Learn how to run your existing DynamoDB workloads on Google Cloud (GCP), step-by-step
Amazon’s DynamoDB must be credited for allowing a broader adoption of NoSQL databases at-scale. However, many developers want flexibility to run workloads on different clouds or across multiple clouds for high availability or disaster recovery purposes. This was a key reason ScyllaDB introduced its DynamoDB-compatible API, Project Alternator. It allows you to run a ScyllaDB cluster on your favorite public cloud, or even on-premises.
Let’s say that your favorite cloud is Google Cloud and that’s where you’d like to move your current DynamoDB workload. Moving from AWS to Google Cloud can be hard, especially if your application is tightly-coupled with the proprietary AWS DynamoDB API. With the introduction of ScyllaDB Cloud Alternator, our DynamoDB-compatible API as a service, this task became much easier.
This post will guide you through the database part of the migration process, ensuring minimal changes to your applications. What does it take? Let’s go step-by-step through the migration process.
Launch a ScyllaDB Cloud Alternator instance on Google Cloud
This part is easy:
Visit cloud.scylladb.com, sign in or sign up, and click “new cluster”.
Select GCP and Alternator, choose the instance type, click “Launch” and grab a coffee. You will have a cluster up and running in a few minutes.

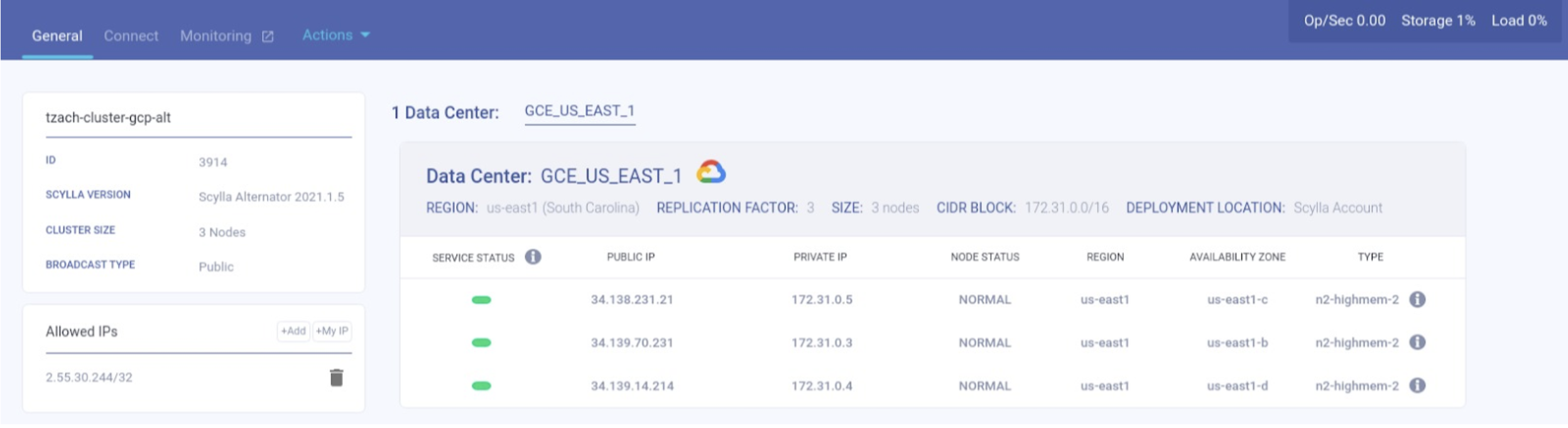
Once the cluster is up and running, you can visit the cluster view to check its status
Move to the New Cluster
For the scope of this document, I’m ignoring the migration of the application logic, and the data transfer cost. Clearly you will need to consider both.
First question you need to ask yourself is: can I tolerate a downtime in service during the migration?
