





2025 update: Both ScyllaDB and CockroachDB have changed a lot since this benchmark. For tips on running you own benchmark with these tools, see our Benchmarking for Performance masterclass.
An Apples and Oranges Comparison
The database space has always been a complicated field that introduced many options and tradeoffs. Two particular classes of databases, NoSQL and NewSQL, have been most recently pitted against each other in the industry. However, both terms were coined long ago. These two families of databases offer expanded capabilities beyond traditional databases. They also often overlap so that today the boundaries are even more blurred as more new database implementations are born.
In this article, we compare what we consider the best of breed in NoSQL versus the best in class in NewSQL. Admittedly biased, we selected ourselves for NoSQL. For NewSQL, we chose CockroachDB. The latter represents distributed SQL, the segment which represents not only the SQL API but also the distributed relational database model.
Obviously, the comparison is of the apples and oranges type. We expect ScyllaDB will be faster — providing lower latencies and greater throughputs — while CockroachDB should have stronger consistency and be friendlier to use with its SQL interface. Our goal was to put forward a rational analysis and put a price tag on the differences in workloads that could be addressed by the two databases. So we won’t cover SQL JOINs which are supported by CockroachDB alone and we won’t cover timeseries workloads where ScyllaDB has a clear design advantage.
TAKE ME STRAIGHT TO THE BENCHMARK RESULTS
Background
CockroachDB (CRDB) was built from the ground up to support global OLTP workloads while maintaining high availability and strong consistency. It is based on ideas from Google Spanner [whitepapers] [2012-GDD] [2017-TT] [2017-SQL] (and F1). Cockroach Labs, the company that supports it, was founded in 2014.
ScyllaDB has likewise been under development since 2014. It was modeled after Apache Cassandra and Amazon DynamoDB, supporting API compatibility for both.
ScyllaDB
ScyllaDB is a wide-column distributed NoSQL database that uses an eventual consistency model to provide fast and efficient reads and writes along with multi-datacenter high availability.
In ScyllaDB all nodes are equal: there are no leaders, followers, or replica sets. And there is no single point of failure; client applications can interact with any node in the cluster. This allows ScyllaDB to scale linearly to many nodes without performance degradation and overhead costs.
Performance
ScyllaDB is a Cassandra rewrite in C++, however, the performance gains arrive from its radical, asynchronous, shard-per-core design and its desire to achieve full control of the entire resource allocation and execution.
The computing model is completely async with futures and promises and has its own task switching mechanism, developed in order to run a million continuations (lambda functions) per second per core. In a high performance database, control is even more important than efficiency. ScyllaDB makes every computation and IO operation belong to a priority class. Its CPU and IO schedulers control the execution of all continuations. Latency sensitive classes such as read and write operations are given a higher, dynamic priority over background tasks such as compaction, repair, streaming, etc.
ScyllaDB makes sure the OS does not play its traditional role by pinning threads to cores, memory to shards nor overload the filesystem/disks with IO beyond their capacity. Compaction controllers measure the compaction debt and dynamically set the compaction priority. Thus compaction control, which makes Log Structured Merge (LSM) trees complicated, is a solved problem with ScyllaDB. More on the thread-per-core approach can be found here, and on seastar.io, our application framework. These capabilities to precisely control resource utilization are behind another unique feature of ScyllaDB: workload prioritization, where different workloads can have different priorities, permitting OLTP and OLAP (driven by Presto/Spark) workloads to co-exist running simultaneously in the same cluster on the same hardware.
Availability
ScyllaDB uses an eventual consistency model. Many workloads do not require strong consistency guarantees while they do require availability. For example, during partitioning, an isolated datacenter should continue to accept reads and writes. ScyllaDB has an API for stronger consistency using lightweight transactions (LWT).
ScyllaDB can even be tuned per transaction, so that you can state the desired level of consistency. Do you just want the transaction to succeed if even one node acknowledges a read or write (a consistency level of 1, or CL=1)? If so, the rest of the nodes will be caught up in due time. Or do you want a majority of replica nodes to acknowledge a read or write (CL=QUORUM, LOCAL_QUORUM, ..)? Or do you want every replica node to acknowledge that the transaction successfully completed (CL=ALL)?
Data Distribution
In ScyllaDB data is spread as uniformly as possible across all nodes by the means of the hash function (partitioner) so that the load can be evenly distributed and efficiently processed by all cores in the cluster. Token ring and cluster topology configuration is shared with the clients. This makes clients aware of the nodes where data actually resides. They can efficiently choose the closest nodes that own the data and even reach the specific cpu core that handles partition within the node, minimizing extra hops and maximizing load balancing.
