



Eventual Consistency FAQs
What is Eventual Consistency?
Consistency refers to a database query returning the same data each time the same request is made. Strong consistency means the latest data is returned, but, due to internal consistency methods, it may result with higher latency or delay. With eventual consistency, results are less consistent early on, but they are provided much faster with low latency. Early results of eventual consistency data queries may not have the most recent updates because it takes time for updates to reach replicas across a database cluster.
What is Eventual Consistency In NoSQL?
A key benefit of an eventually consistent database is that it supports the high availability model of NoSQL. Eventually consistent databases prioritize availability over strong consistency. Eventual consistency in microservices can support an always-available API that must be responsive, even if the query results may occasionally be missing the latest commit.
 Video: Distributed Database Consistency: Architectural Considerations and Tradeoffs
Video: Distributed Database Consistency: Architectural Considerations and Tradeoffs
Explore the technologies and trends behind a new generation of distributed databases, then take a technical deep dive into one example: ScyllaDB. ScyllaDB was built specifically for extreme low latencies, but has recently increased consistency by implementing the Raft consensus protocol. Engineers will share how they are implementing a low-latency architecture, and how strongly consistent topology and schema changes enable highly reliable and safe systems, without sacrificing low-latency characteristics.
ACID vs. BASE: How is Eventual Consistency Similar to Strong Consistency?
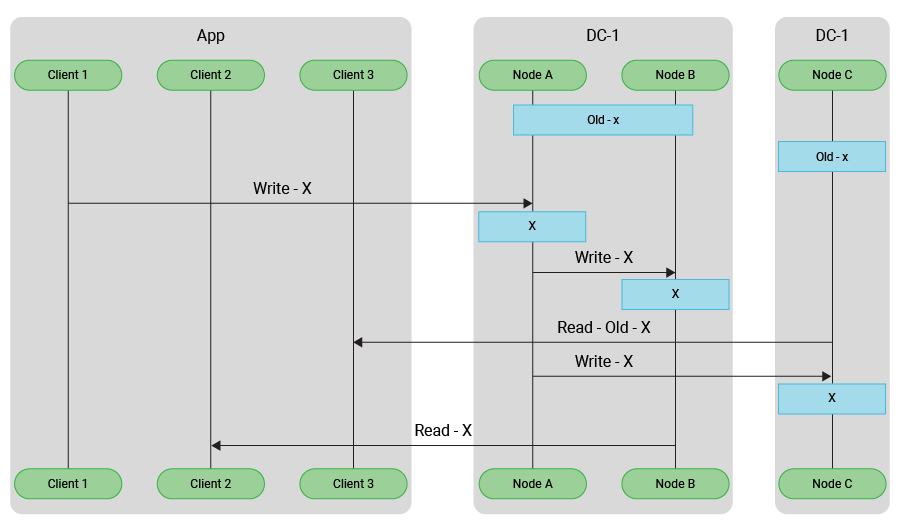
Eventual consistency in general refers to a database’s ability to process transactions simultaneously while preserving the integrity of the data. In simple terms, inconsistency designates the guarantee that a READ should return the result of the latest successful WRITE. This seems simple, but such a guarantee is incredibly difficult to deliver in a globally distributed database topology, that involves multiple clusters each containing many nodes.
In general, relational databases that support ‘strong consistency’ provide ‘ACID guarantees’. ACID is an acronym designed to capture the essential elements of a strongly consistent database. The components of ACID are as follows:
- Atomicity – if transaction fails at any point, the entire operation rolls back
- Consistency – the database remains structurally sound with every transaction
- Isolation – each transaction is independent of any other transaction
- Durability – all transaction results are permanently preserved
ACID compliance is a complex and often contested topic. In fact, one popular system of analysis, the Jepsen tests, are dedicated to verifying vendor consistency claims.
For this reason, ACID-compliant databases are generally slow, difficult to scale, and expensive to run and maintain. Some RDBMS systems, it should be noted, enable ACID guarantees to be relaxed. Still, all SQL databases are ACID compliant to varying degrees, they all share this downside. it is extraordinarily difficult and expensive to achieve resilient, distributed SQL database deployments.
ACID vs. BASE: How is Eventual Consistency Different from Strong Consistency?
