




Project Circe is our 2021 initiative to improve ScyllaDB by adding greater capabilities for consistency, performance, scalability, stability, manageability and ease of use. For this installment of our monthly updates on Project Circe, we’ll take a deep dive into the Raft consensus protocol and the part it will play in ScyllaDB, as well as provide a roundup of activities across our software development efforts.
Raft in ScyllaDB
At ScyllaDB Summit 2021, ScyllaDB engineering team lead Konstantin “Kostja” Osipov presented on the purpose and implementation of the Raft consensus protocol in ScyllaDB. Best known for his work on Lightweight Transactions (LWT) in ScyllaDB using a more efficient implementation of the Paxos protocol, Kostja began with a roundup of those activities, including our recently conducted Jepsen testing to see how our Lightweight Transactions behaved under various stresses and partitioned state conditions.
Watch the full presentation online, or read on if you prefer.
WATCH THE TALK: RAFT IN SCYLLA
What is Raft?
Kostja noted that the purpose of implementing Raft in ScyllaDB extends far beyond enablement of transactions. He also differentiated it from Paxos, which is leaderless, by noting that Raft is a leader-based log replication protocol. “A very crude explanation of what Raft does is it elects a leader once, and then the leader is responsible for making all the decisions about the state of the database. This helps avoid extra communication between replicas during individual reads and writes. Each node maintains the state of who the current leader is, and forwards requests to the leader. ScyllaDB clients are unaffected, except now the leader does some more work than the replicas, so the load distribution may be uneven. This means ScyllaDB will need to support multiple Raft groups — Raft instances — to evenly distribute the load between nodes.”
“Raft is built around the notion of a replicated log,” Kostja explained. “When the leader receives a request, it first stores an entry for it in its durable local log. Then makes sure this local log is replicated to all of the followers, the replicas. Once the majority of replicas confirm they have persisted the log, the leader applies the entry and instructs the replicas to do the same. In the event of leader failure, a replica with the most up-to-date log becomes the leader.”
“Raft defines not only how the group makes a decision, but also the protocol for adding new members and removing members from the group. This lays a solid foundation for ScyllaDB topology changes: they translate naturally to Raft configuration changes, assuming there is a Raft group for all of the nodes in the cluster, and thus no longer need a proprietary protocol.”
“Schema changes translate to simply storing a command in the global Raft log and then applying the change on each node which has a copy of the log.”