- If yes, you need a cold / off line migration. You only needs to migrate the historical data from Dynamo to ScyllaDB, also called forklifting
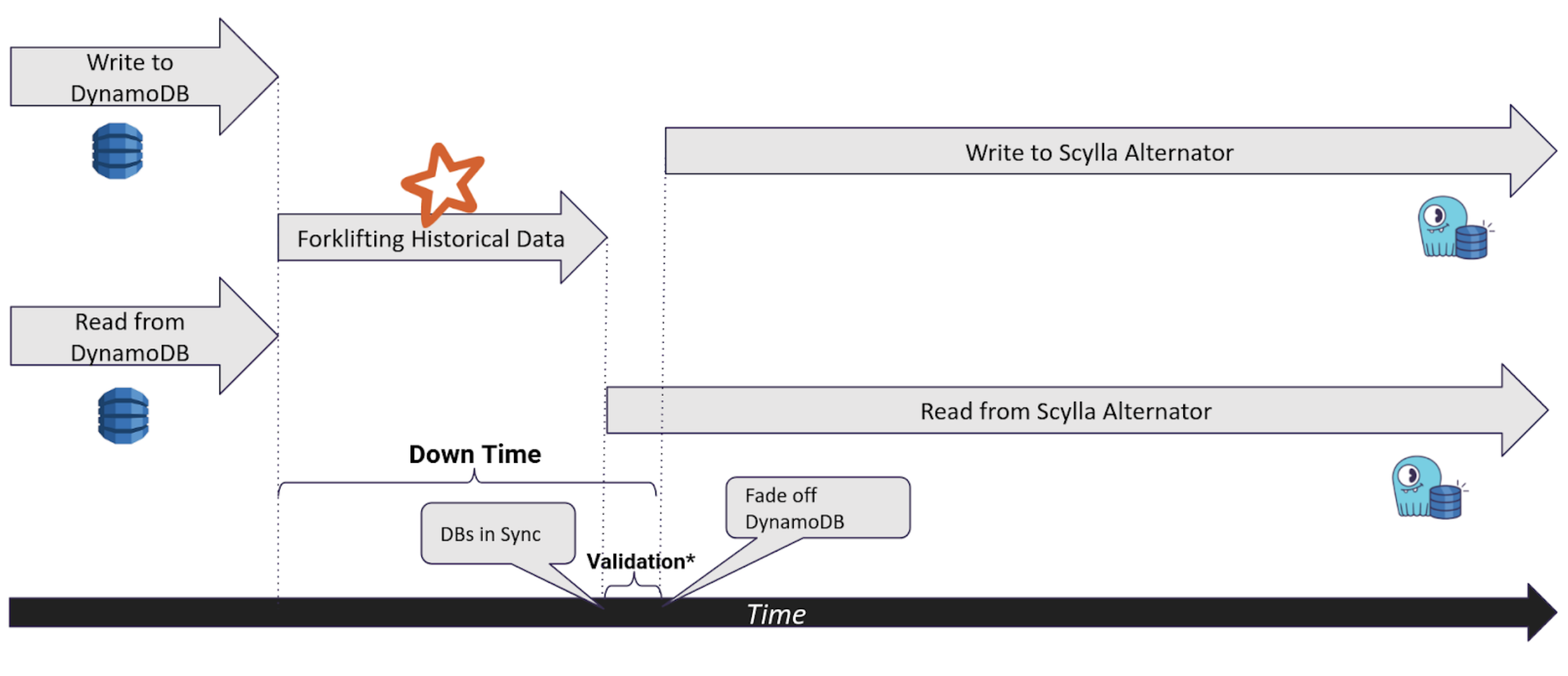
- If not, you need a hot / live Migration. You will first need to extend your application to perform dual write to both databases, and only then execute the forklift.