Read and Write Path
Clients choose the operations coordinator either randomly or as close to the target replicas as possible and send their requests. Multiple policies exist to select the coordinator with different load balancing options. The coordinator asynchronously replicates writes to the number of replicas. A user can pick the number of replicas data shall be read from. That makes request processing very predictable in terms of implied operations, IO and round trips.
ScyllaDB uses a commitlog and in parallel memtable, SSTables, etc. You can read more about ScyllaDB’s read path in this article about our row-level cache, and more on the write path in our documentation.
Data Model
ScyllaDB offers a natural RDBMS-like model when data is organized in tables that consist of rows and columns on top of the wide-column storage. A row key consists of a partition key and optionally clustering key. A clustering key defines rows ordering inside of the partition. A partition key determines partition placement.
Users define tables schemas, insert data into rows, and then read it. There are usual concepts such as Secondary Indexes, Materialized Views, Complex Data Types, Lightweight Transactions, and other features built on top.
The wide-column data model differs from the classical RDBMS-style model in that rows are not first-class citizens but the cells are. Rows consist of cells.
CQL and ACID
Though the ScyllaDB CQL user language can be deceptively very similar to what most of us are used to with SQL:
SELECT * FROM Table;
UPDATE Table (a, b, c) VALUES (1, 2, 3) WHERE Id = 0;However, ScyllaDB does not provide full ACID semantics for its operations. Usually, ACID is applied to transactions but let’s take a look at what is provided for a single operation:
- atomicity is provided with a commitlog
- consistency is provided in an ACID sense that it preserves application invariants if the operations preserve them
- durability is provided with a commit log and replication.
What ScyllaDB does not provide from an ACID perspective is isolation. But why would you need isolation if you don’t have multi-statement cross-partition transactions? If you want to know a detailed analysis to this question, you can read the Jepsen analysis of ScyllaDB here — section 3.4 Normal Writes Are Not Isolated, and our accompanying post here.
Limitations
With such great flexibility and freedom there comes a great price.
Data ordering prohibits efficient sequential primary key scanning because every partition has random placement. This limits an opportunity to make range-based JOIN operations. Even though it allows sequential local scan, it is a tradeoff that ScyllaDB makes in order of delivering maximum performance possible out of available hardware.
Cell-based data organization along with the timestamp non-monotonicity prevents an efficient usage of levels in LSM storage and opens an opportunity for torn row writes.
While all of the nodes in ScyllaDB are homogenous and cluster resizing is easy, the data is sharded through key range allocations to nodes. Sharding is not transactional thus only done in a serial way and there is no software enforcement. In addition, these ranges are static once the topology is set and can result in hot shards. Our recently-announced Project Circe is about to address these limitations.
Lack of multi-partition transactions prevents users from developing applications that require higher consistency guarantees.
CockroachDB
CockroachDB is a distributed NewSQL database built from the ground up to support global OLTP workloads while maintaining high availability and strong consistency.
It is built on the foundation of ideas that stand behind Google’s Spanner database. CockroachDB focuses on providing fully serializable ACID transactions on top of its strongly consistent highly-available distributed KV store. Its transactions are serializable and reads are linearizable from the beginning by default.
It has a completely different design than ScyllaDB and exploits that to serve SQL requests efficiently.
Performance
CockroachDB’s primary focus is consistency, topology flexibility and SQL compatibility. It provides high availability the same way ScyllaDB does — with redundancy, but keeps replicas consistent throughout operations. Maintaining consistency all the time implies additional overhead. However, CockroachDB uses different innovative approaches to provide high performance quality of service such as Raft with Leases, cost-free linearization, parallel two-phase commit, an innovative hybrid transactions scheduler, vectorization, in-memory data layout optimization and more. CockroachDB is written in Go and susceptible to garbage collection spikes.
Availability
CockroachDB favors consistency in place of availability. It provides different options to maintain high availability and build hybrid cluster topologies. Availability is based on redundancy. Because of Raft to be available every ReplicaSet requires a quorum of its nodes to be alive. This limits availability.
Data Distribution
In an architectural sense, it is very similar to Google Spanner: ordered data keyspace is split into Data Ranges or Tablets. Data range replicas are grouped into ReplicaSets. Each ReplicaSet has a dedicated leader that is determined by the consensus process. For consensus, CockroachDB uses Raft with different optimizations.
