ScyllaDB provides a feature called shard-aware port. In addition to listening for CQL driver connections on the usual port (by default 9042), ScyllaDB now also listens for connections on another port (by default 19042). The new port offers a more robust method of connecting to the cluster which decreases the number of connection attempts that the driver needs to make.
In this post, we will describe problems that arise when using the old port and how the new port helps to overcome them.
Token-awareness, Shard-awareness
To understand the problem the shard-aware port solves, we need to remind ourselves what token-awareness and shard-awareness is.
ScyllaDB achieves its high scalability by splitting data in two dimensions:
- Horizontally – a single ScyllaDB cluster consists of multiple nodes, each of them storing a portion of the total data.
- Vertically – a single ScyllaDB node is further split into multiple shards. Each shard is exclusively handled by a single CPU core and handles a subset of the node’s data.
(For a more in-depth look about the partitioning scheme, I refer you to another blog post here.)
All ScyllaDB nodes and shards are equal in importance, and are capable of serving any read and write operations. We call the node which handles a given write or read request a coordinator. Because data in the cluster is replicated – a single piece of data is usually kept on multiple nodes — the coordinator has to contact multiple nodes in order to satisfy a read or write request. We call those nodes replicas.
It’s not hard to see that it is desirable that the coordinator is also a replica. In such a case, the coordinator has one less node to contact over the network — it can serve the operation using local memory and/or disk. This reduces the overall network usage, and reduces the total latency of the operation.
Similarly, it is also best to send the request to the right shard. Although when you choose a wrong shard the right one will be contacted to perform the operation, it’s still more costly than using the right shard from the beginning and may incur a penalty in the form of higher latency.
The strategy of choosing the right node as the coordinator is called token-awareness, while choosing the right shard is called shard-awareness.
Usually, when doing common operations on singular partitions using prepared statements, the driver has enough information to calculate the token of the partition. Based on the token, it’s easy to choose the optimal node and shard to choose as the coordinator.
Problems with the Old Approach
For a driver to be token-aware, it is enough to have a connection open for every node in the cluster. However, in ScyllaDB, each connection is handled by a single shard for its whole lifetime.
Therefore, to achieve shard-awareness, the driver needs to keep a connection open to each shard for every node.
The problem is that previously a driver had no way to communicate to a ScyllaDB node which specific shard should handle the connection. Instead, ScyllaDB chose the shard that handled the least number of connections at the moment and assigned it to the new connection.
This method works well in some scenarios — for example, consider a single application connecting to a node with N shards. It wants to establish one connection for each shard, so it opens N connections, either sequentially or in parallel. If the node does not handle any other clients at the moment, this method will assign a different shard for each connection — each time a new connection is processed, there will be a shard which doesn’t handle any connections at the moment, and it will be chosen. In this scenario, this algorithm of assigning shards to connections works great.
However, there are realistic scenarios in which this algorithm does not perform so well.
Consider a situation in which there are multiple clients connecting at once — for example, after a node was restarted. Now connection requests from all clients will interleave with each other and for each client there is a chance that it will connect to the same shard more than once. If this happens, the driver has to retry connecting for every shard that was not covered by previous attempt.
An even worse situation occurs if there are some non-shard aware applications connected to a node such that one shard handles many more connections than the others. The shard assignment algorithm will then be very reluctant to assign the most loaded shard to a new connection. The driver will have to keep establishing excess connections to other shards until connection counts on each shard equalize. Only then the unlucky shard will have a chance of being assigned.
All of this can cause a driver to take some time before it manages to cover all shards with connections. During that time, if it is not connected to a shard, all requests which are supposed to be routed to it must be sent to another shard. This impacts latency.
Introducing the “Shard-Aware” Port
In order to fix this problem we made it possible for the driver to choose the shard that handles the new connection. We couldn’t do it by extending the CQL protocol. Unfortunately, due to implementation specifics of Seastar — the framework used to implement ScyllaDB — migrating a connection to another shard would be very hard to implement. Instead, ScyllaDB now listens for connections on the shard-aware port. The new port uses a different algorithm to assign shards — the chosen shard is the connection’s source port modulo the number of shards.
The drivers which support connecting over the shard-aware port will use it, if available, to establish connections to missing shards. This greatly reduces the number of connection attempts it has to make when multiple drivers connect at the same time. It also is immune to the problem caused by connections being unevenly distributed across shards due to non-shard-aware drivers.
An Experiment
To show that connecting to the cluster over the shard-aware port is more robust than the old approach, we ran a test which simulates a scenario in which multiple clients are connecting to the same node at the same time. We used our benchmarking application scylla-bench, which uses our fork of the GoCQL driver.
Our setup looked like this:
- Cluster: 3 nodes, each using i3.8xlarge instance type with ScyllaDB 4.3 installed. Each node had 30 shards.
- Loaders: 3 instances of type c5.9xlarge. On each loader we ran 50 scylla-bench instances in parallel, each writing 5k rows per second with concurrency 100.
During the test we restarted one of the database nodes and observed how many connections it took until all scylla-bench instances managed to establish connection per shard.
