



Shrinking infrastructure costs with ScyllaDB
Comcast Xfinity improved user experience and shrank their cluster from 962 nodes with Cassandra to 78 nodes on ScyllaDB, reducing administrative overhead over 90%.
ScyllaDB powers real-time AI with low latency, high throughput, and billion-scale data.
Learn More
ScyllaDB is purpose-built for data-intensive apps that require high throughput & predictable low latency.
Learn More
Home Compare Landing Page ScyllaDB vs. Apache Cassandra
ScyllaDB was built from the ground up to achieve predictable low latency and operational simplicity at scale. Our close-to-the-metal architecture squeezes every ounce of power from the hardware – so you can achieve better performance on fewer nodes. With a similar architecture, data format, and query language as Cassandra, you eliminate Cassandra pains without major refactoring.
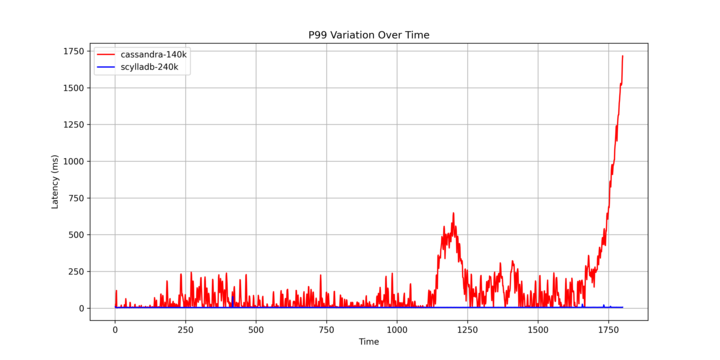
ScyllaDB delivers consistent, reliable real-time performance. That’s because its built-in schedulers prioritize reads and writes over maintenance tasks, such as repairs and compactions — eliminating latency spikes. With ScyllaDB, you never experience garbage collection stalls, which impact Cassandra performance.
“Fetching historical messages had a p99 of 40-125ms on Cassandra, with ScyllaDB having a nice and chill 15ms p99 latency. Message insert performance went from 5-70ms p99 on Cassandra to a steady 5ms p99 on ScyllaDB.”
The total cost of ownership (TCO) with ScyllaDB is much less than that of Cassandra. ScyllaDB was designed from the ground up to deliver the best possible price-performance. Its low-level design squeezes every cycle from your CPU. ScyllaDB runs as close as possible to 100% CPU utilization, with every operation given a priority class. There is no need to wastefully over-provision.
ScyllaDB has a notable maintainability advantage as well. It scales up to any number of cores and can stream data to a 60TB meganode just as fast as it does to smaller nodes. These capabilities enable you to shrink your Cassandra cluster by 10x.
“We’ve decreased our P99, P999, and P9999 by 95%. And we’re moving from 962 nodes of Cassandra down to 78 ScyllaDB nodes.”
ScyllaDB seamlessly scales both vertically and horizontally. You no longer need to be confined to a single instance type or spend countless hours tuning a database. Unlike Cassandra, ScyllaDB tunes itself against the hardware it runs on, and transparently detects when different node densities exist in a cluster, evenly spreading the load among them. ScyllaDB also supports parallel scaling operations, allowing you to easily expand and shrink cluster capacity on-demand.

“Cassandra required a lot of babysitting. It was horizontally scalable, but that came at a steep cost. We not only reduced TCO, but also reduced the pain required to keep the cluster in a healthy state.”
ScyllaDB and Cassandra are identical where it counts: The CQL protocol and queries, nodetool, SSTables and compaction strategies. ScyllaDB supports many of the same open-source projects and integrations as Cassandra, including Spark, Kafka (using our optimized ScyllaDB connector), Presto, JanusGraph, and many others. ScyllaDB even provides a Spark-based ScyllaDB Migrator to automate the process.
ScyllaDB’s innovative shard-per-core design divides a server’s resources into shared-nothing units of CPU-core, RAM, persistent storage and network I/O. ScyllaDB runs at near maximum utilization on all available cores of multi-CPU hardware architectures. ScyllaDB’s end-to-end sharded architecture, along with shard-aware drivers means that each client writing or requesting data can send queries directly to the CPU core responsible for that shard of data. This minimizes hot shards and removes extra hops.