Cold Migration
Hot Migration
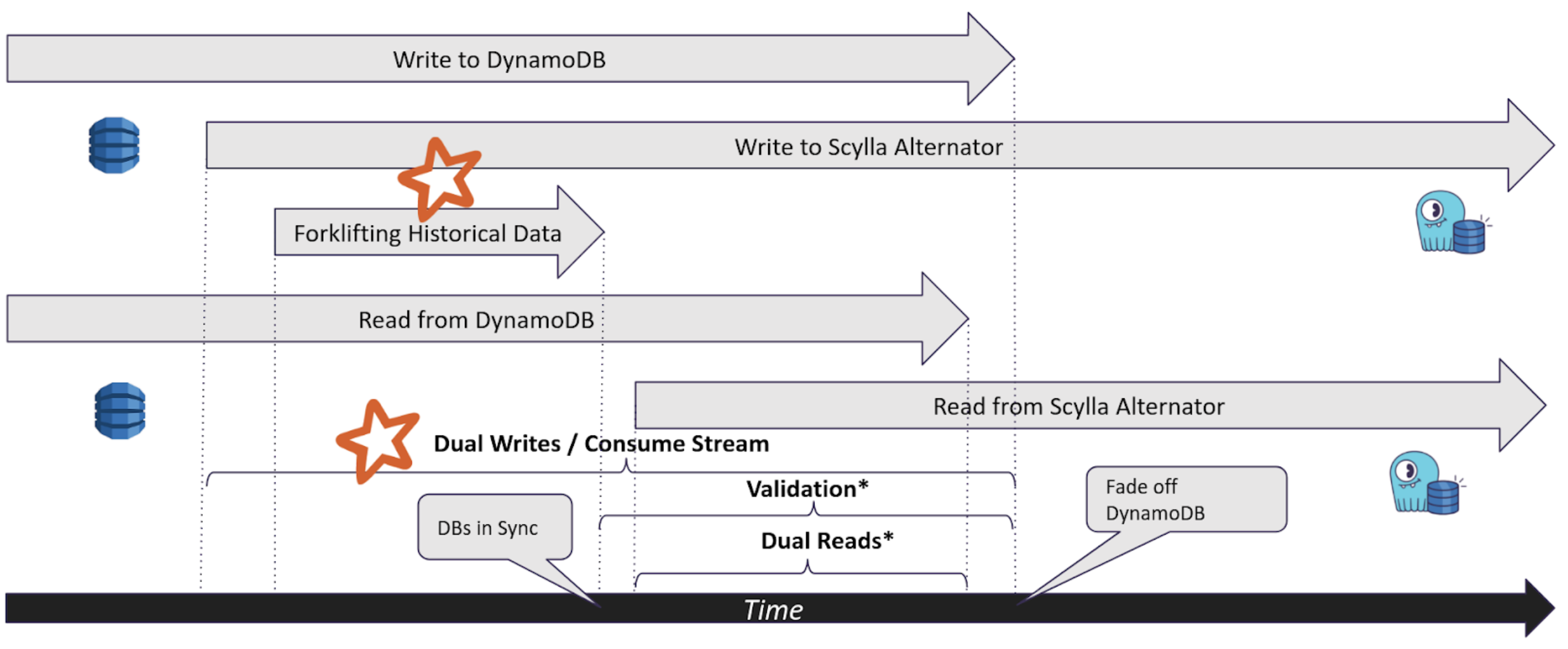
Real Time Sync
There are two possible alternatives to keep the two DBs in sync in real time:
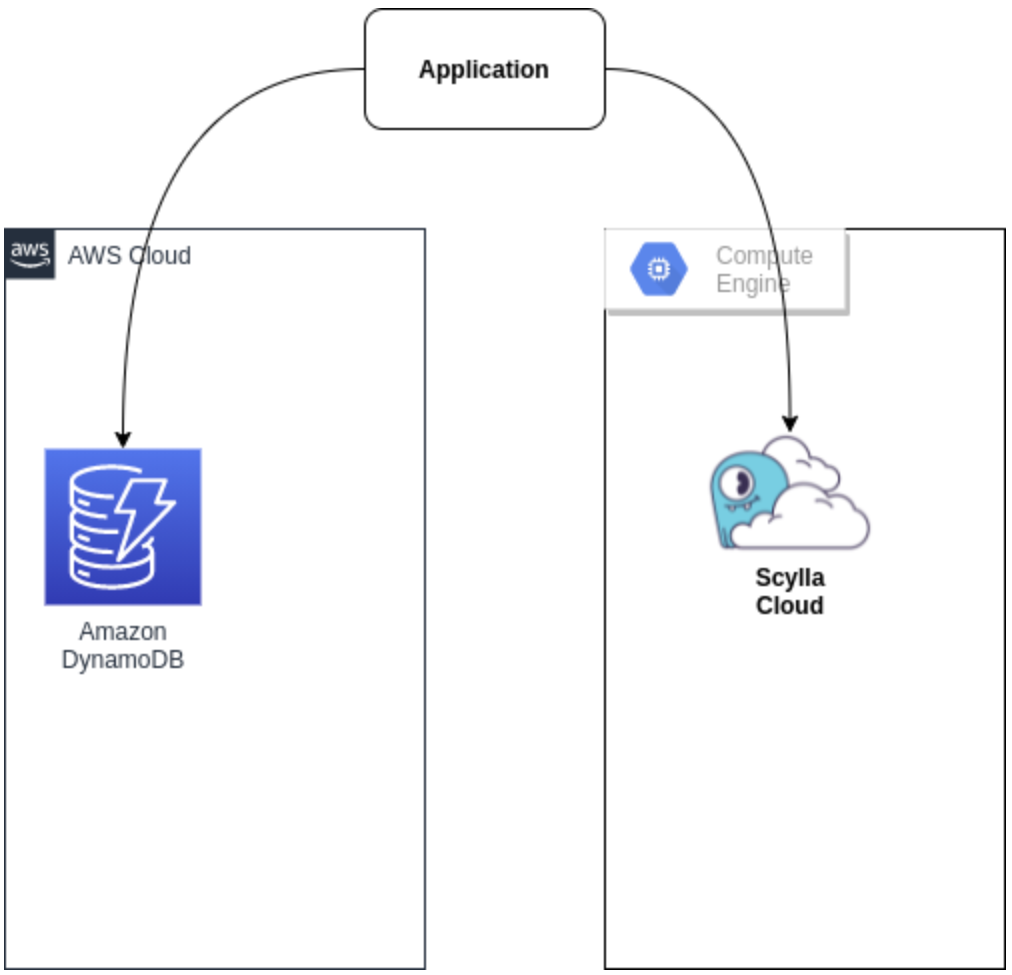
- Dual Writes — the application writes the same event to the two DBs. This can extend to dual reads as well, allowing the application to compare the reads in real time. The disadvantage is the need to update the application with non-trivial logic.
- Consuming DynamoDB Streams to feed the new Database — The disadvantage is the need to set streams for all relevant DynamoDB tables, and the cost associated with it.
