




Rakuten is a Japanese online shopping powerhouse, responsible for $15 billion in annual sales. It is one of the most frequented sites in the world. To keep it operational throughout the year, and especially during peak shopping seasons, Rakuten relies on a team of expert developers and architects.
Hitesh Shah is a Senior Engineering Manager on the Rakuten catalog platform team. He has spent over a half decade as a passionate engineer at the heart of their distributed systems infrastructure, pushing the envelope of technology. He spent an hour with the ScyllaDB community in a webinar describing how Rakuten eliminated the volatile latencies that can plague online shopping experiences.
Rakuten had been able to achieve a certain level of scale with Apache Cassandra, yet ran into challenges. Instead they turned to ScyllaDB. Hitesh wanted to share their experience in migration, as well as their post-migration KPI results and lessons learned.
Rakuten Catalog Platform
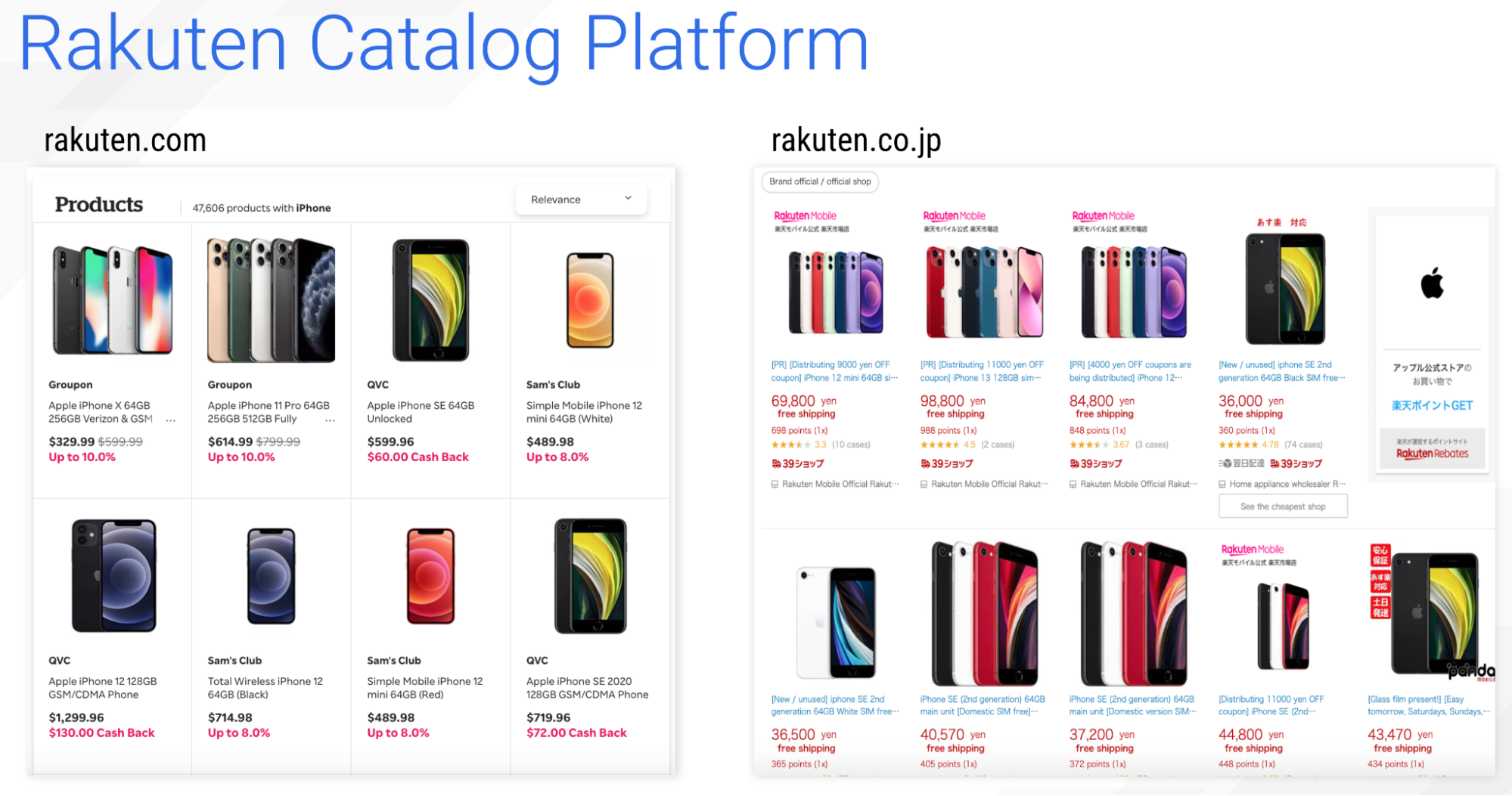
Rakuten built its brand on not just providing a great shopping experience across thousands of stores, but also in providing cash back earnings and perks to its loyal customers. The system that powers this experience is known as the Rakuten Catalog Platform.
