





“We found having about 50% free disk space is a good rule of thumb.”
2025 update: For a more recent take on compaction, see Balancing Compaction Principles and Practices
You’ve heard this advice since you first laid hands on Cassandra. And over time, we’ve all gotten used to it. Yet it still sounds awful, right? It’s the sad reality for all Size-Tiered compaction strategy (STCS) users, even those on DataStax Enterprise or ScyllaDB. You need to leave at least half of the disk free so that you’re guaranteed your cluster won’t run out of disk space when you need to run compactions.
That translates into burning tons of money because tons of disk space are set aside due to this limitation. Let’s do some math: Suppose you have a cluster with 1000 nodes, where each has a 1 TB disk. If you need to keep each of those nodes under 50% of total disk usage, it means that at least 500TB will be wasted in the end. It’s a terrible limitation which increases storage cost by a factor of 2.
That’s why we came up with a new compaction approach, named Incremental Compaction, that solves this problem by considerably reducing the aforementioned space overhead with a hybrid technique that combines properties from both Size-Tiered and Leveled compaction strategies.
Incremental Compaction Strategy (ICS) was created to take full advantage of this new compaction approach and it is exclusively available in newer ScyllaDB Enterprise releases (2019.1.4 and above).
Space overhead in Size-Tiered Compaction Strategy (STCS)
A compaction that runs on behalf of a table that uses STCS potentially has a 100% space overhead. It means that compaction may temporarily use disk space which can be up to the total size of all input SSTables. That’s because compaction, as-is, cannot release disk space for any of the input data until the whole operation is finished, and it needs additional space for storing all the output data, which can be as large as the input data.

Let’s say that a user is provided with a 1TB disk and the size of its table using STCS is roughly 0.5T. Compacting all SSTables in that aforementioned table together via nodetool compact, for example, could temporarily increase disk usage by ~0.5T so as to store the output data, potentially causing ScyllaDB to run out of disk space.
That scenario is not triggered only with nodetool compact, it could also happen when compacting SSTables in the largest size-tiers, an automatic process that happens occasionally. So that’s why keeping each node under 50% disk usage is a major concern for all users of this compaction strategy.
To further understand how STCS works with regards to space amplification, we’d recommend you to take a look at this blog post.
Incremental compaction as a solution for temporary space overhead in STCS
We fixed the temporary space overhead on STCS by applying the incremental compaction approach to it, which resulted in the creation of Incremental Compaction Strategy (ICS). The compacted SSTables, that become increasingly larger over time with STCS, are replaced with sorted runs of SSTable fragments, together called “SSTable runs” – which is a concept borrowed from Leveled Compaction Strategy (LCS).
Each fragment is a roughly fixed size (aligned to partition boundaries) SSTable and it holds a unique range of keys, a portion of the whole SSTable run. Note that as the SSTable-runs in ICS hold exactly the same data as the corresponding SSTables created by STCS, they become increasingly longer over time (holding more fragments), in the same way that SSTables grow in size with STCS, yet the ICS SSTable fragments’ size remains the same.
For example, when compacting two SSTables (or SSTable runs) holding 7GB each: instead of writing up to 14GB into a single SSTable file, we’ll break the output SSTable into a run of 14 x 1GB fragments (fragment size is 1GB by default).