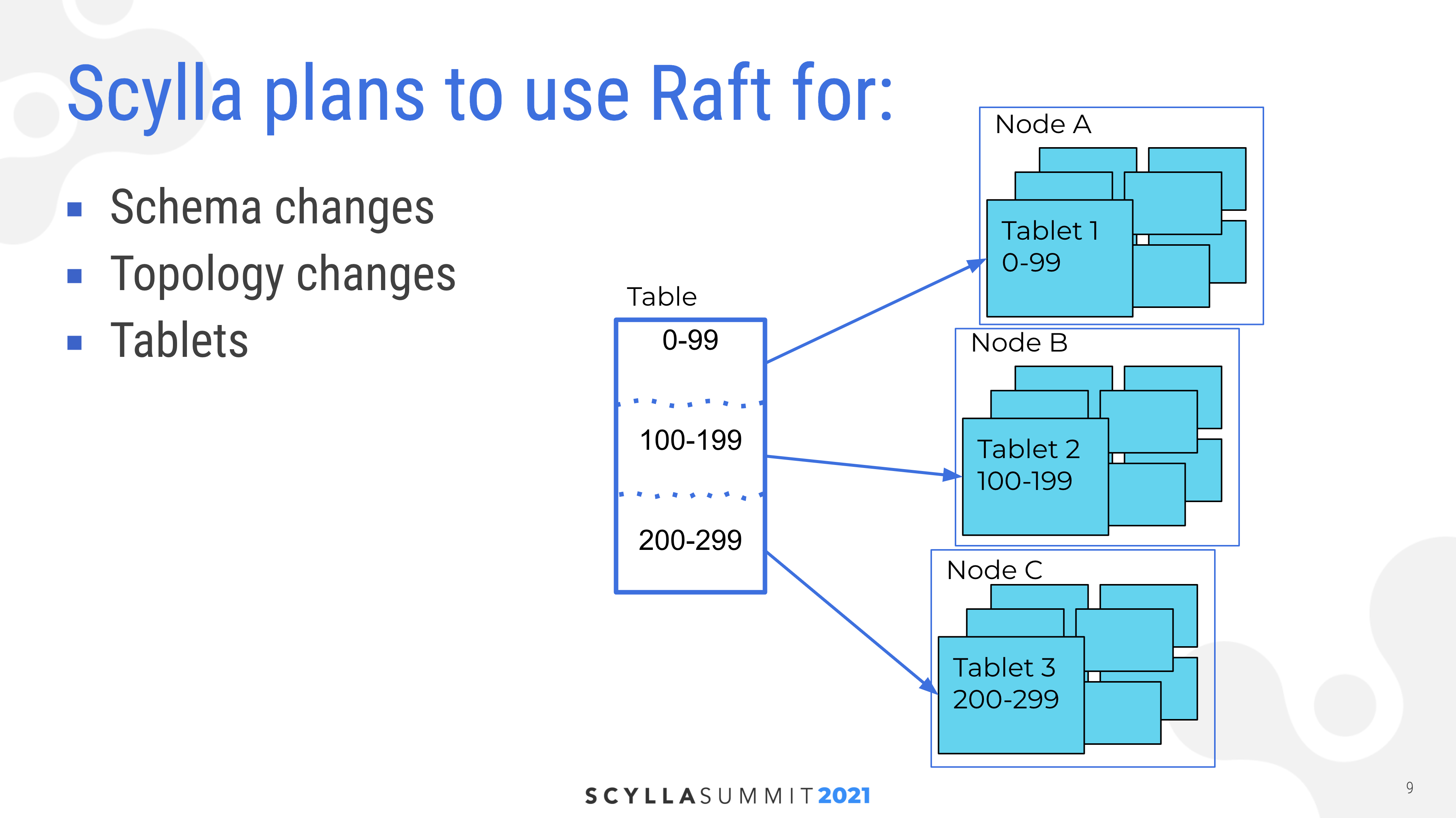
“Because of the additional state stored at each peer, it’s not as straightforward to do regular reads and writes using Raft. Maintaining a separate leader for each partition would be too much overhead, considering individual partition updates may be rare.”
“This is why ScyllaDB is working on a new partitioner alongside Raft, which would reduce the total number of tokens or partitions, while still keeping the number high to guarantee even distribution of work. It will also allow balancing the data between partitions more flexibly. We will call such partitions tablets. ScyllaDB will run an independent Raft instance for each tablet.”.
Topology Changes
“Presently, topology changes in ScyllaDB are eventually consistent. Let’s use node addition as an example. A node wishing to join the cluster advertises itself to the rest of the members through gossip.
For those of you not familiar with gossip, it’s an epidemic protocol which is good for distributing some infrequently changing information at low cost. It’s commonly used for failure detection. So when the cluster is healthy it imposes very low overhead on the network. And the state of a failing node is disseminated across the cluster reasonably quickly. Several seconds would be a typical interval.”
“Since gossip is not too fast, the joining node waits by default for 30 seconds to let the news spread. Then nodes that received information about the joining node begin forwarding reads and writes once they become aware of it. Once the joining node waits for the interval and starts receiving updates it can begin data rebalancing.”
“Node removal or decommission works similarly, except the node gossiping about the node being removed is not the node being removed, because that node is already basically dead. So this is very similar to real life. Not all of the gossip spread about us is spread by us. Most of it is not spread by us.”
“This poses some challenges. If some of the nodes in the cluster are not around while a node is joining it will not be aware of the new topology. So as soon as it is back, and before gossip is actually reaching it with news about the new joined node, it will assume the old topology [is still valid] and serve reads and writes using the old topology. This is not terrible, but repair will be needed to bring the writes that were served using this old topology back to the new node.”
“Another issue is that information dissemination of gossip is fairly slow. One way we reason about how we could add multiple nodes to the cluster concurrently, we think about splitting node addition or node topology change operations into multiple steps. And communicating between the nodes during each step independently. Relying upon gossip in that case would be impractical. That would require a thirty second interval for each step.”
