
Six years ago, a few of us were busy hacking on a new unikernel, OSv, which we hoped would speed up any Linux application. One of the applications which we wanted to speed up was Apache Cassandra — a popular and powerful open-source NoSQL database. We soon realized that although OSv does speed up Cassandra a bit, we could achieve much better performance by rewriting Cassandra from scratch.
The result of this rewrite was ScyllaDB — a new open-source distributed database. ScyllaDB kept compatibility with Cassandra’s APIs and file formats, and as hoped outperformed Cassandra — achieving higher throughput per node, lower tail latencies, and vertical scalability (many-core nodes) in addition to Cassandra’s already-famous horizontal scalability (many-node clusters).
As part of ScyllaDB’s compatibility with Apache Cassandra, ScyllaDB adopted Cassandra’s CQL (Cassandra Query Language) API. This choice of API had several consequences:
- CQL, as its acronym says, is a query language. This language was inspired by the popular SQL but differs from it in syntax and features in many important ways.
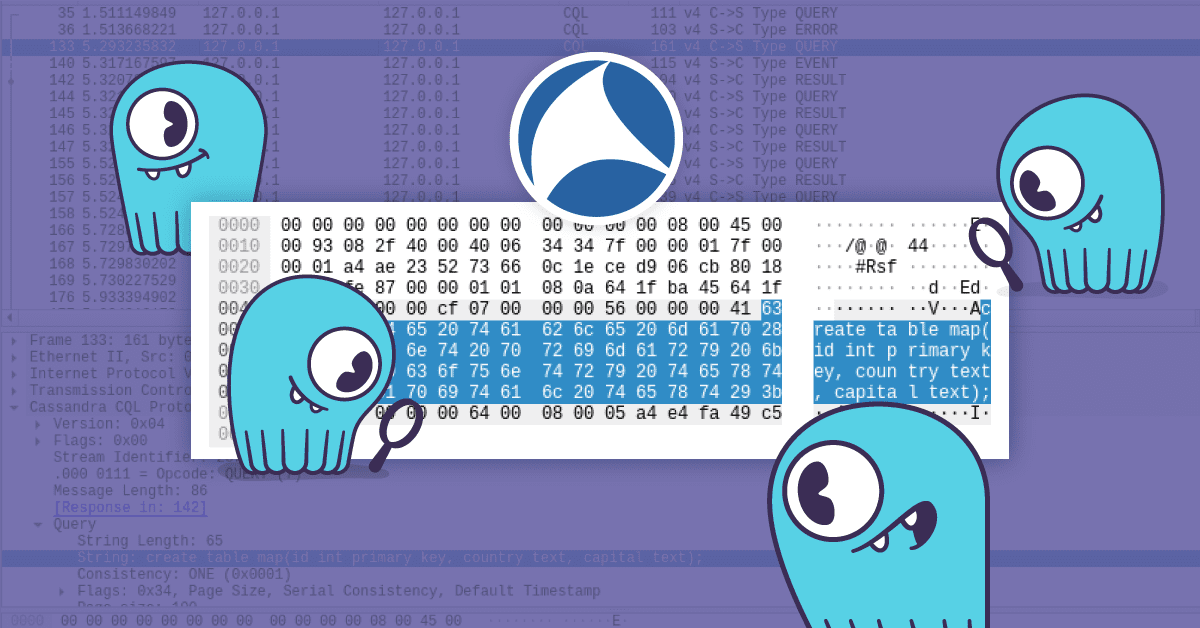
- CQL is also a protocol — telling clients how to communicate with which ScyllaDB node.
- CQL is also a data model — database rows are grouped together in a wide row, called a partition. The rows inside the partition are sorted by a clustering key.
Oddly enough, this data model does not have an established name, and is often referred to as a wide column store.
Recently, ScyllaDB announced Project Alternator, which added support for a second NoSQL API to ScyllaDB — the API of Amazon’s DynamoDB. DynamoDB is another popular NoSQL database, whose popularity has been growing steadily in recent years thanks to its ease of use and its backing by Amazon. DynamoDB was designed based on lessons learned from Cassandra (as well as Amazon’s earlier Dynamo work), so its data model is sufficiently similar to that of Cassandra to make supporting both Cassandra’s API and DynamoDB’s API in one database an approachable effort. However, while the two data models are similar, the other aspects of the two APIs — the protocol and the query language — are very different.
