Getting your database running at the right scale and speed to handle your growing business should not be complex or confusing. As I wrote in a previous blog post, capacity planning is not to be discounted and providing tools to streamline it is part of our mission.
To help you get started, we recently released our ScyllaDB Cloud pricing and sizing calculator. This handy tool takes your peak workload requirements in terms of transactions per second and total data stored to recommend the proper sized cluster to run sustained workload.
But the real test is to see if the recommended cluster can actually achieve the desired performance numbers. Luckily with ScyllaDB Cloud (NoSQL DBaaS) it’s easy enough to run a quick test with just a few clicks! Let’s check how the calculator fares for a nice round sustained workload of 1 million operations per second, using a balanced 50:50 read/write ratio.
EXPLORE MORE SCYLLADB CLOUD CONTENT
Estimating with the Calculator
We put in 500,000 reads and 500,000 writes per second, stick with the average 1 kb item size, and let’s say our data set will consume 10 terabytes of disk (before replication).
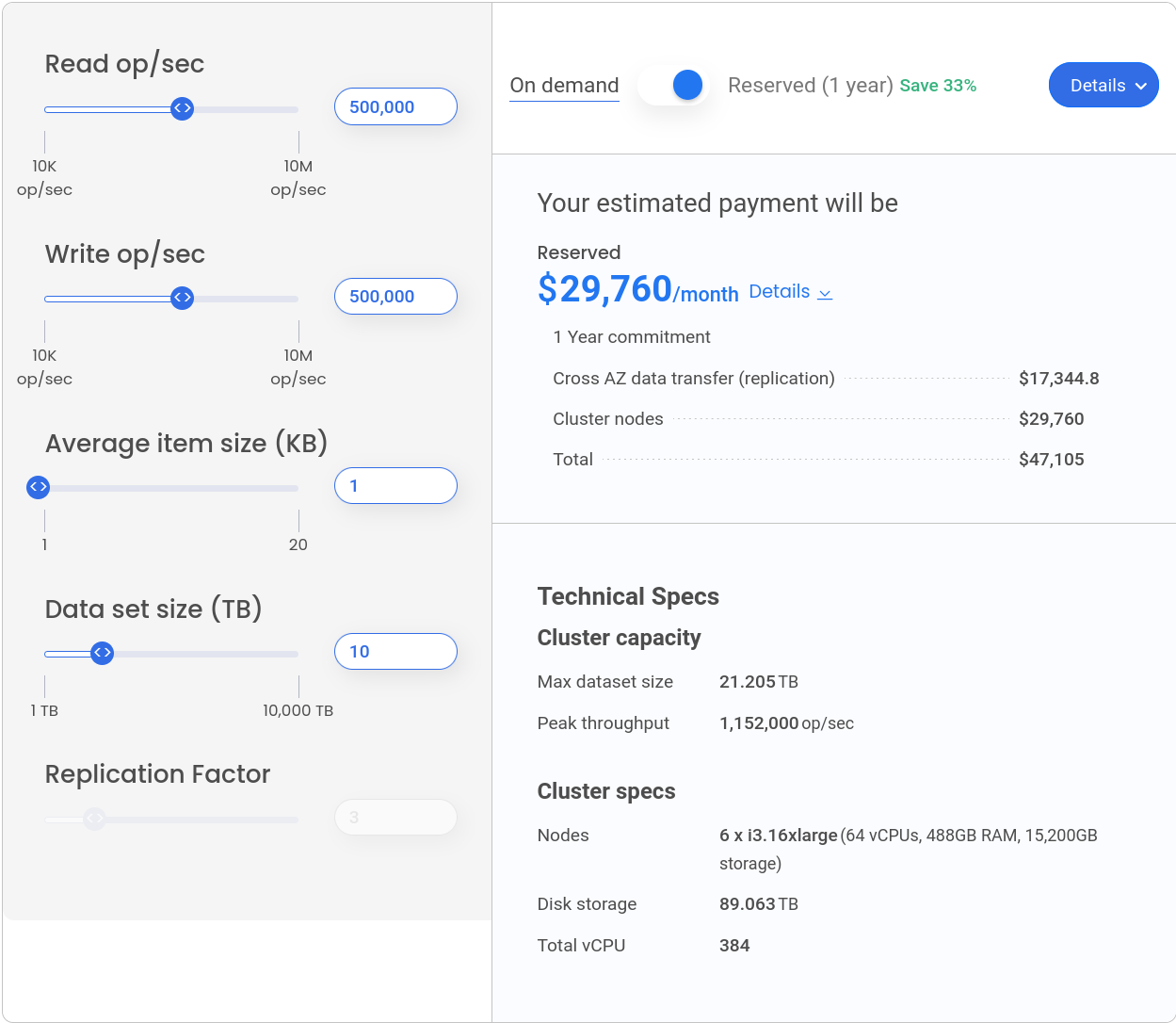
Given those inputs, the calculator recommends a cluster of 6 i3.16xlarge nodes, which is actually much more than is required for a simple workload as the benchmark we are about to run. The calculator is designed to support a wide range of workloads and usage patterns and errs on the side of caution as a necessity, but we will take its recommendation at face value and launch this cluster on ScyllaDB Cloud.
Note that the calculator’s workload projections are based on supporting peak sustained performance. There may be issues where you have a spike in your workload, or certain operations (range scans, lightweight transactions, etc.) that require extra processing or round trips. So a benchmark may vary significantly from your actual production experience.
This cluster will run us ~$30K/month, which might seem a lot until we compare it with other cloud databases: DynamoDB would run $133K/month with reserved capacity and DataStax Astra would cost a whopping $690K/month.
ScyllaDB Cloud Formation