At the heart of ScyllaDB lies its core engine, the Seastar framework, a standalone library developed by ScyllaDB. Seastar has a specialized scheduler with a fully async programming paradigm of futures and promises and advanced concepts like coroutines, that can run a million lambda functions per core per second. Seastar is responsible for scheduling, networking, Direct Memory Access, shard-per-core memory allocators, and so forth. Seastar is written in C++20 and uses every innovative trick and paradigm. Find out more about ScyllaDB’s “everything-async” architecture here.
ScyllaDB uses C++20 and the best compiler techniques, as well as deep knowledge of the Linux kernel and per-core hyperthreading to maximize CPU utilization. ScyllaDB also automatically configures your network card interrupts to balance interrupt request (IRQ) processing across CPU cores. ScyllaDB explicitly chooses to read-ahead data from the drive when it expects a follow-on disk access instead of blindly relying on the disk, as is the case with Cassandra. ScyllaDB controls all aspects of CPU execution and runs procedures to use the CPU idle time so memory layout will be optimized.
Like Apache Cassandra, ScyllaDB’s client driver is topology-aware and will prefer a node that owns the key range under query. ScyllaDB takes this design one step further and enables the client to reach the specific CPU core within the replica that owns that shard of data. This design improves load balancing among the servers and provides superior performance by avoiding needless concurrency overhead. Shard-aware ScyllaDB drivers are available for Java, Go, Python, C++ and Rust. However, ScyllaDB also fully supports standard Cassandra/DSE drivers for frictionless replacement compatibility.
ScyllaDB’s lightweight transactions (LWT) use a Paxos algorithm mechanism similar to Cassandra, but they involve one fewer round trips, making them more efficient, faster, and with lower latency. While Cassandra issues a separate read query to fetch the old record, ScyllaDB piggybacks the read result on the response to the prepare round. ScyllaDB’s LWT has a special commitlog mode that automatically balances between the transaction durability flush requirement and fast, non-transactional operations.
Per-query cache bypass clause on SELECT statements allows for range scan queries that typically process large amounts of data to skip reading the cache and avoids populating the cache, flooding it with data. Bypass cache keeps your working set in-cache, enabling you to squeeze more performance from your cluster and minimizes RAM overhead, so real-time queries receive the best latency.
ScyllaDB is designed to be Non-Uniform Memory Access (NUMA)-friendly, with highly optimized memory management down to the application binaries. Each shard of data is assigned its own chunk of RAM and CPU core, bound within the same socket. This is referred to as “NUMA-local” processing. A non-NUMA-friendly deployment causing memory access to be twice as expensive.
ScyllaDB implements a different repair checksum algorithm that resembles rsync and runs the checksum at row granularity instead of partition granularity. The new algorithm conciliates repair faster and more efficiently, sends less data over the wire reducing network traffic and is less sensitive to large partitions.
DSE instead uses a Merkle tree mechanism for anti-entropy repairs. It has no row-level repair mechanism, and thus repairs take longer and are far less efficient, generating many times more network traffic and degrading overall performance.
ScyllaDB’s I/O scheduler prioritizes read/write operations class over compactions. When reads and writes spike, ScyllaDB automatically queues compaction activity so that they do not impact your throughput or latencies. ScyllaDB runs compaction at full speed only when there is CPU/disk idle time, with all cores running compactions in parallel.
With Cassandra and its heavier utilization of system resources, you have to worry about and track compactions. When making a Cassandra comparison keep in mind that ScyllaDB requires no brittle tuning.
