Repair is one of several anti-entropy mechanisms in ScyllaDB. It is used to synchronize data across replicas. In this post, we introduce a new repair algorithm coming with ScyllaDB Open Source 3.1 that improves performance by operating at the row-level, rather than across entire partitions.
What is Repair?
During regular operation, a ScyllaDB cluster continues to function and remains ‘always-on’ even in the face of failures such as:
- A down node
- A network partition
- Complete datacenter failure
- Dropped mutations due to timeouts
- Process crashes (before a flush)
- A replica that cannot write due to a lack of resources
As long as the cluster can satisfy the required consistency level (usually a quorum), availability and consistency will be met. However, in order to automatically mitigate data inconsistency (entropy), ScyllaDB, following Apache Cassandra, uses three processes:
- Hinted Handoff: automatically recover intermediate failures by storing up to 3 hours of untransmitted data between nodes.
- Read Repair: fix inconsistencies as part of the read path.
- Repair: described below.

The infinite War: Chaos Monster and Sun God, Chaos vs Order, Entropy vs ScyllaDB Repair. (Source: Wikimedia Commons)
ScyllaDB repair is a process that runs in the background and synchronizes the data between nodes so that all replicas eventually hold exactly the same data. Repairs are a necessary part of database maintenance because data can become inconsistent with other replicas over time. ScyllaDB Manager optimizes repair and automates it by running the process according to a schedule.
In most cases, the proportion of data that is out of sync is very small, while in a few other cases, for example, if a node was down for a day, the difference might be bigger.
How Repair Works in ScyllaDB Open Source 3.0
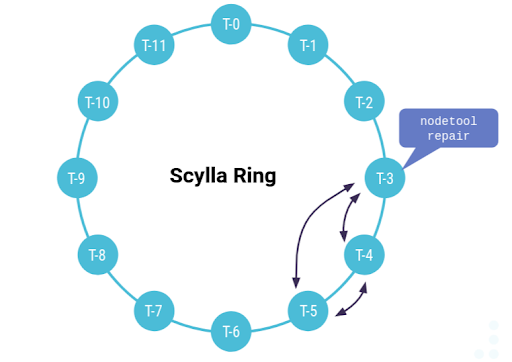
Running repair on node T-3
In ScyllaDB 3.0, the repair master, the node that initiates the repair, selects a range of partitions to work on and executes the following steps:
- Detect mismatch
- The repair master splits the ranges into sub-ranges that contain around 100 partitions.
- The repair master computes the checksum of each sub-range and asks the related peers to compute the checksum of the same subrange.
- Sync mismatch
- If the checksums match, the data in this sub-range is already in sync.
- If the checksums do not match, the repair master fetches the data from the followers and sends back the merged data to followers.
What is the Problem with ScyllaDB 3.0 Repair?
There are two problems with the implementation described above:
- Low granularity may cause a huge overhead: a mismatch of a single row in any of the 100 partitions causes 100 partitions to be transferred. Even a single partition can be very large, not to mention the size of 100 partitions. A difference of just a single byte can easily cause 10GB of data to be streamed.
- The data is read twice: once to calculate the checksum and find the mismatch and again to stream the data to fix the mismatch.
Clearly, the two issues above can significantly slow down the repair process, needlessly sending a huge amount of unnecessary data over the wire. In the case of a cross datacenter repair, this extra data translates into additional costs.

Basic repair unit in ScyllaDB 3.0 and prior: 100 partitions
What is a Row-level Repair?
By now the solution for the above seems straightforward: repair should work at the row-level, not the partition-level. Repair should transfer only the mismatched rows.