To run this load test, I will use a pre-configured load test cluster with automated provisioning using CloudFormation stacks, which can be found in this repository. This makes running the load test as easy as providing AWS CloudFormation with a URL of the template, filling a few parameters and hitting “create.” But first, being good cloud citizens, we must create a VPC for our load test workers and configure VPC peering with ScyllaDB cloud’s VPC to allow the workers to communicate securely with the database cluster. The repository contains two templates, one for the VPC and another for load test itself. I have preloaded the CloudFormation templates on S3 to allow anyone to run them easily, so all I need to do is paste the URL in the AWS console:
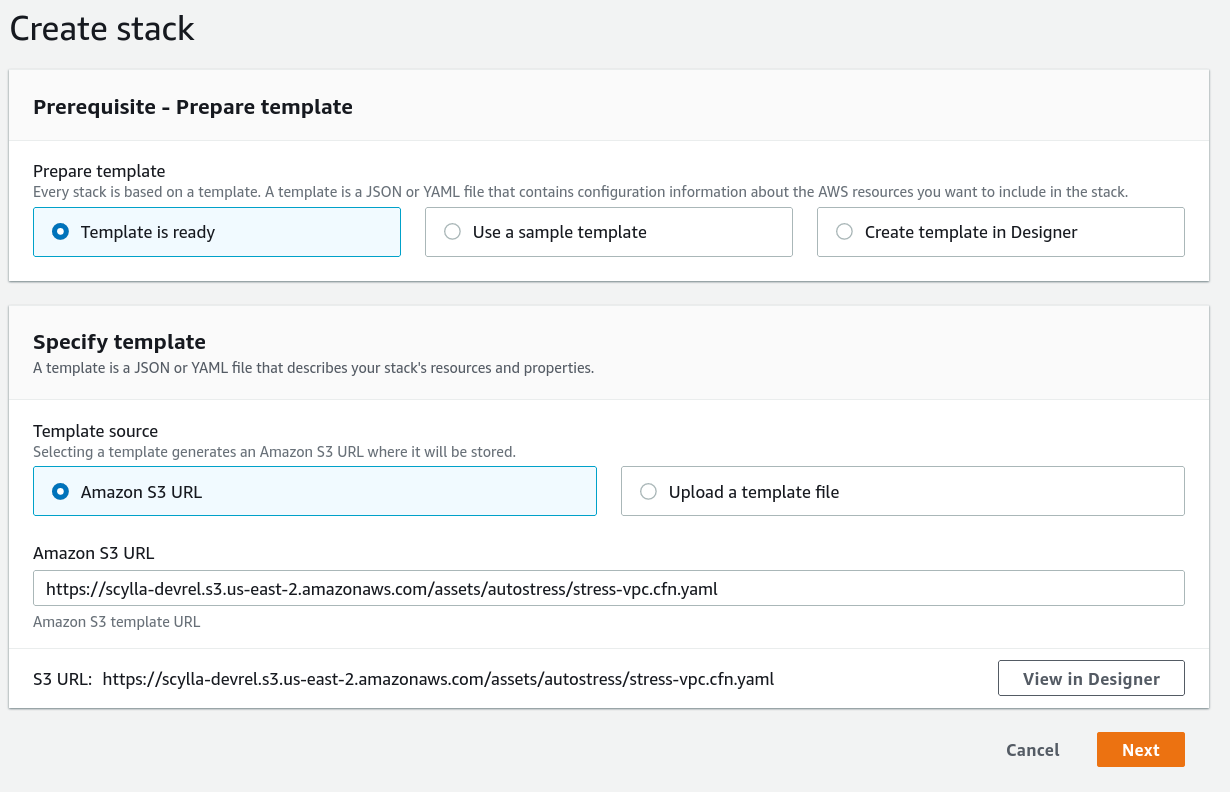
After the stack has finished creating the VPC, I’ve executed the peering procedure (see the docs for more details) and I’m ready to run the load test! Again, I’m using a template from S3:
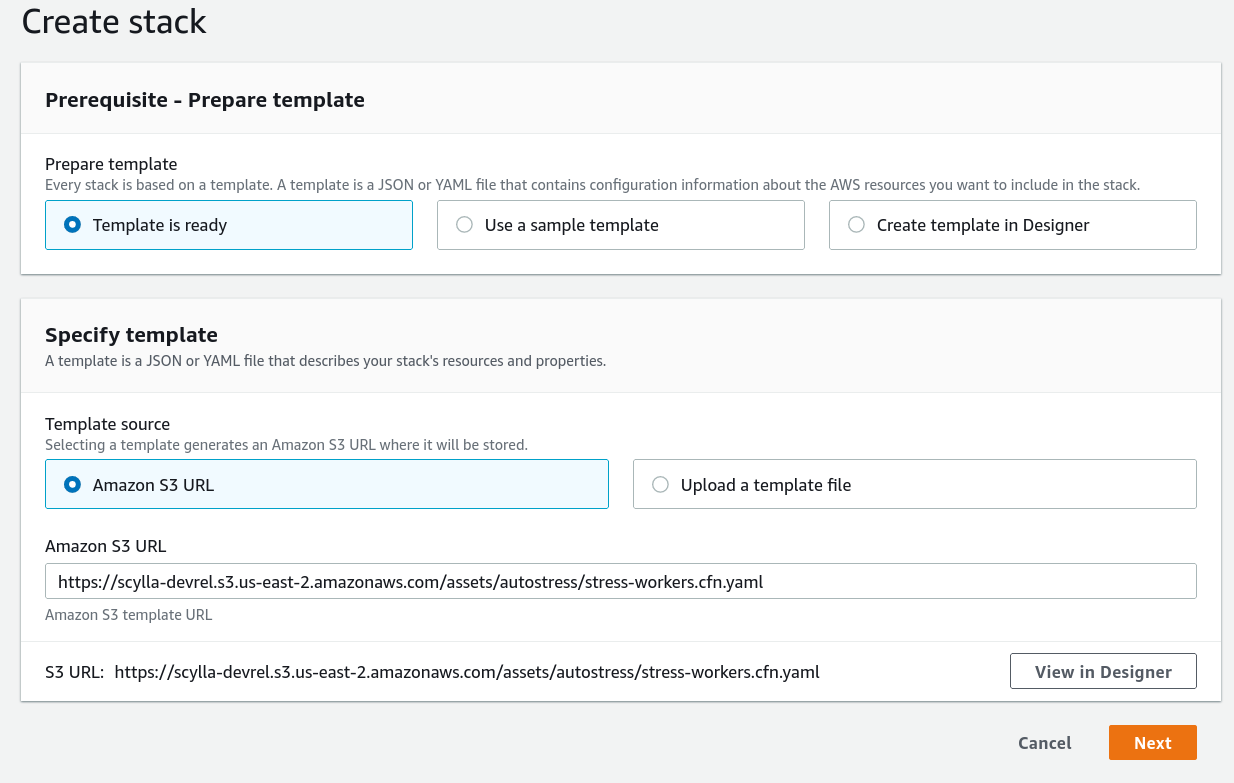
But this time I have a few parameters to put in:
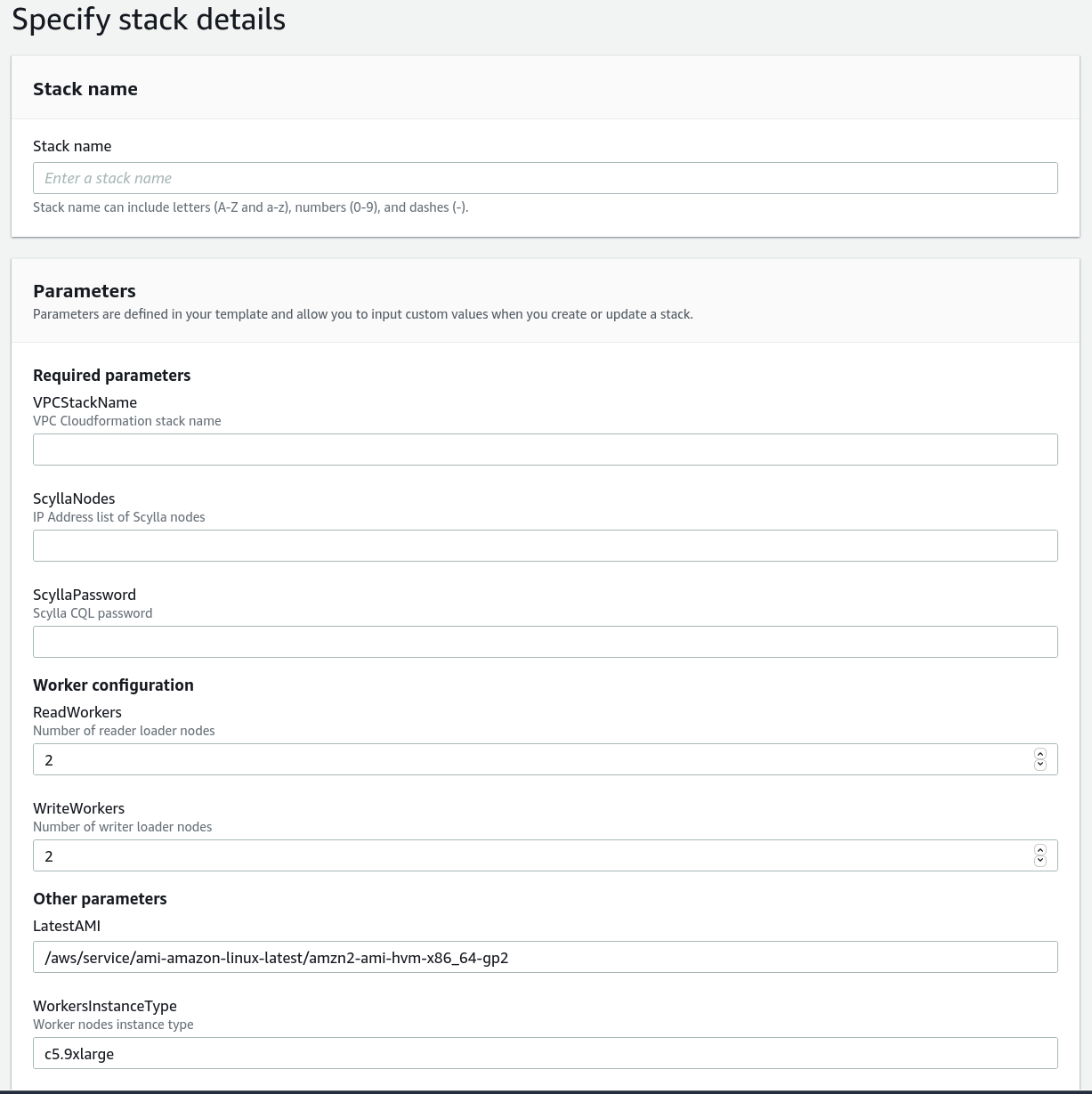
