandra, but it would be shard-per-core (CPU core) on ScyllaDB.
In ScyllaDB, after a token is assigned to a node, the node decides on which core to place the token. To do that, the entire range of tokens is cut into equal 2n pieces, where n is a node configuration parameter, by default 12. Each piece is further cut into S smaller equal pieces, where S is the number of shards; each of the smaller pieces belongs to one of the cores. The token falls into one of these pieces, determining the core to which it is assigned.
This means ScyllaDB provides even more granular distribution and, thus, should be smoother in performance.
Client Driver Queries and Token Awareness
Alexys then described how client drivers query a Cassandra or a ScyllaDB cluster. “Because now that we know this we could guess and expect that client drivers use this knowledge to find out and optimize their query plan.” He described how a naive client would connect to a Cassandra or ScyllaDB cluster by opening the connection to any node of the cluster when it wants to issue a query, and would pick its connection randomly. However, the random node it connects to might not be where the data the client is looking for is stored.
In this case, the node acts as a coordinator for the query. “It is taking the ephemeral responsibility of routing the query internally in the cluster to the right nodes that are replicas for this data.” It is responsible for routing the query to all the replica nodes where the data resides, gathering the responses and then responding back to the client.
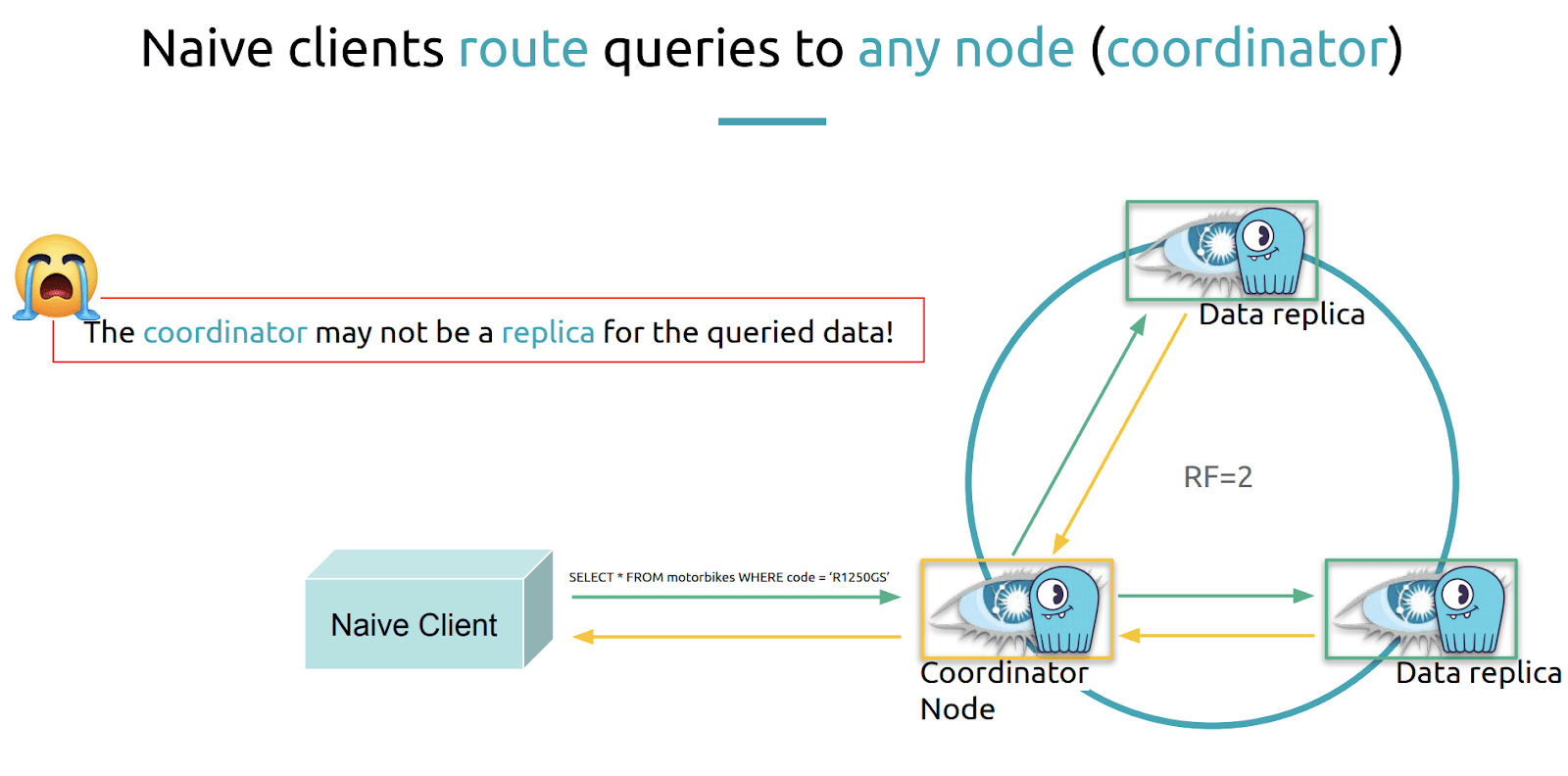
If the coordinator is not a replica for the query data it has to issue the queries to all replicas
Itself. “That means that you have an extra hop inside the cluster to get the responses. This is suboptimal of course, as it consumes network and processing power on the coordinator node for something that the client could have guessed right in the first place.”
