




The upcoming ScyllaDB Open Source 3.1 release will supplement our global secondary indexing implementation with support for local indexing. This blog post will explain which use cases benefit from local indexes, and which ones would be better served by global ones. We’ll show a few examples of how to use local indexes, and how can they coexist with global indexing. Finally, implementation details will demonstrate some of the performance implications of both types of indexes.
Why Do We Need Indexes?
Indexing is a useful tool that provides more types of queries on your tables. In principle, columns we wish to be queryable should be declared when the table is created, as part of a table’s primary key. Secondary Indexing is a neat way of making other columns queryable, but it comes with a cost of additional storage space and processing power to maintain the secondary index data coherent with the primary index information.
A comprehensive overview of indexing can be found in our blog post on scalable, distributed secondary indexing in ScyllaDB.
Global Indexes
When first designing indexes in ScyllaDB, we decided to diverge from the original Apache Cassandra implementation of indexing — we made ScyllaDB’s indexes global instead of local. The rationale was that, since global indexes are not node-local, they scale well, albeit at the cost of more complicated writes.
Let’s see an example of creating a global index in ScyllaDB.
You can use the following code snippets to build a database of restaurant chain menus. (This example will serve as a reference in the proceeding sections.)
CREATE KEYSPACE restaurant_chain WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
USE restaurant_chain;
CREATE TABLE menus (location text, name text, price float, dish_type text, PRIMARY KEY(location, name));
INSERT INTO menus (location, name, price, dish_type) VALUES ('Reykjavik', 'hakarl', 16, 'cold Icelandic starter');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Reykjavik', 'svid', 21, 'hot Icelandic main dish');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Warsaw', 'sour rye soup', 7, 'Polish soup');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Warsaw', 'sorrel soup', 5, 'Polish soup');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Cracow', 'beef tripe soup', 6, 'Polish soup');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Warsaw', 'pork jelly', 8, 'cold Polish starter');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Ho Chi Minh', 'bun mam', 8, 'Vietnamese soup');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Da Lat', 'banh mi', 5, 'Vietnamese breakfast');
INSERT INTO menus (location, name, price, dish_type) VALUES ('Ho Chi Minh', 'goi cuon', 6, 'Vietnamese hot starter');
Once our table is prepared and populated with data, we can see that for complex analytical purposes, we need to be able to extract all dishes of a specific type, regardless of the location at which they’re served. A query might look like:
SELECT * FROM menus WHERE dish_type = 'Polish soup';
Since dish_type is not a partition key, this query will result in a warning:
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"
The warning lets us know that while this query can be performed, it will involve filtering, and thus can lead to unpredictable performance. To address this problem, we can create a secondary index on the dish_type column to make it queryable:
CREATE INDEX ON menus(dish_type);
With the index created, we can execute the query without further issues and receive all entries that describe a Polish soup, from all locations.
The index is global; underneath it stores base primary keys in a table, where the indexed column acts as a partition key. The key allows the index to scale properly. To avoid pitfalls, schema designers must remember that the same best practices for primary keys apply to secondary indexes columns, for example: avoid creating an index on a low cardinality column. Also, note that indexed data will be stored on a node that serves the partition key token of an indexed table. That node may not necessarily be the same node that stores base table data.
Local Indexes
Let’s consider indexing dish_type again, but this time in a local index. Our use case is being able to ask for all dishes of a given type for one specific location. Let’s start by creating a local index. By creating a local index we instruct the database to use the same partition key columns as base:
CREATE INDEX ON menus((location),dish_type);
Our target query is:
SELECT * FROM menus WHERE location = 'Warsaw' and dish_type = 'Polish soup';
Can we leverage a global index for this purpose? Yes, we can. With our global index, dish_type acts as the partition key of the index table. It also means that, even though our query will contact the node responsible for rows in Warsaw location, indexed data can be found on a node that handles dish_type = 'Polish soup' partition key, possibly a different node, creating the possibility of inter-node communication, which adds to query latency.
Using local indexes makes this query very efficient. The indexing table’s partition key is explicitly the same as base, which ensures that both the extracting keys from the index and fetching the corresponding base rows happens on the same node. That’s much faster than a global query, which may involve fetching rows from other nodes.
