




When things go wrong with your database solution, a strong understanding of your system’s architecture, capabilities, and limitations will prepare you for making things right as quickly as possible. Regardless of throughput, 99th percentile latency, or any other metric observed during stable operations, what happens during periods of instability can make or break SLAs. All the IOPS in the world won’t save you from misconfigurations, suboptimal architecture, or unforeseen complexities.
Consider this service degradation at PagerDuty in September 2017. In their thorough root cause analysis, PagerDuty revealed a number of operational concerns in Apache Cassandra that we at ScyllaDB strive to address in ScyllaDB. From this analysis, we have seen a number of issues that are mitigated through ScyllaDB’s architecture versus that of Apache Cassandra. We’ll review how not running on the JVM and techniques like workload conditioning and Heat Weighted Load Balancing provide ScyllaDB with resiliency in the face of cluster instability.
Degraded State
With distributed systems, it’s best to concern yourself less with what you see when all the lights are green and focus on what you see when the lights are orange and red. As stated in the service degradation report by PagerDuty, things started going awry during the replacement of a failed virtual machine in the cluster (Orange Lights): “The procedure used to replace the failed node triggered a chain reaction of load on other nodes in the cluster.” The report continued to say, “Specifically, the node was moved to a new location in the Cassandra token ring after being added to the cluster, rather than being inserted into its desired location initially” (Red Lights).
There may have been ways to mitigate this problem in the configuration via replace_address_first_boot. However, Apache Cassandra is meant to gracefully handle cluster mutations in particular token range movements that trigger token range streaming operations among the nodes in the cluster. Streaming token ranges is a costly operation that competes for resources with other simultaneously executed operations like reads and writes. In our blog posts on workload conditioning 1 2 and userspace I/O scheduling 3 4 , we reviewed some of the ways in which ScyllaDB is able to dynamically allocate resources to different workloads by leveraging its ability to directly control scheduling operations in userspace and by controlling background task CPU utilization. In short, ScyllaDB is able to finely control I/O requests amongst different workloads (read/write/compaction/streaming/etc) in its own scheduler (Figure 1) and control the maximum quota of CPU used by background tasks like compactions and memtable flushes when the system is saturated (Figure 2). These two capabilities ensure that critical tasks are not starved of resources.
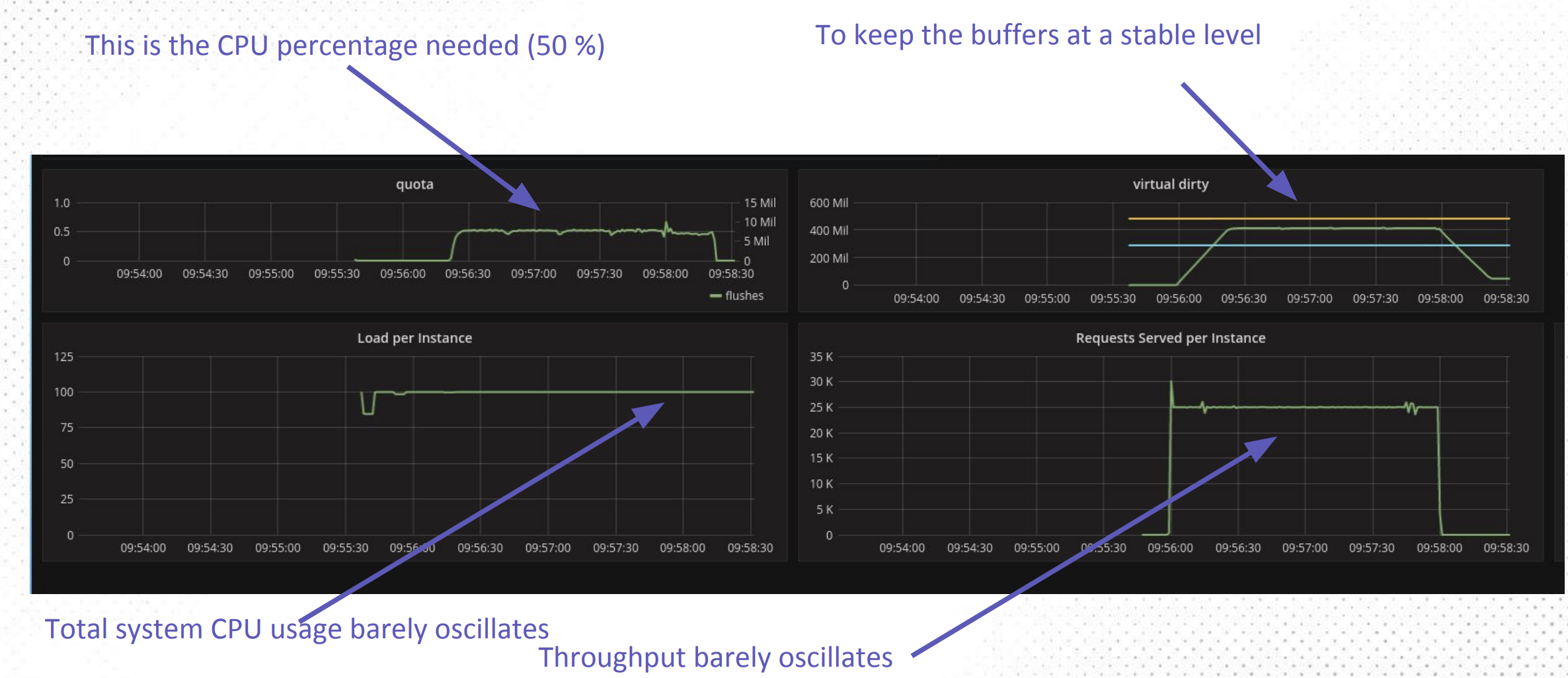
Figure 1. Workload Conditioning peak reduction, transaction stabilization. Delta between memory and disk speed.