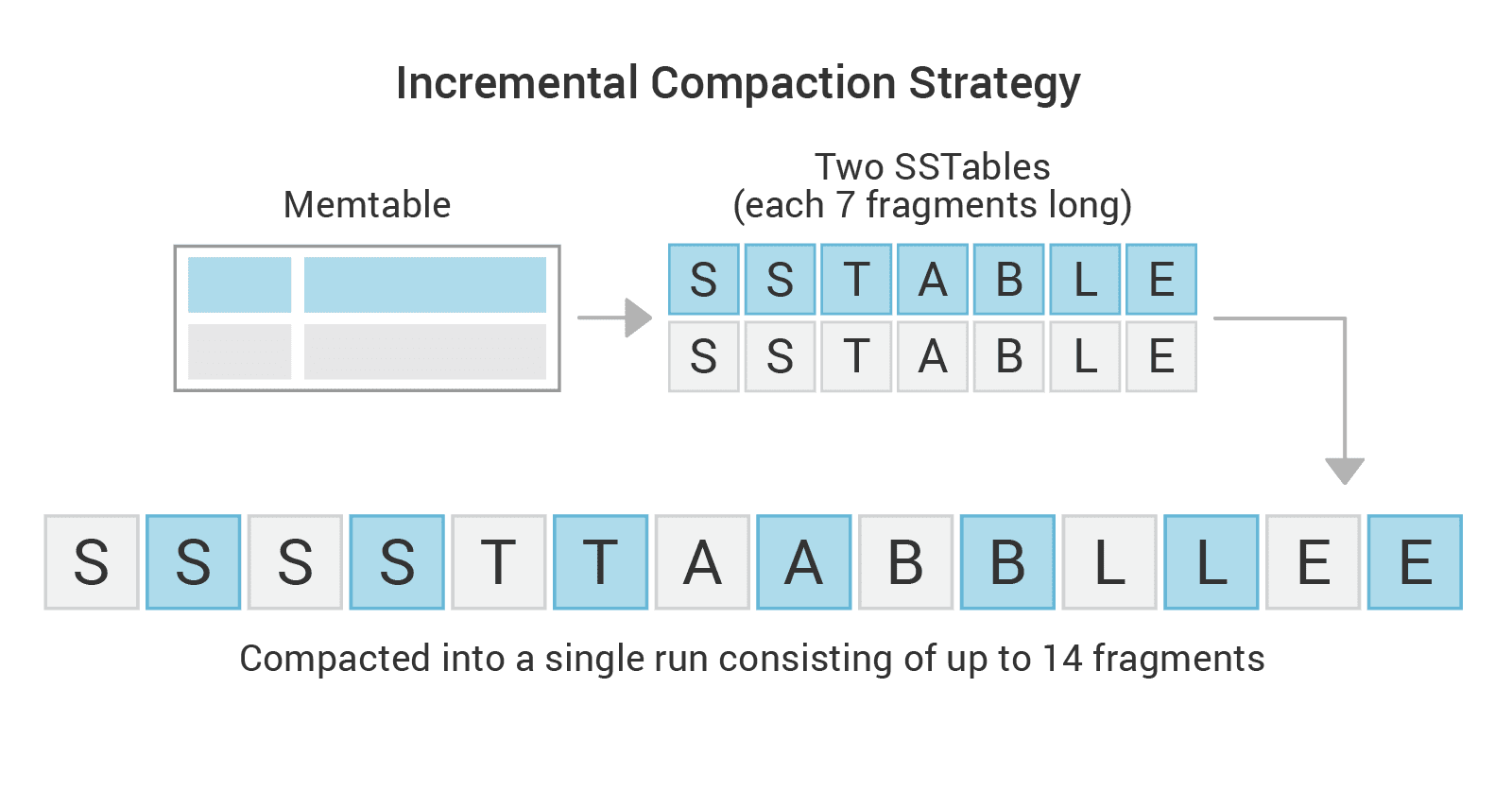
It can be seen that this new compaction approach takes runs as input and consequently outputs a new run, all of which are composed of one or more fragments. Also, the compaction procedure is modified to release an input fragment as soon as all of its data is safe in a new output fragment.
