In a previous post, Comparing CQL and the DynamoDB API, I introduced ScyllaDB — an open-source distributed database which supports two popular NoSQL APIs: Cassandra’s query language (CQL) and Amazon’s DynamoDB API. The goal of that post was to outline some of the interesting differences between the two APIs.
In this post I want to look more closely at one of these differences: The fact that DynamoDB-API applications are not aware of the layout of the ScyllaDB cluster and its individual nodes. This means that ScyllaDB’s DynamoDB API implementation — Alternator -—needs a load balancing solution which will redirect the application’s requests to many nodes. We will look at a few options of how to do this, recommend a client-side load balancing solution, and explain how we implemented it and how to use it.
Why Alternator Needs a Load Balancer
In the CQL protocol, clients know which ScyllaDB nodes exist. Moreover, clients are usually token aware, meaning that a client is aware of which partition ranges (“token” ranges) are held by which of the ScyllaDB nodes. Clients may even be aware of which specific CPU inside a node is responsible for each partition (we looked at this shard awareness in a recent post).
The CQL clients’ awareness of the cluster allows a client to send a request directly to one of the nodes holding the required data. Moreover, the clients are responsible for balancing the load between all the ScyllaDB nodes (though the cluster also helps by further balancing the load internally – we explained how this works in an earlier post on heat-weighted load balancing).
The situation is very different in the DynamoDB API, where clients are not aware of which nodes exist. Instead, a client is configured with a single “endpoint address”, and all requests are sent to it. Amazon DynamoDB provides one endpoint per geographical region, as listed here. For example in the us-east-1 region, the endpoint is:
https://dynamodb.us-east-1.amazonaws.com
If, naïvely, we configure an application with the IP address of a single ScyllaDB node as its single DynamoDB API endpoint address, the application will work correctly. After all, any Alternator node can answer any request by forwarding it to other nodes as necessary. However this single node will be more loaded than the other nodes. This node will also become a single point of failure: If it goes down clients cannot use the cluster any more.
So we’re looking for a better, less naïve, solution which will provide:
- High availability — any single Alternator node can go down without loss of service.
- Load balancing — clients sending DynamoDB API requests will cause nearly equal load on all ScyllaDB nodes.
In this document we shortly survey a few possible load-balancing solutions for Alternator, starting with server-side options, and finally recommending a client-side load balancing solution, and explaining how this solution works and how it is used.
Server-side Load Balancing
The easiest load-balancing solution, as far as the client application is concerned, is a server-side load balancer: The application code remains completely unchanged, configured with a single endpoint URL, and some server-side magic ensures that the different requests to this single URL somehow get routed to the different nodes of the ScyllaDB cluster. There are different ways to achieve this request-routing magic, with different advantages and different costs:
The most straightforward approach is to use a load-balancer device — or in a virtualized network, a load-balancer service. Such a device or service accepts connections or HTTP requests at a single IP address (a TCP or HTTP load balancer, respectively), and distributes these connections or requests to the many individual nodes behind the load balancer. Setting up load-balancing hardware requires solving additional challenges, such as failover load-balancers to ensure high availability, and scaling the load balancer when the traffic grows. As usual, everything is easier in the cloud: In the cloud, adding a highly-available and scalable load balancer is as easy as signing up for another cloud service. For example, Amazon has its Elastic Load Balancer service, with its three variants: “Gateway Load Balancer” (an IP-layer load balancer), “Network Load Balancer” (a TCP load balancer) and “Application Load Balancer” (an HTTP load balancer).
As easy as deploying a TCP or HTTP load balancer is, it comes with a price tag. All connections need to flow through this single service in their entirety, so it needs to do a lot of work and also adds latency. Needing to be highly available and scalable further complicates the load balancer and increases its costs.
There are cheaper server-side load balancing solutions that avoid passing all the traffic through a single load-balancing device. One efficient technique is DNS load balancing, which works as follows: We observe that the endpoint address is not a numeric IP address, but rather a domain name, such as “dynamodb.us-east-1.amazonaws.com”. This gives the DNS server for this domain name an opportunity to return a different ScyllaDB node each time a domain-name resolution is requested.
If we experiment with Amazon DynamoDB, we can see that it uses this DNS load-balancing technique: Each time that “dynamodb.us-east-1.amazonaws.com” is resolved, a different IP address is returned, apparently chosen from a set of several hundreds. The DNS responses have a short TTL (5 seconds) to encourage clients to not cache these responses for very long. For example:
$ while :
do
dig +noall +answer dynamodb.us-east-1.amazonaws.com
sleep 1
done
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.94.2.86
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.228.140
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.233.18
dynamodb.us-east-1.amazonaws.com. 3 IN A 52.119.228.140
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.233.182
dynamodb.us-east-1.amazonaws.com. 1 IN A 52.119.228.140
dynamodb.us-east-1.amazonaws.com. 1 IN A 52.119.233.18
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.233.238
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.234.122
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.233.174
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.233.214
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.224.232
dynamodb.us-east-1.amazonaws.com. 4 IN A 52.119.224.232
dynamodb.us-east-1.amazonaws.com. 5 IN A 52.119.225.12
dynamodb.us-east-1.amazonaws.com. 1 IN A 52.119.226.182
...These different IP addresses may be different physical nodes, or be small load balancers fronting for a few nodes each.