Take a look at the pictures below in order to see the subtle difference between global and local indexing in ScyllaDB:
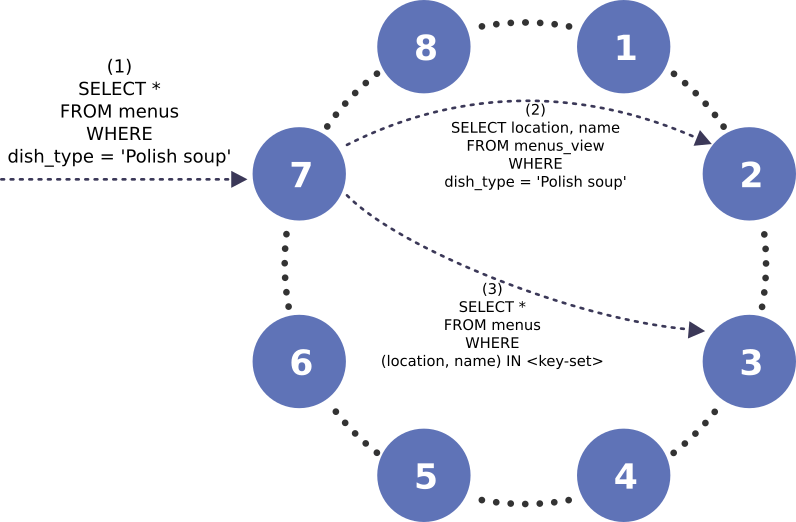
Diagram 1:A global indexing query workflow in ScyllaDB
Diagram 1 above describes global indexing query workflow. User provides query details to the coordinator node (1). An indexing subquery (2) is used to fetch all matching base keys from the materialized view. After that’s done, the coordinator can use the resulting base key set to request appropriate rows from the base table itself (3). Note, partition keys from the base table and underlying materialized view are different, meaning their data is likely to be stored on different nodes.
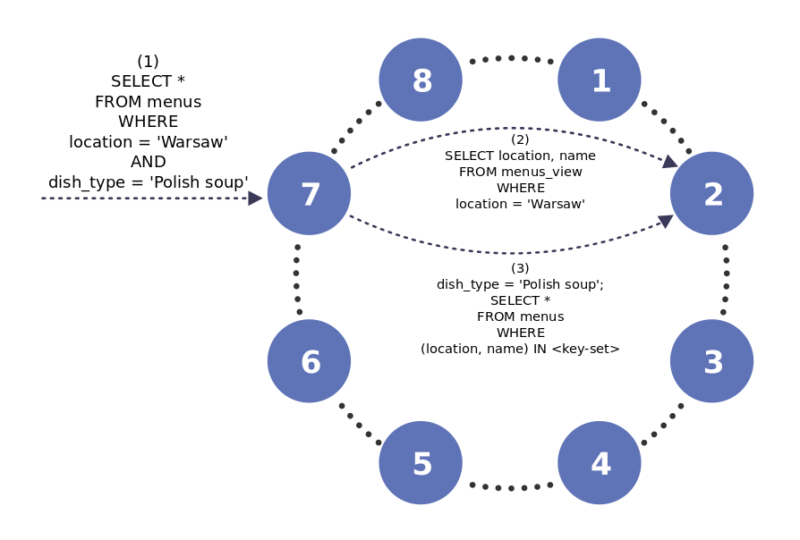
Diagram 2: A local indexing query workflow in ScyllaDB
Diagram 2 describes a local indexing that is similar in principle — each query provided by the user (1) is translated to an indexing subquery and a base table query (2)&(3). However, both the base table and the underlying materialized view have the same partition keys for corresponding rows. That means that their data resides on the same node; there’s no third replica that stores the indexing information.
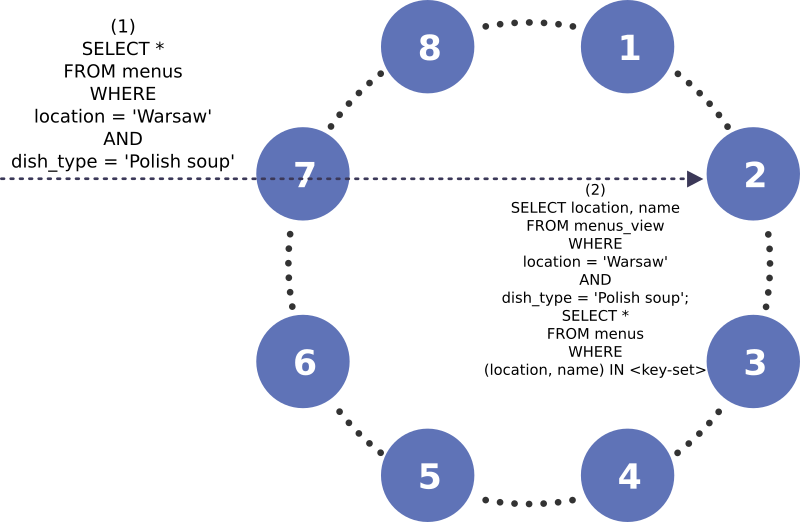
Diagram 3: A query workload that leverages a token-aware load balancing policy.