Rakuten aggregates the product availability from all of their thousands of partner vendors and merchants, such as Groupon, Sam’s Club, or JCPenney. All of these results are managed in the same worldwide data store, so whether you are shopping at the US-based rakuten.com, or the Japanese-based rakuten.co.jp, it’s the same common backend.
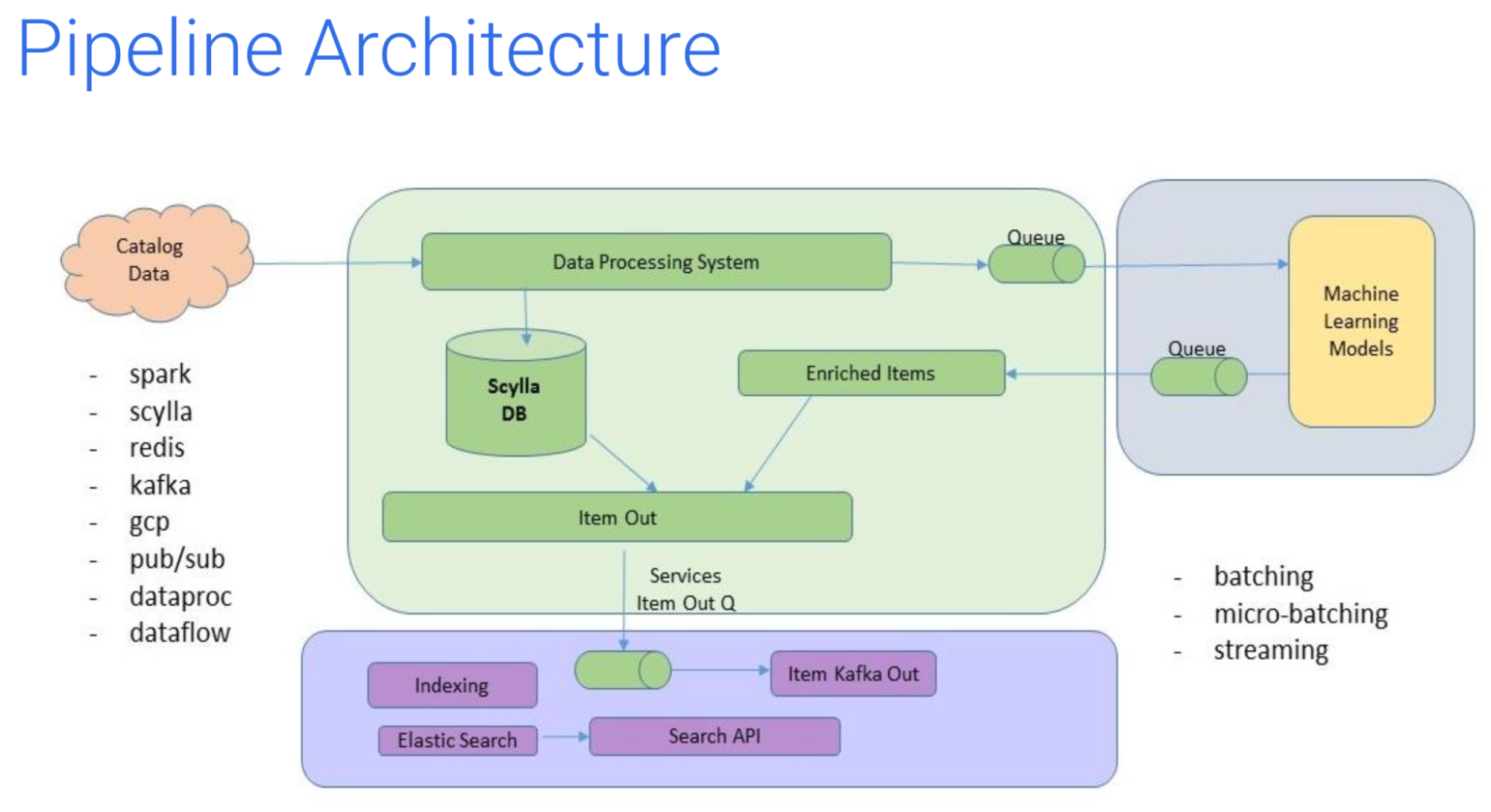
Here is how they architected that back end. Catalog data is brought into the data processing system from all of their partner vendors and merchants. In this data processing system, all of the data is transformed into a single common format, normalizing it and cleaning it up for consumption. From there, it is queued to feed their machine learning (ML) models and to feed ScyllaDB as their central database.
