



High Availability Database FAQs
What is High Availability?
A High Availability (HA) system is designed to operate continuously with no interruptions in service. That doesn’t mean the system never encounters errors, but it has enough redundancy built in to handle errors without causing a wider failure.
What is a High Availability Database System?
A High Availability (HA) Database is a database system designed to operate continuously with no interruptions in service. So database errors and failures must be handled by automatically failing over to redundant nodes when problems occur.
How Does ScyllaDB Support High Availability SLAs?
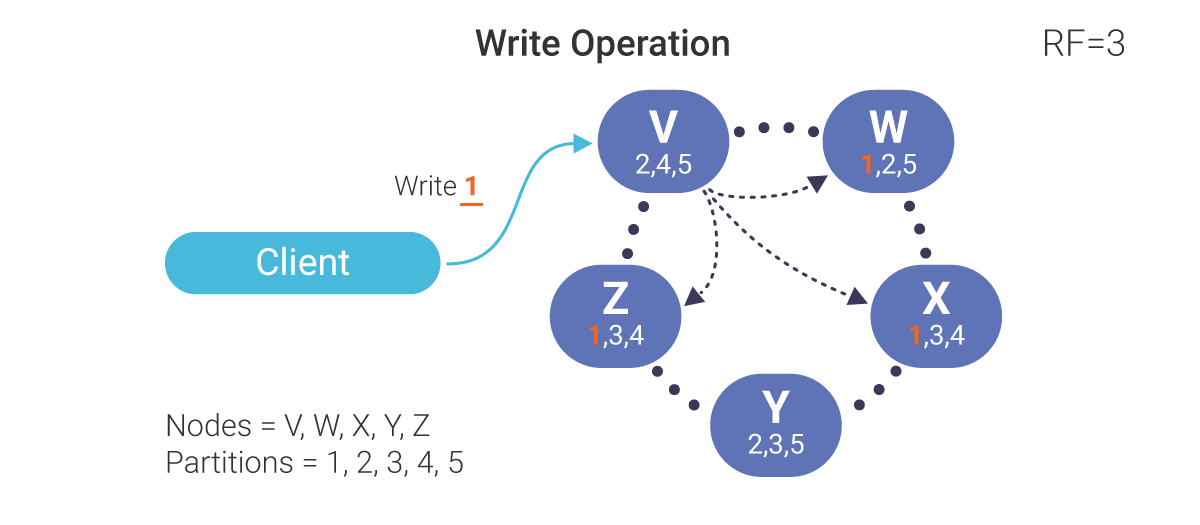
You have commitments to your customers, and those are often in the form of Service Level Agreements (SLAs). ScyllaDB helps you keep those commitments by giving you a configurable Replication Factor (RF) which specifies how many nodes each piece of data will be stored on. For many high availability systems, a Replication Factor of three nodes is sufficient. ScyllaDB also has a network topology strategy in its cross-datacenter replication, so that different datacenters may have different replication factors. For example, the main datacenter might have an RF=3, but a remote satellite datacenter might only have an RF=2.
ScyllaDB also staggers the distribution of data across partitions so that if one CPU is faulty, or even an entire node goes down the rest of the cluster does not become unduly overloaded. ScyllaDB’s high availability architecture is also rack-aware and even datacenter-aware, so that nodes can be distributed across racks in a datacenter, or across datacenters so that even if you lose an entire hardware rack, or an entire datacenter, your NoSQL database will remain up and available.
A ScyllaDB NoSQL database can also be affected by temporary or transient unavailability of a node, such as a server reboot. In case of such a temporary loss of a node, for upwards of a few hours, ScyllaDB knows how to maintain hinted handoffs. These are the writes, updates and deletes meant for a node that is temporarily unavailable. When the node comes back online and rejoins the ScyllaDB database cluster, it will be given all of the hinted handoffs meant for it as a backlog of transactions to process.
How Can a High Availability Database Eliminate a Single Point of Failure?
If multiple nodes relied on a single load balancer or similar controller, there would still be a single point of failure (SPOF). Any component that would cause downtime if it failed is considered a single point of failure. A High Availability (HA) Database must eliminate those single points of failure. ScyllaDB establishes a peer-to-peer relationship between database nodes, so the nodes can talk to each other without going through a central hub. This extends all the way to the network level. For instance ScyllaDB uses multiple IP addresses, rather than route all traffic through a single IP address for the cluster.
What are Common Use Cases for High Availability Databases?
High availability database solutions were once for only mission-critical applications such as emergency services, enterprise IT systems, cybersecurity, banking and finance, or government agencies. Now users have come to expect any web-based platform to be highly available. Some businesses will still publish notices of maintenance windows, but nowadays movie streaming services are expected to always be available to subscribers, and even free social media sites live up to the same expectation. Almost any Internet-connected application needs to be available all the time.
How Is High Availability Generally Achieved?
High availability architecture eliminates single points of failure. It requires at least one high availability cluster consisting of multiple nodes. That high availability database cluster must distribute the queries and transactions across the nodes so that the system always provides a timely response.
How To Ensure High Availability?
High availability database design requires enough nodes to properly distribute the load, and an appropriate consistency requirement. The more nodes, and the stronger the consistency model, the more latency is possible in the system. High availability database architecture begins with an understanding of your application. More nodes isn’t necessarily better.
What’s the Difference: High Availability vs. Fault Tolerance?
When we talk about database high availability solutions, we sometimes think of a traditional relational database that has a failover mechanism such as a transaction log shipping arrangement. Or we might consider cloud replication options and speak loosely of Azure database high availability or AWS high availability databases, simply because of their options for near-real time replication to read-only database copies. These providers have done a great job with implementing fault tolerance, but NoSQL high availability database systems go beyond a single database with multiple copies. NoSQL high availability depends on splitting the storage and transaction load across one or more high availability database clusters in multiple global regions or Availability Zones (AZs) so the processing is truly distributed.
Traditional databases focus on fault tolerance by maintaining highly consistent data in the case of component failure, preventing the database from writing additional data at all if it could in any way result in data inconsistencies or anomalies. This prioritizes the correctness of the database at the expense of system availability. Whereas modern NoSQL high availability databases would prefer that the database remain available for reads or writes even if it results in occasionally inconsistent data, producing transactions known as dirty writes or lost writes. This prioritizes the continuity of access, at the expense of the correctness of data.
What are Drawbacks of High Availability Database Systems?
The CAP Theorem says distributed databases have three critical properties: consistency, availability and partition tolerance. They can only maintain two of the three, so a high availability database must focus on availability. ScyllaDB focuses on high availability (“A”) and partition tolerance (“P”), so is referred to as an “AP” system. The third property, consistency, is not the priority of the system, so the data across all nodes will become consistent eventually, but may not be consistent immediately.
Another drawback is the space required for multiple nodes and multiple copies of the same data. ScyllaDB implements several compaction strategies to decrease the footprint of redundant copies of data.
Masterclass: Data Modeling for NoSQL Databases
 Looking for extensive training on about data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
Looking for extensive training on about data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
You can access the complete course here.
Does ScyllaDB Offer a High Availability Database?
ScyllaDB is a highly available fast NoSQL database. Disk drives, nodes, racks, and even whole datacenters can fail. Your applications must not fail. They remain always-on. That’s the goal for high availability database systems. ScyllaDB achieves zero downtime through a few mechanisms, including rack and datacenter awareness, as well as multi-datacenter replication.
A ScyllaDB cluster can span data centers colocated across any geographic space. Data in ScyllaDB is automatically synchronized across datacenters in an eventually consistent manner without requiring users to create any sort of streaming or batch processing to ensure the clusters communicate changes.