The DNS-based load balancing method is cheap because only the DNS resolution goes through the DNS server — not the entire connection. This method is also highly available and scalable because it points clients to multiple ScyllaDB nodes and there can be more than one DNS server.
However, DNS load balancing alone has a problem: When a ScyllaDB node fails, clients who have already cached a DNS resolution may continue to send requests to this dead node for a relatively long time. The floating IP address technique can be used to solve this problem: We can have more than one IP address pointing to the same physical node. When one of the nodes fails, other nodes take over the dead node’s IP addresses — servicing clients who cached its IP addresses until those clients retry the DNS request and get a live node.
Here are two examples of complete server-side load balancing solutions. Both include a DNS server and virtual IP addresses for quick failover. The second example also adds small TCP load balancers; Those are important when there are just a few client machines who cache just a few DNS resolutions — but add additional costs and latency (requests go through another network hop).
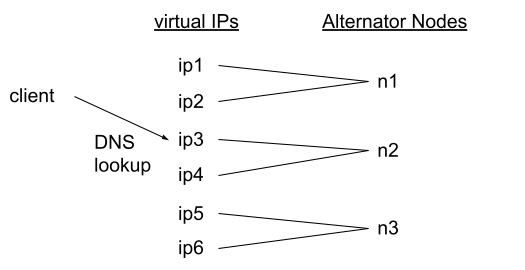
Server-side load balancing, example 1:
DNS + virtual IP addresses
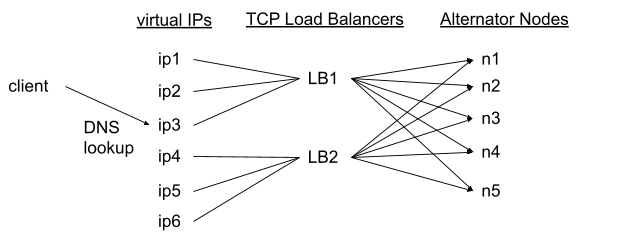
Server-side load balancing, example 2:
DNS + TCP load balancers + virtual IP addresses
Alternator provides two discovery services that these different load-balancing techniques can use to know which nodes are alive and should be balanced:
- Some load balancers can be configured with a fixed list of nodes plus a health-check service to periodically verify if each node is still alive. Alternator allows checking the health of a node with a trivial HTTP GET request, without any authentication needed:
$ curl http://1.2.3.4:8000/
healthy: 1.2.3.4:8000
- In other setups, the load balancer might not know which Alternator nodes exist or when additional nodes come up or go down. In this case, the load balancer will need to know of one live node (at least), and can discover the rest by sending a “
/localnodes” request to a known node:
$ curl http://127.0.0.1:8000/localnodes
["127.0.0.1", “127.0.0.2”, “127.0.0.3”]
The response is a list of all living nodes in this data center of the Alternator cluster, a list of IP addresses in JSON format (the list does not repeat the protocol and port number, which are assumed to be the same for all nodes).
This request is called localnodes because it returns the local nodes — the nodes in the same data center as the known node. This is usually what we need — we will have a separate load balancer per data center, just like AWS DynamoDB has a separate endpoint per AWS region.
Most DNS servers, load balancers and floating IP address solutions can be configured to use these discovery services. As a proof-of-concept, we also wrote a simple DNS server that uses the /localnodes in just 50 lines of Python.
Client-side Load Balancing
So, should this post about load balancing in Alternator end here? After all, we found some excellent server-side load balancing options. Don’t they solve all our problems?
Well not quite…
The first problem with these server-side solutions is their complexity. We started the previous section by saying that the main advantage of server-side load balancing was the simplicity of using it in applications — you only need to configure applications with a single endpoint URL. However, this simplicity only helps you if you are only responsible for the application, and someone else takes care of deploying the server for you — as is the case in Amazon DynamoDB. Yet, many Alternator users are responsible for deploying both application and database. Such users do not welcome the significant complexity added to their database deployment, and the extra costs which come with this complexity.
The second problem with the server-side solutions is added latency. Solutions which involve a TCP or HTTP load balancer require another hop for each request – increasing not just the cost of each request, but also its latency.
So an alternative which does not require complex, expensive or latency-inducing server-side load balancing is client-side load balancing, an approach that has been gaining popularity, e.g., in microservice stacks with tools such as Netflix Eureka.
Client-side load balancing means that we modify the client application to be aware of the Alternator cluster. The application can use Alternator’s discovery services (described above) to maintain a list of available server nodes, and then open separate DynamoDB API connections to each of those endpoints. The application is then modified to send requests through all these connections instead of sending all requests to the same ScyllaDB node.
