ScyllaDB powers real-time AI with low latency, high throughput, and billion-scale data.
Learn More



What is Distributed SQL?
Distributed SQL is one logical relational database system deployed in a single data center across multiple nodes or across many data centers as needed to deliver improved scale and resilience. Distributed SQL distributes data in a cluster while maintaining the ability to perform SQL queries on the data as if it were in a single location.
In a distributed SQL system, data is partitioned and distributed across multiple nodes, with each node storing a subset of the data. Ideally, these nodes communicate with each other to ensure that data is consistent across the cluster, and the system provides mechanisms for handling query optimization and execution across the distributed data.
Distributed SQL servers can provide advantages such as high availability, scalability, and fault tolerance, making them suitable for large-scale applications and complex workloads that require strong consistency with relatively high performance and reliability. Examples of modern distributed SQL databases include CockroachDB and Google Cloud Spanner, while YugabyteDB is an example of open-source distributed SQL.
What is the History of Distributed SQL?
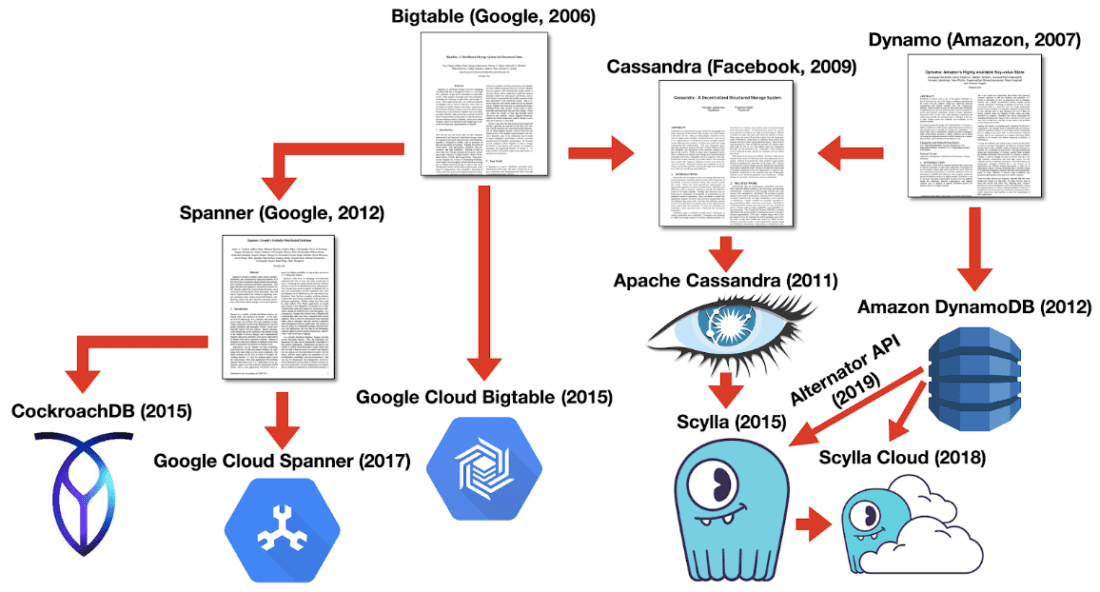
A team at Google took up the challenge and established a new generation of distributed databases that came to be known as “NewSQL” and then “distributed SQL.” The first distributed SQL database, Spanner, is a “scalable, multi-version, globally distributed, and synchronously replicated database.” Spanner was designed specifically to address limitations in Google’s Bigtable database. According to the white paper, Spanner was conceived in part for applications that require “strong consistency in the presence of wide-area replication.” How does Spanner accomplish this? The paper states that “the linchpin of Spanner’s feature set is TrueTime.” Spanner is able to consistently order transactions across distributed servers because servers in Google datacenters around the world all share precisely the same high-precision clocks (HPC). Spanner leverages TrueTime to execute transactions more efficiently.