The previous diagrams, diagrams 1 and 2, illustrated the general case, in which a user contacts an arbitrary node to retrieve data. But, for performance benefits, users often leverage token-aware load balancing policies. As such, they’ll try to contact the node that serves the range of tokens corresponding to the partition key they need. This will reduce the number of network hops and maximize cluster throughput. With this policy enabled, the user will contact the node directly, enabling both subqueries to be local, the one retrieving base from the secondary index and the base query itself.
But wait, didn’t we just create an additional secondary index on the same dish_type column?
Combining Global and Local Indexing
A column can be indexed both locally and globally. The question is, which index will be used to help a query? Currently the rules are simple: if there’s only one index on a column, that index will be picked. When both a local and a global index exist on the same column, the local index will be preferred if the query allows using it. How do we know if a local index is applicable? It’s simple. If partition key restrictions uniquely identify a single partition, we use the local index, which was designed specifically for that purpose.
So, out of these queries:
1) SELECT * FROM menus WHERE dish_type = 'starter';
2) SELECT * FROM menus WHERE location >= 'a' and dish_type = 'starter';
3) SELECT * FROM menus WHERE location = 'Warsaw' and dish_type = 'starter';
Only number 3) is a viable candidate for using a local index. 1) and 2) may cover multiple partitions, and thus cannot be directly backed by a local index. Global indexes can handle 1) just fine, too. 2) has a more complex inequality restriction on the base partition key; it therefore requires additional filtering on top of a global index.
In order to see which kinds of indexes exist in our database, we can query the `indexes` system schema table:
SELECT * FROM system_schema.indexes;
There are two indexes that refer to dish_type column, but one of them has a more complex target, which specifies a partition key equal to the one in the base table.
Local indexing implementation
Like their global counterparts, ScyllaDB’s local indexes are based on materialized views. The subtle difference lies in the primary key; local indexes share the base partition key, ensuring that their data will be colocated with base rows.
For compatibility, global indexes include an additional hidden token column, which ensures that rows are returned in the proper order. For local indexes this kind of trick would be superfluous, since partition keys are already the same as in the base table.
Performance implications
We performed a very simple experiment on a single 3-node cluster. To demonstrate the difference between global and local indexing, using our example schema below, the table was filled with 100,000 rows distributed across 100 partitions and indexed both globally and locally on dish_type column. The column held 10000 distinct values, with 10 rows each. Latency between machines was set to approximately 100ms for a single round trip.
Then, we measured execution time of a query of the form below:
SELECT * FROM menus WHERE location = X and dish_type = Y ALLOW FILTERING;
We compared the following queries:
A) No indexes, which forces the query to fall back to filtering
B) A global index on dish_type column
C) A local index on dish_type column
The table below shows the results for running this query for all configurations (an average of 1000 executions):
| Configuration | Time (s) |
| 1. no indexes | 0.10356 |
| 2. global index | 0.20190 |
| 3. local index | 0.10161 |
As we can see, local indexing leads by a small margin. The resulting set of rows is small, so we knew exactly which node was responsible for a given partition. The results were fetched quickly. Filtering is not far behind, because our query included partition key restrictions, this only one local partition was filtered. Depending on the use case filtering may be even faster even than a local index. In this particular case we were filtering fairly big partitions, which is why local indexing won. Global indexes are left far behind. Why is that? It turned out that the base data and the index data were not collocated. Instead, they resided on different nodes. As a result, the indexed query coordinator was forced to communicate with another node from the cluster and thus paid the price of increased latency. Global indexing is simply not a good fit for the described use case.
Future Plans
Taking advantage of the fact that secondary indexes are implemented on top of materialized views, a notion of generic secondary indexing can be introduced. Such indexes would enable flexible indexes not only with any partition/clustering key columns that are valid for the underlying materialized view, but also with changed ordering, filters, etc.
The current format for a local index is compatible with this futuristic vision:
CREATE INDEX ON menus((location),dish_type);
The above statement can be understood as “create an index in which location will act as partition key, and dish_type will be the first clustering key part.”
Local indexing is a first step towards query execution optimization. Currently, ScyllaDB’s query engine makes the decision whether it should use global or local index for the same column, but this behavior can be extended with more crucial decisions, for example, do not use indexing at all and fall back to filtering, use another index on another column instead, etc.
Summary
Local indexes supplement ScyllaDB’s current indexing implementation with a powerful tool for optimizing partition-local indexed queries. Along with global indexes, materialized views and filtering, local indexes allow executing queries in a more flexible way while minimizing the impact on performance.