Read and Write Path
In every ReplicaSet, there is only one dedicated node that serves reads and writes. It is called a leaseholder. Only the leaseholder can offer a write to the ReplicaSet leader. Because there always exists only one leaseholder in a group, reads that served from it are linearizable.
Now it must be clear that reads are cheap and linearizable. The writes in its turn are synchronous — the transaction coordinator always waits until all writes would be replicated before committing the transaction. Transaction commit is asynchronous though.
All reads and writes in CockroachDB execute in the context of transactions. A transaction is an interactive session with respect to the ACID properties in which a client sends requests and then finalizes them with a commit or abort keyword.
Data Model
CockroachDB offers a classical relational data model with tables and rows built on top of LSM-based key-value storage. CockroachDB is wire compatible with PostgreSQL.
Consistency and Isolation
CockroachDB currently supports only one transaction execution mode: SERIALIZABLE isolation. This is good when a user needs strong isolation guarantees free of anomalies. CockroachDB does not offer picking a weaker isolation model for higher performance.
To serialize transactions CockroachDB offers a parallel two-phase commit variant and a novel hybrid serialization scheduler. In the best simple case, CockroachDB is capable of committing a transaction in 1 Round Trip Time (RTT). In general, though, it requires a serialization check on every read and write and waiting that all writes were replicated. To atomically switch data visibility CockroachDB uses indirection in the read path.
Overall, CockroachDB provides near strong-1SR consistency.
Tablets
CockroachDB offers maximum flexibility on data placement policy. Users have control over how data is organized on disk (families) and how it is split and distributed across the world. The model supports independent data rebalance (instead of a ring rebalance), an independent isolated cluster topology change, and even data access control.
This design approach allows CockroachDB to flexibly and seamlessly control cluster membership. Nodes can be added or removed instantly and in parallel into the cluster and they can start serving data as soon as they have the first data range replicated. Data split and rebalance occurs automatically in the background based on the load distribution and resources utilization.
In data modeling, a user has great flexibility in keeping all data in an ordered fashion or randomly distributing it in the keyspace depending on his load patterns.
Data replicas are always kept in a consistent state. That gives an opportunity to compact delete tombstones in the LSM trees right away and simplifies many operations.
Limitations
Writes inside a ReplicaSet require consensus coordination and are limited in throughput in that sense. To mitigate this CockroachDB implies dynamic data ranges splitting and rebalancing.
Clocks instability affects replicas performance.
Transactions require serialization that is not cost-free and contended keys transactions do not scale.
Reads preliminary are served only from the leaseholder nodes which means that you don’t utilize the rest of the replicas.
It’s easier to miss load distribution and get hot data ranges. If load distribution is uneven hot data ranges will affect performance.
Availability guarantees are weaker. There is an overhead implied by the language with automatic memory management.
Benchmarking
Overall both databases are focused on different things and use different approaches to serve reads and write. However, let’s take a look at their performance.
In order to measure performance differences, we ran YCSB workloads on AWS for ScyllaDB and CockroachDB with two datasets, with sizes of 1B and 100M keys. All clusters consisted of 3 × i3.4xlarge AWS EC2 nodes (each with 16 vCPU, 122 GiB RAM, 10GiB network, and 2 × 1.9TiB NVMe SSDs) in a single region (eu-north-1) spread across 3 availability zones (abc) with the standard replication factor (RF=3) and almost default configuration.
To measure CockroachDB performance, we used the brianfrankcooper/YCSB 0.17.0 benchmark with PostgreNoSQL binding and CockroachDB v20.1.6 YCSB port to the Go programming language that offers better support for this database. For ScyllaDB 4.2.0, we used the brianfrankcooper/YCSB 0.18.0 with a ScyllaDB-native binding and a Token Aware balancing policy.
Data loading
While the official CockroachDB documentation states that the storage capacity limit is 150GiB per vCPU and up to 2.5 TB per node total, we did not manage [#56362 with 20.1.6] [#38778 with 20.2.0] to successfully load 1B keys into the CockroachDB cluster — for most of the trials it went unresponsive after about 3-5 hours of loading with some critical errors in the logs. A few times we observed a similar behavior during a 30 minute long sustained workload.
Another problem was load throughput degradation from 12K TPS down to 2.5K TPS in 3-5 hours. Loading 1B keys at a rate of 2.5K keys inserted per second could take about 111 hours or 4.5 days. We decided not to wait for it. Similar issues were observed by YugaByte: [1B trial], [slowdown] and [results].