Concepts from the Spanner paper were also incorporated in another distributed SQL database, CockroachDB. CockroachDB is an open-source alternative to Google’s implementation of Spanner. In contrast to Google Spanner, CockroachDB runs on commodity hardware, which lacks the high-precision clocks that help Spanner to scale consistent transactions. Instead, CockroachDB uses different, though similar, algorithms and techniques to provide distributed transactions like those of Spanner.
The model traditionally used for comparing tradeoffs in distributed systems is known as the “CAP theorem.” While not developed specifically for describing databases, the CAP theorem does provide a useful model for articulating the tradeoffs between NoSQL and distributed SQL databases. According to the CAP theorem a distributed system can provide only two of the following three attributes: Consistency, Availability, and Partition tolerance.
NoSQL databases are generally considered to be AP systems, providing Availability and Partition tolerance at the expense of Consistency. In contrast, distributed SQLdatabases provide Consistency, Availability and Partition tolerance. (According to Eric Brewer’s painstaking analysis, Google Spanner is technically a CP system that can claim to be an “effectively CA” system. Such nuances, while important, are beyond the scope of this paper.)
The fusion of strong consistency with distributed architecture is undeniably attractive. The question is whether distributed SQLcan deliver on this promise without compromising in other critical areas – primarily performance. Notably, the traditional CAP theorem makes no provision for performance or latency. For example, according to the CAP theorem, a database can be considered Available if a query returns a response after 30 days. Obviously, such latency would be unacceptable for any real-world application.
A newer way to model databases, called the PACELC theorem, extends beyond the CAP theorem model, showing that systems can either tend towards latency sensitivity or strong consistency. In this way, a distributed SQLsystem such as CockroachDB is defined as PC/EC — focusing on being strongly consistent — whereas a NoSQL system like ScyllaDB will be defined as PA/EL — highly available and latency sensitive.
What is the Difference Between NoSQL and Distributed SQL?
NoSQL and distributed SQL are both types of database systems, but they differ in several key ways.
Data model. NoSQL databases typically use non-relational data models such as wide column, key-value, document-oriented, or graph databases, while distributed SQL databases use a relational data model that supports SQL queries.
Scalability. Both NoSQL and distributed SQL databases can scale horizontally across multiple nodes, but they use different approaches.
Consistency. NoSQL databases often prioritize availability and partition tolerance over consistency, meaning that data may not be consistent across all nodes at all times. Distributed SQL databases typically prioritize consistency and use techniques such as distributed transactions and quorum-based replication to ensure data consistency across all nodes.
Query language. NoSQL databases often do not support SQL, instead offering their own query languages (such as CQL) or APIs. Distributed SQL databases, in contrast, support SQL and can be used with existing SQL-based applications and tools.
Although there is some overlap between the two types of databases, NoSQL databases are often used for high-velocity, high-volume, and unstructured data, while distributed SQL databases are more commonly used for structured data that requires strong consistency and support for SQL.
What is New SQL?
NewSQL is a term sometimes used to refer to the class of relational database management systems that seeks to scale online transaction processing (OLTP) workloads in a distributed manner – like NoSQL systems do, but without losing the ACID (Atomicity, Consistency, Isolation, and Durability) guarantees ensured in a classic relational database system.
Almost all traditional relational database systems use structured query language (SQL), the underpinning concepts of which are represented by ACID guarantees. SQL databases can also be called relational database management systems (RDBMS).
With the advent of “big data” during the late 2000s, a new type of non-relational databases grouped under the term NoSQL emerged to address growing numbers of problems related to mass data storage. These NoSQL databases offer better scaling, flexible schemas, and faster queries but do not offer ACID transactional support.
By 2011 there was a proposed fix in the form of NewSQL systems. This new type of relational database was created to deliver NoSQL scalability while maintaining traditional ACID compliance.
NewSQL actually refers to a group of emerging database vendors and products that includes distributed database-as-a-service cloud offerings, middleware with similar sharding infrastructure to Google and others, and novel systems with new architecture.
