This post aims to help selecting the most cost effective and operationally simple configuration of DynamoDB tables.
TLDR; Choosing the Right Mode
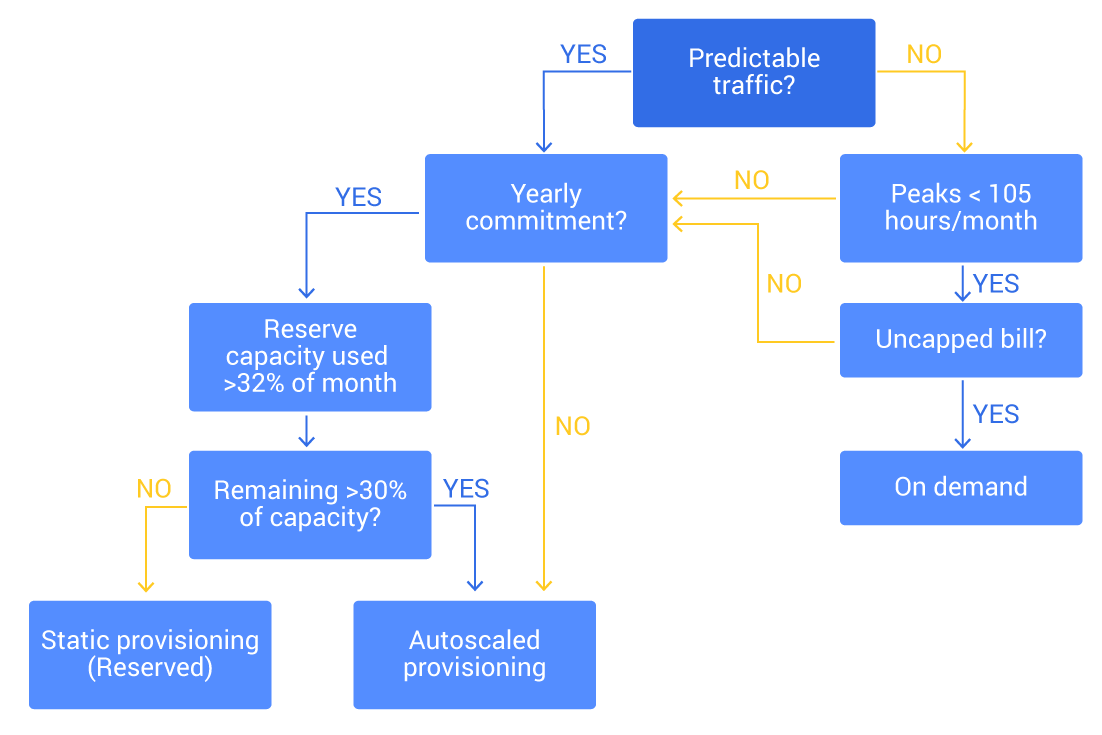
Making sense of the multitude of scaling options available for DynamoDB can be quite confusing, but running a short checklist with a calculator can go a long way to help.
- Follow the flowchart below to decide which mode to use
- If you have historical data of your database load (or an estimate of load pattern), create a histogram or a percentile curve of the load (aggregate on hours used) – this is the easiest way to observe how many reserved units to pre-purchase. As a rule of thumb purchase reservations for units used over 32% of the time when accounting for partial usage and 46% of the time when not accounting for partial usage.
- When in doubt, opt for static provisioning unless your top priority is avoiding being out of capacity – even at extreme costs.
- Configure scaling limits (both upper and lower) for provisioned autoscaling. You want to avoid out-of-capacity during outages and extreme cost in case of rogue overload (DDOS anyone?)
- Remember that there is no upper limit on DynamoDB on-demand billing other than the table’s scaling limit (which you may have requested raising for performance reasons). Make sure to configure billing alerts and respond quickly when they fire.
The Long Version
Before we dive in, it’s useful to be reminded of DynamoDB different service models and their scaling characteristics: DynamoDB tables can be configured to be either “provisioned capacity” or “on demand”, and there’s a cooldown period of 24 hours before you can change again.
On Demand
In this mode, DynamoDB tables are billed by cumulative query count. It doesn’t matter (from a billing perspective) what momentary throughput you have, only how many times you’ve queried the table over the month. You don’t have to worry about what throughput you might have, or plan ahead — or at least, that’s the promise. Unfortunately, DynamoDB scaling isn’t magic and if your load rises too fast, it will be throttled until enough capacity is added. As you are only paying for queries you actually did, and not for capacity, if you only have sporadic load your bill will be quite low; However if you actually have substantial sustained throughput the bill will be very high. For example, sustained 10k reads/sec would cost you around $6,500/month (compared with $1,000 provisioned).