Figure 2. Memtable flush and compactions do not affect requests served due to CPU workload conditioning.
“We made attempts to isolate the hosts from production traffic so that they could devote their computing power to completing the streaming operations. Specifically, we tried to make sure the struggling nodes were not also acting as coordinators for the cluster.” – PagerDuty
Isolating nodes client side from being used as coordinator nodes can be tricky business. Another approach is to build isolations into ScyllaDB itself. In this detailed post on Heat Weighted Load Balancing, we described an approach to alleviating latency spikes from cold cache nodes after being rebooted (Figure 3). When a node reboots, it loses its memory resident cache and returns to the cluster with a “cold cache”, i.e. everything that had been in memory is no longer there and all data retrievals will execute reads from the disk. Heat weighted load balancing will recognize this by shedding reads to other nodes in the cluster and slowly begin serving reads itself, thereby warming its own cache.

Figure 3. Latency spike reduction before and after application of Heat Weighted Load Balancing
Garbage Collection in the JVM
“Another theory emerged, based on metrics in our dashboards, that the nodes were experiencing an above-normal number of garbage collections in the Java Virtual Machine. This would likely indicate memory pressure was too high, leading to thrash as the JVM continually tried to preserve heap size. We restarted one of the problem nodes with increased heap size. This involves the node rejoining the cluster after restarting, which is itself a time-consuming operation. The time spent in this change/restart/measure cycle was a significant factor in how long the issue took to resolve.” – PagerDuty
While Apache Cassandra is written in Java and inherits all the advantages and disadvantages of the JVM, ScyllaDB is written in C++. Most notably, even when the JVM is configured to mitigate garbage collection related issues it can still be affected by them. Consider that statically modifying garbage collection settings for any single workload will not help you when your workload is in flux – which is exactly what a failed node will do to your cluster. Much has been written about garbage collection in the JVM, needless to say, garbage collection is a constant consideration in JVM deployments. The general garbage collection issue is magnified in applications that make extensive use of large swaths of memory, such as memory hungry databases.