The difficulty with this approach is that it requires many modifications to the client’s application. When an application is composed of many components which make many different requests to the database, modifying all these places is time-consuming and error-prone. It also makes it more difficult to keep using exactly the same application with both Alternator and DynamoDB.
Instead, we want to implement client-side load balancing with as few as possible changes to the client application. Ideally, all that would need to be changed in an application is to have it load an additional library, or initialize the existing library a bit differently; From there on, the usual unmodified AWS SDK functions will automatically use all of Alternator’s nodes instead of just one.
And this is exactly what we set out to do — and we will describe the result here, and recommend it as the preferred Alternator load-balancing solution.
Clearly, such a library-based solution will be different for different AWS SDKs in different programming languages. We implemented such a solution for six different SDKs in five programming languages: Java (SDK versions 1 and 2), Go, Javascript (Node.js), Python and C++. The result of this effort is collected in an open-source project, and this is the method we recommend for load balancing Alternator. The rest of this post will be devoted to demonstrating this method.
In this post, we will take a look at one example, using the Java programming language, and Amazon’s original AWS SDK (AWS SDK for Java v1). The support for other languages and SDK is similar – see https://github.com/scylladb/alternator-load-balancing/ for the different instructions for each language.
An Example in Java
An application using AWS SDK for Java v1 creates a DynamoDB object and then uses methods on this object to perform various requests. For example, DynamoDB.createTable() creates a new table.
Had Alternator been just a single node, https://127.0.0.1:8043/, an application that wished to connect to this one node with the AWS SDK for Java v1 would use code that looks something like this to create the DynamoDB object:
URI node = URI.create("https://127.0.0.1:8043/");
AWSCredentialsProvider myCredentials =
new AWSStaticCredentialsProvider(
new BasicAWSCredentials("myusername", "mypassword"));
AmazonDynamoDB client =
AmazonDynamoDBClientBuilder.standard()
.withEndpointConfiguration(
new AwsClientBuilder.EndpointConfiguration(
node.toString(), "region-doesnt-matter"))
.withCredentials(myCredentials)
.build();
DynamoDB dynamodb = new DynamoDB(client);And after this setup, the application can use this “dynamodb” object any time it wants to send a DynamoDB API request (the object is thread-safe, so every thread in the application can access the same object). For example, to create a table in the database, the application can do:
Table tab = dynamodb.createTable(tabName,
Arrays.asList(
new KeySchemaElement("k", KeyType.HASH),
new KeySchemaElement("c", KeyType.RANGE)),
Arrays.asList(
new AttributeDefinition("k", ScalarAttributeType.N),
new AttributeDefinition("c", ScalarAttributeType.N)),
new ProvisionedThroughput(0L, 0L));We want a way to create a DynamoDB object that can be used everywhere that the application used the normal DynamoDB object (e.g., in the above createTable request), just that each request will go to a different Alternator node instead of all of them going to the same URL.
Our small library (see installation instructions) allows us to do exactly this, by creating the DynamoDB object as follows. The code is mostly the same as above, with the new code in bold:
import com.scylladb.alternator.AlternatorRequestHandler;
URI node = URI.create("https://127.0.0.1:8043/");
AlternatorRequestHandler handler =
new AlternatorRequestHandler(node);
AmazonDynamoDB client = AmazonDynamoDBClientBuilder.standard()
.withRegion("region-doesnt-matter")
.withRequestHandlers(handler)
.withCredentials(myCredentials)
.build();
DynamoDB dynamodb = new DynamoDB(client);The main novelty in this snippet is the AlternatorRequestHandler, which is passed into the client builder with withRequestHandlers(handler). The handler is created with the URI of one known Alternator node. The handler object then contacts this node to discover the rest of the Alternator nodes in this data-center. The handler also keeps a background thread which periodically refreshes the list of live nodes. After learning of more Alternator nodes, there is nothing special about the original node passed when creating the handler — and this original node may go down at any time without hurting availability.
The region passed to withRegion() does not matter (and can be any string), because AlternatorRequestHandler will override the chosen endpoint anyway. Unfortunately we can’t just drop the withRegion() call, because without it the library will expect to find a default region in the configuration file and complain when it is missing.
Each request made to this dynamodb object will now go to a different live Alternator node. The application code doing those requests does not need to change at all.
Conclusions
We started this post by explaining why Alternator, ScyllaDB’s implementation of the DynamoDB API, needs a load-balancing solution for sending different requests to different ScyllaDB nodes. We then surveyed both server-side and client-side load balancing solutions, and recommended a client-side load balancing solution.
We showed that this approach requires only very minimal modification to applications — adding a small library and changing the way that the DynamoDB object is set up, while the rest of the application remains unchanged: The application continues to use the same AWS SDK it used with Amazon DynamoDB, and the many places in the application which invoke individual requests remain exactly the same.
The client-side load balancing allows porting DynamoDB applications to Alternator with only trivial modifications, while not complicating the ScyllaDB cluster with load balancing setups.