With the release of ScyllaDB Open Source 4.0, we’ve introduced a set of noteworthy production-ready new features, including a DynamoDB-compatible API that lets you to take your locked-in DynamoDB workloads and run them anywhere, a more efficient implementation of Lightweight Transactions (LWT), plus improved and new experimental features such as Change Data capture (CDC), which uses standard CQL tables.
4.0 is the most expansive release of our open source NoSQL database we’ve ever done. After all, it’s rare to release a whole new database API in General Availability (GA), and our Alternator project has finally graduated. In 4.0 we also reach full feature parity with the database of our roots: LWT graduated from experimental mode and is now ready for prime time. Just yesterday, ScyllaDB was tested with Kong, the cloud native API gateway, which relies upon LWT, and it worked as flawlessly as we hoped. This single Github issue of Kong integration shows the long journey we’ve completed to reach full feature parity. The issue was opened in 2015, just as we launched our company out of stealth mode. From that point forward, integration waited for counters, ALTER TABLE, materialized views, indexes, Cassandra Cluster Manager (CCM) integration and finally LWT.
In this blog, I’d like to look at the enhancements we’ve made to our technology from 3.0 to 4.0, compare where we are today versus Cassandra 4.0 and DynamoDB, and touch on the future.
Journey from 3.0 to 4.0
We released 3.0 on January 17, 2019. The team had been burning the midnight oil to deliver many vital features such as the “mc” SSTable format. After that we put in extensive stabilization work and we relaxed our upstream master branch testing, which caused us a great deal of stabilization time before we delivered our 3.1 release on October 15, 2019. After that, we shifted more focus upstream, so more testing, unlocking the debug release mode, which turned out to be instrumental to catching bugs early (thanks Benny Halevy and Rafael Avila de Espindola) on our nightly master branch. Releases 3.2 (Jan 21), 3.3 (March 24) and now 4.0 were subsequently published. Today we’re able to meet our goal of a monthly release cadence (with minimum misses). Apart from achieving better release predictability, our new processes increase the quality of our releases and reduce the bug hunt churn.
During the 3.0 to 4.0 development period, 6,242 commits were contributed to ScyllaDB by 80 unique developers. That’s a pace of 13 commits per day. This pace, both in the quality and quantity, was what allowed us to reach parity with Apache Cassandra, a very good project with many adopters but, surprisingly, far fewer core committers. A git log analysis over the past 5 years verifies this, as you’ll see below. Top is Cassandra, bottom is ScyllaDB, the number of commits is on the left, and number of authors on the right. (Note that the charts are not to the same scale. Cassandra peaks at just over 500 commits and now averages less than 100 a month; the peak for ScyllaDB was over 900 and averages between 200 to 400 a month.)


We invested in a mix of performance, functionality and usability features. As our adoption continues to grow, we’re moving our emphasis from performance to usability and functionality.
Some of our key functionality enhancements over this period included:
- Lightweight transactions (LWT)
- Local secondary indexes (next to our global indexes)
- Change Data Capture (CDC, in experimental mode)
- User Defined Functions (using Lua, in experimental mode)
- IPv6 support
- Various query improvements: CQL per partition limit, allow filtering enhancements, CQL LIKE operator.
Usability enhancements include:
- Large Cell / Collection Detector
- Nodetool TopPartitions
- Relocatable packages
Performance enhancements include:
- Row-level repair
- Support for AWS i3en servers with up to 60TB/node
- CQL BYPASS CACHE
- Faster network polling – IOCB_CMD_POLL
(Another contribution by ScyllaDB to the Linux kernel) - Improved CQL server admission control
Outside of ScyllaDB CQL core our 4.0 release also includes other game changing new features. I’ll take a bit of time to describe them here.
DynamoDB-Compatible API (Project Alternator)
Project Alternator is an open-source implementation for an Amazon DynamoDB™-compatible API. The goal of this project was to deliver an open source database alternative to Amazon’s DynamoDB, deployable wherever a user would want: on-premises, on other public clouds like Microsoft Azure or Google Cloud Platform, or still on AWS (for users who wish to take advantage of other aspects of Amazon’s market-leading cloud ecosystem, such as the high-density i3en instances).