A DBMS using the ACID model expects a unit of work to be atomic. It is all-or-nothing. While that unit of work is being done, the records or tables affected may be locked. Distributed databases with a BASE model give high availability. The records stay available, but once the transaction has completed across a majority of nodes, the transaction is deemed successful. Data replication across all nodes can take a little more time, but the data in all nodes will become consistent eventually. Once the transaction is deemed successful, queries for the data will consistently provide the updated data, even before data replication reaches the last few nodes.
Early results of eventual consistency data queries may not have the most recent updates. This is because it takes time for updates to reach replicas across a database cluster. In strong consistency, data is sent to every replica the moment a query is made. This causes delay because responses to any new requests must wait while the replicas are updated. When the data is consistent, the waiting requests are handled in the order they arrived and the cycle repeats.
In contrast to SQL’s ACID guarantees, NoSQL databases provide so-called BASE guarantees. A BASE enables availability and relaxes the stringent consistency. The acronym BASE designates:
- Basic Availability – Data is available most of the time, even during a partial system failure.
- Soft state – replicas are not consistent all the time.
- Eventual consistency – data will become consistent at some point in time, with no guarantee when.
As such, NoSQL databases sacrifice a degree of consistency in order to increase availability. Rather than providing strong consistency, they provide eventual consistency. This means that a datastore that provides BASE guarantees can occasionally fail to return the result of the latest WRITE.
In a globally distributed eventual consistency NoSQL database deployment, some transactions might overlap. In a typical example, an eventual consistency NoSQL database might permit a hotel room to be reserved on the same night by two different customers, one in Hong Kong and the other in New York City. For many business applications, this is not a problem. The resilience, availability, and low-latency afforded by NoSQL are well worth the tradeoff. The hotel can provide perks to a disgruntled customer, but, by contrast, a regional outage could create significant churn.
What Are Eventual Consistency Examples?
Eventually consistent NoSQL databases choose how to implement eventual consistency in some different ways. Eventual consistency in NoSQL supports the BASE (basically available eventually consistent) pattern for speed and scalability.
In AWS eventual consistency can refer to more than one eventual consistency database. DynamoDB eventual consistency and Cassandra eventual consistency both depend on a ring topology where data is spread to more than one peer database node. A good example is DynamoDB eventual consistency vs strong consistency with results written to a majority of nodes, and eventually updating all nodes. As long as a majority of nodes are consulted on the read process, the read will get either conflicting values, or the latest value.
Redis eventual consistency offers another way how eventual consistency is achieved. Redis uses a master-slave topology for how to handle eventual consistency, relying on replication from the master node to the slave nodes.
ElasticSearch eventual consistency is handled similarly to Redis with a master node and plus a primary shard and replica shards. The ElasticSearch eventual consistency pattern is also a hybrid with the methods of eventual consistency Cassandra and DynamoDB utilize, because ElasticSearch also offers consistency parameters to indicate how many shards must be written or read for a successful operation.
Masterclass: Data Modeling for NoSQL Databases
 Looking for extensive training on about data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
Looking for extensive training on about data modeling for NoSQL Databases? Our experts offer a 3-hour masterclass that assists practitioners wanting to migrate from SQL to NoSQL or advance their understanding of NoSQL data modeling. This free, self-paced class covers techniques and best practices on NoSQL data modeling that will help you steer clear of mistakes that could inconvenience any engineering team.
You can access the complete course here.
Does ScyllaDB Offer Eventual Consistency for distributed databases?
ScyllaDB is the company beyond ScyllaDB, the monstrously fast and scalable NoSQL database. ScyllaDB offers tunable consistency, which enables IT to set consistency levels for the cluster overall. It also allows each operation (each read or write) to have its own consistency level, a feature known as tunable consistency.
Because data may have changed on a coordinator node, but it may not have yet been recorded and stored on all the required replicas, a ScyllaDB cluster offers eventual consistency. With eventual consistency all of the replica nodes will eventually arrive at the same data state; operations may continue updating the database in the meantime.
ScyllaDB supports eventual consistency patterns from very low consistency with a Consistency Level of One or Any, all the way up to a Consistency Level of All. The sweet spot for most high performance applications will be somewhere in the middle, so a quorum where a majority of nodes must be written or read is the default starting point. With NoSQL eventual consistency can be implemented several ways, and ScyllaDB is flexible enough with its multi modes and tunable consistency to achieve anything from an eventually consistent key value datastore all the way to more complex database eventual consistency implementations.