Update: We now have a full masterclass on NoSQL migration. You can watch it (free + on-demand) here: NoSQL Data Migration Masterclass. And we also have a new blog on the ScyllaDB Spark Migrator.
Last year, we introduced the ability to migrate DynamoDB tables to ScyllaDB’s Dynamo-compatible interface — Alternator. Using the ScyllaDB Migrator, this allows users to easily transfer data stored in DynamoDB into ScyllaDB and enjoy reduced costs and lower latencies.
Transferring a snapshot of a live table is usually insufficient for a complete migration; setting up dual writes on the application layer is required for a safe migration that can also be rolled back in the face of unexpected errors.
Today, we are introducing the ability to perform live replication of changes applied to DynamoDB tables into Alternator tables after the initial snapshot transfer has completed. This feature is based on DynamoDB Streams and uses Spark Streaming to replicate the change data. Read on for a description of how this works and a short walkthrough!
DynamoDB Streams
Introduced in 2014, DynamoDB Streams can be enabled on any DynamoDB table to capture modification activities into a stream that can be consumed by user applications. Behind the scenes, a Kinesis stream is created into which modification records are written.
For example, given a DynamoDB table created using the following command:
aws dynamodb create-table \
--table-name migration_test \
--attribute-definitions AttributeName=id,AttributeType=S AttributeName=version,AttributeType=N \
--key-schema AttributeName=id,KeyType=HASH AttributeName=version,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5We can enable a DynamoDB Stream for the table like so:
aws dynamodb update-table \
--table-name migration_test \
--stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES{
"TableDescription": {
...
"StreamSpecification": {
"StreamEnabled": true,
"StreamViewType": "NEW_AND_OLD_IMAGES"
}
}
}DynamoDB will now enable the stream for your table. You can monitor that process using describe-stream:
export STREAM_ARN=$(aws dynamodb describe-table --table-name migration_test | jq -r ".Table.LatestStreamArn")
aws dynamodbstreams describe-stream --stream-arn $STREAM_ARN{
"StreamDescription": {
"StreamArn": "arn:aws:dynamodb:eu-west-1:277356164710:table/migration_test/stream/2020-08-19T19:26:06.164",
"StreamLabel": "2020-08-19T19:26:06.164",
"StreamStatus": "ENABLING",
"StreamViewType": "NEW_IMAGE",
"CreationRequestDateTime": "2020-08-19T22:26:06.161000+03:00",
"TableName": "migration_test",
...
}
}Once the StreamStatus field switches to ENABLED, the stream is created and table modifications (puts, updates, deletes) will result in a record emitted to the stream. Because we chose NEW_AND_OLD_IMAGES for the stream view type, the maximal amount of information will be emitted for every modification (the IMAGE term refers to the item content): the OldImage field will contain the old contents of the modified item in the table (if it existed), and the NewImage field will contain the new contents.
Here’s a sample of the data record emitted upon item update:
{
"awsRegion": "us-west-2",
"dynamodb": {
"ApproximateCreationDateTime": 1.46480527E9,
"Keys": {
"id": {"S": "id1"},
"version": {"N": "10"}
},
"OldImage": {
"id": {"S": "id1"},
"version": {"N": "10"},
"data": {"S": "foo"}
},
"NewImage": {
"id": {"S": "id1"},
"version": {"N": "10"},
"data": {"S": "bar"}
},
"SequenceNumber": "400000000000000499660",
"SizeBytes": 41,
"StreamViewType": "NEW_AND_OLD_IMAGES"
},
"eventID": "4b25bd0da9a181a155114127e4837252",
"eventName": "MODIFY",
"eventSource": "aws:dynamodb",
"eventVersion": "1.0"
}ScyllaDB Migrator and DynamoDB Streams
The functionality we are introducing today is aimed at helping you perform live migrations of DynamoDB Tables into your ScyllaDB deployment without application downtime. Here’s a sketch of how this works:
- The migrator, on start-up, verifies that the target table exists (or creates it with the same schema as the source table) and enables the DynamoDB Stream of the source table. This causes inserts, modifications and deletions to be recorded on the stream;
- A snapshot of the source table is transferred from DynamoDB to ScyllaDB;
- When the snapshot transfer completes, the migrator starts consuming the DynamoDB Stream and applies every change to the target table. This runs indefinitely until you stop it.