“Because the partitioner hash function is known, our client library can use it to predict data location on the cluster and optimize the query routing. This is what the Cassandra driver does using the token aware policy.” Using token aware policy drivers, the coordinator should be selected from one of the replicas where the data is stored. Using a token aware driver means you save a network hop, reduce latency and minimize internal server load.
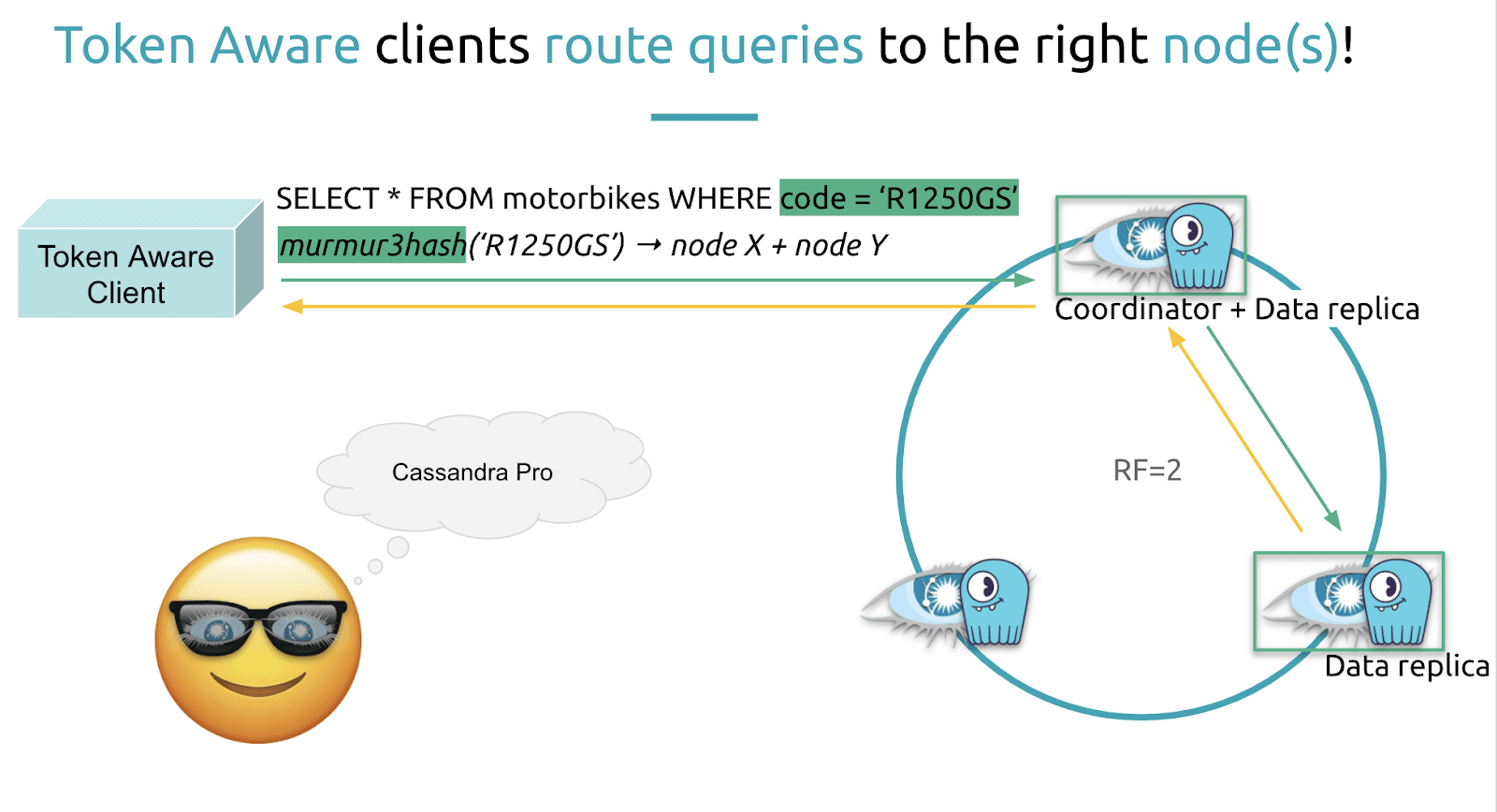
“From the point of view of the Python Cassandra driver the partition key is seen as a routing key” which is used to determine which nodes are the replicas for the query. The query itself must be prepared as a server-side statement. “You can see them a bit like stored procedures in the SQL world.”
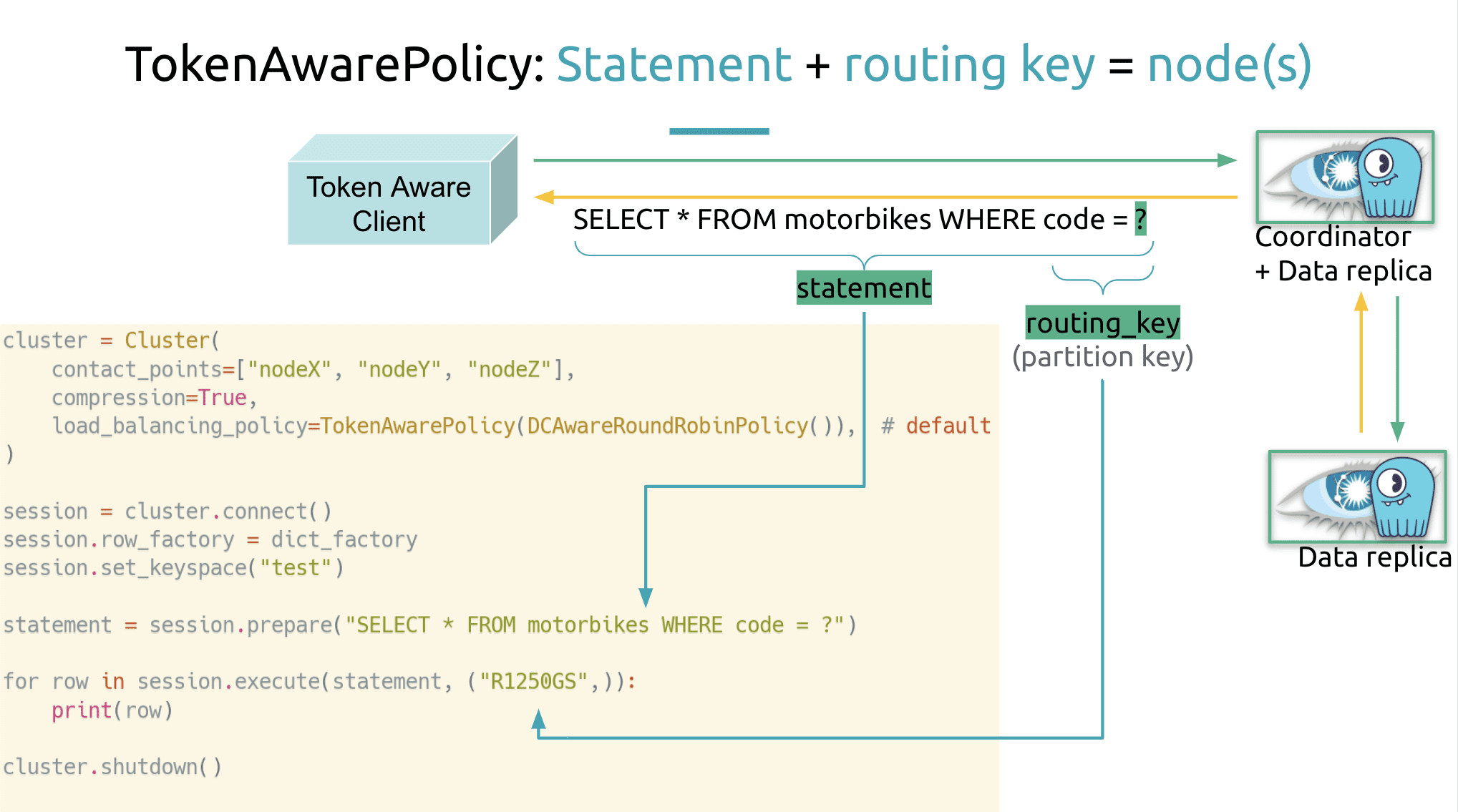
“If you see this statement = session.prepare and then you express the the query that you want,” (in this case, SELECT * FROM motorbikes WHERE code = ?) when you have an argument or parameter you just put a question mark. “This is the recommended and most optimal way to query the data because when you have prepared your