We reduced the dataset size for CockroachDB to 100M. Loading took 7 hours and resulted in 1.1TB of data overall that later was compacted to 450GiB. The latency graph over this 7 hours period can be seen below.
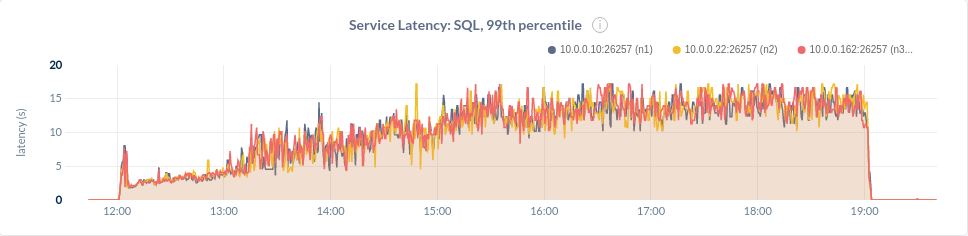
In its turn, ScyllaDB did well with 1B keys — ScyllaDB loaded 4.8TB of data (before major compaction, 3.9 TB after) in about 3 hours and showed the same performance characteristics as with the smaller dataset.
- Key Observation: Loading 10 times the data into ScyllaDB took less than half the time it took for CockroachDB. ScyllaDB was over 20x more efficient in initial data loading.
YCSB Workload A Results
From YCSB’s github: “This workload has a mix of 50/50 reads and writes. An application example is a session store recording recent actions.”
ScyllaDB showed the capability to produce 120K TPS under 60% CPU utilization with P99 latency <4.6ms, and 150K TPS with P99 <12ms for the 1B dataset size.

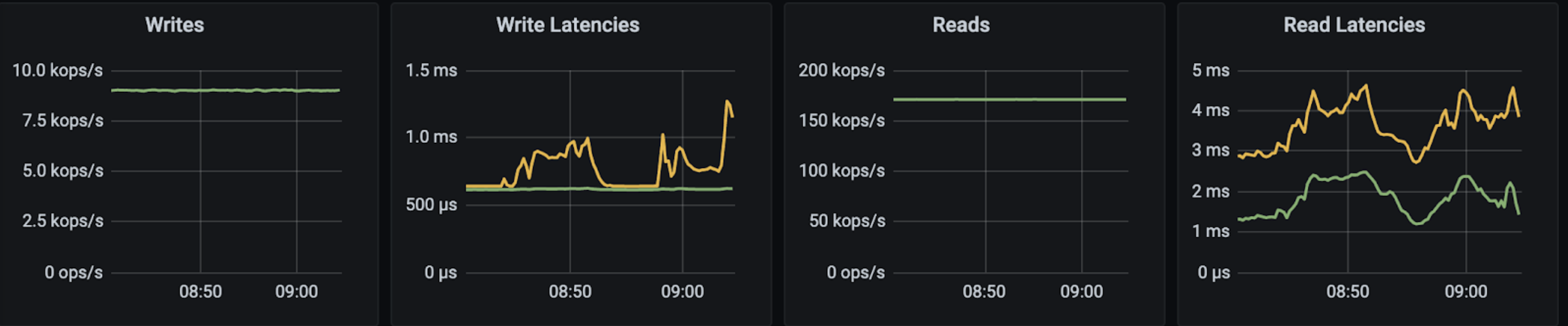
In this Grafana diagram, taken from the ScyllaDB Monitoring Stack dashboard, you can see that 2 clients have 600 µsec P99 latency for writes, <4ms P99 latency for reads while serving 60k ops for reads and 60k ops for writes; 120K TPS in total.