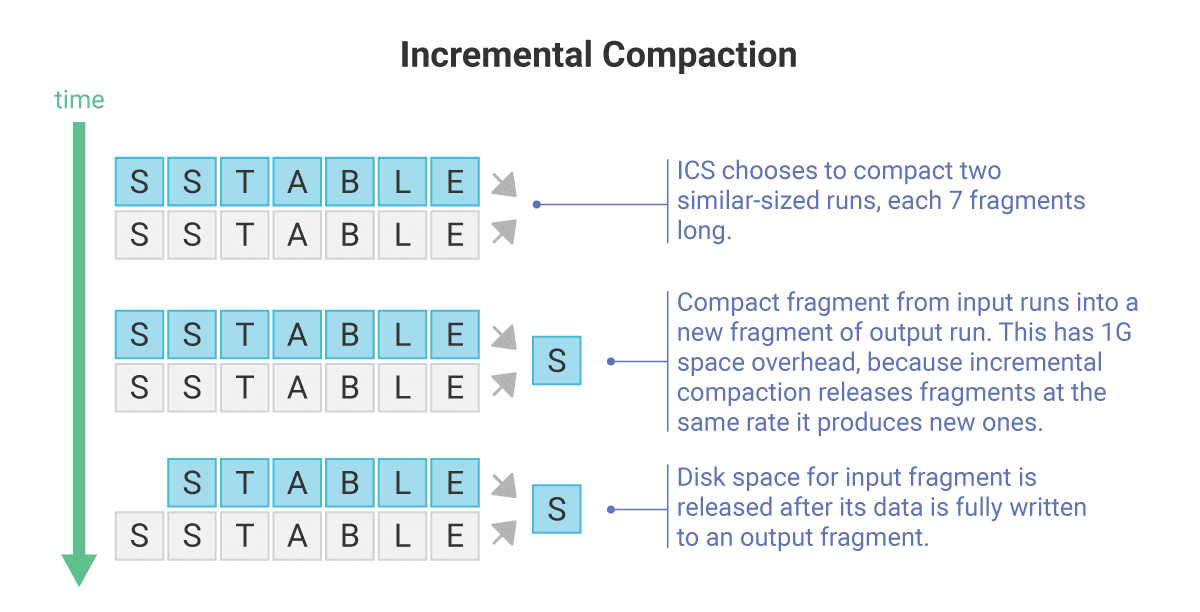
For example, when compacting 2 SSTables together, each 100GB in size, the worst-case temporary space requirement with STCS would be 200G. ICS, on the other hand, would have a worst-case requirement of roughly 2G (with the default fragment size of 1G) for exactly the same scenario. That’s because with the incremental compaction approach, those 2 SSTables would be actually 2 SSTable runs, each 100 fragments long, making it possible to roughly release 1 input SSTable fragment for each new output SSTable fragment, both of which are 1GB in size.
Given that ICS inherits the size-tiered nature from STCS, it will provide the same low write amplification as STCS. ICS also has the same read amplification as STCS even though the number of SSTables in a table is increased, compared to STCS. That’s because a SSTable run is composed of non-overlapping fragments, so we’re able to filter out all SSTables that don’t overlap with a given partition range in logarithmic complexity (using interval trees), not requiring any additional disk I/O. So read and write performance-wise, STCS and ICS are essentially the same. ICS has the same relatively-high space amplification as STCS due to accumulation of data within tiers if there are overwrites or fine-grain deletes in the workload, but when it comes to temporary space requirement, ICS doesn’t suffer from the same problem as STCS at all. That makes ICS far more efficient than STCS space wise, allowing its users to further utilize the disk.
- Note: ICS may have better read performance if there are overwrites or fine-grain deletes in the workload, because compaction output can be used much earlier for data queries due to the incremental approach.
Watch this ScyllaDB webinar to further understand how this new compaction approach works!
How much can I further utilize the disk with incremental compaction?
In order to know how much further you can utilize the disk, it’s important to first understand how the temporary space requirement works in practice for incremental compaction.
Given that incremental compaction can release fragments at roughly the same rate it produces new ones, a single compaction job will have, on average, a space overhead of 2GB (with the default 1GB fragment size). To calculate the worst-case space requirement for compaction, you need to multiply the maximum number of ongoing compactions by the space overhead for a single compaction job. The maximum number of ongoing compactions can be figured out by multiplying the number of shards by log4 of (disk size per shard).
For example, on a setup with 10 shards and 1TB disk, the maximum number of compactions will be 33 (10 * log4(1000/10)), which results in a worst-case space requirement of 66GB. Since the space overhead is a logarithmic function of the disk size, when increasing the disk size by a factor of 10 to 10TB, the maximum number of compactions will be 50 (10 * log4(10000/10)), resulting in a worst-case space requirement of 100GB which is only 1.5x (log(1000)/log(100)) larger than of 1TB disks. As you can see, the worst-case space requirement increased by a logarithmic factor even though the disk size increased by a factor of 10.