query it is validated and it lives on the server side. So you don’t have to pass it. You just have to pass a reference to it and then only pass the arguments.” One of the arguments will be the mandatory routing key, partition key, “So statement + routing key = node and it’s very very cool.”
“Another thing to note is that, just like prepared stored procedures, prepared statements are also the safest way because they prevent query injection. So please in production, at the bare minimum, only use prepared statements when you issue queries to Cassandra or ScyllaDB clusters.”
(Pro tips: Learn more about CQL prepared statements in this blog post. Also note ScyllaDB Monitoring Stack allows you to optimize your CQL by observing how many non-prepared statement queries you had that did not leverage token aware drivers.)
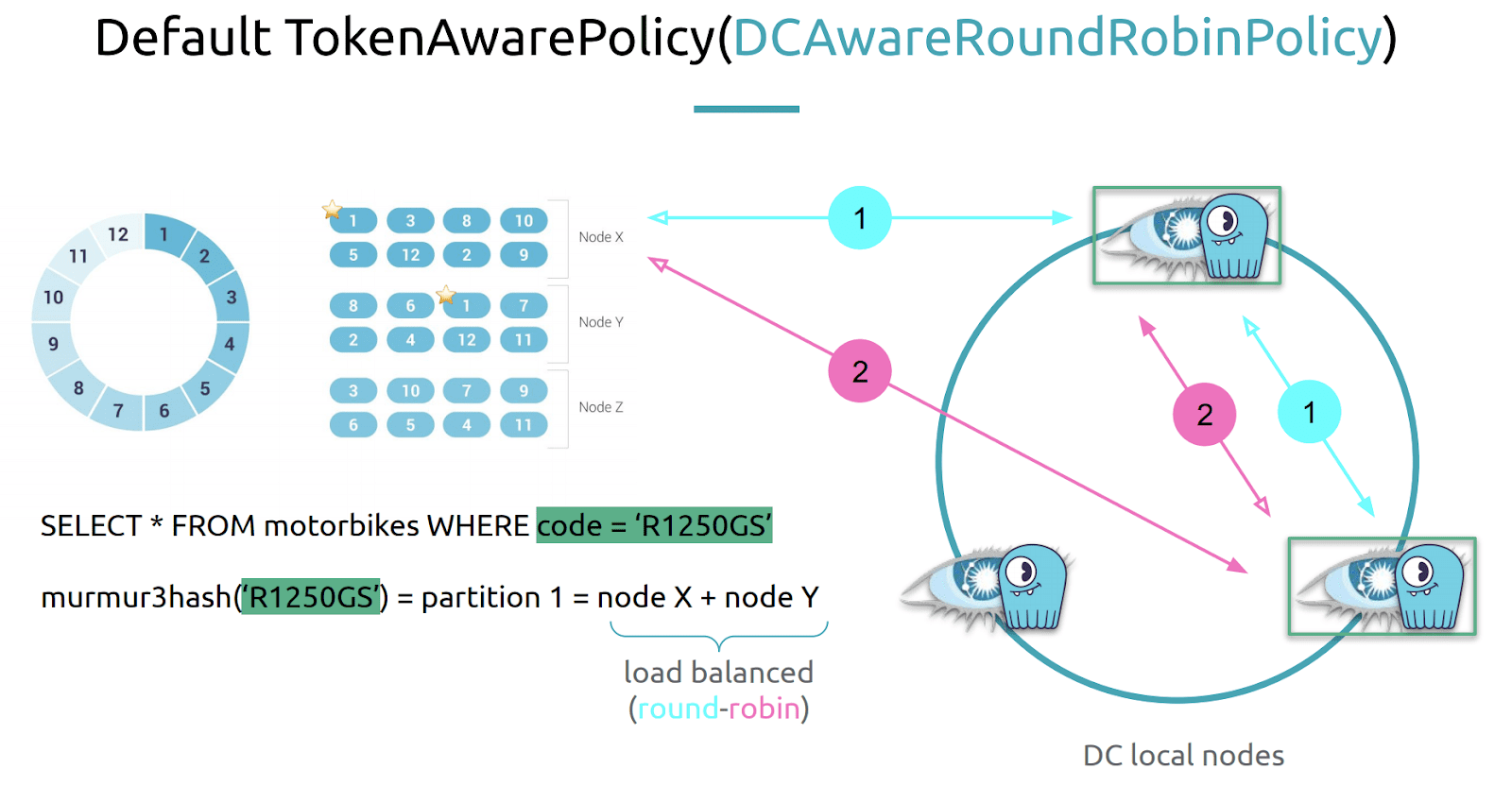
The Python Cassandra driver defaults to the token aware policy to route the query and then it also defaults to datacenter aware round robin (DCAwareRoundRobinPolicy) load