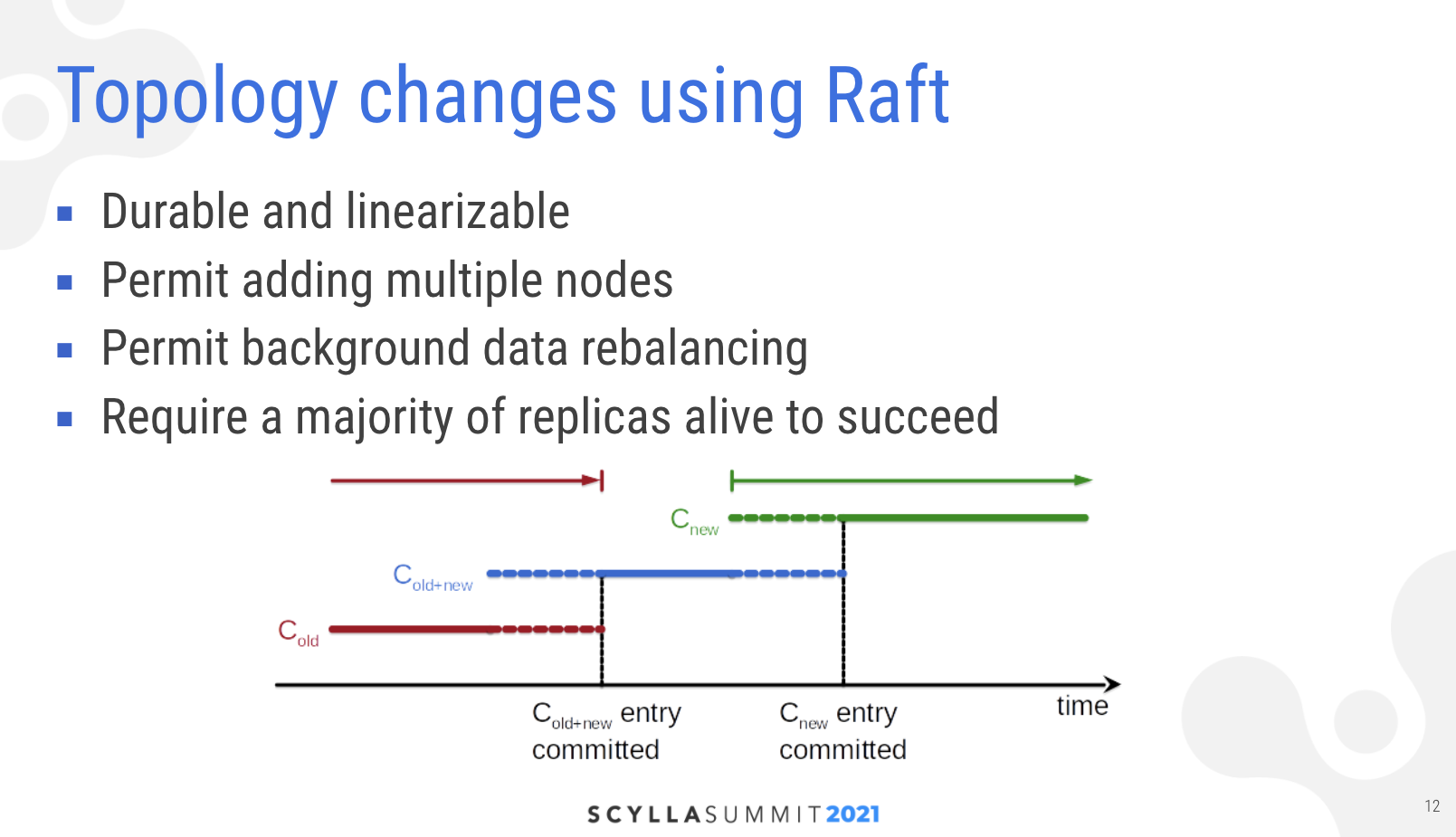
Raft handles these challenges by including topology changes (called “configuration changes”) in its protocol core. This part of Raft protocol is also widely adopted and went under extensive scrutiny, so should be naturally preferred to ScyllaDB’s proprietary gossip-based solution inherited from Cassandra.
“It approaches configuration [topology] changes very similarly to regular reads and writes,” Kostja noted. “The first thing Raft does about the configuration change is [the leader] stores information about it in the log. The first entry stored in the log is special. It informs all of the followers and replicas. They now need to begin to work in this new joint configuration. They need to take this new configuration into account while still ensuring they also reach all of the nodes from the old configuration in case they become deleted.”
“Then when the leader knows that the majority of replicas in the cluster have received this joint configuration it stores another auxiliary entry in the log that informs the nodes to switch entirely to the new configuration. This approach guarantees that the majority of the cluster actually works in the new configuration all together. So some nodes know the old configuration, and some nodes use this new configuration.”
“The worst case that can happen is that some nodes in this majority will use the joint configuration and other nodes will use the old configuration, or some nodes use joint configuration and some nodes use new configuration. But since joint configuration includes both old and new, these configurations are compatible so this preserves linearizability of configuration changes.”
“In ScyllaDB we plan to use Raft for configuration changes as the first step of any topology change. So when a node is joining or leaving it will first be added or last removed from the global Raft group. Then we can use the global Raft log to consistently store the information about the actual range movement, token additions, token removals and so on.”
Schema Changes
“Schema changes are operations such as creating and dropping key spaces, tables, user defined types or functions. If they are using Raft they can also benefit from linearizability.”
“Currently schema changes in ScyllaDB are eventually consistent. Each ScyllaDB node has a full copy of the schema. Requests to change schema are validated against a local copy and then applied locally. A new data item might be added immediately following the schema change, so before any other nodes even know about the new schema.”
“There is no coordination between changes at different nodes, and any node is free to propose a change. The changes eventually propagate through the cluster and the last time stamp wins rule is used to resolve conflicts if two changes against the same object happen concurrently.”