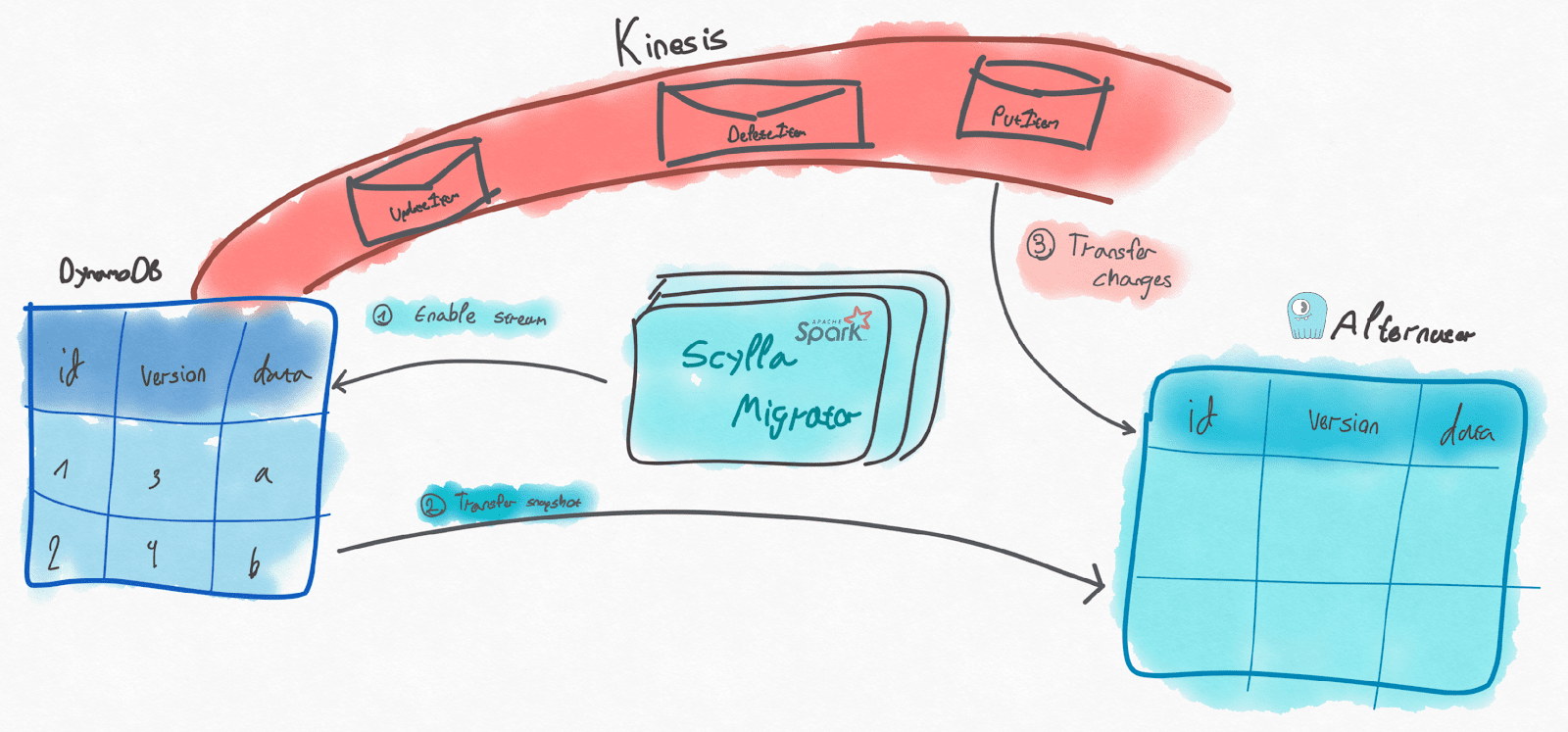
The order of steps in this process guarantees that no changes will be lost in the transfer. During step 5, old changes might be applied to the target table, but eventually the source and target tables should converge.
In contrast to our example before, which used NEW_AND_OLD_IMAGE for the stream type, the Migrator uses the NEW_IMAGE mode, as we always apply the modifications without any conditions on the existing items.
There’s one important limitation to note here: DynamoDB Streams have a fixed retention of 24 hours. That means that the snapshot transfer has to complete within 24 hours, or some of the changes applied to the table during the snapshot transfer might be lost. Make sure that you allocate enough resources for the migration process for it to complete sufficiently quickly. This includes:
- Provisioned read throughput (or auto-scaling) on the source DynamoDB table;
- Sufficient executors and resources on the Spark cluster;
- Sufficient resources on the ScyllaDB cluster.