As this is a full database API, I won’t cover it here. Go give it a try on Docker, Kubernetes or ScyllaDB Cloud.
ScyllaDB Operator for Kubernetes (Beta)
Kubernetes has become the go-to technology for the cloud devops community. It allows for the automated provisioning of cloud-native containerized applications, supporting the entire lifecycle of deployment, scaling, and management. ScyllaDB Operator, created by Yannis Zarkadas and championed by Henrik Johansson, is our extension to enable the management of ScyllaDB clusters. It currently supports deploying multi-zone clusters, scaling up or adding new racks, scaling down, and monitoring ScyllaDB clusters with Prometheus and Grafana.
ScyllaDB and the Rest of the Pack
Now that we have feature parity with Cassandra, and our DynamoDB-compatible API is production ready, let’s compare value.
We’ll start by repeating one of our previous benchmarks that compares ScyllaDB 2.2 vs Cassandra 3.11. In this benchmark, we defined an application with an SLA of 10 msec for its P99 reads and ran a mixed workload of 100k, 200k, 300k OPS and compared the cost and SLA violations. We have repeated this comparison with ScyllaDB 4.0. Previously, 4 ScyllaDB servers of i3.metal met the SLA for 100k, 200k and were slightly above the latency to meet 300k OPS.
40 C* 3.11 servers running on i3.4xl were used in our initial benchmark. We selected i3.4xl for Cassandra since Cassandra doesn’t scale vertically well, thus it would have been a waste of machine time and money to use machines that were too large. Back then, the 40 i3.4xl servers, which cost 2.5x more than the 4 i3.metal servers, could meet the SLA only in the 100k case.
Not only did ScyllaDB 4.0 easily make the grade with 300k OPS with P99 read of 7msec, we tried 600k and achieved P99 of 12msec. So ScyllaDB 4.0 is twice as cost effective as ScyllaDB 2.2. It means that Cassandra, even with the most appropriate machine type, will be 5x more expensive, its latency will be 10x worse, and it will be much harder to manage.
We tested Cassandra 4.0 but had issues; naturally, it is still in alpha. However, a smaller scale comparison between Cassandra 3.11 and Cassandra 4.0 did not reveal performance differences. We will share those results in depth at a later date.
Elasticity Results
