




2023 Update: For the latest on Discord’s journey with ScyllaDB, see How Discord Migrated Trillions of Messages from Cassandra to ScyllaDB and the associated Discord ScyllaDB blog.
Mark Smith, Director of Engineering at Discord, manages the infrastructure team for the company that powers community across the gaming industry. Last May, when the company turned three years old, Discord boasted a user base of 130 million registered users. That compared to 45 million the year before, marking a three-fold increase in users in a single year. By the time of this writing, in March 2019, the provider of free voice and text chat focused on Internet gaming had grown its user base to over 250 million users worldwide, and thus is well on its way towards doubling in size in a year.
Discord has risen to a global website rank of 126 on Alexa, and on Similarweb it is ranked the 100th most popular site in the world. Every day somewhere around fourteen million people use Discord to send over three hundred million messages.
Which means that scalability and uptime are not optional.
Productionization
Mark did not begin by talking about ScyllaDB, nor about Discord. Instead, Mark harkened back to his experience with Apache Kafka at Dropbox. There, he was part of a team of four engineers that launched the technology, where it scaled to 15 million messages per second on 100 brokers organized into multiple clusters. He said it took about a year to “productionize.”
Mark’s definition of the term was slightly different than what one would find in a dictionary. To him it was more than just getting into production. “This is sort of the road from running it, turning it on, to the point where you feel comfortable running it. Where you can recover from outages. Where you can deal with whatever problems arise. Where you can train people. And all of those good things.” And this process took a year.
“It turns out Kafka is actually kind of hard. And this is a story we see repeated in the open source world in a lot of the projects that we use like Cassandra, MongoDB, etc. It’s very easy to download and start them. It’s a lot harder to run them at scale.”
Taking Kafka for further example, Mark noted there are different Kafka distributions available, from open source to proprietary offerings. Plus, configuration is often a black art. While you can study how Kafka is used in different environments, those configurations are often dependent on unique characteristics of hardware and other use case factors particular to that installation. There are over 150 tunables for a Kafka broker. The permutations of which lead to huge complexity and are incredibly hard.
Beyond that is the issue of monitoring. “If you Google ‘How to monitor Kafka,’ they say ‘Here is how you use JMX.’ That just gives you stats. That gives you a lot of stats. That doesn’t actually tell you how to monitor a system. That doesn’t tell you what matters.”
“When you are paged at 3 AM, and you have ten thousand metrics to look through…? What matters? It’s really hard to tell.”
“This also makes getting community help very difficult. Because you have to spend the first hour of every conversation: ‘Here’s my config file. Here’s my hardware. Here’s my use case. Here’s my load. Here’s how everything fits together,’ before they can get to the point of understanding what you are doing to try to help you out.”
“We followed the road that most of you have probably followed at one time or another. You start by being very reactive with incidents. You write post-mortems. You do root cause analysis. You do all those sorts of things to understand what has gone wrong in your cluster. And then you make betterments out of that. You make playbooks. You improve your monitoring. You create dashboards. You learn about stuff that you don’t have today that you need to have.
“And then over time, hopefully, you move to a more proactive story. With chaos engineering, disaster readiness testing [DRT]. Stuff like that. But it’s never easy. And if you’ve deployed, in this case, Kafka, or Cassandra, or Mongo, or any of these systems at scale, you’ve been through this story before. It’s never as easy as we’d hope.”
Opinionated Systems
Mark took a small digression to talk about flight lessons. He compared the complexity of the cockpit of a 747, and the training needed for a multi-person crew, and how we are still able to end up with a very safe method of transportation. Standard Operating Procedures (SOPs), Pilot’s Operating Handbooks (POHs). Checklists, checklists, checklists.
“It’s regimented, and it’s fully documented and trained. You know exactly what you’re doing. And you’re following the list.”
Such systems are designed by “competent stewards of the system who understand it deeply.” Whereas in aviation you have the FAA and NTSB, you don’t have the same regulating forces in open source. It’s up to the community and the users.
“The software is good. But the ecosystem around it. How you run it in production. It’s Wild West. You can ask LinkedIn what they do. And they will help you out and show you what’s been successful for them. You can talk to Twitter. You can talk to your friends at wherever and you will get a hundred stories from a hundred people. But that’s not really going to help you in running your system.”
ScyllaDB at Discord
When you launch the app, you land in the Activity Tab. It includes news, a quick launcher for your favorite games, a list of what your friends are currently playing (or recently played), plus a section for your friends’ listening parties, streams and Xbox status. “We use ScyllaDB to power this and we trust it to be the data source for the homepage of Discord.”