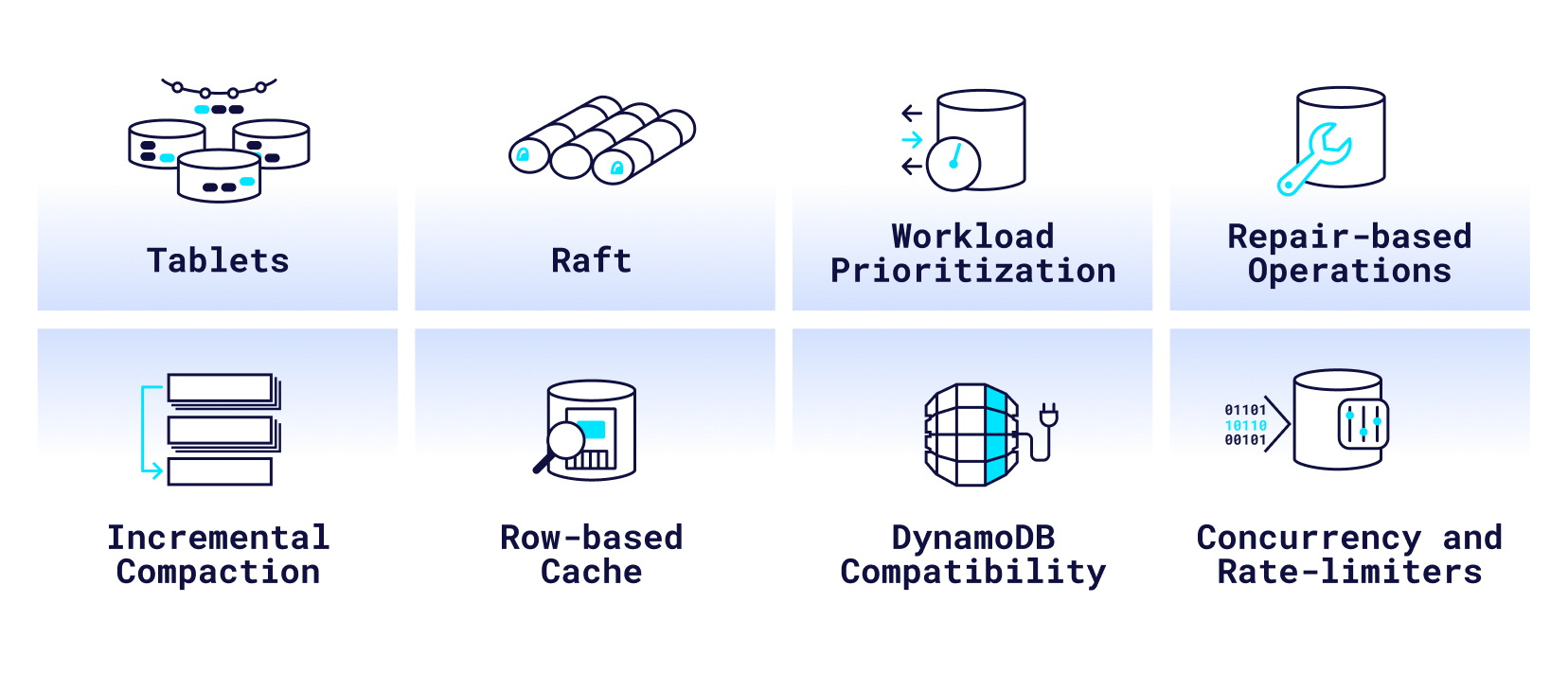
ScyllaDB allows for operational and analytics workloads to run against a shared cluster — a unique feature we call Workload Prioritization. ScyllaDB’s built-in scheduler prioritizes transactions and tasks based on ‘shares’ of system resources assigned per-user, balancing requests to maintain desired service level agreements (SLAs) for each service. This enables you to run a single cluster that is scaled to support both types of operations, simplifying your architecture and saving on hardware provisioning.
With Cassandra, you have no control over system utilization so that, for example, full scan queries could cause timeouts, blocking ongoing write transactions.
ScyllaDB is written in natively compiled C++, and thus does not use a Java Virtual Machine (JVM). There is no need to optimize JVM flags, and you can forget about Garbage Collection (GC) stalls, tuning, and surprises. With ScyllaDB, there is no need to compute heap sizes, no need to divide the RAM between the JVM, the off-heap, and the page cache. Cassandra suffers from the worst of all possible worlds, having to manage memory (pools, off-heap), ongoing tuning, and suffering slowdowns due to the JVM.
Forget about tuning your database! Upon installation, ScyllaDB runs a benchmark to measure your disk and will make all of the Linux configurations on your behalf — from RAID setup to clock drift and fstrim disk scheduling. Using control theory, ScyllaDB continuously makes the database less fragile by dynamically tuning the way resources are used instead of requiring an operator to adjust an overwhelming number of configurations on the fly.
With Cassandra, you have to tune many aspects manually, including the JVM, bloom filters, row and key caches, and even memtable thresholds. Not to mention all the operating system and hardware settings.
ScyllaDB has a unified row-based cache system that automatically tunes itself, allowing it to adapt to different data access patterns and workloads. With ScyllaDB, with its inherent low-latency design, there’s no need for external caches, further simplifying the infrastructure.
Cassandra uses several separate competing caches (key cache, row cache, on/off-heap, and Linux OS page cache) that require an operator to analyze and tune — a manual process that will never be able to keep up with users’ dynamic workloads.
ScyllaDB enables you to scale up and out efficiently. Its ability to fully utilize system resources allows ScyllaDB to run on smaller clusters of larger nodes. ScyllaDB’s Raft consensus protocol and Tablets permit scaling out of multiple nodes at a time. Tablets break down token distribution to smaller chunks, and Raft lets the system safely reallocate data across the cluster.