After implementing both APIs — CQL and DynamoDB — we, the ScyllaDB developers, are in a unique position to be able to provide an unbiased technical comparison between the two APIs. We have implemented both APIs in ScyllaDB, and have no particular stake in either. The goal of this post is to explain some of the more interesting differences between the two APIs, and how these differences affect users and implementers of these APIs. However, this post will not cover all the differences between the two APIs.
Transport: proprietary vs. standard
A very visible difference between the CQL and DynamoDB APIs is the transport protocol used to send requests and responses. CQL uses its own binary protocol for transporting SQL-like requests, while DynamoDB uses JSON-formatted requests and responses over HTTP or HTTPS.
DynamoDB’s use of popular standards — JSON and HTTP — has an obvious benefit: They are familiar to most users, and many programming languages have built-in tools for them. This, at least in theory, makes it easier to write client code for this protocol compared to CQL’s non-standard protocol, which requires special client libraries (a.k.a. “client drivers”). Moreover, the generality of JSON and HTTP also makes it easy to add more features to this API over time, unlike rigid binary protocols that need to change and further complicate the client libraries. In the last 8 years, the CQL binary protocol underwent four major changes (it is now in version 5), while the DynamoDB API added features gradually without changing the protocol at all.
However, closer inspection reveals that special client libraries are needed for DynamoDB as well. The problem is that beyond the standard JSON and HTTP, several other non-standard pieces are needed to fully utilize this API. Among other things, clients need to sign their requests using a non-standard signature process, and DynamoDB’s data types are encoded in JSON in non-obvious ways.
So DynamoDB users cannot really use JSON or HTTP directly. Just like CQL users, they also use a client library that Amazon or the AWS community provided. For example, the Python SDK for AWS (and for DynamoDB in particular) is called boto3. The bottom line is that both CQL and DynamoDB ecosystems have client libraries for many programming languages, with a slight numerical advantage to CQL. For users who use many AWS services, the ability to use the same client library to access many different services — not just the database — is a bonus. But in this post we want to limit ourselves just to the database, and DynamoDB’s use of standardized protocols ends up being of no real advantage to the user.
At the same time, there are significant drawbacks to using the standard JSON and HTTP as the DynamoDB API does:
- DynamoDB supports only HTTP/1.1 — it does not support HTTP/2. One of the features missing in HTTP/1.1 is support for multiplexing many requests (and their responses) over the same connection. As a result, clients that need high throughput, and therefore high concurrency, need to open many connections to the server. These extra connections consume significant networking, CPU, and memory resources.
At the same time the CQL binary protocol allows sending multiple (up to 32,768) requests asynchronously and potentially receiving their responses in a different order.
The DynamoDB API had to work around its transport’s lack of multiplexing by adding special multi-request operations, namelyBatchGetItemandBatchWriteItem— each can perform multiple operations and return reordered responses. However, these workarounds are more limited and less convenient than generic support for multiplexing.
Had DynamoDB supported HTTP/2, it would have gained multiplexing as well, and would even gain an advantage over CQL for large requests or responses: The CQL protocol cannot break up a single request or response into chunks, but HTTP/2 does do it, avoiding large latencies for small requests which happen to follow a large request on the same connection. We predict that in the future, DynamoDB will support HTTP/2. Some other Amazon services already do. - DynamoDB’s requests and responses are encoded in JSON. The JSON format is verbose and textual, which is convenient for humans but longer and slower to parse than CQL’s binary protocol. Because there isn’t a direct mapping of DynamoDB’s types to JSON, the JSON encoding is quite elaborate. For example, the string “
hello” is represented in JSON as{"S": "hello"}, and the number 3 is represented as{"N": "3"}. Binary blobs are encoded using base64, which makes them 33% longer than necessary. The request parsing code then needs to parse JSON, decode all these conventions and deal with all the error cases when a request deviates from these conventions. This is all significantly slower than parsing a binary protocol. - DynamoDB, like other HTTP-based protocols, treats each request as a self-contained message that can be sent over any HTTP connection. In particular, each request is signed individually using a hash-based message authentication code (HMAC) which proves the request’s source as well as its integrity. But these signatures do not encrypt the requests, which are still visible to prying eyes on the network — so most DynamoDB users use encrypted HTTPS (a.k.a. TLS, or SSL) instead of unencrypted HTTP as the transport. But TLS also has its own mechanisms to ensure message integrity, duplicating some of the effort done by the DynamoDB signature mechanism. In contrast, the CQL protocol also uses TLS — but relies on TLS for both message secrecy and integrity. All that is left for the CQL protocol is to authenticate the client (i.e., verify which client connected), but that can be done only once per connection — and not once per request.