In contrast, NoSQL is more purpose-built to support flexible data processing and application development requirements that were ill-suited to the relational database model. NewSQL aims to retain the performance, consistency, structure, and transactional support of the relational data model while delivering the NoSQL scalability advantage.
NoSQL and NewSQL Databases: Are They Distributed Databases?
Usually, but not always. While both NoSQL and NewSQL databases can be distributed, it is not a requirement for either type of database.
NoSQL databases are often designed to be horizontally scalable, meaning that they can scale by adding more nodes to the cluster. This scalability is often achieved through sharding, where the data is partitioned across multiple nodes. However, not all NoSQL databases are distributed.
NewSQL databases, on the other hand, are designed to combine the benefits of traditional SQL databases with the scalability of NoSQL databases. NewSQL databases typically use distributed architectures to achieve scalability, but not all NewSQL databases are distributed.
Some NoSQL databases and NewSQL databases are designed to be single-node databases optimized for fast data access and do not support horizontal scaling. Being distributed is not a requirement for either type of database. The decision to use a distributed structure depends on the specific needs of the application, such as scalability, fault tolerance, and consistency.
Distributed SQL vs NoSQL and NewSQL Databases
What is the difference between NoSQL vs distributed SQL? First, consider the difference between NewSQL vs distributed SQL.
Distributed SQL databases are built from the ground-up, while NewSQL databases tend to add synchronous replication and sharding technologies to existing client-server relational databases like PostgreSQL. However, both achieve most of the same goals.
What is the more general difference, then, between NewSQL vs NoSQL?
The basic difference between NewSQL and NoSQL is that NoSQL databases use documents, graphs, a key-value pair, or wide column stores without a typical schema. NewSQL, an even more recent development in database systems, seeks to retain qualities of a relational database yet achieve the scalable properties of NoSQL.
Yet to really understand how NewSQL systems work, it is important to explore the difference between SQL, NoSQL, and NewSQL. This is because NewSQL architecture is really a reaction to both SQL and NoSQL approaches.
Relational databases arrange data into different columns and rows, associating each row with a specific key. Almost all relational database systems use structured query language (SQL).
The underpinning concepts of SQL relational databases exist to maintain the reliability of transactions and are represented by ACID: Atomicity, Consistency, Isolation, Durability.
Atomicity sees a transaction as an all or nothing prospect: it is completed as a whole or not at all. Consistency ensures the database remains stable with or without changes. Isolation ensures that multiple transactions do not interfere with each other. And durability refers to any permanent effects changes to the database may have.
However, RDBMS suffer greatly from some major drawbacks although they also provide exclusive features.
- Rigid Data Modeling. A primary limitation of the RDBMS is the inherent rigidity of organizing the data into the specific structure in tables and relations.
- Diversity. The complexity of big data also limits the usefulness of RDBMS; complex images, numbers, and multimedia data are difficult to access, store, and process.
- Inefficient Use of Space. It’s necessary to define the size of all the attributes when we define the schema, but not all records fit into the given data type or use their full space.
- Heavyweight Changes. Any changes one record requires must be applied to all records, and these heavyweight changes can be infeasible and costly.
- Inefficient for Big Data. SQL is unsuitable for data at high volume, in great variety, or traveling at velocity, making it inefficient for cloud-based applications.
NoSQL developed to help process massive amounts of unstructured data rapidly and is best understood as an alternative to relational databases. The most common interpretation of NoSQL is, “Not only SQL,” meaning that some systems may yet support SQL-like query languages.
NoSQL systems handle large amounts of both structured and unstructured data, and they do it quickly due in part to their distributed nature and non-relational, ad-hoc approach to organizing data. NoSQL was devised to work around the limitations of SQL and provide fast scalability when handling big data applications or dealing with unstructured data platforms.
Core NoSQL concepts include:
- Lack of schema. Supports structured, semi-structured, and unstructured data.
- Auto balancing. Automatic division of data among multiple servers, without assistance from applications.
- Integrated caching. Data cached in system memory to increase performance and data throughput for high reliability and scalability with a simple query language and data model.