On the setup with 1TB disk, it could theoretically be used up to 93% given that compaction would temporarily increase usage by 6% at most. Whereas on the setup with 10TB disk, it could theoretically be used up to 98% given that compaction would temporarily increase usage by 1% at most. Note that additional disk capacity needs to be reserved for system usage, like commitlog, for example.
Now, consider a real life example with 14 shards and 1TB disk. The worst-case space requirement is calculated to be 86GB. We expect the disk usage to be temporarily increased by 8% at most, so we could theoretically use up to 90% of the disk.
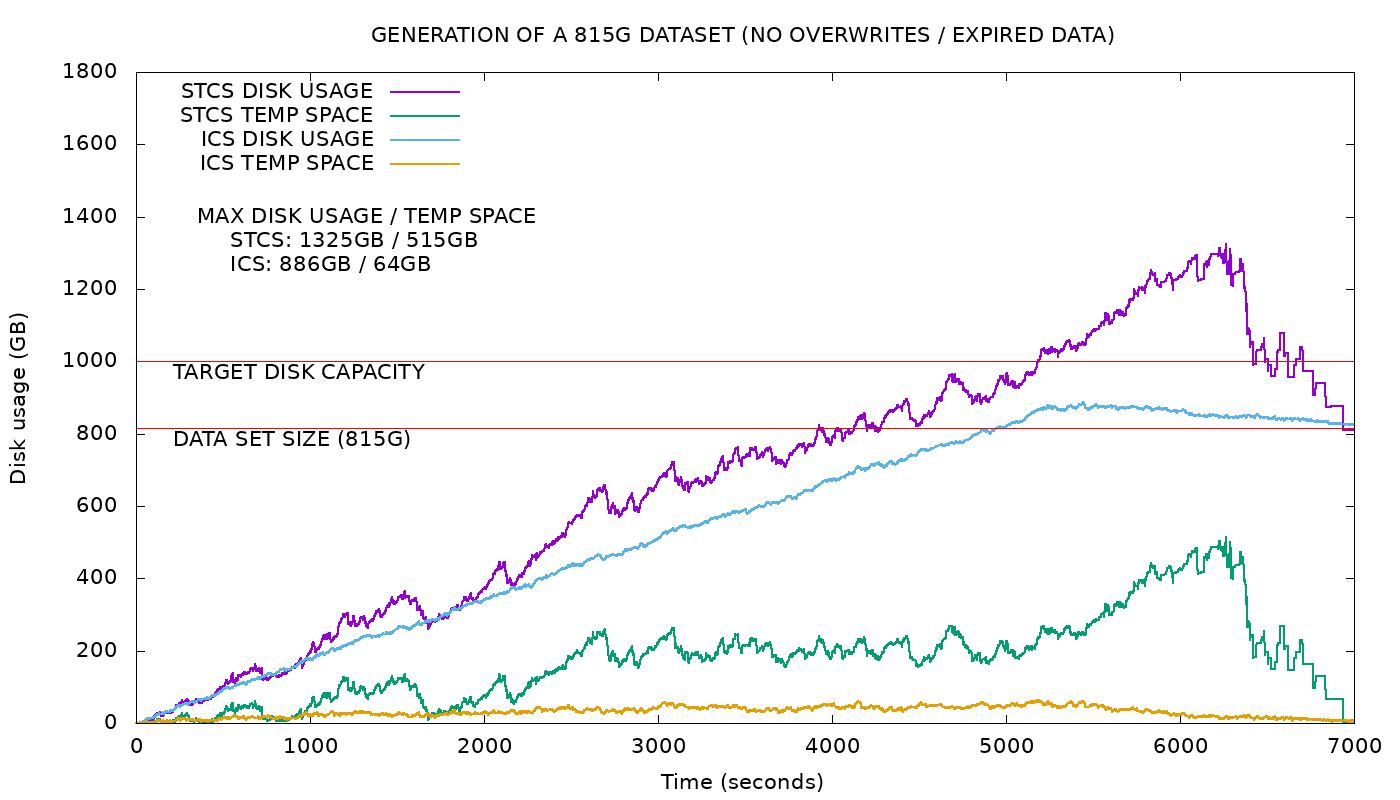
In the experiment above we compared the temporary space consumption of ICS vs. STCS. The data set size filled about 82% of the disk and ICS compaction temporarily increased usage by a maximum of 6% (lower than the worst-case requirement), leading to a maximum of 88%, as depicted by the blue curve in the graph.