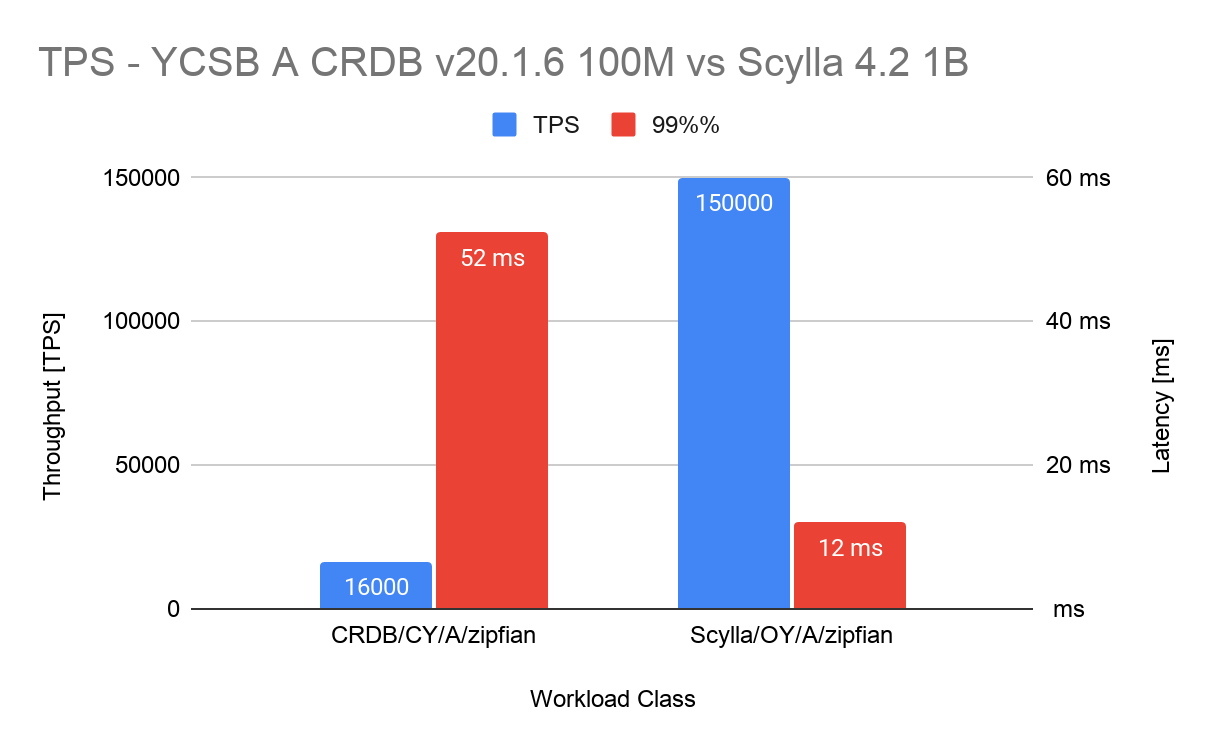
CockroachDB in this example of workload A produced at most 16K TPS with P99 52ms and intermediate spikes that reach 200ms at utilization varying from 50% – 75%:
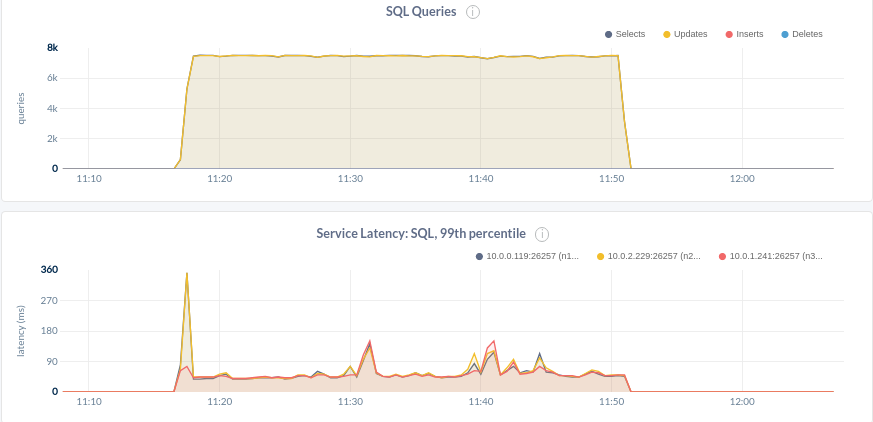
- Key Observation: ScyllaDB handled 10x the amount of data, while providing 9.3x the throughput at 1/4th the latency.
Results for Workloads A through F
ScyllaDB
For the large, 1B key dataset, ScyllaDB successfully managed to serve 150K-200K TPS on most of the workloads at 75-80% utilization with decent latency. One of the best ScyllaDB results was 180K TPS with p99 latencies <5.5ms at average load 75% on workload D with 1B keys. 200K TPS resulted in small overload and gave latencies around 20-60ms.
