This week we announced our Project Alternator, open-source software that will enable application- and API-level compatibility between ScyllaDB and Amazon DynamoDB. Available for use with ScyllaDB Open Source, Alternator will let DynamoDB users easily migrate to an open source NoSQL database that runs anywhere — on any cloud platform, on-premises, on bare-metal, virtual machines or Kubernetes — without having to change their client code.
Of course, applications operate on data, and the data that is in DynamoDB has to first be migrated to ScyllaDB so that users can take full advantage of this new capability. ScyllaDB already supported migrations from Apache Cassandra by means of the scylla-migrator project, an Apache Spark-based tool that we’ve previously described.
This article presents the extensions done to the ScyllaDB Migrator to also support data movement between an existing DynamoDB installation and ScyllaDB.The idea is simple: a cluster of Spark workers reads the source database (DynamoDB) in parallel and writes in parallel to the target database, ScyllaDB.
Running the Migrator
The latest copy of the scylla-migrator, which already contains the DynamoDB-compatible API bindings can be found here. Always refer for latest steps to bundled README.dynamodb.md.
The first step is to build it. Make sure a recent copy of sbt is properly installed on your machine, and run build.sh.
Next, the connection properties with DynamoDB have to be configured. The migrator ships with an example file, so we can start by copying the example to a configuration file
cp config.dynamodb.yaml.example config.dynamodb.yaml
Most importantly, we will configure the source and target sections to describe our source DynamoDB cluster and target ScyllaDB cluster:
The first thing to notice is that the target configuration is simpler; since we one will be connecting to a live ScyllaDB cluster, not to an AWS service, there is no need to provide the access keys (for public clusters usernames, and passwords can be provided instead).
The next step is to submit the spark application. The application is submitted in a generic way, the migrator leverages spark.scylla.config variable to pass on parameters.
An Example Migration
To test and demonstrate the migrator, we have created an example table in DynamoDB and filled it with data.
