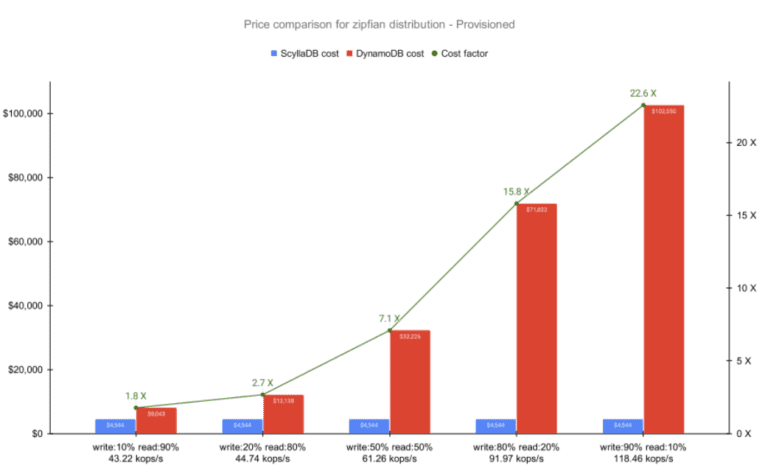
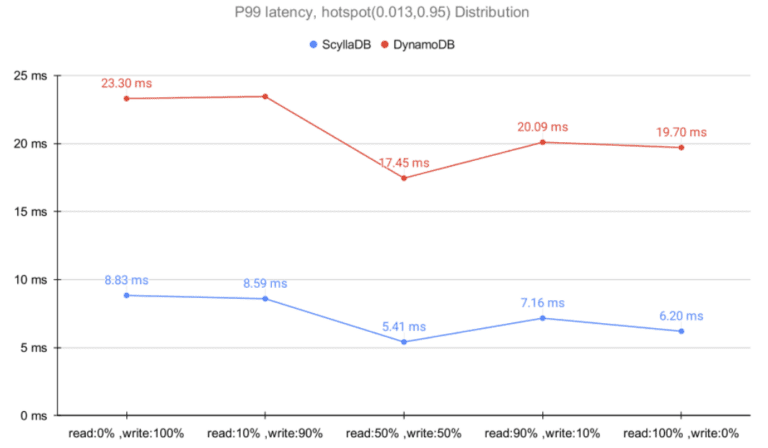
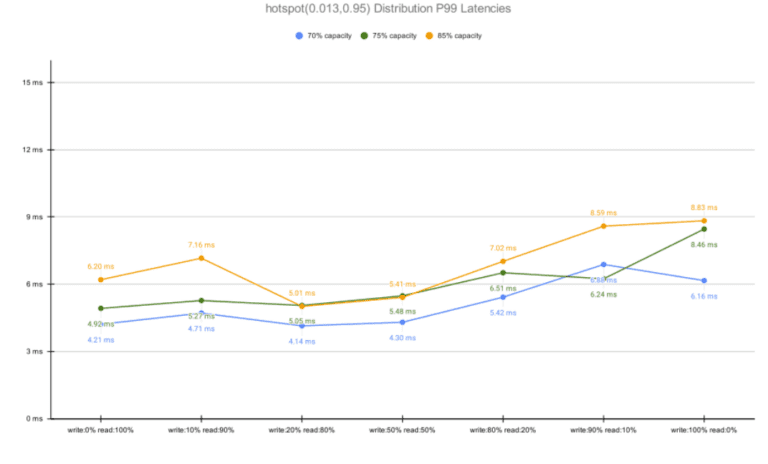
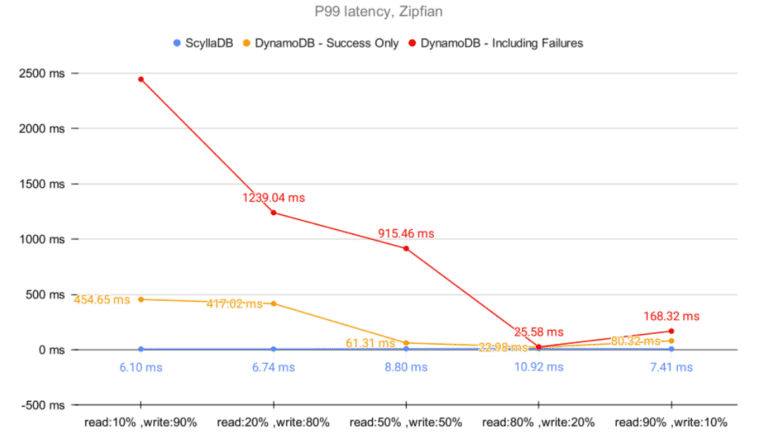
As noted by DeBrie, the Zipfian distribution is likely to create hot partitions, an imbalance introduced by uneven item access from within the database. As hot partitions are a known antipattern, DynamoDB restricts the number of hits on the same partition (documented to be 3,000 RCUs and 1,000 WCUs per partition at the time of writing). Aware of this limitation and of Zipfian’s imbalances, we compared both ScyllaDB and DynamoDB at scale.