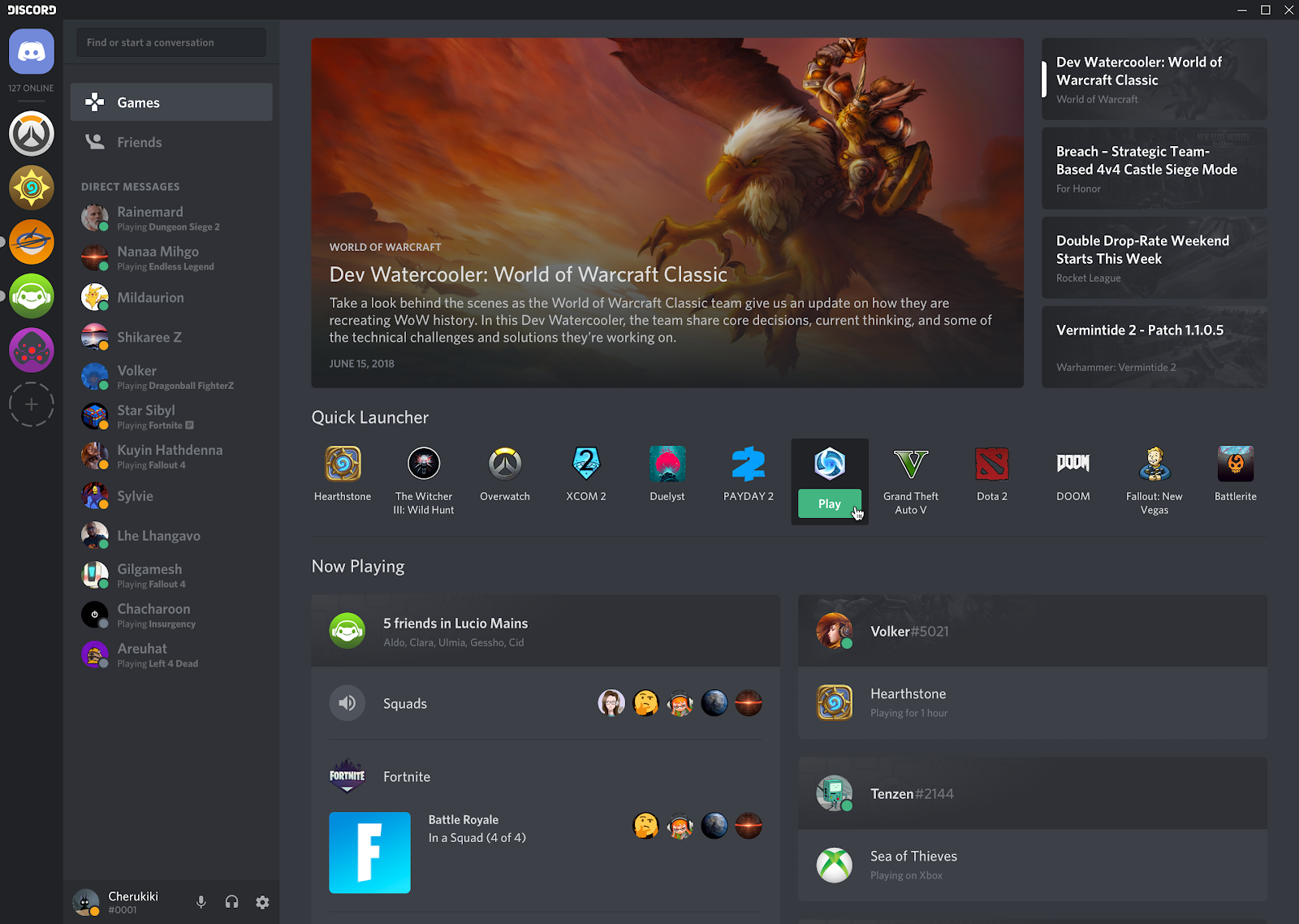
Mark talked about the surety that comes with ScyllaDB’s autoconfiguration. “ScyllaDB just says, ‘You know what? This is our system. We’ve spent years building this and understanding it. Do it like this. Here’s how you install it. Here’s how you configure it.’”
“In fact, you don’t choose how to configure ScyllaDB for the most part. You run some tools. They write out config files. Yes, you can go in after the fact and change it, if you wish, but they give you the baseline of how to do it. And for monitoring, they are very opinionated. Here’s your Docker image of Prometheus. Here’s your image of Grafana. Here are your dashboards. Use these.”
Such opinionated systems are, to Mark, a critical advantage. “If you go out into the community and you ask for help with ScyllaDB, everybody knows what you’re going to be looking at. They know what graphs are important. People who are good stewards of the system have already figured out what is important and how to present it. So you don’t actually have a lot of decisions to make when it comes to deploying ScyllaDB.”
“In our experience at Discord we found this to be true. Setup was trivial. The operations have been easy and well-understood. We also have a background in Cassandra which has helped in some of that.”
He did add a caution: “We have had a production incident,” with the acknowledgement that systems will always fail. In Discord’s case it was a capacity issue. However, because of its strongly-opinionated methods, the ScyllaDB team was able to immediately pinpoint the issue. The solution was simply to expand the cluster.
“The multiplicative factor of having shared knowledge, shared language, shared ability to understand what these things look like and how they work is very powerful for your business. It’s very powerful for running these systems at scale.”
To Mark, it is okay, even preferable, to have strong opinions. “It’s okay to say, ‘This is how you run something. This is how you do something.’”
This advice applied beyond open source vendors to the services offered by organizations themselves. “This applies to each of us too, in the things that we are delivering to our customers. There is a cost to infinite configuration. There is a cost to the mental overhead of having to make all these choices. Of understanding how to put stuff together. Your customers may ask for it. They may say, ‘Give us all these knobs and whistles and buttons.’ But it is up to you to figure out is that actually the right thing for them? Am I actually adding value to their use case and what they’re doing.”
In conclusion, Mark offered a pretty definitive assessment: “ScyllaDB has exemplified this sort of principle and it has ended up saving Discord time, money and downtime.”