Both methods allow you to choose which updates you want to sync in real time. Often one can use Cold Migration for most of the data, and Hot migration for the rest.
Dual Writes
Streams
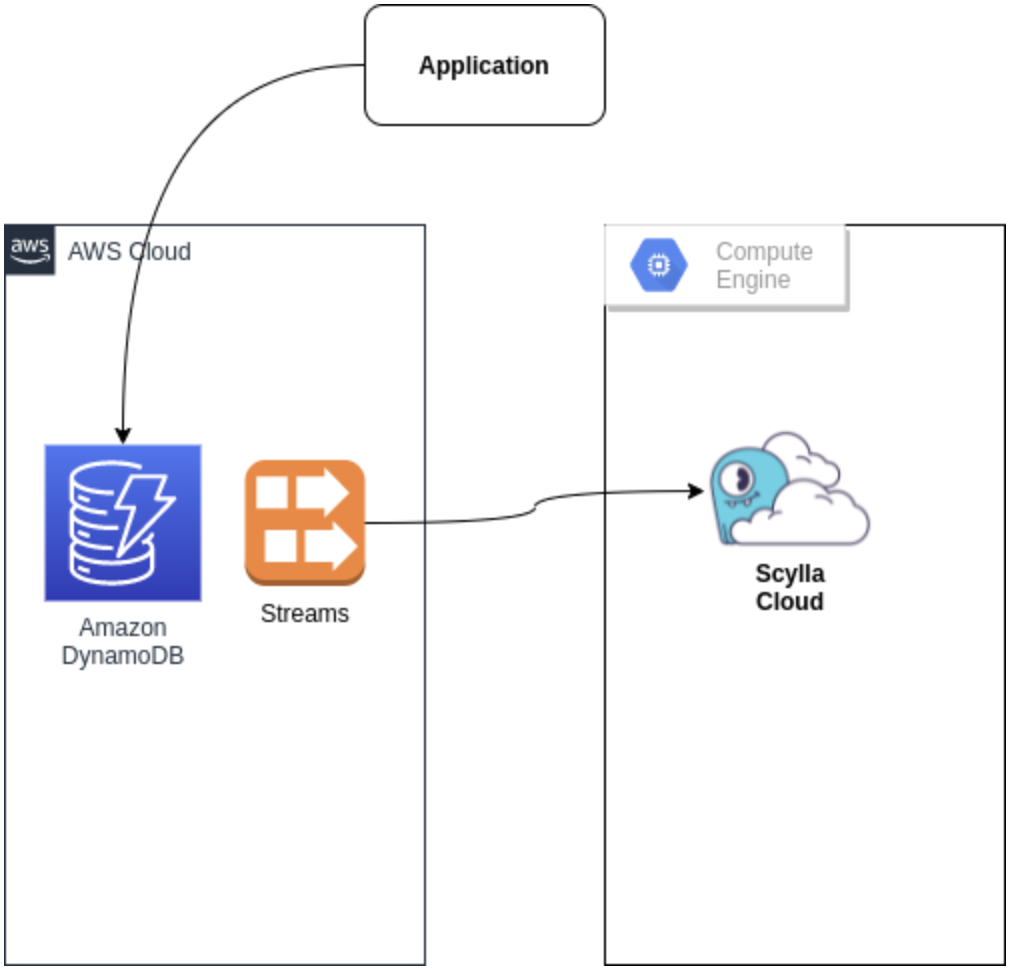
More on using streams to sync real time requests:
Forklifting Historical Data
To upload historical data from AWS DynamoDB to ScyllaDB Alternator we will use the ScyllaDB Migrator. A Spark base tool which can read from AWS DynamoDB (as well as Apache Cassandra, ScyllaDB) and write to ScyllaDB Alternator API.