Walkthrough
Let’s do a walkthrough on how this process is configured on the ScyllaDB Migrator. First, we need to configure the source section of the configuration file. Here’s an example:
source:
type: dynamodb
table: migration_test
credentials:
accessKey:
secretKey:
region: us-west-2
scanSegments: 32
readThroughput: 1
throughputReadPercent: 1.0
maxMapTasks: 8Because we’re dealing with AWS services, authentication must be configured properly. The migrator currently supports static credentials and instance profile credentials. Role-based credentials (through role assumption) will be supported in the future. Refer to the previous post about DynamoDB integration for more details about the rest of the parameters. They are also well-documented in the example configuration file supplied with the migrator.
Next, we need to configure a similar section for the target table:
target:
type: dynamodb
table: mutator_table
endpoint:
host: http://scylla
port: 8000
credentials:
accessKey: empty
secretKey: empty
scanSegments: 8
streamChanges: truePretty similar to the source section, except this time, we’re specifying a custom endpoint that points to one of the ScyllaDB nodes’ hostname and the Alternator interface port. We’re also specifying dummy static credentials as those are required by the AWS SDK. Finally, note the streamChanges parameter. This instructs the migrator to set up the stream and replicate the live changes.
Launching the migrator is done with the spark-submit script:
spark-submit --class com.scylladb.migrator.Migrator \
--master spark://spark-master:7077 \
--conf spark.driver.host=spark-master \
--conf spark.scylla.config=./config.yaml.scylla
scylla-migrator-assembly-0.0.1.jarAmong the usual logs printed out while transferring data using the migrator, you should see the following lines that indicate that the migrator is setting up the DynamoDB Stream:
20/08/19 19:26:05 INFO migrator: Source is a Dynamo table and change streaming requested; enabling Dynamo Stream
20/08/19 19:26:06 INFO DynamoUtils: Stream not yet enabled (status ENABLING); waiting for 5 seconds and retrying
20/08/19 19:26:12 INFO DynamoUtils: Stream enabled successfullyNote that the migrator will abort if the table already has a stream enabled. This is due to the previously mentioned 24-hour retention imposed on DynamoDB Streams; we cannot guarantee the completeness of the migration if the stream already exists, so you’ll need to disable it.
Once the snapshot transfer has finished, the migrator will indicate that:
20/08/19 19:26:18 INFO migrator: Done transferring table snapshot. Starting to transfer changesThat will be followed by repeatedly printing out the counts of operation types that will be applied to the target table. For example, if there’s a batch of 5 inserts/modifications and 2 deletions, the following table will be printed:
+---------------+-----+
|_dynamo_op_type|count|
+---------------+-----+
| DELETE | 2|
| MODIFY | 5|
+---------------+-----+You may monitor the progress of the Spark application on the Streaming tab of the Spark UI (available at port 4040 of the machine running the spark-submit command on a client-based submission or through the resource manager on a cluster-based submission).
As mentioned, the migrator will continue running indefinitely at this point. Once you are satisfied with the validity of the data on the target table, you may switch over your application to write to the ScyllaDB cluster. The DynamoDB Stream will eventually be drained by the migrator, at which point no more operations will be printed on the logs. You may then shut it down by hitting Ctrl-C or stopping the receiver job from the UI.
A Test Run
We’ve tested this new functionality with a load generation tool that repeatedly applies random mutations to a DynamoDB table on a preset number of keys. You may review the tool here: https://github.com/iravid/migrator-dynamo-mutator.
For our test run, we’ve used a dataset of 10,000 distinct keys. The tool applies between 10 and 25 mutations to the table every second; these mutations are item puts and deletions.

While the tool is running, we started the migrator, configured to transfer the table and its changes to ScyllaDB. As we’ve explained, the migrator starts by enabling the stream, scanning the table and transferring a snapshot of it to ScyllaDB.
![]()
Once the initial transfer is done, the migrator starts transferring the changes that have accumulated so far in the DynamoDB Stream. It takes a few polls to the stream to start, but eventually we see puts and deletions being applied.

Once the migrator has caught up with the changes, indicated by the smaller number of changes applied in each batch, we move the load generation tool to the next step: it stops applying mutations to the source table, and loads the contents of both tables into memory for a comparison. Because we’re applying both deletions and puts, it’s important to perform the comparison in both directions – the table contents should be identical. Luckily, this is the case:

The tool checks that the set-wise difference between the item sets on DynamoDB (labelled as remote) and ScyllaDB (labelled as local) are both empty, which means that the contents are identical.
Summary
We’ve seen in this post how you may transfer the contents of live DynamoDB tables to ScyllaDB’s Alternator interface using the ScyllaDB Migrator. Please give this a try and let us know how it works!
LEARN MORE ABOUT SCYLLA ALTERNATOR
LEARN MORE ABOUT THE SCYLLA MIGRATOR