For this reason, AWS recommends using on demand for sporadic load or small serverless applications. Even sporadic load or bursts on demand might be unusable, as it takes upwards of 2.5 hours to reach 40k rps from 0. The solution recommended by AWS to “warm up” the table is to switch to provisioned mode with enough provisioned capacity for your planned load and then switch back to on demand (but if you know in advance what load you need to handle and when, why would you use on demand in the first place?). One point to remember is that on demand tables are never scaled back down – which is very helpful for sporadic peaks.
Other than the aggressive scaling policies on demand employs other optimizations in the structure of its storage which makes it more suitable for bursty loads and dense multitenancy (you didn’t think AWS dedicates machines to you, did you?), which helps AWS compensate for the huge cost of overprovisioning.
Provisioned Capacity
In provisioned mode, AWS bills you by table capacity — although instead of specifying capacity in units of CPUs and disks AWS makes life easier for you and lets you specify your load in a more developer natural form of throughput: reads and writes per second. This is already a tremendous achievement, but unfortunately still requires you to do some capacity planning; this isn’t too bad in practice as capacity can be added and removed pretty quickly — in the span of hours.
Reservations
As with EC2, you have the option to reserve provisioned capacity — pay an upfront partial payment to have reduced price when using that capacity. The only catch, of course, is you need to decide up front how much you want to reserve. The cost savings can be as high as 56% if you can commit to the reservation period (one or three years).
A DynamoDB table can be either on-demand or provisioned, and while you can switch back and forth between the two they cannot be active simultaneously. To use reservations, your table must be in provisioned mode.
Autoscaling Demystified
The function of autoscaling controllers is to try and preserve some function within a band of specified margins. Utilization is the ratio of available capacity (provisioned by the user or by AWS internal on-demand controller) and the capacity consumed by external workload.
Utilization = available capacity / consumed capacity
To do that, the controller will add or remove capacity to reach the target utilization based on the past data it has seen. However, adjusting capacity takes time, and the load might continue changing during that time; The controller is always risking adding too much capacity or too little.
Another way to look at this is that the controller needs to “predict the future” and it’s prediction will be either too aggressive or too meek. Looking at the problem this way, it’s clear that the further into the future the controller needs to predict the greater the errors can be. In practice, this means that controllers need to be tuned to handle only a certain range of changes; a controller that handles rapid large changes will not handle slow changes or rapid small changes well. It also means that changes that are faster than the system response time (the time it takes the controller to add capacity) cannot be handled by the controller at all.
In the case of load spikes that rise sharply within a seconds or minutes all databases must handle the spikes using the already provisioned capacity — so a certain degree of over provisioning must always be kept, possibly by a large amount if the anticipated bursts are rapid and large. DynamoDB offers two basic scaling controllers: the aggressive on-demand mode and the more tame provisioned autoscaling.
On-Demand Scaling
DynamoDB on-demand under the hood automatically scales to double the capacity of the largest traffic peak in the last 30 minutes time window — anything above that and you get throttled. In other words, it always provisions 2x; So if you had a peak of 50,000 qps, DynamoDB will autoscale to support 100,000 qps — and it never scales back down. This type of exponential scaling algorithm is very aggressive and suitable for workloads that change fairly quickly. However, the price of aggressiveness of the algorithm is massive overprovisioning — the steady state can be close to 0% average utilization since it operates on peaks, which is very expensive. Although the pricing model of on demand is pay-per-query and not per capacity, which makes 0% utilization essentially free, the high overprovisioning cost is shoved into the per-query price making on demand extremely expensive at scale or sustained throughput.
Provisioned Autoscaling
This is AWS’ latest offering which utilizes their Application Auto Scaling services to adjust the provisioned capacity of DynamoDB tables. The controller uses a simple algorithm which allocates capacity to keep a certain utilization percentage. It will respond fairly quickly to capacity increase, but will be very pessimistic when reducing capacity and will wait relatively long (15 minutes) before adjusting it downward — a reasonable tradeoff of availability over cost. Unlike on demand mode it operates on 1 minute average load and not peaks of 30 minutes time window — which means it both responds faster and does not does not overallocate as much. You can get aggressive scaling behavior similar to on-demand by simply setting the utilization target to 0.5.
The Limits of Autoscaling
Autoscaling isn’t magic — it’s simply a robot managing capacity for you. But the robot has two fundamental problems: it can only add capacity so fast, and its knowledge about the traffic patterns is very limited. This means that autoscaling cannot deal with unexpected large changes in capacity. Nor can it be optimal when it comes to cost savings.
