
I recently had the pleasure of exchanging a few questions and answers with Guy Shtub, Manager of ScyllaDB University. Guy had some exciting news about a new module available for ScyllaDB University users plus shared his insights into what else is in the works.
Tell us about the new Data Modeling section of ScyllaDB University.
Data modeling is an important topic when approaching databases in general and specifically ScyllaDB. What we did with the University is we created a new lesson which is quite extensive. It starts with the basics of data modeling and gives an overview of how to get started and how to do it correctly. Going over concepts such as primary key, partitioning key, clustering key. The importance of choosing those keys. We saw that many users — even some that are more experienced — ran into issues getting those concepts confused, and also, in doing the data modeling itself and choosing the right keys or the correct way to actually data model.
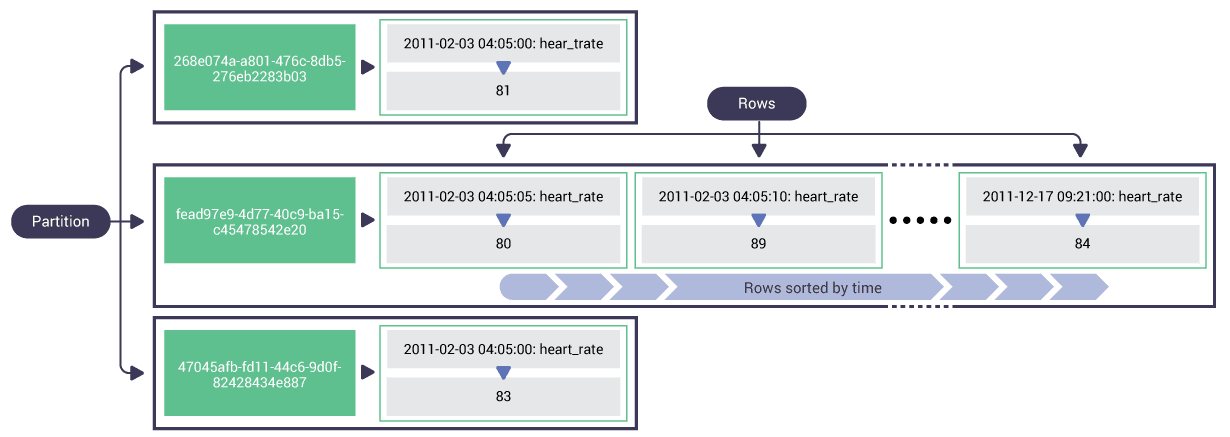
An image from the new data modeling module of ScyllaDB Essentials
So is this a whole new course, or is it part of a larger course?
It’s part of a larger course. It’s part of the ScyllaDB Essentials – Overview of ScyllaDB course. We previously did have a much shorter and less-extensive data modeling lesson however we completely rewrote it from scratch. And created one that goes into more details, has hands-on exercises, and explains this subject in more depth.
What are the most crucial concepts to understand about data modeling in ScyllaDB or even Cassandra?
I think, since most people that approach data modeling in ScyllaDB already have some database experience, whether it’s SQL or NoSQL, the most important concept is to understand that when approaching data modeling in ScyllaDB, or Cassandra for that matter, we have to think about the application and the actual queries that will be performed at the beginning of the data modeling process. On the other hand, the typical data modeling process with relational databases starts with our domain. That includes identifying the different entities in the domain, the relationships between them, and breaking that down until finally the database schema is created, the physical data model is created. The queries and the application are something that is thought about only at the end of the process. So the queries are more of an afterthought.
On the other hand, when we talk about data modeling in ScyllaDB or Cassandra we have to think about the application and about the queries that will be performed very early on in the process. That’s a very important point. So it’s not that we don’t think about the domain and the entities and the relationships between those entities at all, but we just do that in addition to thinking about the application and the different queries that will be performed. And then we base our data model on both of those things. So also the domain and also on the application.
ScyllaDB University was announced at ScyllaDB Summit 2018, and was featured in a blog in February 2019. How many people have gone through ScyllaDB University in these first months of availability?
We’ve had quite a success with the University. We’ve had hundreds of people register and go through thousands of steps on the University.
What are the next courses that you’re working on?