The yellow line shows that the temporary requirement for incremental compaction is reduced and bound by a constant function of the number of shards and the fragment size, both of which are constants. Contrast that to the green line that shows that the temporary requirement for STCS is a function of data size.
If we had used a fragment size of 500MB instead of the default 1000MB, the worst-case space requirement would have been reduced from 86GB to 43GB, increasing the utilization by 4% for a 1TB disk.
If we had a 10TB disk instead, reducing the fragment size to 500MB might have been pointless because a saving less than 100GB in worst-case space requirement increases the utilization only in less than 1%.
Incremental compaction guarantees that with a certain configuration, the worst-case temporary space requirement for compaction can be calculated as a function of the number of shards, the disk size, and the fragment size. The exact percentage that results in — 80%, 90%, etc. — depends on the disk size. Since the space overhead is proportional to the logarithm of the disk size, its percentage decreases significantly for larger disks.
Major (manual) compaction is not a nightmare anymore
The nightmare in terms of space requirement for virtually all compaction strategies is also known as major (manual) compaction. That has been a big problem for users because this compaction type is very important for getting rid of redundant data. Many STCS users rely on it periodically so as to avoid disk usage issues.
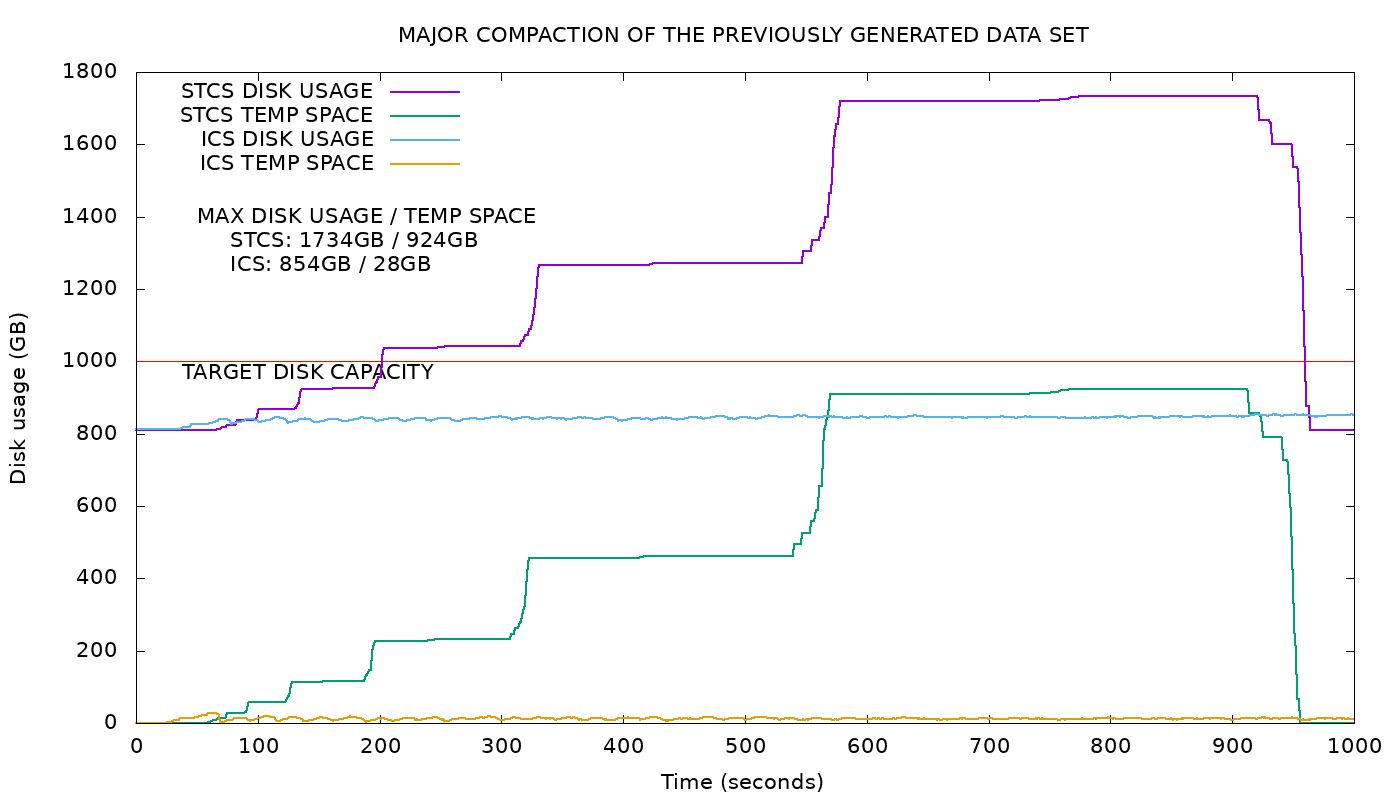
As you probably know, major compaction is basically about compacting all SSTables together. Given that STCS has 100% space overhead, it can be seen by the purple curve above that during STCS major compaction the disk usage doubles, and that can be correlated with a proportional increase in temporary space (in green). ICS major compaction, however, resulted in a space overhead of only ~5%, as shown by the blue line, making the operation feasible even when the disk usage was at 80%!. Therefore, major compaction is not a nightmare for ICS users at all.
Migrating from Size-tiered to Incremental Compaction Strategy
ICS is available from ScyllaDB Enterprise 2019.1.4. Enterprise users can migrate to ICS by merely running the ALTER TABLE command on their STCS tables, as shown in the example below:
ALTER TABLE foo.bar with compaction =