The data in ScyllaDB, as well as the enriched data returned from ML, then goes into a Kafka queue which propagates to Elasticsearch.
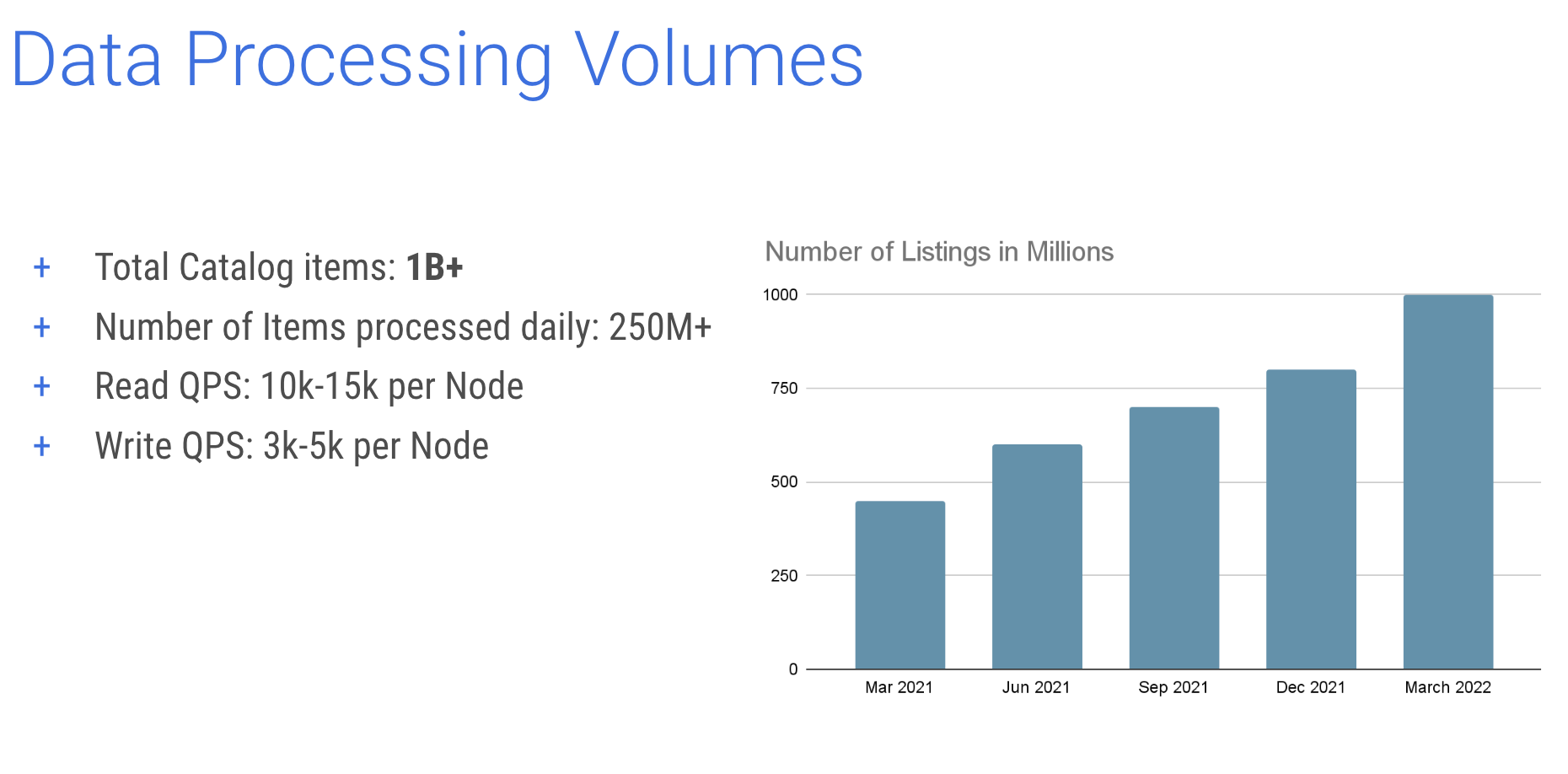
Back in 2021, Rakuten’s catalog was approaching 450 million items. Within a year they had doubled to more than a billion catalog items. On a daily basis, they are processing 250 million items. Query volume per node ranges from about 10,000 to 15,000 writes per second and 3,000 – 5,000 writes per second per node.