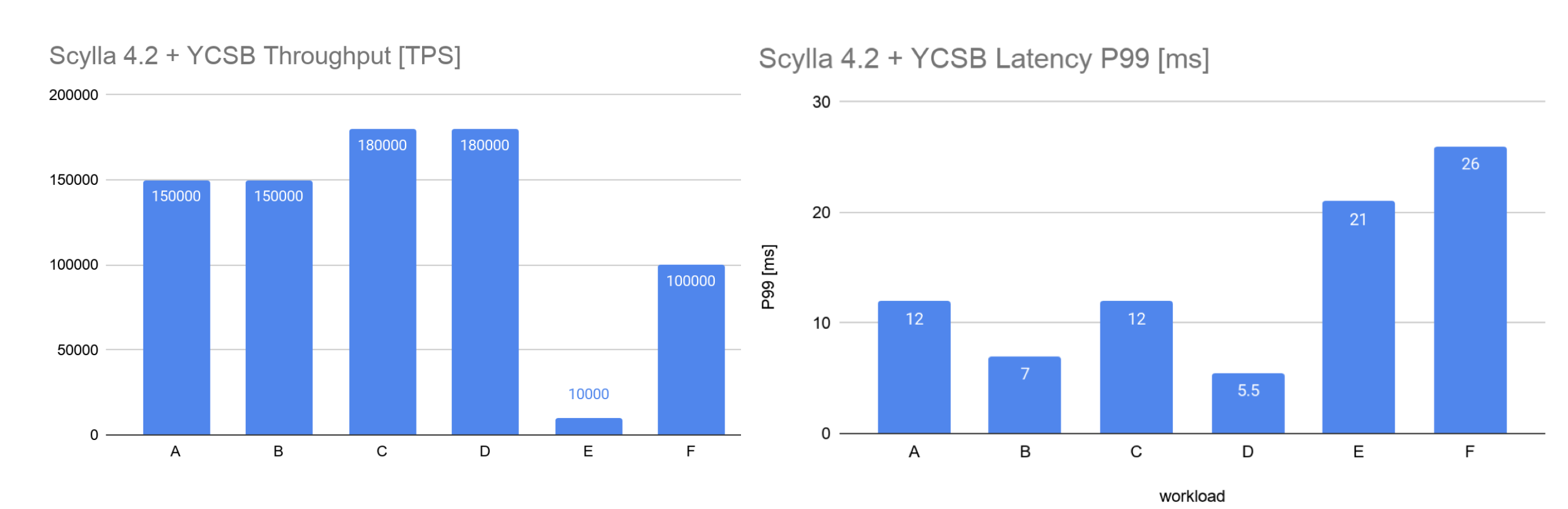
These two tables present the throughput and latency achieved per workload.
As shown in this Grafana chart, it’s not only the performance numbers that are better but also show how ScyllaDB achieves almost maximum system utilization.
For example for workload D with 1B keys dataset, ScyllaDB demonstrated 180K TPS with p99 latency of <5.5ms and CPU utilization only at 75%. This level of performance scalability is rare for most of the OSS distributed database systems.
Workload E produced the worst performance, only 10k ops. This was expected as the operations are short range scans instead of individual records. From YCSB: “Application example: threaded conversations, where each scan is for the posts in a given thread assumed to be clustered by thread id”.
Workload E is an antipattern for ScyllaDB unless it is modeled as a clustering key. ScyllaDB’s range partition scans are token-based which are randomly placed in the cluster, thus many random reads across multiple nodes are required to satisfy a single scan request.
Even with that said, for the range scan use-case (E) ScyllaDB outperformed CRDB by 5x.
CockroachDB
CockroachDB in its turn demonstrated performance scalability limits much earlier even with the 100M keys dataset: for workload A it showed 16K TPS with p99 of <52ms. It’s best result was achieved with workload D that showed 40K TPS with p99 <176ms at 80% utilization. Further increasing of the load did not lead to any throughput growth, but only to the growth of latency and its variance.