Once DynamoDB limits were reached, requests started getting throttled, requiring the application to retry. As a result of the throttling and retries, the YCSB latency became severely impacted. Under some circumstances, we experienced DynamoDB throttling at up to ~2.5 seconds per request – thus preventing the application from accessing the item during that time.
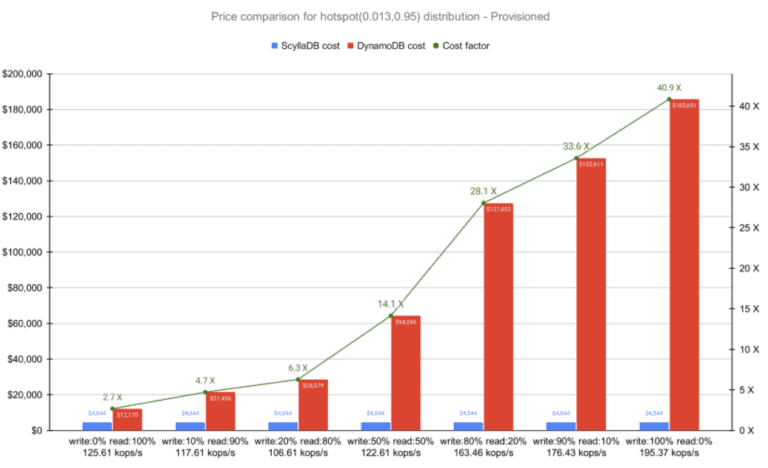
At best, DynamoDB delivered 39.72% of the expected throughput (88.19 good kops/s vs. the target 222 kops/s). At worst, it delivered only 16.22% (20.28 kops/s) of what was purchased (125 kops/s) and supposedly provisioned. Given the documented DynamoDB limitations, some discrepancy is to be expected. However, the magnitude of this unfulfilled throughput was surprising.
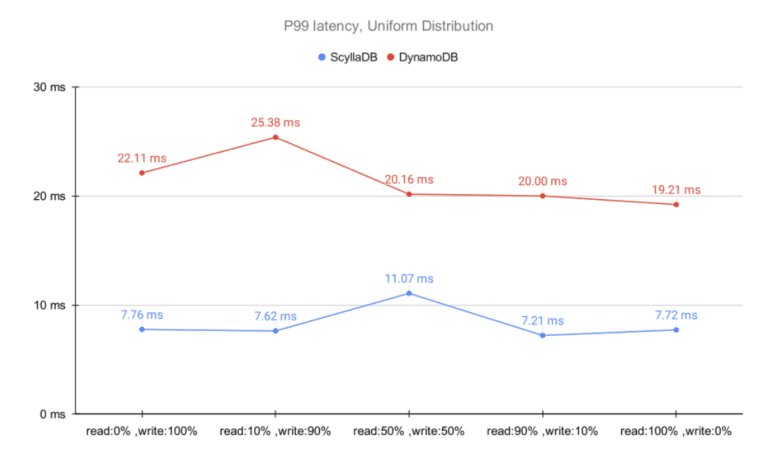
Unlike DynamoDB, ScyllaDB managed to sustain the target throughput without any throttling and still deliver single-digit millisecond latencies. In that regard, ScyllaDB does not impose any hard limits on querying hot partitions. Even though ScyllaDB implements concurrency-limiting mechanisms, frequently accessing popular items will typically benefit from its cache implementation – thus explaining why no failures have been seen during the Zipfian tests. Even then, it is worth underscoring that hot partitions are an antipattern, even for databases like ScyllaDB. Read more about ScyllaDB’s advanced control mechanisms in ScyllaDB in this blog.