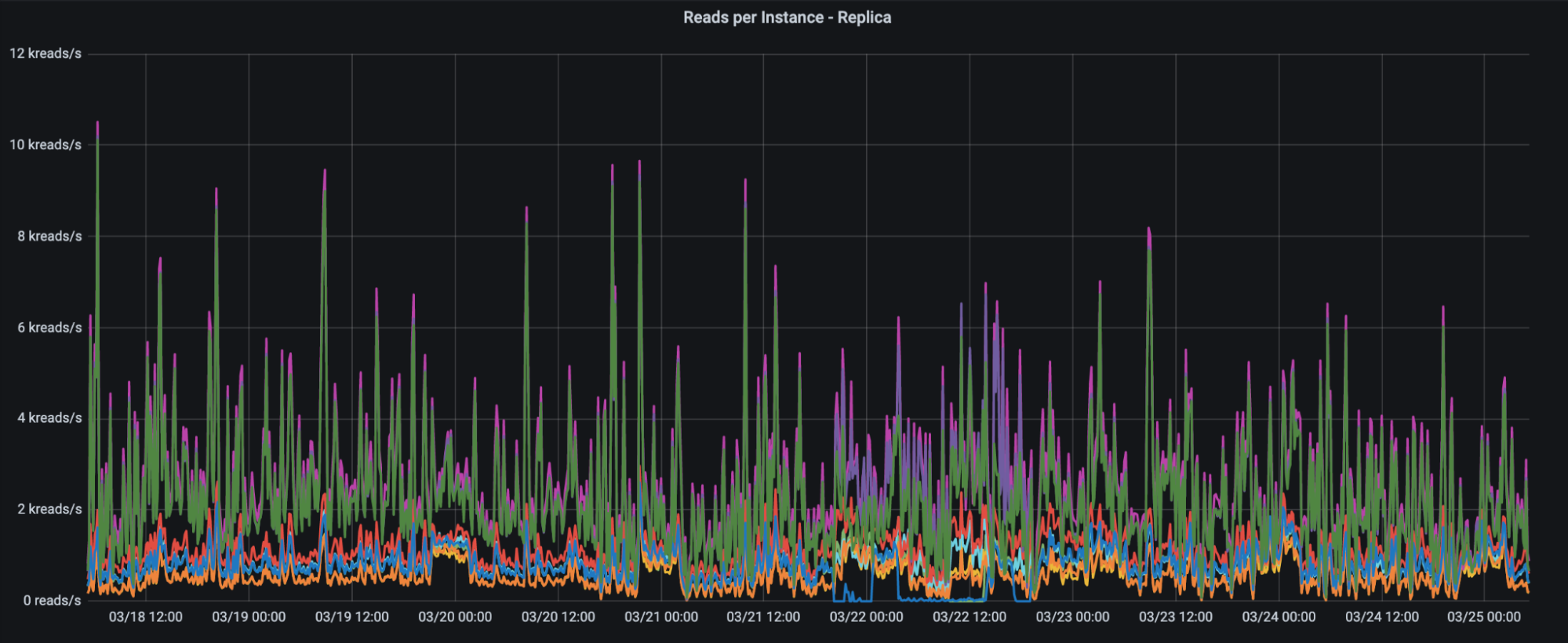
ScyllaDB Monitoring Stack provides Rakuten with Grafana charts showing queries per second. Note how Rakuten’s operations per second can be very bursty in nature.
Product Catalog Design
“Let’s say somebody has to start a product catalog platform from scratch,” Hitesh hypothesized, “then how will they go about it? What are the technologies to consider?” He then provided a list of key features or attributes for designing a product catalog system:
- Near real-time price updates
- Near real-time availability updates
- Discovering purchasing trends — analytics
- Discovering shopper preferences — analytics
- Large volume of data
- Fast growing catalog — 100s of millions of catalog items
- Catalog enrichment support
- Low latency requirements
A pipeline of near real-time price and product availability updates is crucial. “The merchants or retailers are constantly changing the price. Also, items are getting sold out; they run out of stock. Particularly around Black Friday or Cyber Monday, prices are constantly changing based on the deals available. In those situations, it becomes very, very important for the platform to propagate the price updates from the retailer to the e-commerce website as soon as possible or in a real-time manner.”