- The BASE transaction principle. As ACID provides foundational concepts for SQL, BASE principles (Basically Available Soft-state, Eventually consistent) ensure NoSQL reliability.
NoSQL databases also experience several drawbacks, which include:
- Lack of consistency. Prioritizing availability over consistency is less ideal for functions such as financial transactions.
- Lack of analytics. A relational model is important for processing data in analytics, which means increased cost overhead as the whole database needs to be converted using a relational model.
- Lack of standardization. No specific, standardized language.
- Security. At the elemental data level NoSQL does not provide security.
- Transactional nature. High-volume transactions demand a highly scalable, strongly consistent database, so NoSQL fails when the database needs to perform this type of task.
How Does Distributed SQL Work?
Distributed databases are designed to address the challenges presented by both NoSQL and traditional RDBMS by leveraging the benefits of both approaches.
One of the main challenges with traditional RDBMS is their limited scalability. As the amount of data grows, RDBMS systems can become slow and expensive to operate. Distributed databases, on the other hand, are designed to scale horizontally by adding more servers to the cluster. This allows them to handle large volumes of data and high levels of traffic and create utilities such as cloud availability zones.
NoSQL databases are designed to handle unstructured or semi-structured data, which can be difficult to store in traditional RDBMS systems. However, NoSQL databases can also present challenges such as limited query capabilities and eventual consistency. Distributed databases can help address these challenges by providing more advanced query capabilities and strong consistency guarantees.
Additionally, distributed databases can help improve data availability and fault tolerance. By replicating data across multiple servers, distributed databases can ensure that data is always available even if some servers fail. This can be especially important in mission-critical applications where downtime can be costly.
The core concepts of distributed SQL databases include:
Distributed architecture. Distributed SQL databases are designed to operate across multiple nodes or servers in a cluster, with each node responsible for storing a portion of the data. The distributed architecture enables the database to scale horizontally as more nodes are added to the cluster.
Data partitioning. To enable distributed operation, the system will distribute data and partition or shard it across the nodes in the cluster. Each node is responsible for storing and processing a subset of the data. This partitioning can be based on a variety of factors, such as hash-based partitioning or range-based partitioning.
Consistency. To ensure data consistency across the distributed nodes, distributed SQL databases use techniques such as distributed transactions and quorum-based replication. These techniques ensure that all nodes in the cluster have a consistent view of the data.
Query optimization. To optimize query performance across the distributed data, distributed SQL databases use techniques such as query routing and query planning. Query routing determines which node is responsible for processing a query, while query planning determines the most efficient way to execute the query across the distributed data.
High availability and fault tolerance. Distributed SQL databases are designed to be highly available and fault-tolerant, meaning that they can continue to operate even if one or more nodes in the cluster fail. To achieve high availability, distributed SQL databases use techniques such as node redundancy and automatic failover.
Distributed SQL Implementations
Distributed SQL databases are typically implemented using a shared-nothing architecture. In this architecture, each server in the cluster has its own CPU, memory, and disk storage. The servers communicate with each other over a high-speed network, and the database software coordinates data access and updates across the servers.
The implementation of distributed SQL databases involves several key components:
Query router. The query router is responsible for routing queries to the appropriate server in the cluster. It also coordinates query execution across multiple servers if necessary.
Distributed storage. Distributed SQL databases use distributed storage to store data across multiple servers in the cluster. This provides high availability and scalability by allowing data to be replicated across multiple servers.
Distributed transaction manager. The distributed transaction manager is responsible for coordinating transactions across multiple servers in the cluster. It ensures that transactions are executed atomically and consistently across all servers.
Distributed metadata manager. The distributed metadata manager is responsible for managing the metadata of the database, such as schema information, data partitioning, and replication settings. It ensures that all servers in the cluster have consistent metadata.
Distributed lock manager. The distributed lock manager is responsible for managing locks on data objects to ensure data consistency and prevent conflicts in concurrent transactions.