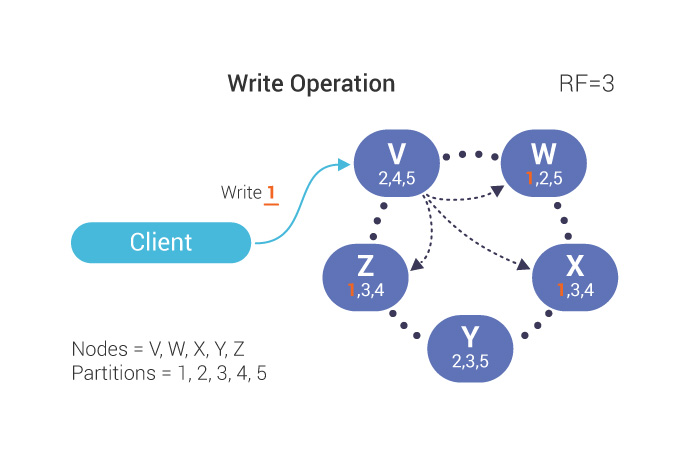
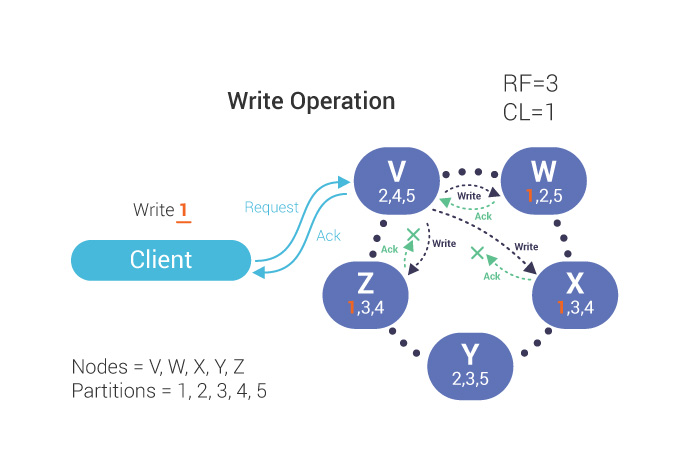
Some of the things that we are doing right now is developing a course that is called the “Mutant Monitoring System.” What we did there is we provided a story arc for ScyllaDB training. And in each lesson, we talk about a different topic starting from the very basics and moving on to more advanced topics. The first lessons deal with how to get a ScyllaDB cluster up and running, about high availability, for example, consistency levels, replication factor. Then we talk about using multiple datacenters. That is, replicating data across different geographical locations. As we move forward in the course we go into more interesting and more advanced topics. The students can take each one of these lessons at their own pace.
It’s not an extensive course, like the ScyllaDB Essentials, which covers everything from the beginning. So we do expect the trainees to have some prior knowledge about ScyllaDB. However, in every place that we introduce a new term, we reference either the documentation or other lessons that explain that term. It’s a pretty cool way to dive into a specific issue that’s interesting for the student. For example, monitoring multiple datacenters, repair, and other interesting subjects.
The Mutant Monitoring System is based on a series of blog posts that were released a few months ago. We’re updating those posts. and making sure that everything is up-to-date and working.
I saw that there’s also a course that complements on-site training. Can you tell us more about that?
Right. So the University is relatively new. We wanted to put as much material on the University as soon as possible and make it available to our trainees and ScyllaDB users. What we did there is we took slides from some more advanced courses that we typically use when we provide on-site training. As a first stage, we put those slides on the website as a separate course. We updated those slides and added some quiz questions. We put that as something initial that would create value to the user as it is.
Our plans for the future is to take that course and those lessons and make them more interactive. More hands-on. To improve that material. But until we get that done, we didn’t want to have people waiting for that material. So we just put an initial version online, which still creates value and which will be improved in the future.
Is there anything else you wanted to tell us about ScyllaDB University?
For those that haven’t tried it out yet, I would encourage you to just register as a user. Have a look at the available courses and the different lessons. Just have a go at it. See how it works.
I didn’t mention it but all of the material is available for free. So all you have to do is just register as a user. The courses are completely online. They’re self-paced, which means that whenever you have some free time you can advance at your own pace. So it doesn’t require you to finish it at one go.
We’ll keep our users updated. We’re constantly adding more material. Expect more to come!