With zero-copy streaming, data is sent over the network in bulk. By transmitting whole SSTables – which are internal database files – transferring data is much more efficient.
When the time comes to scale your Cassandra deployment, you will find that Cassandra can add only one node at a time. Plus, since Cassandra nodes will generally be smaller instances, each addition only brings on a lower amount of storage and compute. As a result, it will take at least 10x longer to expand your cluster. Since expanding your cluster hinders your ability to quickly react to changes, you’re forced to overprovision up-front.
ScyllaDB offers advanced network compression capabilities that go beyond Cassandra’s standard compression methods. These capabilities allow for significant reduction in data size during transmission between ScyllaDB nodes. Users have the ability to fine-tune the compression process by selecting different algorithms and adjusting the trade-off between compression intensity and CPU usage. This flexibility enables cost optimization for Cloud environments with cross-Zone and cross-Region traffic.
ScyllaDB also leverages shared dictionaries to enhance compression efficiency. By maintaining a common set of frequently occurring data patterns, the system can reference these patterns using shorter codes, thereby reducing the overall size of transmitted data.
ScyllaDB adopts open standards and allows you to use your tools of choice. ScyllaDB’s metrics are based on Prometheus for collection, Grafana dashboards for presentation, and Grafana Loki for log aggregation. Both Prometheus and Grafana are Cloud Native Computing Foundation (CNCF) graduated projects. ScyllaDB contributed to Wireshark to add support for CQL and also for its internal RPC for better traceability. ScyllaDB strives to maintain Apache Cassandra compatibility.
Comparing ScyllaDB vs Cassandra, it becomes clear that ScyllaDB provides flexibility, supporting both local and global secondary indexes. ScyllaDB allows for tables to have global secondary indexes across all nodes in a cluster, not just locally on a single node. This is an efficient way to lookup rows because you can find the node hosting the row by hashing the partition key. However, this also means that finding a row using a non-partition key requires a full table scan which is inefficient. That’s why we also support local secondary indexes.
Cassandra and other Cassandra alternatives support only local indexes, which aren’t scalable and aren’t designed for performing full table scans.
ScyllaDB node operations such as streaming and decommission are based on repair algorithms under the hood. This enables you to pause or restart repair operations while going back to the same checkpoint position, saving a lot of time on administrative operations and keeping repair impact as low as possible on your cluster.
Cassandra has no such feature, but offers NodeSync for continuous background repairs. However, DataStax admits, “It is not a race-free lock; there is a possibility of duplicated work.”
ScyllaDB enables you to easily and consistently track and stream table changes. Change data is stored in ScyllaDB as a standard CDC-readable table that developers can query using standard CQL. The data is consistent across the replica set and can provide the previous version of the data changed. Cassandra CDC was introduced with version 4.0; however, ScyllaDB’s CDC surpasses Cassandra’s CDC in terms of ease of use and functionality. It supports capturing the pre- and post-image as well as the delta (specific changes) for the record. Query results are automatically de-duplicated.
Cassandra stores CDC in a special commitlog-like structure on each node. It cannot be read using CQL queries, and requires special applications to be written to aggregate and de-duplicate the data.
ScyllaDB supports Amazon DynamoDB-compatible operations, including a version of DynamoDB Streams, which we call Project Alternator. This provides users more flexibility in data models and query APIs. ScyllaDB allows you to avoid vendor lock-in. You are free to choose among multiple database APIs and at any point change your physical deployment, from on-premises to the cloud vendor of your choice.
Cassandra provides only a CQL-compatible API. It offers no DynamoDB compatibility.
ScyllaDB’s cluster metadata and topology changes are managed using Raft for strong consistency, allowing for safe, concurrent, and fast bootstrapping, and consistent metadata and topology modifications. All topology and metadata operations are internally sequenced, ensuring metadata synchronization across nodes. Changes are driven by a centralized process, ensuring these updates are faster and safer, enabling rapid cluster assembly and concurrent changes for maximum elasticity.
With this feature, dozens of nodes can start concurrently, rapidly assembling a fresh cluster, performing concurrent topology and schema changes, and quickly restarting a node with a different IP address or configuration.
Heat-weighted load balancing efficiently performs rolling node upgrades and reboots by allowing cold nodes to slowly ramp up into requests as its cache is being populated. This aids after restarts or any other time when a cluster loses its cache. Cassandra does not support heat-weighted load balancing.