Distributed SQL databases also use a number of optimization techniques to improve performance, such as partitioning data across servers, caching frequently accessed data, and optimizing query execution plans.
Advantages and Disadvantages of Distributed SQL
The advantages of using distributed SQL include:
Scalability. Distributed SQL databases can scale horizontally by adding more servers to the cluster. This allows them to handle large volumes of data and high levels of traffic.
Flexibility. Distributed SQL databases can handle both structured and unstructured data, making them a good fit for a wide range of applications.
Consistency. Distributed SQL databases can provide strong consistency guarantees, ensuring that data is always accurate and up-to-date.
Query capabilities. SQL is a powerful language for querying and analyzing data, and distributed SQL databases can provide advanced query capabilities such as joins, aggregation, and complex queries.
Performance. With proper tuning and optimization, distributed SQL databases can provide high performance for both read and write operations. However, the performance is significantly less than what NoSQL can achieve [read distributed SQL vs NoSQL benchmark]
Disadvantages of using distributed SQL include:
Complexity. A distributed SQL dd can be more complex to set up and manage than traditional RDBMS systems.
Cost. The cost of operating a distributed SQL database can be higher than traditional RDBMS systems due to the need for additional hardware and software.
Latency. When data is spread across multiple servers, there can be additional network latency when querying the database.
Data security. Because data is distributed across multiple servers, it can be more difficult to ensure that data is properly secured.
Operational complexity. Because distributed SQL databases are complex systems, they require specialized skills to manage and maintain.
Distributed SQL Use Cases
Distributed SQL databases are designed to handle large volumes of structured and semi-structured data in a distributed environment. Some common use cases for distributed SQL include:
Web applications. Distributed SQL databases are well-suited for web applications that require high scalability and availability. They can handle large volumes of user data and traffic, and provide fast and reliable response times.
E-commerce. Distributed SQL databases can be used in e-commerce applications to manage large volumes of transactional data, such as order history and customer information. They can also provide real-time inventory management and order processing.
IoT (Internet of Things). With the proliferation of IoT devices, there is a need for databases that can handle the large volumes of data generated by these devices. Distributed SQL databases can provide fast and efficient storage and analysis of sensor data, machine logs, and other IoT data.
Financial services. Distributed SQL databases can be used in financial services applications to manage large volumes of transactional data, such as trading and investment history, and provide real-time analysis of market data.
Gaming. Distributed SQL databases can be used in gaming applications to manage user profiles, leaderboards, and game state data. They can also provide real-time distributed SQL analytics to improve game performance and user experience.
How Does ScyllaDB Compare to Distributed SQL?
ScyllaDB is NoSQL database focused that is architected to deliver predictable low latencies (single digit millisecond or submillisecond P99 latencies) at high throughput (millions of IOPS).
In terms of performance, ScyllaDB offers significantly better performance than distributed SQL (e.g., CockroachDB). Benchmarks found that ScyllaDB achieve 10X the volume, 9X the throughput, and 4X lower latency vs distributed SQL on YCSB tests. [Read the ScyllaDB NoSQL vs Distributed SQL benchmark].
In terms of the CAP theorem, ScyllaDB chooses availability and partition tolerance over consistency (which is prioritized by distributed SQL databases. ScyllaDB (as well as Apache Cassandra and other NoSQL databases), sacrifice a degree of consistency in order to increase availability. Rather than providing strong consistency, they provide eventual consistency. This means that in some cases, a read request will fail to return the result of the latest WRITE.
For many workloads, low latency and high availability are more critical than strong consistency. For example, during partitioning, an isolated datacenter should continue to accept reads and writes. Companies’ tolerance for eventual consistency has been increasing. Moreover, features like “tuneable consistency” make it possible to prioritize consistency over latency at the query level, overriding keyspace or even datacenter-wide consistency settings. Lightweight transactions provide another path towards ACID with a lower performance penalty. And now, innovative implementations of Raft are paving the way for high-performance low latency databases like ScyllaDB to achieve strong consistency.