In order to be agile and budget friendly, a horizontally scalable database needs to expand on demand. We added a 5th node to our 4-node i3.metal cluster and measured the time it took it to stream the data to the new node. Each of the four nodes had 7.5TB, and it’s quite a challenge to stream the data as fast as possible while still meeting a 10 msec P99 read latency goal. ScyllaDB managed to complete the streaming in just over an hour while handling 300k OPS of mixed workload. Streaming pace was 1.5GB/s (12gbps).
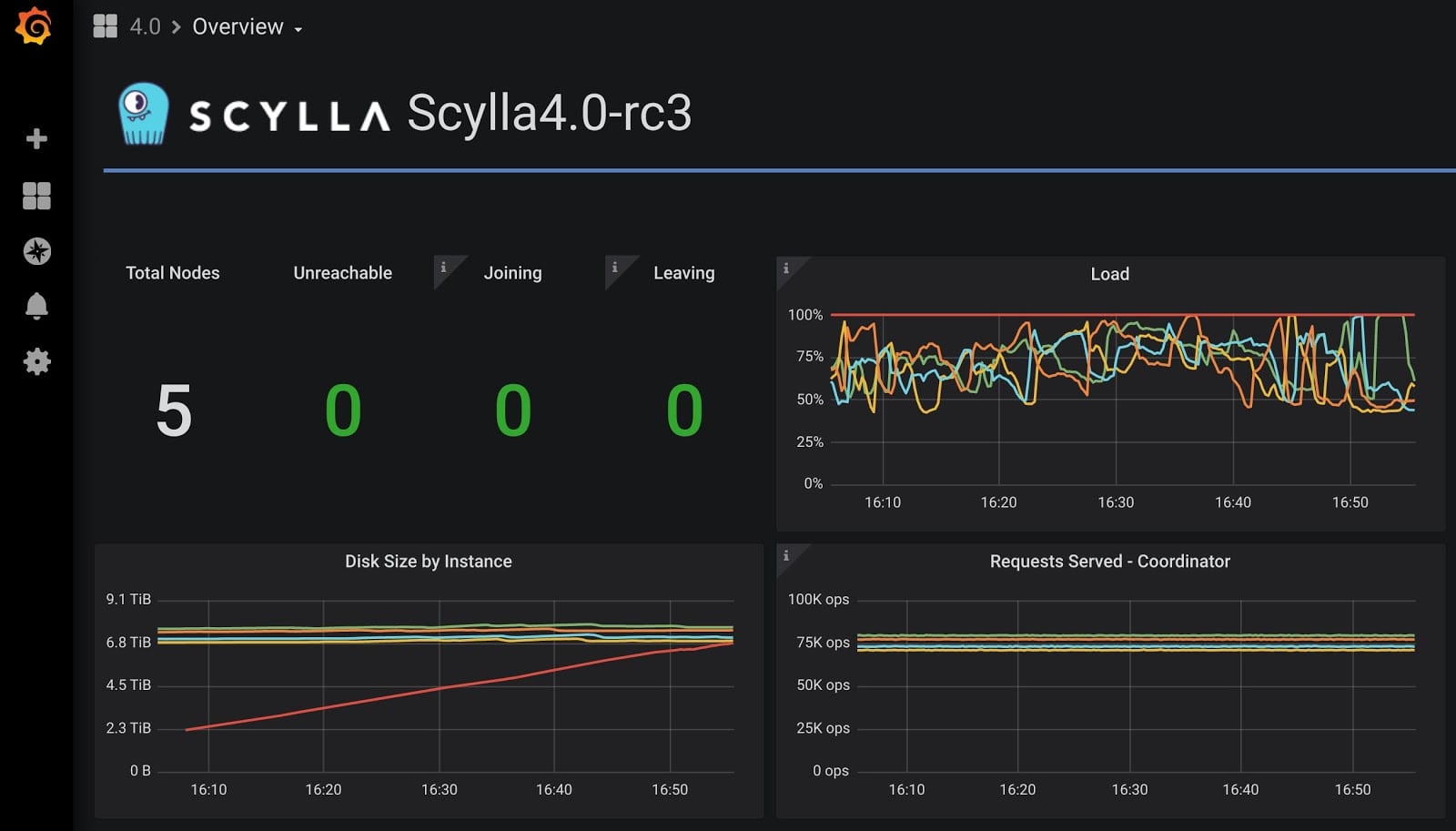
If you dig into our Grafana dashboards, you will observe all sorts of activities: The commitlog bandwidth, streaming scheduler share, query class IO bandwidth, number of active compactions (tens to hundreds), queue sizes, and more. Our CPU and IO schedulers are responsible for prioritizing queries over streaming and compactions and keeping these balance/queue sizes dynamic.
It is possible to observe that the new joining node is capped by CPU load, originated from compaction. Future releases of ScyllaDB will automatically halt the compaction while streaming, since more and more data arrives to the node, and will further accelerate streaming.
As the 40 nodes of Cassandra suffered from P99 latency of 131 msec with 300k OPS, we estimate that Cassandra will need around 60-80 nodes of i3.4xl to meet the latency target for 300k OPS. If you need to grow the cluster by 25% as ScyllaDB has, that’s an additional 15 machines you’ll need. Since Cassandra (and ScyllaDB, too, but not for long) adds a single node at a time, it will take 1-2 hours per node multiplied by 15 nodes. That’s over 24 hours! Not only is it 24x slower than ScyllaDB, you wouldn’t have the capacity in place to handle variable spikes. That means you’d have to overprovision your Cassandra cluster from the get-go, thus incurring even greater costs.
ScyllaDB 4.0 has a new experimental feature called repair-based-node-operation. Asias He implemented streaming for node addition and node decommission using our repair algorithm (better than a merkle tree). Repair is the process of syncing our replicas. It can run on different sets of replicas and is supposed to run iteratively. This allows us to offer restartable node operations. That means if you started to add/remove a node, and as an admin, and you want to pause, restart the server, etc., it’s now possible to do so without starting the streaming from scratch.