As a great example of that, let’s look at this AWS DynamoDB autoscaling blog post. In it AWS used provisioned autoscaling to bring the cost of DynamoDB workload from $1,024,920 static provisioning cost to $708,867 variable capacity cost. While a 30% cost reduction isn’t something that should be discounted, it also shows the limits of autoscaling: even with a slowly changing workload which is relatively easy to handle automatically, they only saved 30%. Had they used static provisioned capacity with 1 year reservation for the entire workload, the cost would have gone down to $473,232, a 53.8% cost reduction!
Even when combining autoscaling with reserved capacity, reserving units that are used more than 46% of the time (which is when reservation becomes cheaper) AWS was only able to bring down the cost to $460,327 — a negligible cost saving compared to completely reserved capacity — and they needed to know in the traffic pattern in advance. Is a cost saving of 2.7% worth moving your system from static capacity to dynamic, risking potential throttling when autoscaling fails to respond fast enough?
Given that both scenarios require capacity planning and good estimation of the workload and also given that autoscaling is not without peril, I would argue “no” — especially as using completely static 3 year reservation would bring the cost down further to $451,604.
| DynamoDB | Statically Provisioned | WCUs: 2,000,000 RCUs: 800,000 |
$1,024,920 |
| Auto scaling | Variable capacity | $708,867 | |
| Blended auto scaling and one-year reserved capacity | Variable capacity | $460,327 | |
| One year reserved capacity | WCUs: 2,000,000 RCUs: 800,000 |
$473,232 | |
| Three-year reserved capacity | WCUs: 2,000,000 RCUs: 800,000 |
$451,604 |
The Perils of Autoscaling
We’ve discussed above how automatic controllers are limited to a certain range of behaviours and must be tuned to err either on the side of caution (and cost) or risk overloading the system — this is common knowledge in the industry. What is not discussed as much is the sometimes catastrophic results of automatic controllers facing situations that are completely out of scope of their local and limited knowledge: namely, their behavior during system breakdown and malfunctions.
When Slack published a post mortem for their January 4th outage they described how autoscaling shut down critical parts of their infrastructure in response to network issues, further escalating incidents and causing a complete outage. This is not as rare as you think and has happened numerous times to many respectable companies — which is why autoscaling is often limited to a predetermined range of capacity regardless of the actual load, further limiting potential cost savings.
Ask yourself, are you willing to risk autoscaling erroneously downscaling your database in the middle of an outage? This isn’t so far fetched given the load anomalies that happen frequently during incidents. It’s important to note that this isn’t an argument for avoiding autoscaling altogether, only to use it cautiously and where appropriate.
Summary: the Cost of Variance
A recurring theme in performance and capacity engineering is the cost of variance. At scale we can capitalize on averaging effects by spreading out variance between many different parties — which is basically how AWS is able to reduce the cost of infrastructure to its clients, shifting capacity between them as needed. But the higher and more correlated the variance, the less averaging effect we have, and the cost of variance can only be masked to some degree. AWS knows this, and offers its customers significant discounts for reducing the variance and uncertainty of capacity utilization by purchasing reserved capacity.
In AWS’ own example, autoscaling failed to bring significant cost savings compared to capacity planning and upfront reservations — but that does not mean autoscaling is completely useless. Indeed there are traffic patterns and situations in which autoscaling can be beneficial — if only to allow operators to sleep well at night when unexpected loads occur.
So when is autoscaling useful? If the load changes too quickly and violently, autoscaling will be slow to respond. If the change in load has low amplitude, adjusting capacity is insignificant.
Autoscaling is most useful when:
- Load changes have high amplitude
- The rate of change is in the magnitude of hours
- The load peak is narrow relative to the baseline
Even if your workload is within those parameters, it is still necessary to do proper capacity planning in order to cap and limit the capacity that autoscaling manages, or else you are risking a system run amok.
Autoscaling is no substitute for capacity planning and in many cases will cost more than a properly tuned and sized system. After all, if automation alone could solve our scaling problems, why are we still working so hard?
Want to Do Your Capacity Planning with Style?
If you have found this article interesting, the next step is to read our article about Capacity Planning with Style. Learn how to get the most out of our ScyllaDB Cloud Calculator which you can use to compare provisioning and pricing work across various cloud database-as-a-service (DBaaS) offerings, from ScyllaDB Cloud (NoSQL DBaaS) to DynamoDB to DataStax Astra or Amazon Keyspaces.