If Rakuten could not keep up with that rate of data change over a short period of time, retail vendors may end up paying the price, such as having to honor prices that they thought had already changed or discounts that should have already expired. Similarly if items are no longer available and orders cannot be fulfilled it can create negative customer experiences, wasting the customer’s time as well as the retailer’s dealing with reversals of charges and canceling orders that should not have been accepted in the first place. All of this drives the requirement for low-latency lookups.
Analytics also need to be built in to discover aggregate purchasing trends for hot products (or, conversely, to find those that are not providing quick inventory turns), as well as to understand individual shopper preferences.
When Rakuten first started building their product catalog platform, they began with Apache Cassandra. Hitesh notes, “We ended up selecting Cassandra because that was the most natural choice for us.” It was horizontally scalable, offered automatic data replication and automatic sharding, plus was designed for fast writes. As well, “Cassandra is more of a column family store and that definitely made a lot of sense for us because we have these use cases around enriching the subset of the data… you can just separate the subset of the data without impacting the operations on the other columns in the same row. Speed of deployment is very easy with Cassandra. You spin up a new node and data starts replicating and traffic will get started.”
However, getting started is not the same thing as performance over time. Within a few years of corporate and data growth Cassandra’s limits were clearly showing. Inconsistent performance. Volatile latencies.
“Let’s take a particular select statement or select query. Cassandra is returning the results in maybe in 60 or 70 milliseconds.” Hitesh proposed as an example. “Then the same query will take 120, 130 milliseconds at a different time on the same day. Or it might even end up taking 140, 150, 160 milliseconds on a different day. Basically, the latencies were all over the place with Cassandra.”
The Java-based code, with stop-the-world pauses caused by garbage collection, client-side connection timeouts and out-of-memory errors, made it difficult to make service commitments to partners as well as internal customers. While every distributed system will only be as fast as the slowest performing node, Cassandra made this phenomenon all-too-apparent. The unpredictable behavior of Apache Cassandra combined with the need for a lot of manual intervention drove Hitesh and his team at Rakuten to consider an alternate solution: ScyllaDB.
Moving to ScyllaDB
The fact that ScyllaDB implemented the Cassandra CQL interface and had the same horizontal scalability made it a natural fit. But since ScyllaDB was written in C++ it would not be subject to the same foibles. Rakuten believed ScyllaDB would be five to six times faster in terms of performance right out of the box. And because of this performance gain, it would have a better total cost of ownership (TCO) and provide a better return on investment (ROI) even on the exact same hardware.
“One of the other things we observed with ScyllaDB,” Hitesh noted, “performance was very, very consistent.” This was true at any time, day or night, which provided huge peace of mind. Hitesh noted ScyllaDB gets such performance by being built on the Seastar framework, which provides a shard-per-core, shared-nothing architecture. “This reduces the kernel-level contention substantially and improves the parallelism much, much, much better.
ScyllaDB’s shard-aware drivers also provided a further source of improved performance. These deliver queries directly to the CPU assigned to a certain data partition, meaning fewer internal hops and redirects within the ScyllaDB server cluster, and thus, lower latencies.
Another ScyllaDB-specific capability that Rakuten looked to for cost savings was Incremental Compaction Strategy (ICS). It allows greater disk utility than standard Cassandra compaction strategies, meaning the same amount of total data would require less hardware. For traditional compaction strategies, users need to set aside half of their total storage for compaction activities. With ICS, Rakuten would be able to use 85% or more of their total storage for data, thus getting far better hardware utilization.
A final key for Rakuten was enterprise-level support. While ScyllaDB offers a fully-functional open source offering, Rakuten wanted the surety that came with 24/7 support, including a private slack channel to directly work with ScyllaDB software engineers.
Rakuten’s KPI Improvements
After moving to ScyllaDB, the team at Rakuten found their product feed ingestion rate improved 30% – 35%. In addition, their second use case — sending enriched data to their partners — saw between 2.5 to 5 times improvement in feed publishing times. They were now basically doing real-time updates.
Plus, because of the performance and storage gains with ScyllaDB, Rakuten was able to condense a cluster of 21 Cassandra nodes to only 6 ScyllaDB nodes, providing far easier cluster administration and lower TCO due to hardware savings.
Watch the video (above) for more details of their ScyllaDB migration, as well as lessons learned in production.