“Data manipulation is aware of this possible schema inconsistency. A specific request carries a schema version with it. ScyllaDB is able to execute requests with divergent history. So it will fetch the necessary schema version just to execute the request. This guarantees the schema changes are fully available even in the presence of severe network failures.”
“It has some downsides as well. It is possible to submit changes that conflict: define a table that uses UDT, then drop that UDT. New features — such as triggers or functions, UDFs — aggravate the consistency problem.”

“Schema changes using Raft also benefit from linearizability. After switching them to Raft any node would still be able to propose a change. The change would be forwarded to the leader. The leader validates it against the latest version of the schema. Then it will store the entry for the schema change in the Raft log, make sure it’s disseminated among the majority of the nodes, and only then will it apply the change on all of the nodes in linearizable order.”
“With this approach, changes will form a linear history and divergent changes will be impossible. It should open the way for more complex but safe dependencies between schema objects such as triggers, functional indexes, and so on.”
“Replicas that were down while the cluster has been making schema changes will first catch up with the entire history of the schema changes and only then will start serving reads and writes. There is also a downside: it will not be possible to do a schema change on an isolated node, or a node which is isolated from the majority.”
“Still possible, even with this approach, is that the node gets a request — say an eventually consistent write — that uses an old version of the schema, or a version of the schema the node is still not aware of. In this case the node which doesn’t have the schema will still have to pull it like we do today.”
Tablets
“Finally, the ultimate feature enabled by Raft are fast and efficient, strongly-consistent tables. Tablets is a term for a database unit of data distribution load balancing first introduced in Google Bigtable in 2016. Let’s see how they work.”
“Today’s ScyllaDB partitioning strategy is not pluggable. Compare it with replication strategy. You can change how many replicas you have. Where these replicas are located. What is the consistency level you use for each read and write. The ScyllaDB partitioner is not like that. All you can do is define a partitioning key and then the partition key is mapped to a token, and tokens map to a specific replica set or shard.”
“Thanks to hashing and use of vNodes, the data is evenly distributed across the cluster. Most write and read workloads produce even load on all [nodes] of the cluster. Even including such workloads as time series workloads. So hotspots are unlikely.”
“Despite excellent randomization provided by applying hashing, oversized partitions and very hot tokens are possible: you cannot select the partition key perfectly, so some keys will naturally have more data or will be more frequently accessed. Frequent range scans over even over small tables require streaming from many nodes, even if they stream very little data.”

“With tablets we would like to introduce a partitioning strategy which is based on data size, not only the number of partitions it contains, or on partition hash. Tablets split the entire key range over the primary key range and make sure that every tablet contains roughly equal numbers of data. When the tablet becomes too big it is split. When it becomes too small it’s coalesced — two small adjacent tablets are merged into one. This is called dynamic load balancing.”
“Another good thing about tablets is that even in very large clusters there can’t be too many of them. Like a hundred thousand tablets is 64 terabytes of data. This means we can have a reasonable number of Raft groups.”
“Every tablet will have its own Raft log. If a Raft log is used for reads and writes we cannot accept client-side timestamps because there is a single linearizable order for all writes to the table. We provide serial consistency for all queries. Writes do not need to require a read like LWT. There is no need to repair because Raft automatically repairs itself. There still may be a need to repair the Raft log itself, but this is different from repairing the actual data.”
“Those of you who are familiar with consistency of materialized views know that it’s very hard to make materialized views consistent in the presence of eventual consistent writes to the base table. This problem will also be solved with Raft and tablets.”
Project Circe Progress for February 2021
Recent Raft Developments
Since our ScyllaDB Summit there have been Raft-related commits into our repository to bring these plans to fruition.
- Raft Joint Consensus has been merged. This is the ability to change a Raft group from one set of nodes to another. This is needed to change cluster topology or to migrate data to different nodes.
- Raft now integrates with the ScyllaDB RPC subsystem; Raft itself is modular and requires integration with the various ScyllaDB service providers.
DynamoDB-Compatible API Improvements
In line with the broad set of capabilities outlined in Project Circe, we’re also making improvements to our Amazon DynamoDB-compatible interface, called Alternator.
- We now support nested attributes #5024
- Alternator: support Cross-Origin Resource Sharing (CORS) #8025
- Support limiting the number of concurrent requests in Alternator #7294
ScyllaDB Operator for Kubernetes
ScyllaDB Operator 1.1 is almost released (rc) with many bug fixes and three Helm Charts, especially useful for users interested in customizing their ScyllaDB setups:
- scylla – allows for customization and deployment of ScyllaDB clusters.
- scylla-manager – allows for customization and deployment of ScyllaDB Manager.
- scylla-operator – allows for customization and deployment of ScyllaDB Operator.
To help you start using new Helm Charts, we added an example run to our documentation.