You will need to configure the source DynamoDB and target ScyllaDB Cluster, and launch A Spark migration job.
Below is an example for such a job from Spark UI.
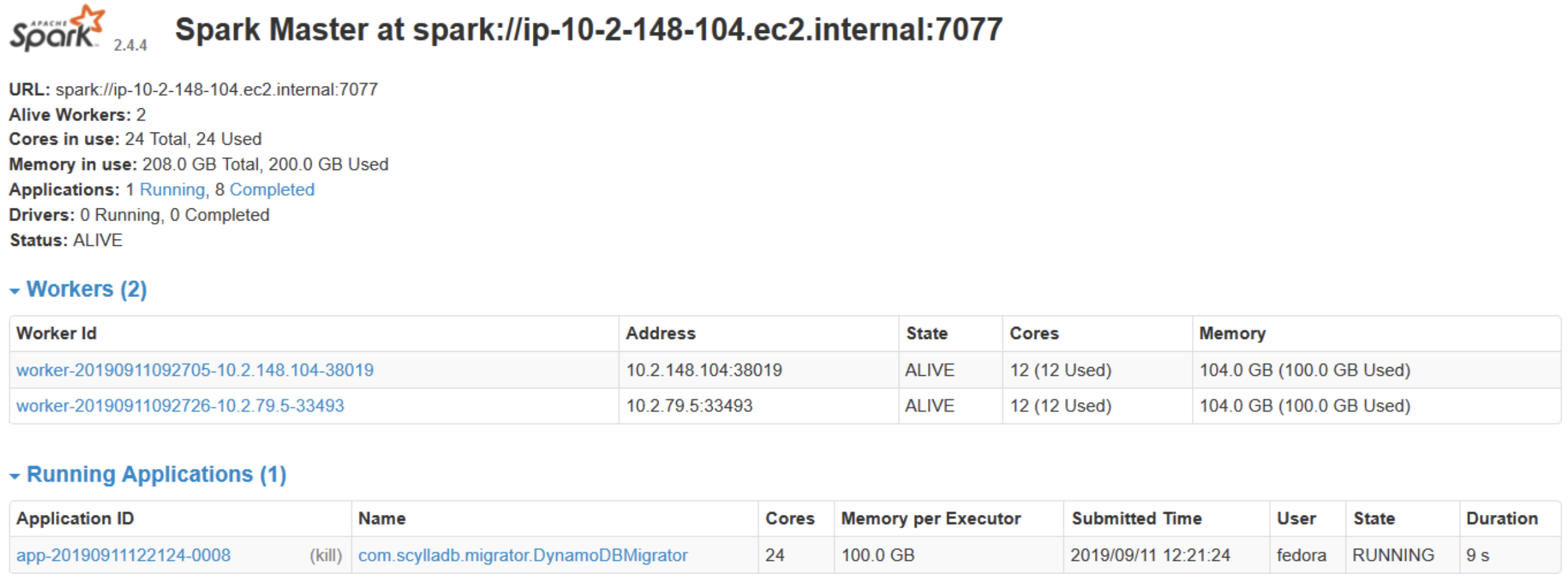
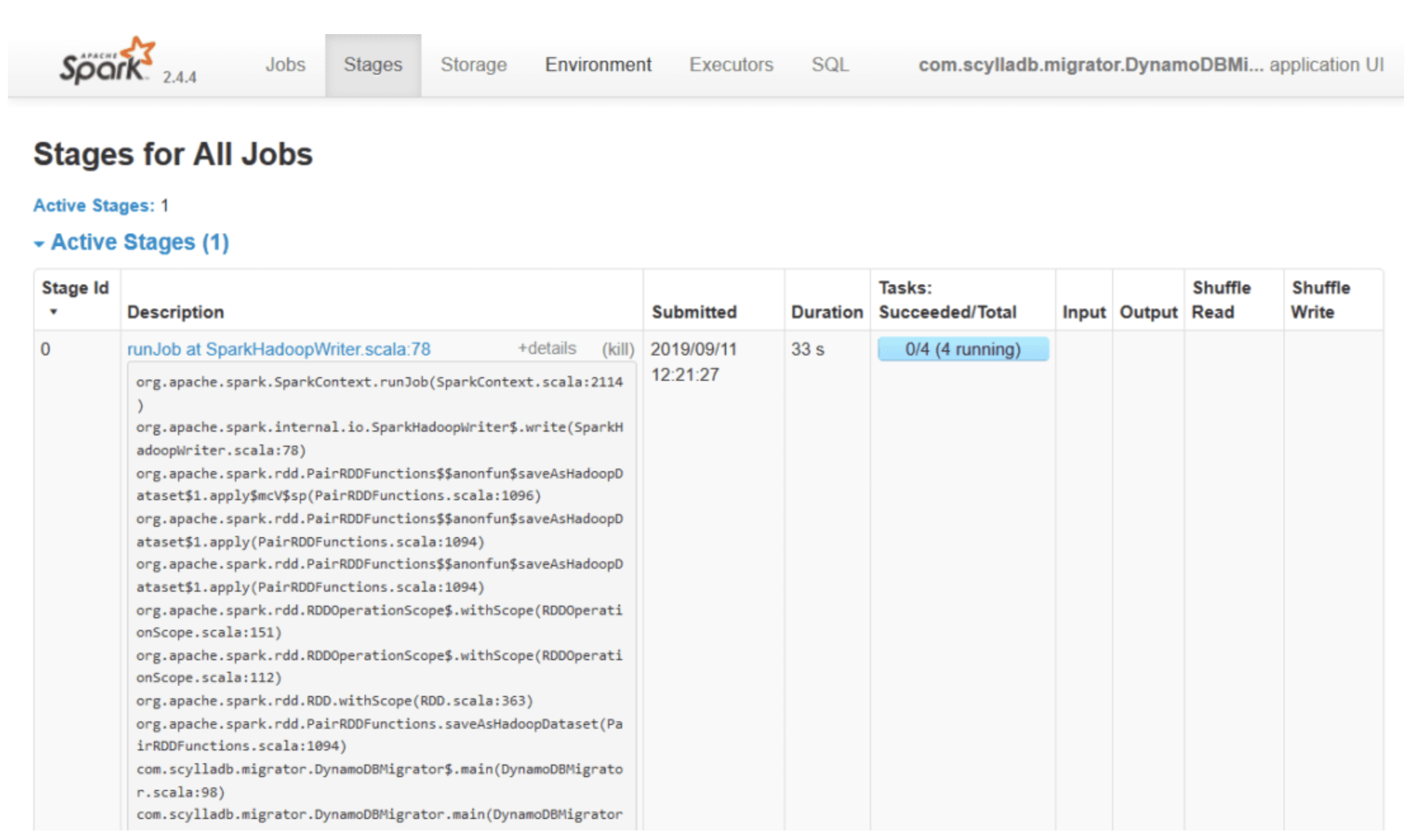
For more details, recommended configuration, and how to validate the migration success see Migrating From DynamoDB To ScyllaDB.
Update Your Application
When ready, update your application to use ScyllaDB Alternator endpoint instead of AWS one.
Checkout the Connect tab in ScyllaDB Cloud (NoSQL DBaaS) cluster view for examples.
Resources