The VPCStackName parameter allows the load test stack to automatically configure itself with the VPC, and the ScyllaDB cluster parameters — a list of nodes and the password — are copy-pasted directly from the “Connect” tab of the ScyllaDB Cloud cluster; the number of workers can be changed to create more load, but in this case I’ll go with the default of 2 writers and 2 readers.
The workers’ CloudFormation stack creates 2 autoscaling groups (one for reader nodes, one for writers) which contain EC2 instances pre-configured to run scylla-bench with a concurrency setting of 500 for each node. You can view the exact parameters in the CloudFormation template, as well as change them if you wish to run a different workload.
Less than a minute after launching the workers stack, the load test is automatically starting and you can switch to ScyllaDB Monitoring Stack dashboards to see what’s going on:
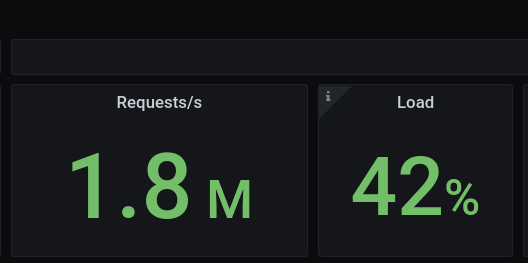
1.8M op/sec with a load of 42%! Impressive!
This cluster is clearly capable of higher loads than the calculator specified — nearly 2M OPS. That’s not surprising — this is, after all, a cluster that has very little data at the moment. Sustained operations need to account for things like compactions, which manifest when more data accumulates.
In the meantime, let’s take a look at the latency:
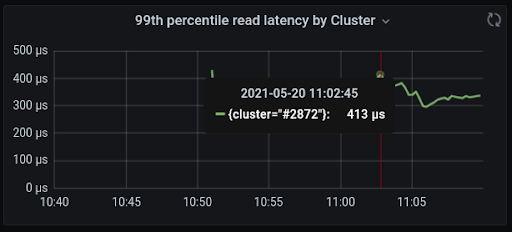
The P99 read latency is about 400µs (that’s right — microseconds) while running almost 2M operations per second! Not too shabby. Write latency P99 is even lower, about 250µs — which makes sense as ScyllaDB was designed for fast writes.
Conclusion
The calculator is handy to get a starting point for the size of the cluster you need, but by no means a final step — it is always wise to benchmark with a workload similar to what will run in production.
In the cloud it is easy to bootstrap clusters for tests, so benchmarking a few configurations is pretty straightforward. The hard part, of course, is understanding what the workload would be like and designing the benchmark. Even simple load tests like this one have value, at the very least showing what ScyllaDB clusters can do with in terms of raw performance.
I encourage you to run your own benchmarks, using the templates we have published or your own tools — it’s only a few clicks away!