Basic repair unit beginning in ScyllaDB 3.1: A row
The new Row Level Repair improves ScyllaDB in two ways:
Minimize data transfer
With Row Level Repair, ScyllaDB calculates the checksum for each row and uses set reconciliation algorithms to find the mismatches between nodes. As a result, only the mismatched rows are exchanged, which eliminates unnecessary data transmission over the network.
Minimize disk reads
The new implementation manages to:
- Read the data only once
- Keep the data in a temporary buffer
- Use the cached data to calculate the checksum and to send to the replicas.
Results
In a benchmark done on a three-node ScyllaDB cluster on AWS using i3.4xlarge instances, each with 1 billion rows (1 TB of data, with 1 KB of data per row) and no background workload, we tested three use cases, representing three cluster failure types:
- 0% synced: node has completely lost its data. This use case is where the repair needs to sync *all* of its data. In practice, it is better to run a node replace procedure in this case.
- 100% synced: very likely, there were zero failures since the last repair, and the data is in sync. Still, we would like to minimize the effort in reading the data and validate it is the case.
- 99.9% synced: The nodes are almost in sync, but there are a few mismatched rows.
Below are the results for each of the above cases with the old and new repair algorithm.
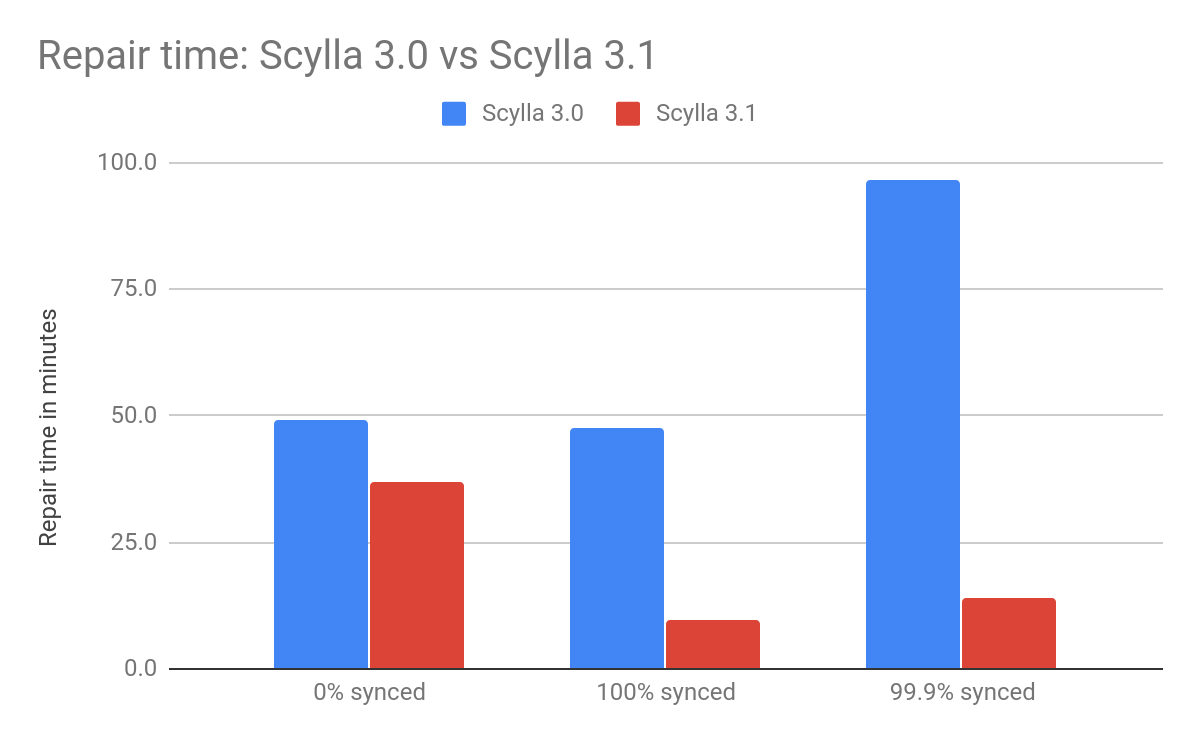
| Test case | Description | Time to repair | Ratio | |
| ScyllaDB 3.0 | ScyllaDB 3.1 | |||
| 0% synced | One of the nodes has zero data. The other two nodes have 1 billion identical rows. | 49.0 min | 37.07 min | x1.32 faster |
| 100% synced | All of the 3 nodes have 1 billion identical rows. | 47.6 min | 9.8 min | x4.85 faster |
| 99.9% synced | Each node has 1 billion identical rows and 1 billion * 0.1% distinct rows. | 96.4 min | 14.2 min | x6.78 faster |
The new row-level repair shines (x6.78 faster) where a small percent of the data is out of sync — which is the most likely use case.
For the last test case, the bytes sent over the wire are as follows:
| ScyllaDB 3.0 | ScyllaDB 3.1 | Transfer data ratio | |
| TX | 120.52 GiB | 4.28 GiB | 3.6% |
| RX | 60.09 GiB | 2.14 GiB | 3.6% |
As expected, where the actual difference between nodes is small, sending just relevant rows, rather than 100 partitions at a time, makes a huge difference: less than 3.6% of the data transfer compared to 3.0 repair!
For the first and second test cases, the speedup comes from two factors:
- More parallelism: In ScyllaDB 3.0 repair, only one token range is repaired per shard at a time. While in 3.1 repair, ScyllaDB repairs more (16) ranges in parallel.
- Faster hash: In ScyllaDB 3.0 repair, the 256-bit cryptographic SHA256 hash algorithm is used; in ScyllaDB 3.1 repair, we switch to a faster, 64-bit non-cryptographic hash. This was possible as 3.1 repair less data to hash per hash group.
Conclusions
With the new row-level repair, we fixed two major issues in the previous repair implementation.
The new algorithm proves to work much faster and sends only a fraction of the data between nodes. This new implementation:
- Shortens the repair time, reducing the chance of failure during the repair (which requires a restart)
- Reduces the resource consumption of the CPU, Disk, and network, and thus frees up more resources for on-line requests.
- Significantly reduces the data transfer amounts between nodes and reduces the costs in cloud deployments (which charge for data transfers between Regions).
We have even more repair improvements planned for upcoming versions of ScyllaDB. Please stay tuned!