By not being beholden to the JVM, ScyllaDB escapes that entire class of problem. ScyllaDB does not use the JVM. ScyllaDB is built on top of an asynchronous thread per core, shared nothing framework called Seastar. The Dynamo distribution model allows Apache Cassandra oriented systems to scale out. The Seastar framework allows ScyllaDB to scale up. ScyllaDB scales linearly with additional cores and offers architects an additional scaling dimension to an only out approach. With I/O and CPU workload conditioning, ScyllaDB can dynamically adjust itself as workloads change due to things like unicorn-like hockey stick growth curves or a batch of defective SSD’s knocking a server or two offline.

An Enterprise Relationship
“Each change we made required a cycle of applying the change, waiting while we watched for the intended effects, determining if the effects were indeed occurring, and re-evaluating our options.” – PagerDuty
Today’s systems architectures are incredibly complex and no one knows your architecture better than you do. Nevertheless, having highly trained professionals on PagerDuty and ready to spring into action at a moment’s notice does not guarantee optimal resolution when dealing with varied and complex systems issues for software you didn’t write.
Software vendors, particularly software authors, have seen everything there is to be seen when it comes to their software. Numerous customer deployments in a myriad of production scenarios all but guarantee that the author will have the best, most relevant knowledge on how to address any particular issue. When you engage in an enterprise relationship with professional, responsive authors with a solid reputation you’ll get a response that will hone in on an optimal solution without wasting critical time. And if you’ve encountered a bug, you’ll have a direct line to core engineers. Don’t take it from me, consider one of our customer successes, mParticle 5 6.

“Since the cluster in question deals with only in-flight notification data and does not act as a long-term data store, it was decided it would be feasible to ‘flip’ over to a new cluster all at once as we wouldn’t need to migrate a large dataset as part of the operation.” – PagerDuty
PagerDuty’s analysis outlines a 30+ hour timeline from initial failure to eventual incident resolution. Due to the ephemeral nature of the data in this particular use case, they were able to escape potential unknown lingering instabilities by cutting over to a brand new cluster. They were lucky. What if they needed to preserve hundreds of terabytes of data? In 2016 and 2017 we’ve seen major airlines suffer 24 hours or longer system outages culminating in tens of millions of dollars in lost earnings. Beyond the financial repercussions, outages of this nature can inflict long-lasting damage to your brand. Getting your operations back to the normal state as quickly as possible is more important than it has ever been.
Knowing what your architecture is capable of in failure scenarios will not only allow you to better manage SLA’s but also inform your recovery plan. Given an amount of data per node, it should be possible to calculate how long it may take to stream data and return your cluster to a normal state.
In Summary
The technical blogosphere is replete with tales of triumph – 1 million TPS on a cluster of Arduinos! Transcontinental sub-millisecond latency using… lasers mounted on eagles! Hey, we’ve put a few of those out ourselves*. Something I’ve always appreciated above these platitudes is the detailed root cause analyses when things go sideways. When major service providers delve into the varied reasons for failures, we all stand to learn from their hard earned experience. In that vein, I’d like to thank PagerDuty for their laudable transparency. Every system suffers failure. From the smallest WordPress deployment to the largest multi-datacenter mission-critical application – failure is a reality we all live with. Sharing these challenges allows us to make informed decisions in our own environments. ScyllaDB’s Seastar framework, disk I/O and CPU, workload conditioning, heat weighted load balancing, and top-shelf customer support are major differentiators from Apache Cassandra and other database solutions. As we’ve seen, ScyllaDB smartly provisions resources so you get the most IOPS out of your deployment which can make the crucial difference when meeting your SLA’s.
*No eagles were harmed in the writing of any of our blog posts.
[1] https://www.scylladb.com/2016/12/15/sswc-part1/
[2] https://www.scylladb.com/2017/09/18/scylla-2-0-workload-conditioning/
[3] https://www.scylladb.com/2016/04/14/io-scheduler-1/
[4] https://www.scylladb.com/2016/04/29/io-scheduler-2/
[5] https://www.scylladb.com/2017/08/31/mparticle-chooses-scylla/
[6] https://www.slideshare.net/ScyllaDB/mparticles-journey-to-scylla-from-cassandra

