




A lot of people want to get clarity on how to use ScyllaDB and Spring. In this blog, we’ll provide you a guide. As a bonus, you will learn tricks on how to work with time series data.
Spring is a Java framework for creating easy to use web services.
Spring Boot makes it easy to create stand-alone, production-grade Spring-based applications that you can “just run”.
How does Spring run on top of ScyllaDB?
Up until Spring Boot 2.5.0 (released May 2021), your application could use an older spring-data-cassandra that didn’t support prepared statements out of the box. CassandraRepository used SimpleStatements that were not routing and token aware, while with prepared statements you get routing info prepopulated and queries know which replicas serve their data. If you wanted to fix this situation you had to do it yourself and often people didn’t even realize their queries were not token aware! (It’s a commonly overlooked programming optimization.)
ScyllaDB Monitoring Stack provides you with ways that can reveal why your application is not performing optimally — either using ScyllaDB Monitoring Advisor, or when you look at the CQL dashboard.
This situation has gotten better: the preparing of queries in CassandraRepository changed with the fix for issue #677 and this related commit — Spring Boot 2.5.0, which included spring-data-cassandra 3.2.0 (we’re up to 3.3 as of this writing), started to support prepared queries out of the box!
Using the default CassandraRepository in OLD versions of Spring Boot still means your queries are made out of SimpleStatement objects. They are not routing aware (nor token aware) and hence their latency is not ideal — your query spends extra time on network hops from coordinator to replica. You need to take care of preparing them in a semi-manual way to get the right routing.
The interesting part is that ReactiveCassandraRepository has this solved for most queries. It does prepare them even in older versions of Spring Boot. When using a reactive approach for the same models as with CassandraRepository, your latencies would be much better!
And of course if you upgrade to the latest Spring Boot (at least 2.5.x), the same will be done for the default CassandraRepository too!
So what is a Kotlin developer supposed to do when he doesn’t want to use reactive, cannot use the latest Spring Boot version, and wants to have full control over his queries with an async repo? (Did someone just say self whipping? 🙃)
Do read on!
Spring Setup
Quick start with Spring Initializr gives you a recent Spring Boot 2.6.0 Kotlin application with gradle and ready for JDK 17. So if you use these options…
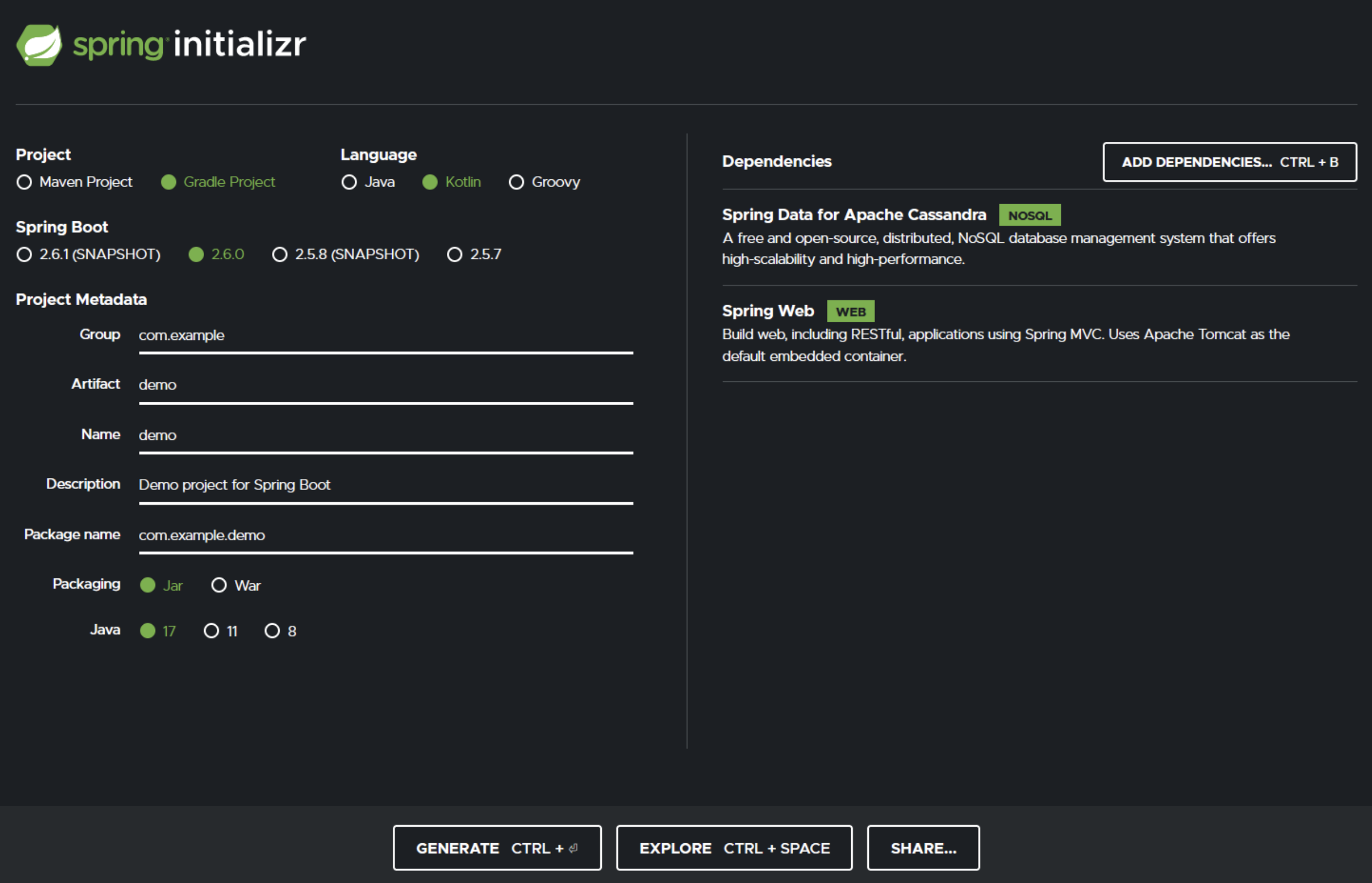
You won’t go wrong and dependencies will be preset for using the default cassandra driver. However, please upgrade the gradle wrapper to 7.3 in gradle-wrapper.properties distributionUrl so you get the Kotlin build working with JDK 17 properly.