How DynamoDB Compares with ScyllaDB 4.0
DynamoDB is known for its elasticity, ease of use and also its high price. Let’s look at how much a 600k OPS mixed workload costs on DynamoDB and assume the way to scale there is simple (although it is not the case, as many blogs indicate).
ScyllaDB Cloud running 4 i3.metal servers costs $48/hour on demand and around $32/hour with an annual commitment.
DynamoDB has multiple pricing options. Let’s fit the best one for the right use cases. If you have a completely spiky workload, very unexpected, like this pattern:
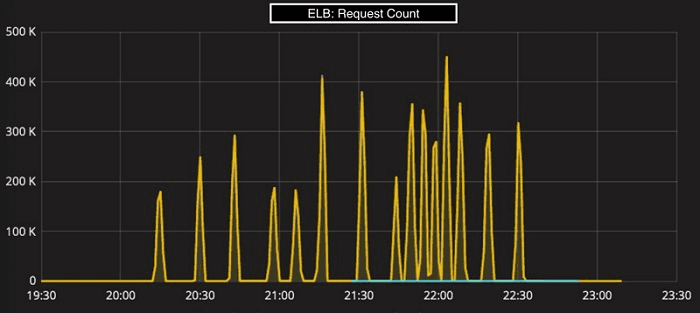
The best fit would be the provisioned capacity since DynamoDB’s autoscale cannot meet this speed and, to be frank, no database can deal with it without a reservation. We’ve taken the scenario from the AWS documentation itself. In the example, AWS recommended to use the more expensive on-demand mode (explained below), but also reported that DynamoDB needs time to scale, cannot double its capacity more often than every half an hour, and is complex to pre-warm.
In such a case, a write per second capacity unit costs $0.00065 and a read unit costs $0.00013. Storage costs $0.25 GB/month. If we multiply it by 300k reads, 300k writes, then add 25% spare (otherwise Dynamo will throttle your requests) and add 10TB of storage it looks like this:
| Throughput | Additional spare | |
| Total read/sec | 300,000 | 375,000 |
| Total writes/sec | 300,000 | 375,000 |
| Read Unit | $0.00013 | $48.75000 |
| Write Unit | $0.00065 | $243.75 |
| Storage | $3.47 | |
| Total (per hour) | $296 | |
That’s 6-9 times the ScyllaDB cost.
Now we can look at another scenario, with a more classic, bell curve of usage, also shared by the AWS team. In this case, the data enables automatic scaling, which uses the on-demand pricing.
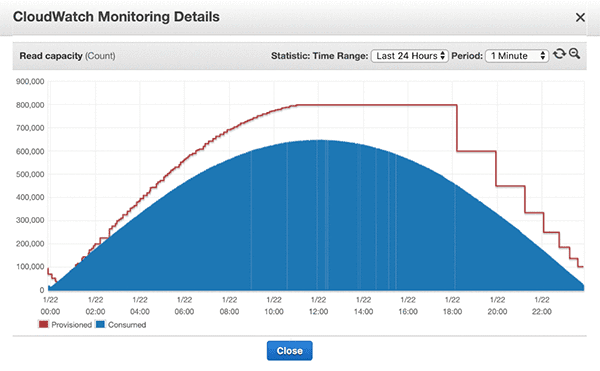
The on-demand cost, with $1.25 for every million writes (amount, not pace), would be $2,028/hour for a full hour with this load — 40x higher than ScyllaDB. Lucky for the user, the scenario is such that the load nicely grows and fades, thus there is no need to run 24×7 at full capacity. However, on average, you’d need around 50% of the load, thus you’ll be paying a shocking price of 20x the cost of the statically provisioned ScyllaDB cluster (which can easily scale too, but not automatically).
Even in cases where the spikes wouldn’t be that high and most of the time, like the first diagram where only 3 hours of usage are needed, on-demand mode is very expensive. A single hour would cover more than a day of full provisioning of ScyllaDB.
Lastly, the AWS documentation recommends combining the provisioned and the on-demand workloads to reduce costs.
