



Low-Latency Database FAQs
What is the Best Way to Measure Latency?
IT organizations often fail to address latency in a holistic way. For a variety of reasons, teams that test and monitor applications tend to focus on average performance measurements. This is not surprising; most of the tools developed for application performance monitoring are built to report averages by default. The problem with averages is that they conceal latency outliers – extreme deviations from the norm that may have a large impact on overall system performance.
Furthermore, human users never actually experience ‘average performance.’ Average latency is a theoretical measurement that has little direct bearing on end user experience.
Percentile-based metrics offer a better measure of real-world performance. The reason is that each measurement within a given percentile reflects a real latency that actually occurred.
Latency is typically calculated in the 50th, 90th, 95th, and 99th percentiles. These are commonly referred to as p50, p90, p95, and p99 latencies. Percentile-based metrics can be used to expose the outliers that constitute the ‘long-tail’ of performance. Measurements of 99th (“p99”) and above are considered measurements of ‘long-tail latency’.
A p50 measurement, for example, measures the median performance of a system. Imagine 10 latency measurements: 1, 2, 5, 5, 18, 25, 33, 36, 122, and 1000 milliseconds (ms). The p50 measurement is 18 ms. 50% of users experienced that latency or less. The p90 measurement is 122, meaning that 9 of the 10 latencies measured less than 122.
Yet, even percentile-based measurements can be misinterpreted. For example, it is a mistake to assume that ‘p99” means that only 1% of users experience that set of latencies. In fact, p99 latencies can easily be experienced by 50% or more end users interacting with the system. So p99 (and higher) outlier latencies can actually have a disproportionate effect on the system as a whole. A low latency database can therefore be understood as a database that is architected to minimize p99 latencies.
How to Eliminate Causes of High Latency in Databases?
High latencies can be minimized by choosing the right type of database for applications that require low latency. NoSQL databases tend to be able to deliver lower response latencies than traditional relational database management systems (RDBMSs). RDBMSs are architected primarily to ensure that transactions are strongly consistent. As such, they emphasize such consistency over performance and are used for applications that depend on a constantly updated distributed ledger of transactions. More information on SQL vs NoSQL.
Many modern applications, however, require low latency and higher throughput and are able to sacrifice the consistency afforded by an RDBMS. Being designed without support for JOINs, NoSQL low-latency databases avoid this basic cause of higher latencies. As tables grow in size, RDBMSs also typically incur long table scans. Databases, in particular NoSQL wide column stores, are built to store each column separately, cutting query times, even for large volumes of data. As such, the key step towards eliminating high latencies is the adoption of a non-relational, NoSQL database.
Even within the family of non-relational NoSQL, database offerings have a wide range of performance characteristics. IT teams can minimize latency by matching an application use case to the appropriate database.
How Can I Achieve Database Low Latency?
For networked applications, latency is unavoidable; database operations will always add to the overall latency experienced by a user. The time required to add, update, and retrieve data can never be zero. Interaction with the physical storage layer will always add ‘disk latency’, even where high-performance solid-state drives (SSDs) are used.
The distributed architecture of NoSQL databases helps to address latency by enabling deployment topologies that place data closer to globally distributed users, thus minimizing network latency. Similarly, NoSQL databases do not impose latency caused by locks. Database operations can be executed against nodes across the cluster relatively independently. Even though more copies of the data are stored across a cluster, the time to access that data is reduced, since the application waits only for the fastest nodes, without waiting for slower nodes to catch up.
What is the Best Low-Latency NoSQL Database?
NoSQL databases are designed to handle scenarios that are not well-suited to relational databases. NoSQL databases are intended for high throughput of large volumes of data across multiple nodes where low latency is more important than immediate consistency across all nodes.
Independent tests of high-speed low-latency databases have shown both Apache HBase and Cassandra outperforming MongoDB across a variety of workloads. Cassandra, however, proved to have an ‘Achilles heel’. Being implemented in Java, it is vulnerable to the weaknesses of that platform. First, it is susceptible to pauses caused by garbage collection (GC), to the degree that some monitoring teams use a specific metric devoted to GC stall percentage. Compaction and repair operations, which become more onerous in larger clusters, add to performance outliers.