Since this is already 2.6.0, you could use the default properly working CassandraRepository. We have a simple example variation on the theme of Greek monsters here:
https://github.com/scylladb/scylla-code-samples/tree/master/spring/springdemo-default
But let’s have a look at more complicated usage, which has custom explicit control of queries below.
ScyllaDB Development Setup
Starting a local ScyllaDB testing instance on a Linux* system is as easy as this:
docker run --name scylla-spring -p 10000:10000 -p 24:22 -p 7000:7000 -p 7001:7001 -p 9180:9180 -p 9042:9042 -p 9160:9160 -d scylladb/scylla:latestOn other systems, just run ScyllaDB on a remote box and connect directly(change configuration of app from localhost). Or using port forwarding with SSH, direct the 9042 port to your local machine. Check the start-scylla-container.sh script in the following github repo for inspiration.
See the ScyllaDB docker hub for other options to quickly start with ScyllaDB in dev using docker:
https://hub.docker.com/r/scylladb/scylla/
Or, see https://www.scylladb.com/download/ for other deployment options.
If you’re using a different IP to access your ScyllaDB server, go to src/main/resources/application.yml and change it appropriately.
Spring Objects Descriptions
Now you can just load the project generated by the Initializr to your favourite IDE.
You can find the sources that we will explain below on
https://github.com/scylladb/scylla-code-samples/tree/master/spring/springdemo-custom
The code uses JDK 17, Kotlin 1.6, Spring Boot 2.6.0, and spring-data-cassandra 2.6; the default Cassandra driver 4.13 is replaced by the ScyllaDB Java shard aware driver to get you the direct read path of prepared queries to the correct CPU.
Usage of the ScyllaDB driver is confirmed when the log shows you:
Using ScyllaDB optimized driver!!!
INFO Using ScyllaDB optimized driver!!!Spring is implementing the Model-View-Controller (MVC) approach, so you need to start with a model.
In this case, the model is a simple Stock object consisting of symbol, timestamp, and value.
In terms of ScyllaDB CQL, this would look like:
CREATE KEYSPACE IF NOT EXISTS springdemo
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor':1}
AND durable_writes = false;
CREATE TABLE IF NOT EXISTS springdemo.stocks
(symbol text, date timestamp, value decimal,
PRIMARY KEY (symbol, date))
WITH CLUSTERING ORDER BY (date DESC);Symbol is the primary key, while date is the clustering (ordering) key.
The above is attached as schema.cql in the github repo. Note that in production, you would likely use replication factor (RF) 3 to make sure your data is protected and highly available.
Accessing or viewing the objects from ScyllaDB is taken care of by AsyncStockRepository, which provides a few sample queries to the controller.
You now have full control and can create queries by yourself, so you can avoid SimpleStatements and achieve token awareness explicitly.
This is done by using prepared statements from the StockQueriesConfiguration singleton object. Happily, enough of them will be routing aware and you get routing to appropriate replica nodes (round-robining over them) out of box for prepared queries. With the scylla driver used, they even get routed to the proper cpu (shard) that handles the data…and that is sweet!
AsyncStockController provides the actual REST functionality on “/api/v1” by using endpoint annotations on top of the handler function.
Don’t get surprised by the timestamp that the REST API expects; it needs a compact format ‘yyyyMMddHHmmssSSS’ (only year is mandatory, but of course you should add month and day for a daily time series).