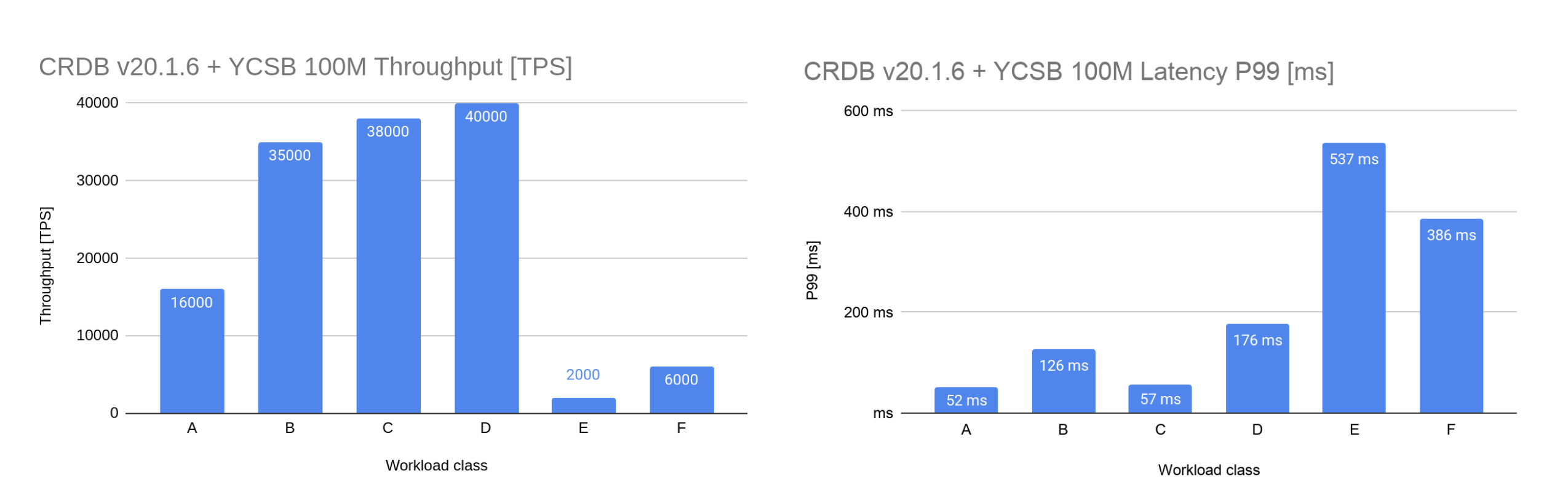
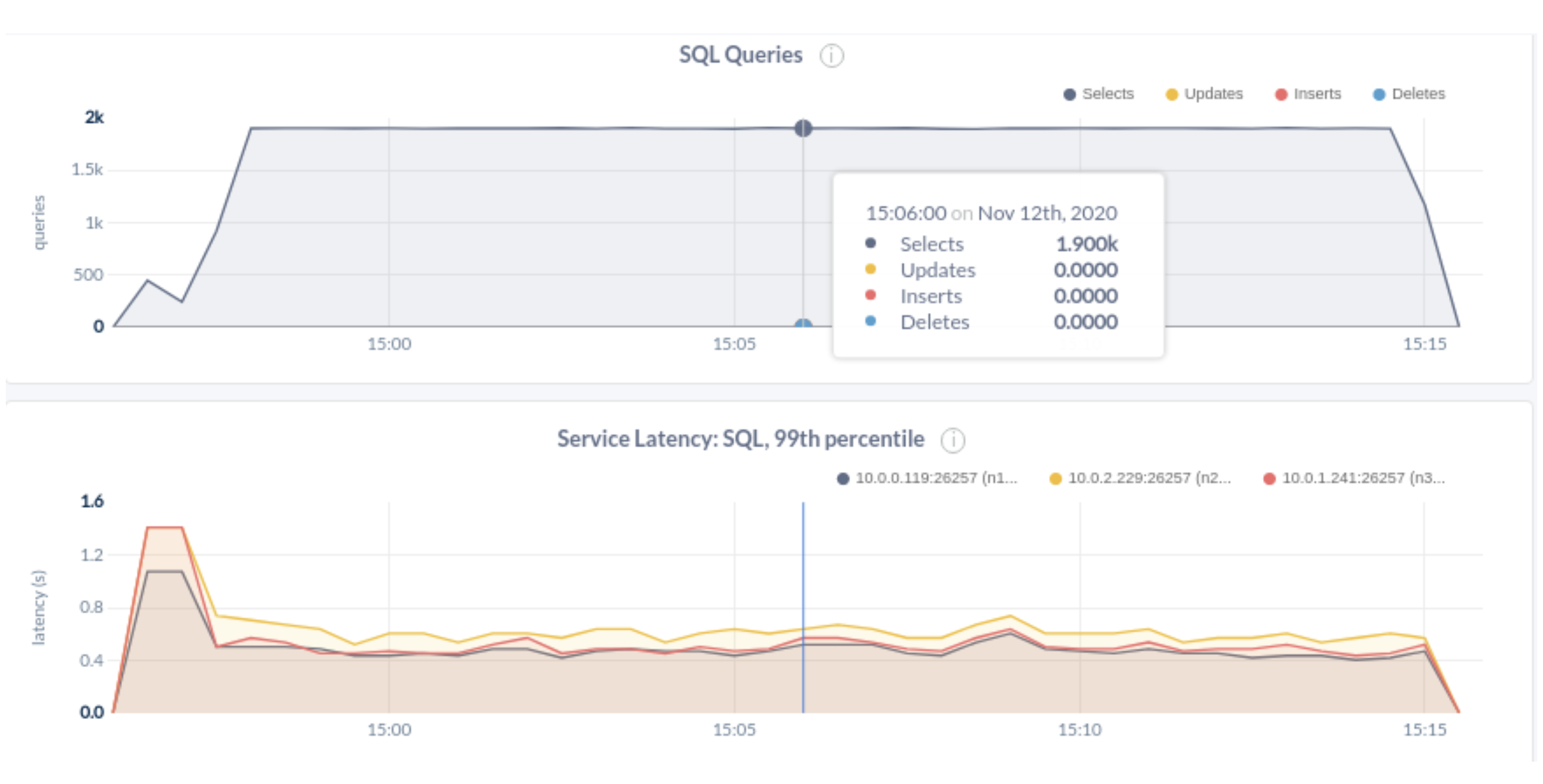
Below are the workload E results with 2k TPS and 537ms P99 latency.
