September 8, 2022 Zeotap: Building a Privacy Compliant Customer Data Platform (CDP) with ScyllaDB Events, User Stories, News & Events
August 11, 2022 CQL-over-WebSocket: Interact with ScyllaDB from Your Browser Tutorials, Seastar, Integrations, ScyllaDB Open Source, Product, Engineering
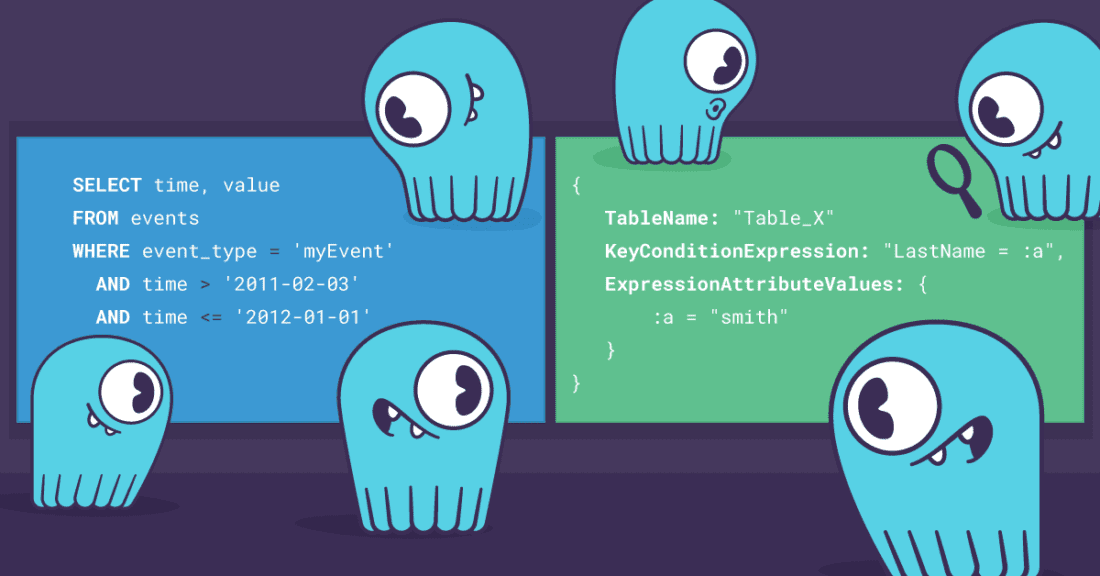
May 11, 2022 5 Tips to Optimize Your CQL Queries Performance, Product, ScyllaDB Monitoring Stack, How To
August 4, 2021 ScyllaDB Brings ScyllaDB Cloud to Google Cloud Featured, News, ScyllaDB Cloud, Product, News & Events
August 2, 2021 Which Will Be the Best Wide Column Store Database? Featured, News, ScyllaDB Open Source, Product, News & Events, Leadership Team
February 17, 2021 ScyllaDB Developer Hackathon: Rust Driver Events, Performance, News & Events, Engineering
December 11, 2019 Project Gemini: An Open Source Automated Random Testing Suite for ScyllaDB and Cassandra Clusters ScyllaDB Open Source