Be sure to pay attention to throughput variables and number of splits and mappers. Do set them up properly based on what capacity you can use from what you’ve provisioned. The scan_segments controls the split size(how many tasks there will be, so this divides your data into smaller chunks for processing) and max_map_tasks controls maximum of map tasks for map reduce job that migrates the data.
Tuning those two variables will generally require more resources on spark worker side, so make sure you allocate them, e.g. by using spark-submit option –conf “spark.executor.memory=100G and similar for CPUs.
Since the migrator is just a spark application, the running application can be monitored using spark web UI:
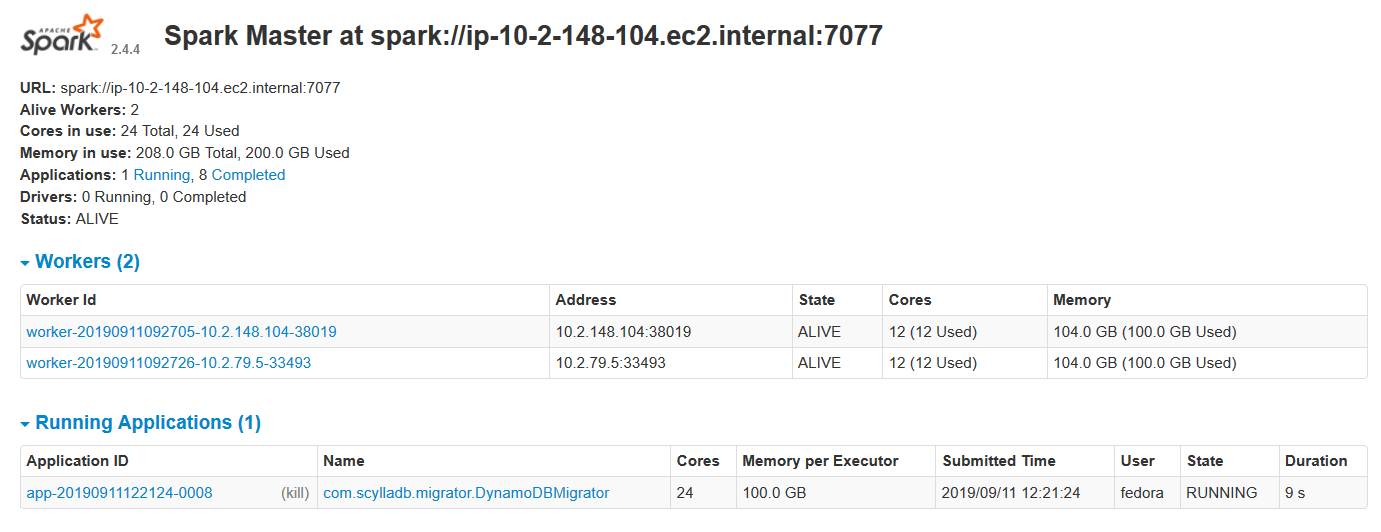
Figure 1: Workers and Running Applications
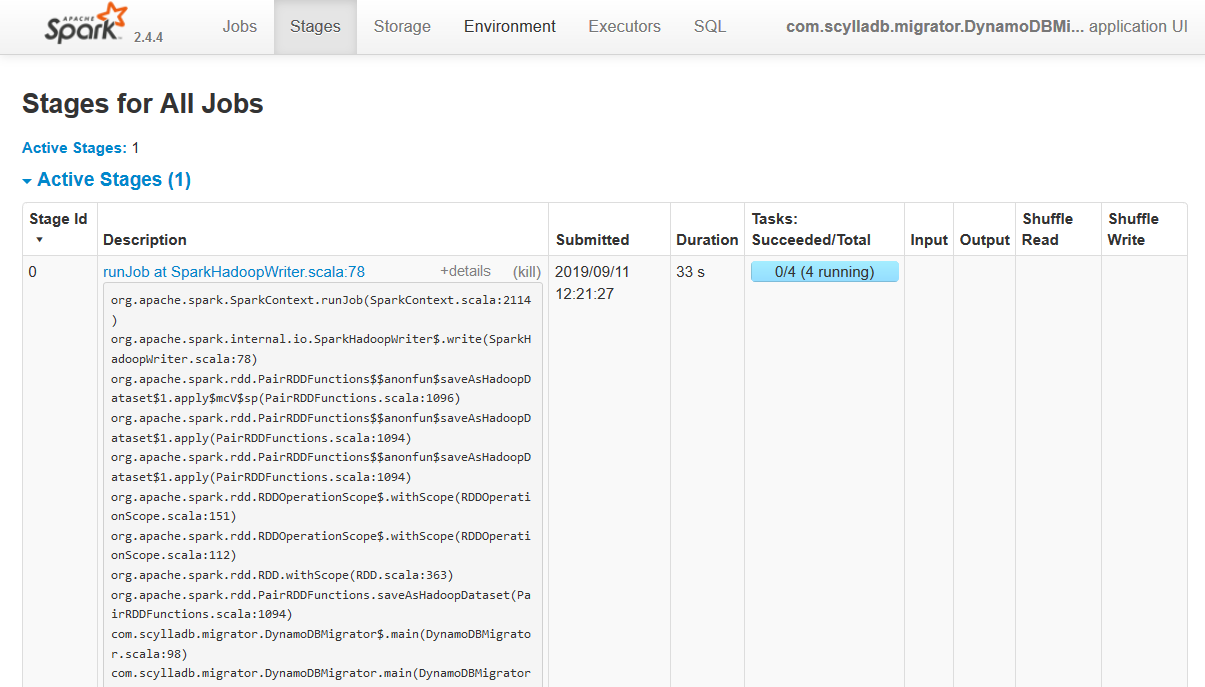
Figure 2: Active Stages
Verifying the Migration
To verify the migration is successful, we can first match the count of keys from DynamoDB. In this case, we have 7,869,600 keys:
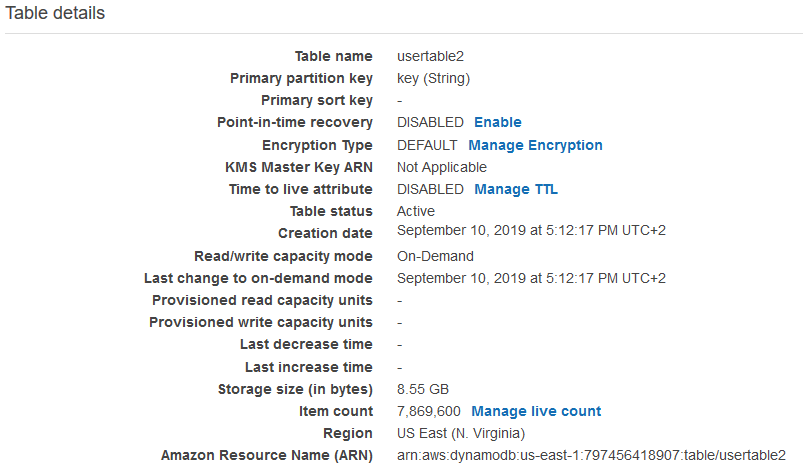
Figure 3: Table Details
When finished, the spark tasks will print messages to their logs with the number of keys that each task transferred:
Which, as we expect, sums up to 7,869,600, the same number of keys we had in the source.
We have also queried some random keys from both databases, since they now accept the same API. We can see that all keys that are randomly sampled are present in both sides:
Script:
Results:
Future work
Much like the DynamoDB-compatible API in ScyllaDB itself, the migrator is a work in progress. In live migrations without downtime, there is usually the need to perform dual writes, a technique in which the application is temporarily and surgically changed so that new writes are sent to both databases, while the old data is scanned and written to the new database. However, DynamoDB supports a well-rounded stream interfaces, where an application can listen for changes. The streams API can be used to facilitate migrations without explicitly coding for dual writes. That is a work in progress in the migrator, expected to debut soon.
Next Steps
If you want to learn more about Project Alternator, we have a webinar that is scheduled for September 25, 10 AM Pacific, 1 PM Eastern. And you can also check out the Project Alternator Wiki.