The Bottom Line
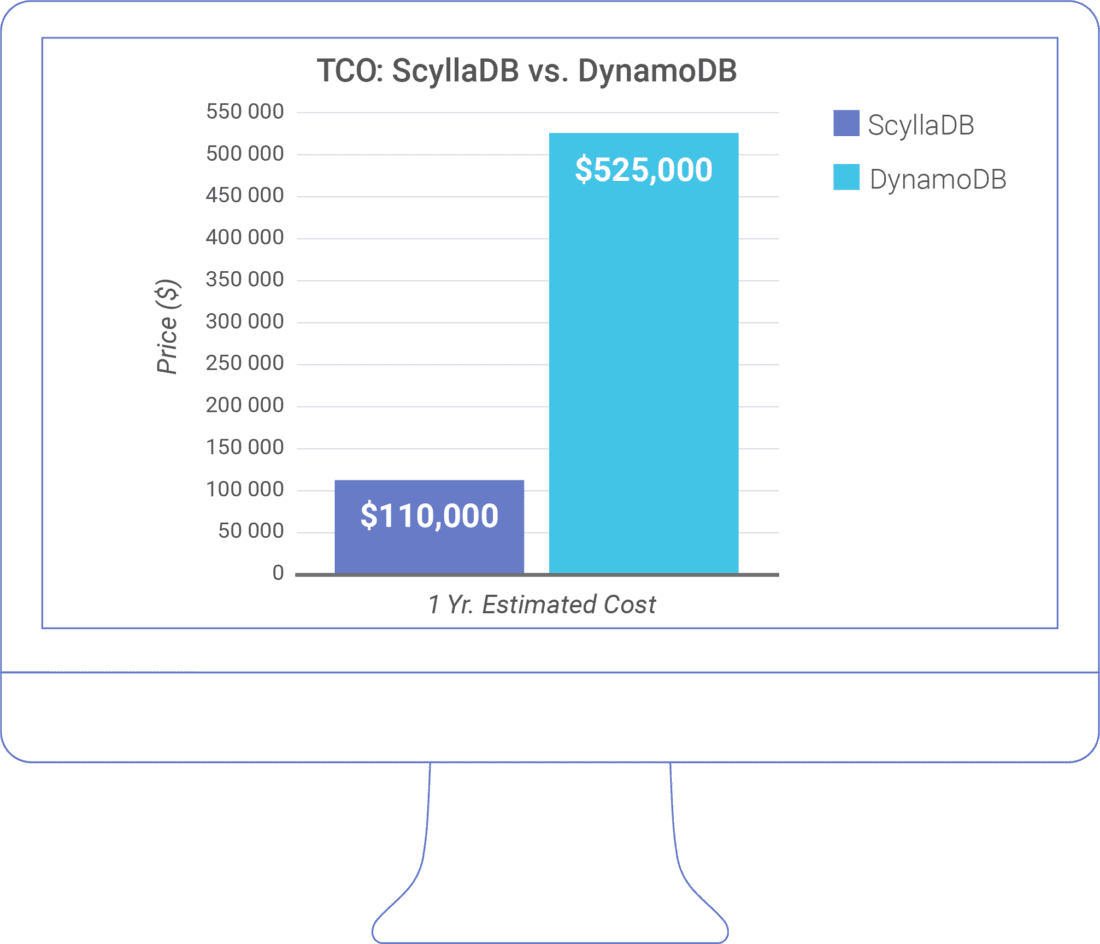
As the results indicate, what might begin at a seemingly reasonable cost can quickly escalate into “bill shock” with DynamoDB – especially as the throughput increases, and particularly with write-heavy workloads. This makes it a suboptimal choice for data-intensive applications anticipating steady or rapid growth. ScyllaDB’s significantly lower costs – a reflection of ScyllaDB taking full advantage of modern infrastructure for high throughput and low latency – make it a more cost-effective solution for data-intensive applications.
ScyllaDB – with its LSM-tree-based storage, unified caching, shard-per-core design, and advanced schedulers – allows you to maximize the advantages of modern hardware, from huge CPU chips to blazing-fast NVMe.
This small-scale benchmark demonstrated how a 57K OPS workload with a 50:50 read/write ratio that cost $4,500/month on-demand on ScyllaDB would cost $30,000 to $200,000/month with DynamoDB. Beyond those cost savings, ScyllaDB sustains 2X peaks and provides 2X-4X better P99 latency. Additionally, it can further reduce latency when idle – or enable spare resources to be shared across multiple tables. For larger workloads spanning 500K-1M OPS and beyond, this can result in a cost saving in the millions – with better performance and fewer query limitations.