We ran the test with an older version of the driver that does not support the shard-aware port (1.4.3) and one that does (1.5.0).
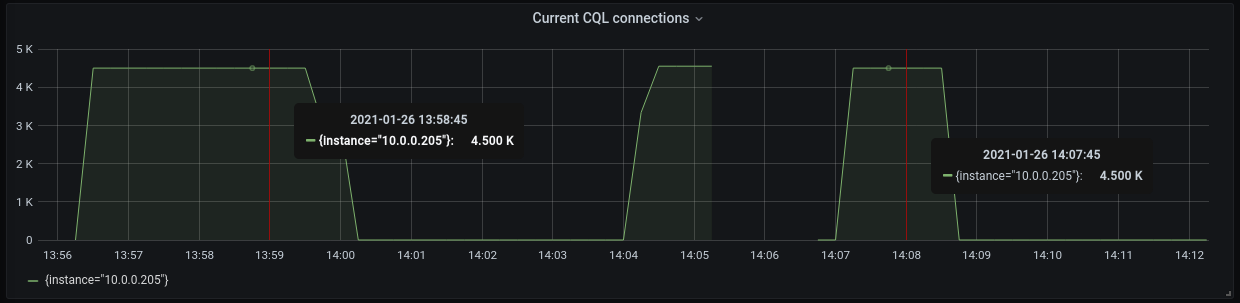
Fig 1. Active connection count to a node after it was restarted. On the left — GoCQL version 1.4.3, on the right — version 1.5.0.
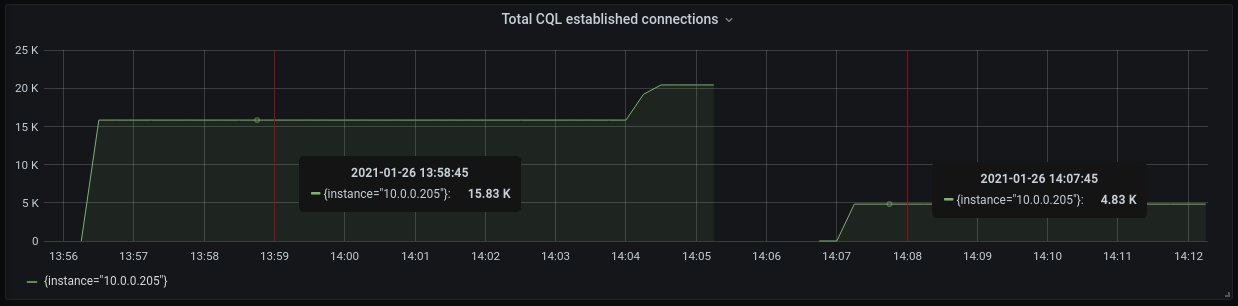
Fig 2. Total count of accepted connections during node’s runtime. Both left and right graphs show the number of accepted connections starting from node’s restart. On the left — GoCQL version 1.4.3, on the right — version 1.5.0.
We can see that the number of connection attempts is much lower for version of GoCQL which supports the shard-aware port – it’s very close to the desired number of connections, which is 4,500 (3 nodes * 50 scylla-bench instances * 30 shards). It’s not equal to 4,500 because a small percentage of connections timed out, which triggered fallback logic that attempts connecting to the non-shard aware port. The number 4,830 is still much better than 15,830 – more than three times smaller.
Limitations
The shard-aware port solution is not a perfect one, and in some circumstances it won’t work properly due to network configuration issues. While our drivers are designed to automatically detect such issues and fall back to the non-shard-aware port if necessary, it’s good to be aware of them so that you may either fix them, or disable this feature — so that your application doesn’t waste time detecting that the shard-aware port doesn’t work.
Unreachable shard-aware port. After establishing the first connection on the non-shard-aware port, a driver will try connecting to other shards using the shard-aware port. If the port is not reachable or connecting times out, it will fall back to the non-shard-aware port.
Client-side NAT. The power of the shard-aware port comes from the fact that the driver can choose which shard to connect to by specifying a particular source port. If your client application is behind a NAT which modifies source ports, it loses this ability. Our drivers should detect if it connects to an incorrect shard and fall back to the non-shard-aware port.
If you cannot fix those issues and suspect that using the non-shard-aware port instead might help you, you can disable this feature (or not enable it in the first place — it depends on the driver). Please refer to the documentation of your driver in order to learn how to do it.
Supported drivers and further reading
We are planning to add this feature to all drivers that are maintained by us. As of writing this blog, two of our drivers have full support for this feature merged and released:
- Supported: Our fork of GoCQL, starting from version 1.5.0. See the README for details.
- Supported: C++ driver for ScyllaDB, starting from version 2.15.2-1. See the documentation for details.
- Mostly supported: ScyllaDB Rust Driver, starting from version 0.1.0. The shard-aware port is detected automatically and used if enabled in ScyllaDB, but the fallback mitigations described in the “Limitations” section are not implemented at the time of writing this blog. See the README for more information about the driver.
- Not supported yet: This feature is not yet implemented in our Python driver nor our Java driver, but we intend to support this feature in both in the coming future.