Protocol: cluster awareness vs. one endpoint
A distributed database is, well… distributed. It is a cluster of many different servers, each responsible for part of the data. When a client needs to send a request, the CQL and DynamoDB APIs took very different approaches on where the client should send its request:
- In CQL, clients are “topology aware” — they know the cluster’s layout. A client knows which ScyllaDB or Cassandra nodes exist, and is expected to balance the load between them. Moreover, the client usually knows which node holds which parts of the data (this is known as “token awareness”), so it can send a request to read or write an individual item directly to a node holding this item. ScyllaDB clients can even be “shard aware,” meaning they can send a request directly to the specific CPU (in a node with many CPUs) that is responsible for the data.
- In the DynamoDB API, clients are not aware of the cluster’s layout. They are not even aware how many nodes there are in the cluster. All that a client gets is one “endpoint,” a URL like
https://dynamodb.us-east-1.amazonaws.com— and directs all requests from that data-center to this one endpoint. DynamoDB’s name server can then direct this one domain name to multiple IP addresses, and load balancers can direct the different IP addresses to any number of underlying physical nodes.
Again, one benefit of the DynamoDB approach is the simplicity of the clients. In contrast, CQL clients need to learn the cluster’s layout and remain aware of it as it changes, which adds complexity to the client library implementation. But since these client libraries already exist, and both CQL and DynamoDB API users need to use client libraries, the real advantage to application developers is minimal.
But CQL’s more elaborate approach comes with an advantage — reducing the number of network hops, and therefore reducing both latency and cost: In CQL, a request can often be sent on a socket directed to a specific node or even a specific CPU core that can answer it. With the DynamoDB API, the request needs to be sent at a minimum through another hop — e.g., in Amazon’s implementation the request first arrives at a front-end server, which then directs the request to the appropriate back-end node. If the front-end servers are themselves load-balanced, this adds yet another hop (and more cost). These extra hops add to the latency and cost of a DynamoDB API implementation compared to a cluster-aware CQL implementation.
On the other hand, the “one endpoint” approach of the DynamoDB API also has an advantage: It makes it easier for the implementation to hide from users unnecessary details on the cluster, and makes it easier to change the cluster without users noticing or caring.
Query language: prepared statements
We already noted above how the DynamoDB API uses the HTTP transport in the traditional way: Even if requests are sent one after another on the same connection (i.e., HTTP Keep-Alive), the requests are independent, signed independently and parsed independently.
In many intensive (and therefore, expensive) use cases, the client sends a huge number of similar requests with slightly different parameters. In the DynamoDB API, the server needs to parse these very similar requests again and again, wasting valuable CPU cycles.