{'class': 'IncrementalCompactionStrategy'};Note that the benefits aren’t instantaneous because the pre-existing SSTables created with STCS cannot be released earlier by incremental compaction, as fragments can. That means their compaction will still suffer with the 100% space overhead. Users will only fully benefit from ICS once all pre-existing SSTables are transformed into SSTable runs. That can be done by running nodetool compact on the ICS tables, otherwise the process is undetermined because it depends on regular compactions eventually picking all those SSTables that were originally created by STCS. Please keep in mind that during migration, the space requirement for nodetool operation to complete is the same as in STCS, which can be up to double the size of a table.
Given that the goal is to push the disk utilization further, it’s extremely important to compact with ICS all of your large tables, that were previously created by STCS (system tables aren’t relevant), otherwise can affect the overall temporary space requirement, potentially leading to disk usage issues. Therefore we recommend running major compaction after the schema is changed to use ICS, before storing any substantial amounts of additional data in the table.
Configuring ICS
ICS inherits all strategy options from STCS, so you can control its behavior exactly like you would do with STCS. In addition, ICS has a new property called sstable_size_in_mb that controls the fragment size of SSTable runs. It is set to 1000 (1GB) by default.
ICS’s temporary space requirement is proportional to the fragment size, so lower sstable_size_in_mb decreases the temporary space overhead and higher values will increase it. For example, if you set sstable_size_in_mb to 500 (0.5GB), the temporary space requirement is expected to be cut by half. However, shrinking sstable_size_in_mb causes the number of SSTables to inflate, and with that, the SSTables in-memory metadata overhead will increase as well. So if you consider changing sstable_size_in_mb, we recommend keeping the average number of SSTables per shard roughly around 100 to 150.
- Note: Number of SSTables per shard is estimated by: (data size in mb /
sstable_size_in_mb/ number of shards).
Conclusion
If you’re a ScyllaDB Enterprise user that relies on STCS, we recommend switching to ICS immediately. Storage at scale is very expensive nowadays so it’s very important to maximize its usage. Incremental Compaction Strategy helps users increase disk utilization to the max, without increasing either read or write amplification. This translates into using fewer nodes, or storing more data on the existing cluster. So incremental compaction allows us to finally say:
Adios <50% disk usage limitation!