Conclusion
NoSQL and NewSQL models are moving towards each other, each providing more functionality and better performance and availability than traditional database offerings. It is not a surprise that a NoSQL database such as ScyllaDB outperforms a distributed SQL database as CockroachDB by a large margin. The results do not mean that one should select ScyllaDB/NoSQL for every workload.
With 1B keys dataset, ScyllaDB showed 5x to 10x better throughput and stable low latencies while handling 10x amount of data. CockroachDB demonstrated throughput degradation while data loading, and during the YCSB workloads we measured throughput that closely matched the CRDB whitepaper, yet with larger and greater varying latencies.
Many modern workloads do not require strong consistency and can’t be straightjacketed by the imposition of operational limits to enormous scale requirements. These workloads are ideal for ScyllaDB, the monstrously fast and scalable NoSQL database. Other workloads, where strong consistency guarantees and transactions are required or the flexibility of a relational database model, with JOINs and sorted keys, and moderate amounts of data should consider a database such as CockroachDB.
Recently at the ScyllaDB summit we announced Project Circe, a 12 month roadmap plan that among other things adds the Raft consensus protocol and allows big improvements for strongly consistent workloads. CockroachDB on their end closed a huge round of funding and improved their LSM performance. Both databases are embraced by their respective communities for the capabilities they provide, and we hope our analysis helps you understand the differences between these systems. Stay tuned for more breakthroughs in this rapidly-evolving, fifty year old domain of distributed databases.
Appendix A
| Workload class | CRDB Whitepaper* [TPS] | CRDB Trial Throughput** [TPS] | ScyllaDB Trial Throughput [TPS] | CRDB Whitepaper* Latency p99 [ms] | CRDB Trial Latency p99** [ms] | ScyllaDB Trial Latency p99 [ms] |
| YCSB A | 20,000 | 16,000 | 150,000 | <3 ms | 52.4 ms | 12 ms |
| YCSB B | 50,000 | 35,000 | 150,000 | <3 ms | 125.8 ms | 7 ms |
| YCSB C | 62,000 | 38,000 | 180,000 | <3 ms | 56.6 ms | 12 ms |
| YCSB D | 53,000 | 40,000 | 180,000 | <3 ms | 176.2 ms | 5.5 ms |
| YCSB E | 17,000 | 2,000 | 10,000 | <3 ms | 536.9 ms | 21 ms |
| YCSB F | 18,000 | 6,000 | 100,000 | <3 ms | 385.9 ms | 26 ms |
* results observed by the CockroachDB authors published in section “6.1 Scalability of CockroachDB” and Figure 7: Throughput of CRDB and Spanner on YCSB A-F, Latency of CRDB and Spanner under a light load.
** YugaByte results match with ours: [throughput], [latency], [1B trial], [slowdown].
Appendix B
- CockroachDB setup configuration.
- ScyllaDB configuration
- Tests results and parameters
Appendix C
It is possible to compare basic requests (SELECTs and INSERTs) of those 2 databases because their read and write paths in the best cases are similar in terms of implied round trips (RTTs). Specifically ScyllaDB performs a Replication factor (RF) number of writes per insert waiting only for the Consistency level number of responses, and CL number of reads per select, while the CockroachDB can commit transaction in the best case in 1RTT replicating writes (RF) in parallel and serves reads directly from the lease holders (eq CL=1).
The best benchmark tool that can emulate different mixes of basic reads and writes operations is YCSB.