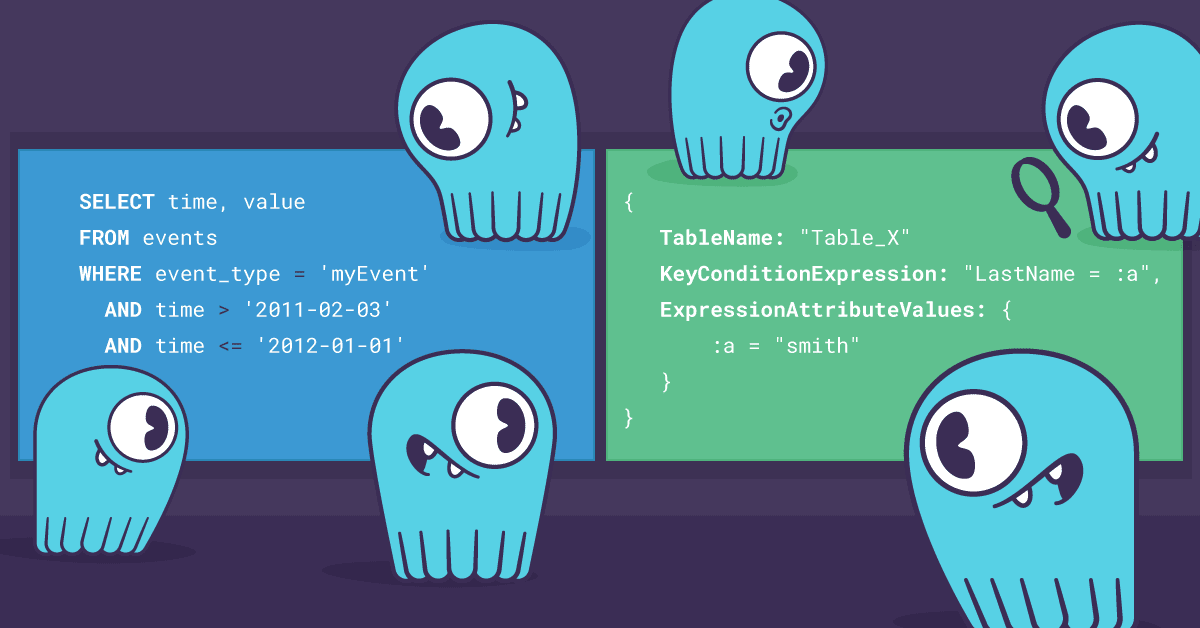
The CQL query language offers a workaround: prepared statements. The user asks to prepare a parameterized statement — e.g., “insert into tb (key, val) values (?, ?)” with two parameters marked with question-marks. This statement is parsed only once, and further requests to the same node can reuse the pre-parsed statement, passing just the two missing values. The benefit of prepared statements are especially pronounced in small and quick requests, such as reads that can frequently be satisfied from cache, or writes. In this blog post we demonstrated in one case that using prepared statements can increase throughput by 50% and lower latency by 33%.
Adding prepared-statement support to the DynamoDB API would be possible, but will require some changes to the protocol:
First, we would need to allow a client to send an identifier of a previously-sent query instead of the full query. In addition to the query identifier, the client will need to send the query’s parameters – luckily the notion of query parameters is already supported by the DynamoDB API, as ExpressionAttributeValues.
Second, DynamoDB API clients are not aware of which of the many nodes in the cluster will get their request, so the client doesn’t know if the node that will receive its request has already parsed this request in the past. So we would need a new “prepare” request that will parse this request and make its identifier available across the entire cluster.
Write model: CRDT vs. read-modify-write
Amazon DynamoDB came out in 2012, two years after Cassandra. DynamoDB’s data model was inspired by Cassandra’s, which in turn was inspired by the data model Google’s BigTable (you can read a brief history of how the early NoSQL databases influenced each other here). In both DynamoDB and Cassandra, database rows are grouped together in a partition by a partition key, with the rows inside the partition sorted by a clustering key. The DynamoDB API and CQL use different names for these same concepts, though:
| CQL Term | DynamoDB term | |
| Smallest addressable content | row | item |
| Sub-entities | column | attribute |
| Unit of distribution | partition (many rows) | partition (many items) |
| Key for distribution | partition key | partition key (also hash key) |
| Key within partition | clustering key | sort key (also range key) |
Despite this basic similarity in how the data is organized — and therefore in how data can be efficiently retrieved — there is a significant difference in how DynamoDB and CQL model writes. The two APIs offer different write primitives and make different guarantees on the performance of these primitives:
Cassandra is optimized for write performance. Importantly, ordinary writes do not require a read of the old item before the write: A write just records the change, and only read operations (and background operations known as compaction and repair) will later reconcile the final state of the row. This approach, known as Conflict-free Replicated Data Types (CRDT), has implications on Cassandra’s implementation, including its data replication and its on-disk storage in a set of immutable files called SSTables (comprising an LSM). But more importantly for this post, the wish that ordinary writes should not read also shaped Cassandra’s API, CQL:
- Ordinary write operations in CQL — both UPDATE and INSERT requests — just set the value of some columns in a given row. These operations cannot check whether the row already existed beforehand, and the new values cannot depend on the old values. A write cannot return the old pre-modification values, nor can it return the entire row when just a part of it was modified.
- These ordinary writes are not always serialized. They usually are: CQL assigns a timestamp (with microsecond resolution) to each write and the latest timestamp wins. However two concurrent writes which happen to receive exactly the same timestamp may get mixed up, with values from both writes being present in the result.