ScyllaDB, a NoSQL database architected for data-intensive apps that require high performance and low latency, introduces a range of design choices that minimize latency. ScyllaDB is built in C++ instead of Java, eliminating the costly garbage collection of managed code. ScyllaDB is also designed to maximize the power of modern high-speed hardware, which is capable of performing millions of I/O operations per second (IOPS). To take advantage of this speed, software needs to be asynchronous, enabling it to drive both I/O and CPU processing in a way that scales linearly with the number of CPU cores. Besides being built in C++, ScyllaDB’s architecture as a whole is asynchronous, enabling components within the database to operate independently.
How Does Cassandra Compare to ScyllaDB?
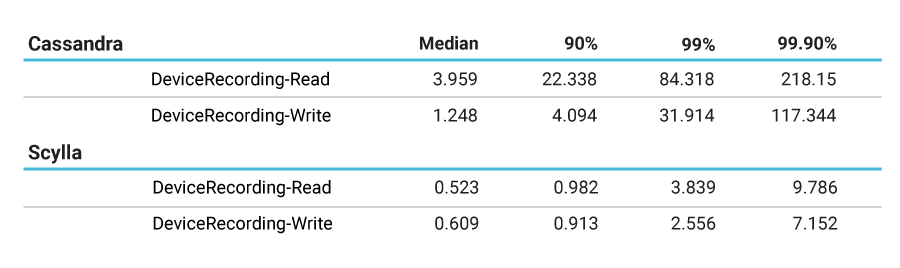
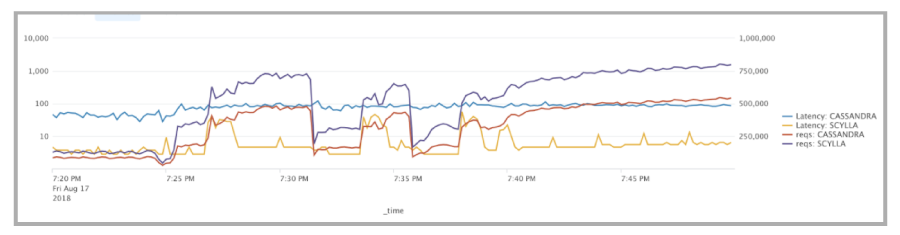
Comcast, a major user of ScyllaDB, benchmarked ScyllaDB against Cassandra prior to deploying in production. They found that under their synthetic load tests they were able to achieve 8ms latency with ScyllaDB compared to 100ms with Cassandra, a 92% reduction in typical latency and a 95% reduction in their p99 latency.
Testing Cassandra and ScyllaDB side-by-side, Comcast measured significant differences in the long-tail of performance, as shown by the metrics below:
Many similar performance benchmarks, including comparisons with AWS DynamoDB and Google BigTable, are available in ScyllaDB’s NoSQL Database Benchmarks resource.
What are the Challenges for Low-Latency Databases?
Databases increasingly serve global consumer bases. To achieve high availability, the database topology is often geographically distributed, with database clusters deployed in multiple data centers around the world. The basic premise of NoSQL is its ability to ‘scale out’ on cheap, commodity hardware. When more capacity is needed, administrators can simply add servers to database clusters. Such distributed architectures have the potential to produce unpredictable latency, which can be caused by context switches, disk failures, and network hiccups.
Many IT organizations turn to external caches as a band-aid designed to insulate end users from the poor long-tail performance of the databases. But the limitations of external caches are well-known.
Does ScyllaDB Offer a Low-Latency Database?
ScyllaDB was built from the ground to deliver high performance and consistent low-latency. The team that invented ScyllaDB has deep roots in low-level kernel programming. They created the KVM hypervisor, which now powers Google, AWS, OpenStack, and many other public clouds.
ScyllaDB is built in C++ instead of Java. ScyllaDB is built on an advanced, open-source C++ framework for high-performance server applications on modern hardware. One example of the way ScyllaDB improves upon Cassandra by using C++ is its kernel-level API enhancement. Such an enhancement would be impossible in Java. This is the fundamental first step toward taming long-tail latencies.
The low-latency design is enabled by an asynchronous, shard-per-core architecture, a dedicated cache, along with tunable consistency and autonomous, self tuning operations.
ScyllaDB’s ability to deliver low and predictable long-tail latencies has led to its adoption in industries such as social media, AdTech, cybersecurity, and the industrial Internet of Things (iIoT).