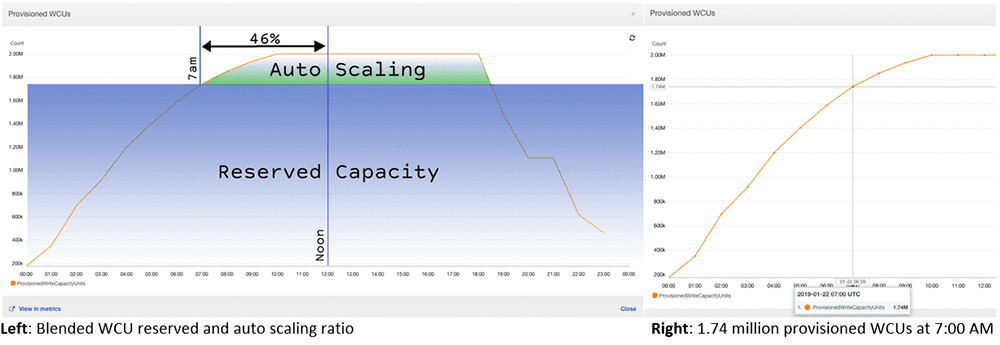
Reserved capacity, with a full 1-year commitment is the cheapest option. 100 write units (per second) cost $0.0128 PLUS $150 upfront. Reads are 5 times cheaper. We’ll need 3,000 of both. When adjusting the price per hour, it will cost $138. That’s still 3x-4.5x more than ScyllaDB, and this is without having the expensive auto-scale price mode.
Just the sheer complexity of tracking the cost, and making bets on consumption, makes it horribly challenging for the end user. We haven’t touched the hot partition issue that can make DynamoDB even more complicated and expensive. ScyllaDB doesn’t ‘like’ hot partitions either but we deal with them better. Plus this year we added a top-partitions enhancement, which allows you to discover your most-accessed partitions.
We’re happy to report that we have early adopters for ScyllaDB Alternator. Some use it not instead of AWS DynamoDB but as a surprising extension — in case you are used to the DynamoDB HTTP API but you want another deployment option, in this case on-premise, ScyllaDB’s Alternator is a great choice. We expect to see multi-cloud usage before we’ll gain a hybrid mode. It is also possible to just wet your feet and let Alternator duplicate a few of your data centers while you keep the lights on for some time using the original DynamoDB.
Open source software allows you to run within a Docker container, there’s no need to pay for dev & test clusters. When you are ready to go live, you can deploy anAlternator cluster via Kubernetes. Stop paying by the query and also enjoy a fully managed, affordable and highly available service on ScyllaDB Cloud. All of our DynamoDB-compatible tables are global, multi-DC and multi-zone and it’s easy to change at any time.
What’s to Expect from ScyllaDB 5.0
The team will kill me for pivoting so quickly to 5.0… they deserve a real vacation once COVID-19 is over. We had to cancel our yearly developer meeting, which was planned in Poland this year. Luckily so far none of our team has gotten sick and the vast majority of our developers were already working from home.
Since we’ve reached feature parity, we now plan on investing our efforts in two main areas. The first is to continue to improve the core ScyllaDB promise, keep raising the bar with awesome performance out of the box, verifying that no matter what happens, P99 latency is the lowest. ScyllaDB tracks latency violations and we still have a few to iron out. Repair speed should continue to be improved and we’d like to invest in workload shedding so ScyllaDB will be able to sustain all types of bursts, including ones with unbounded parallelism.
Another important core enhancement is around elasticity. We want to make it easy, fast and reliable to add and remove nodes, multiple nodes at a time, with minimal interruptions from compactions and simpler operations (further automating repairs, nodetool cleanup and so forth).
The second major area is ease of use. Now that we’ve got drivers such as GocqlX and sharded Go, Java and Python drivers, it is time to simplify the onboarding experience with best practices, to simplify migration, to add a component called ScyllaDB Advisor, which will automatically indicate where there may be configuration issues or performance challenges. We’ll add machine images on GCP and Azure, productize our k8s operator, make ScyllaDB Cloud more elastic and add more self service operations. The list goes on.
For now, as my friends in India like to say, happy upgradation!
Release Notes
You can read more details about ScyllaDB Open Source 4.0 in the Release Notes.