For more information on this problem, see this Jepsen post. - CQL offers a small set of additional CRDT data structures for which writes just record the change and do not need to involve a read of the prior value. These include collections (maps, sets and lists) and counters.
- Additionally, CQL offers special write operations that do need to read a row’s previous state before a write. These include materialized views and lightweight transactions (LWT). However, these write operations are special; Users know that they are significantly slower than ordinary writes because they involve additional synchronization mechanisms – so users use them with forethought, and often sparingly.
Contrasting with CQL’s approach, DynamoDB’s approach is that every write starts with a read of the old value of the item. In other words, every write is a read-modify-write operation. Again, this decision had implications on how DynamoDB was implemented. DynamoDB uses leader-based replication so that a single node (the leader for the item) can know the most recent value of an item and serialize write operations on it. DynamoDB stores data on disk using B-trees which allow reads together with writes. But again, for the purpose of this post, the interesting question is how making every write a read-modify-write operation shaped DynamoDB’s API:
- In the DynamoDB API, every write operation can be conditional: A condition expression can be added to a write operation, and uses the previous value of the item to determine whether the write should occur.
- Every write operation can return the full content of the item before the write (
ReturnValues). - In some update operations (UpdateItem), the new value of the item may be based on the previous value and an update expression. For example, “a = a + 1” can increment the attribute a (there isn’t a need for a special “counter” type as in CQL).
- The value of an item attribute may be a nested JSON-like type, and an update may modify only parts of this nested structure. DynamoDB can do this by reading the old nested structure, modifying it, and finally writing the structure back.
CQL could have supported this ability as well without read-modify-write by adding a CRDT implementation of a nested JSON-like structure (see, for example, this paper) — but currently doesn’t and only supports single-level collections. - Since all writes involve a read of the prior value anyway, DynamoDB charges for writes the same amount whether or not they use any of the above features (condition, returnvalues, update expression). Therefore users do not need to use these features sparingly.
- All writes are isolated from each other; two concurrent writes to the same row will be serialized.
This comparison demonstrates that the write features that the DynamoDB and CQL APIs provide are actually very similar: Much of what DynamoDB can do with its various read-modify-write operations can be done in CQL with the lightweight transactions (LWT) feature or by simple extensions of it. In fact, this is what ScyllaDB does internally: We implemented CQL’s LWT feature first, and then used the same implementation for the write operations of the DynamoDB API.
However, despite the similar write features, the two APIs are very different in their performance characteristics:
- CQL makes an official distinction between write-only updates and read-modify-write updates (LWT), and the two types of writes must not be done concurrently to the same row. This allows a CQL implementation to implement write-only updates more efficiently than read-modify-write updates.
- A DynamoDB API implementation, on the other hand, cannot do this optimization: With the DynamoDB API, write-only updates and (for example) conditional updates can be freely mixed and need to be isolated from one another.
This requirement has led ScyllaDB’s implementation of the DynamoDB API to use the heavyweight (Paxos-based) LWT mechanism for every write, even simple ones that do not require reads, making them significantly slower than the same write performed via the CQL API. We will likely optimize this implementation in the future, perhaps by adopting a leader model (like DynamoDB), but an important observation is that in every implementation of the DynamoDB API, writes will be significantly more expensive than reads. Amazon prices write operations at least 5 times more expensive than reads (this ratio reaches1 40 for weakly-consistent reads of 4 KB items).
ScyllaDB provides users with an option to do DynamoDB-API write-only updates (updates without a condition, update expression, etc.) efficiently, without LWT. However, this option is not officially part of the DynamoDB API, and as explained above — cannot be made safe without adding an assumption that write-only updates and read-modify-write updates to the same item cannot be mixed.
Data items: schema vs. (almost) schema-less
Above we noted that both APIs — DynamoDB and CQL — model their data in the same way: as a set of partitions indexed by a partition key, and each partition is a list of items sorted by a sort key.
Nevertheless, the way that the two APIs model data inside each item is distinctly different:
- CQL is schema-full: A table has a schema — a list of column names and their types – and each item must conform with this schema. The item must have values of the expected types for all or some of these columns.