ScyllaDB can linearly scale-up performance, even on the largest machines available today – such as the AWS i3en.24xlarge, which provides 60TB of local NVMe SSD storage. Custom-built on-premises equipment can scale even larger. On ScyllaDB, compaction and streaming on such a large instance takes exactly the same amount of time as on a small i3en.xlarge.
Cassandra, written in Java and limited by JVM performance, has issues with nodes larger than 2TB. Exceeding this size per node may result in delays in bootstrapping, repairs, compactions, and recovery.
ScyllaDB’s incremental compaction strategy (ICS) enhances Cassandra’s existing Size-tiered Compaction Strategy (STCS) strategy by dividing SStables into increments. ICS greatly reduces the temporary space amplification which is typical of STCS, resulting in more disk space being available for storing user data, eliminating the typical requirement of 50% free space in your drive.
There is no comparable Cassandra feature.
Comcast Xfinity improved user experience and shrank their cluster from 962 nodes with Cassandra to 78 nodes on ScyllaDB, reducing administrative overhead over 90%.

Learn why and how Discord’s persistence team completed their most ambitious migration yet: moving their massive set of trillions of messages from Cassandra to ScyllaDB.

Rakuten’s billion-item catalog 6x better performance while shrinking their cluster 70% moving from Cassandra to ScyllaDB. They also eliminated unpredictable latencies.

Fanatics replaced 55 nodes of Cassandra with just 6 nodes of ScyllaDB. Discover why the brand that powers all NFL, MLB, NBA, and NHL shops switched to ScyllaDB.









In this NoSQL Data Migration Masterclass, Jon Haddad and ScyllaDB field experts shares data migration strategies.



ScyllaDB was designed as a performance-focused replacement for Cassandra, maintaining compatibility with the CQL interface. Your existing applications should work without code changes since ScyllaDB implements the same query language and protocols. However, you’ll need to update your connection configurations to point to the new ScyllaDB endpoints. While most applications work seamlessly, be sure to test thoroughly in a staging environment first.
ScyllaDB’s performance advantage stems from its shard-per-core architecture – which enables each CPU core to operate as an independent unit with its own isolated memory and resources. Unlike Cassandra, which shards per node and achieves relatively low hardware utilization due to JVM limitations, ScyllaDB’s shared-nothing architecture enables true parallel processing and can fully utilize servers of any size, whether they have 100 cores or even 1,000 cores. ScyllaDB automatically schedules reads, writes, and maintenance tasks with different priority levels, reaching up to 100% CPU utilization. This architecture, combined with shard-aware drivers that provide an additional 15-25% performance boost, enables ScyllaDB to deliver 2-5x better throughput with consistently lower latencies while using far fewer nodes than Cassandra.
There are quite a few. To start, ScyllaDB’s Workload Prioritization lets you consolidate multiple workloads on a cluster without impacting the latency of your most performance-sensitive workloads. Moreover, ScyllaDB also provides heat-weighted load balancing that intelligently distributes workloads based on actual usage patterns, and its compaction process is significantly faster – completing 32x quicker than Cassandra. Additionally, ScyllaDB includes a DynamoDB-compatible API. Then there’s Raft, timeout per query, unified row cache, I/O schedulers, tablets, parallel aggregations, and a lot more. We’d be happy to provide a technical demo of the ones that are most interesting for your project and requirements – just contact us.
ScyllaDB’s LWT implementation is fundamentally more efficient than Cassandra’s, requiring only three round trips instead of four. This performance difference is significant enough that users who previously avoided LWTs in Cassandra due to performance issues might find them viable in ScyllaDB.
The CDC implementation is dramatically different between the two systems. While Cassandra implements CDC as a commitlog-like structure requiring off-box combination and deduplication, ScyllaDB uses CDC tables that shadow the base table data on the same node. ScyllaDB’s CDC data is queryable using standard CQL, comes pre-deduplicated, and includes configurable TTL to prevent unbounded growth. It also integrates easily with Kafka through a CDC Source Connector based on Debezium.
While basic compatibility exists, ScyllaDB offers additional optimizations through shard-aware drivers. These drivers maintain backward compatibility with Cassandra but can provide 15-25% better performance when used with ScyllaDB.
There are two main migration strategies: cold and hot migrations. In both cases, you need to backfill ScyllaDB with historical data. Either can be efficiently achieved with the ScyllaDB Migrator.
The ScyllaDB Migrator is a Spark application that migrates data to ScyllaDB. It can:
For more details, see Simplifying Cassandra and DynamoDB Migrations with the ScyllaDB Migrator.