balancing query routing. While that’s a bit of a mouthful, what it means is that your queries will try to balance across the appropriate nodes in the cluster. Round-robin is pretty basic but it is still pretty efficient and can be used even if your cluster is not spread across multiple datacenters.

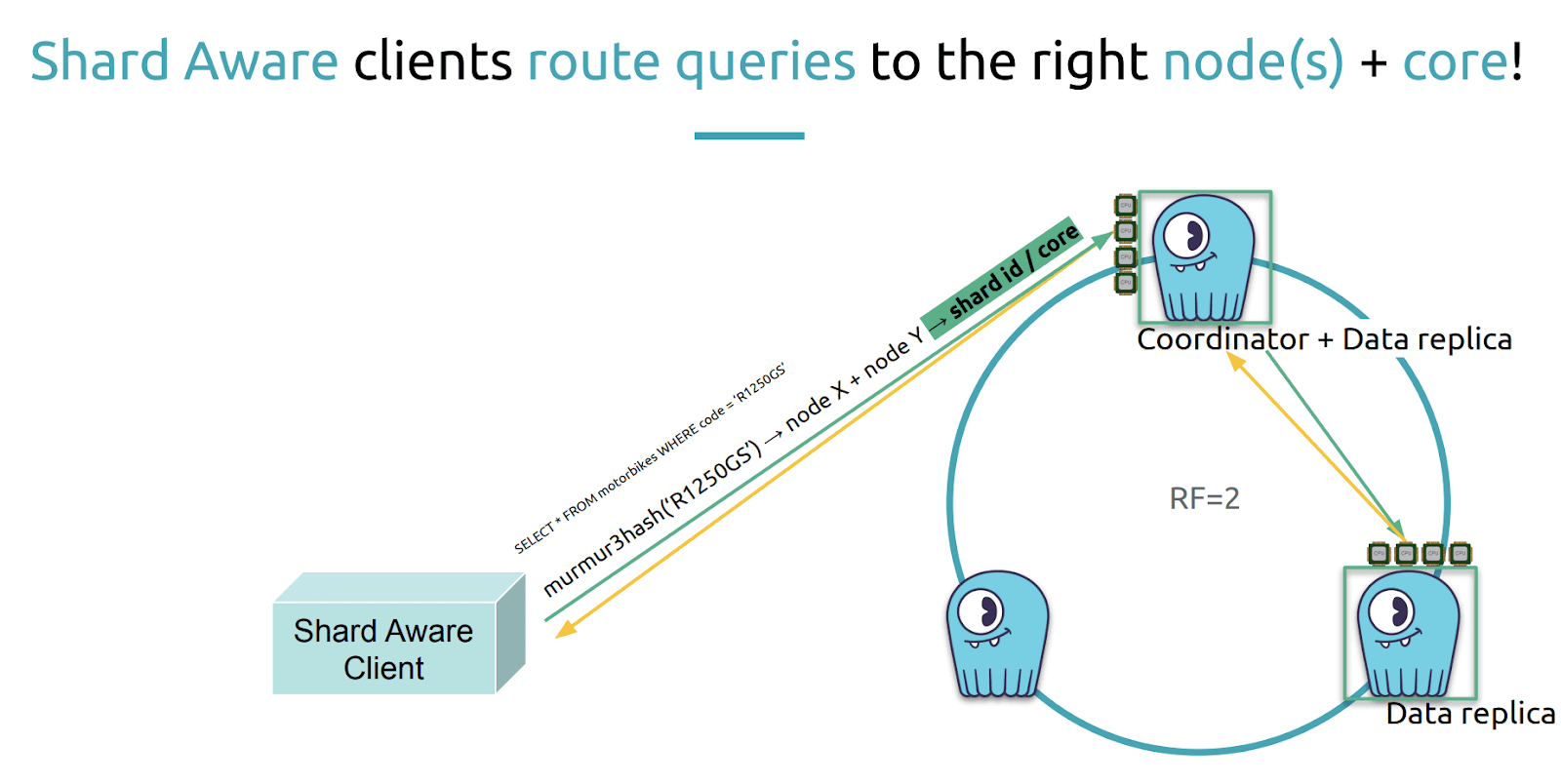
“By doing so the query routine will not only hit the right node holding a copy of the data that you seek, but also load balance the queries evenly between all its replicas.” For Cassandra this is sufficient, however Alexys noted again that ScyllaDB goes one step further, sharding data down to the CPU core. “We can do better than this. Token awareness is cool, but if our client had shard awareness it would be even cooler.”

A token aware client could be extended to become a shard-aware client to route its queries not only to nodes but right to their CPU cores. “This is very interesting to do.”
Examples from Other Languages
Alexys noted such shard-aware drivers already existed as forks of the drivers for Java and Go (learn more about those drivers in ScyllaDB University here). But there was no shard-aware driver for Python. As a championing Pythonista, Alexys was undeterred. “When I attended ScyllaDB Summit last year in San Francisco I did some hard lobbying and found some ScyllaDB developers that were willing to help in making this happen for Python as well.”
Just before that ScyllaDB Summit, when Tubi engineer Alex Bantos put the Java shard-aware driver into production, he immediately saw a balancing of transactions across the cluster, which he shared on Twitter. This was indicative of the kinds of performance improvements Alexys wanted to see from a Python shard-aware driver.
Watch the Video
If you’d like to see Alexys’ full presentation, you can view his slides online, and check out the full video here.
Check Out Part Two!
In the second installment, Alexys takes users step-by-step through the design process, shares his performance results from production deployment, and lay out next steps.