- DynamoDB is (almost) schema-less: Each item may have a different set of attribute names, and the same attribute may have values of different types2. DynamoDB is “almost” schema-less because the items’ key attributes — the partition key and sort key — do have a schema. When a table is created, one must specify the name and type of its partition-key attribute and its optional sort-key attribute.
It might appear, therefore, that DynamoDB’s schema-less data model is more general and more powerful than CQL’s schema-full data model. But this isn’t quite the case. When discussing CRDT above, we already mentioned that CQL supports collection columns. In particular, a CQL table can have a map column, and an application can store in that map any attributes that aren’t part of its usual schema. CQL’s map does have one limitation, though: The values stored in a map must all have the same type. But even this limitation can be circumvented, by serializing values of different types into one common format such as a byte array. This is exactly how ScyllaDB implemented the DynamoDB API’s schema-less items on top of its existing schema-full CQL implementation.
So it turns out that the different approaches that the two APIs took to schemas have no real effect on the power or the generality of the two APIs. Still, this difference does influence what is more convenient to do in each API:
- CQL’s schema makes it easier to catch errors in a complex application ahead of time – in the same way that compile-time type checking in a programming language can catch some errors before the program is run.
- The DynamoDB API makes it natural to store different kinds of data in the same database. Many DynamoDB best-practice guides recommend a single-table design, where all the application’s data resides in just a single table (plus its indexes). In contrast, in CQL the more common approach is to have multiple tables each with a different schema. CQL introduces the notion of “keyspace” to organize several related tables together.
- The schema-less DynamoDB API makes it somewhat easier to change the data’s structure as the application evolves. CQL does allow modifying the schema of an existing table via an “
ALTER TABLE” statement, but it is more limited in what it can modify. For example, it is not possible to start storing strings in a column that used to hold integers (however, it is possible to create a second column to store these strings).
Summary
In this post, we surveyed some of the major differences between the Amazon DynamoDB API and Apache Cassandra’s CQL API — both of which are now supported in one open-source database, ScyllaDB. Despite a similar data model and design heritage, these two APIs differ in the query language, in the protocol used to transport requests and responses, and somewhat even in the data model (e.g., schema-full vs. schema-less items).
We showed that in general, it is easier to write client libraries for the DynamoDB API because it is based on standardized building blocks such as JSON and HTTP. Nevertheless, we noted that this difference does not translate to a real benefit to users because such client libraries already exist for both APIs, in many programming languages. But the flip side is that the simplicity of the DynamoDB API costs in performance: The DynamoDB API requires extra network hops (and therefore increased costs and latency) because clients do not need to be aware of which data belongs to which node. The DynamDB API also requires more protocol and parsing work and more TCP connections.
We discussed some possible directions in which the DynamoDB API could be improved (such as adopting HTTP/2 and a new mechanism for prepared statements) to increase its performance. We don’t know when, if ever, such improvements might reach Amazon DynamoDB. But as an experiment, we could implement these improvements in the open-source ScyllaDB and measure what kinds of benefits an improved API might bring. When we do, look forward to a follow-up on this post detailing these improvements.
We also noted the difference in how the two APIs handle write operations. The DynamoDB API doesn’t make a distinction between writes that need the prior value of the item and writes that do not. This makes it easier to write consistent applications with this API, but also means that writes with the DynamoDB API are always significantly more expensive than reads. Conversely, the CQL API does make this distinction — and does forbid mixing the two types of writes. Therefore, the CQL API allows write-only updates to be optimized, while the read-modify-write updates remain slower. For some applications, this can be a big performance boost.
The final arbiter in weighing these APIs is subjective in answer to the question: “Which will be better for your use case?” Due to many of the points made above, and due to other features which at this point are only available through ScyllaDB’s CQL implementation, ScyllaDB currently advises users to adopt the CQL interface for all use cases apart from “lift and shift” migrations from DynamoDB.
Notes
1 Amazon prices a write unit (WCU) at 5 times the cost of a read unit (RCU). Additionally, for large items, each 1 KB is counted as a write unit, while a read unit is 4 KB. Moreover, eventually-consistent reads are counted as half a read unit. So writing a large item is 40 (=5*4*2) times more expensive than reading it with an eventually-consistent read.
2 The value types supported by the two APIs also differ, and notably the DynamoDB API supports nested documents. But these are mostly superficial differences and we won’t elaborate on this further here.