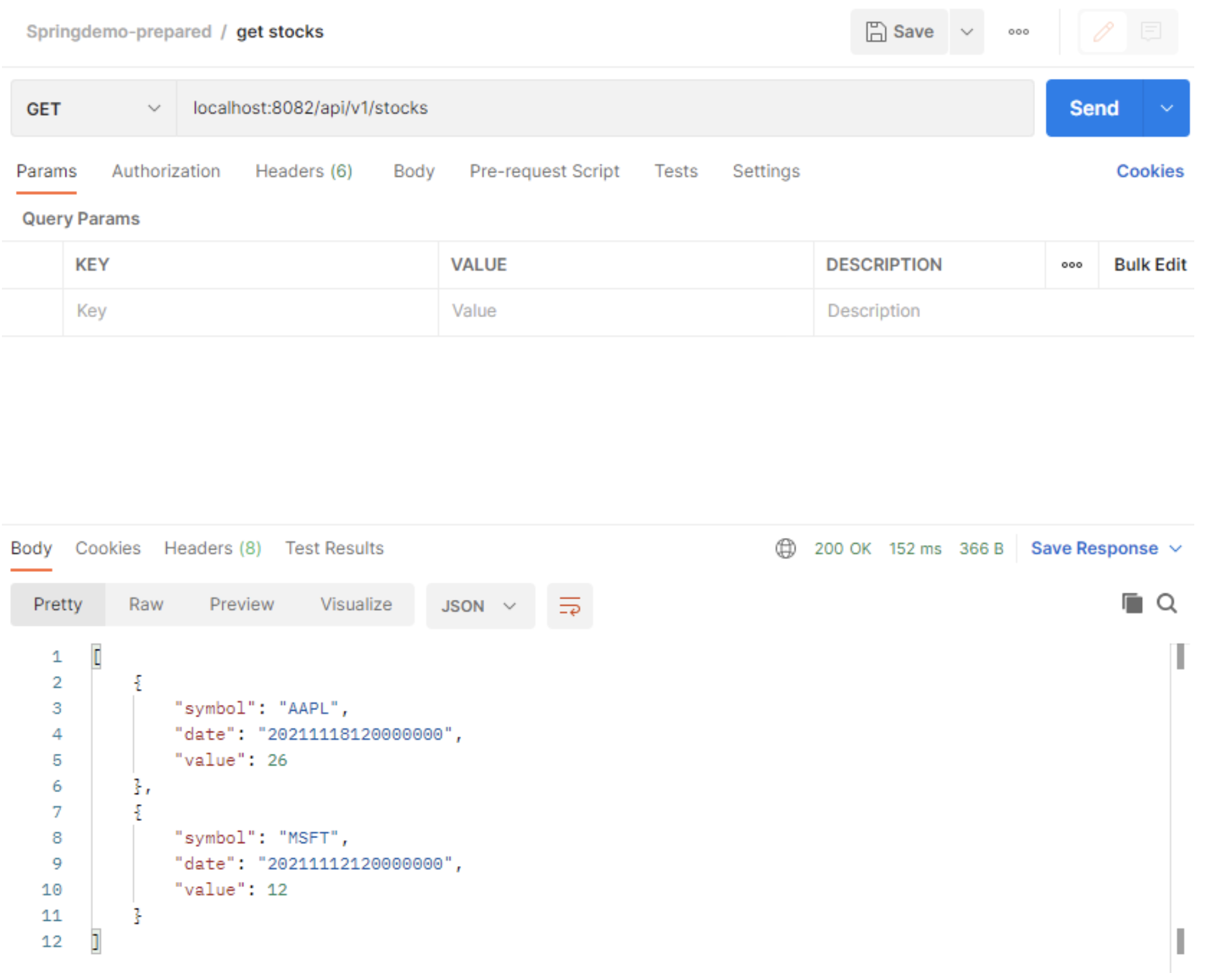
The REST can be easily tested with Postman.
We included a sample export of a collection in Springdemo-prepared.postman_collection.json which can be easily imported and used without needing a web application UI for simple tests.
So maybe in the next blog, we should create a web app UI. 🙂
Will it Scale?
You might ask about whether the data model will scale?
If you define a proper time window bucket, then it will.
ScyllaDB is smart enough to properly scan over such data. In the worst case scenario, you can add an explicit bucket, but it’s not needed here. And if you want to ingest historical data, do USE TIMESTAMP so they get bucketed properly using Time Window Compaction Strategy (TWCS).
To achieve the proper auto-bucketing, you will need to adjust the compaction strategy (or change it when creating the table) using TWCS:
ALTER TABLE springdemo.stocks WITH compaction = { 'class' : 'TimeWindowCompactionStrategy', 'compaction_window_unit' : 'DAYS', 'compaction_window_size' : 31 };And eventually, if you are only interested in the last 365*3 days (3 years) worth of quotes, you should set the default TTL (in seconds):
ALTER TABLE springdemo.stocks WITH default_time_to_live = 94608000;Also if your app is focused on reads, do check the build.gradle.kts for a pointer to the scylla shard aware driver being used (it has to be at the beginning of the dependency list for classloader to load, dtto for maven) and do try to use it in your app, too!
And now your ScyllaDB DB cluster will be happily working with your Spring app for years to come!
Enjoy!
Get Started with ScyllaDB Cloud
If you’d like to try out your own Spring Boot apps with ScyllaDB, the best place to get started is by downloading ScyllaDB Open Source. Then, if you have any questions, feel free to join our user community in Slack.



