This past week Cassandra 4.0 was finally released as GA, six years after the previous major release.
Initially developed as an open source alternative to Amazon DynamoDB and Google Cloud Bigtable, Cassandra has had a major impact on our industry. To the surprise of none, it eventually became one of the 10 most popular databases — quite an achievement! We at ScyllaDB were inspired by Cassandra seven years ago when we first decided to reimplement it in C++ in a close-to-hardware design while keeping its symmetric, scale-out architecture with the goal of becoming the best wide column store database.
Cassandra’s impact continues to echo through our industry. Even in recent years, long after Cassandra’s creation, cloud providers like Azure and AWS have added the CQL (Cassandra Query Language) API with varying degrees of compatibility; they’ve even added a managed Cassandra option.
However, even die-hard fans of Cassandra recognize that the project has slowed dramatically. This slow-down is visible in the trends for Cassandra’s DB-Engines.com ranking (see image below), its Github stars and its active commits.
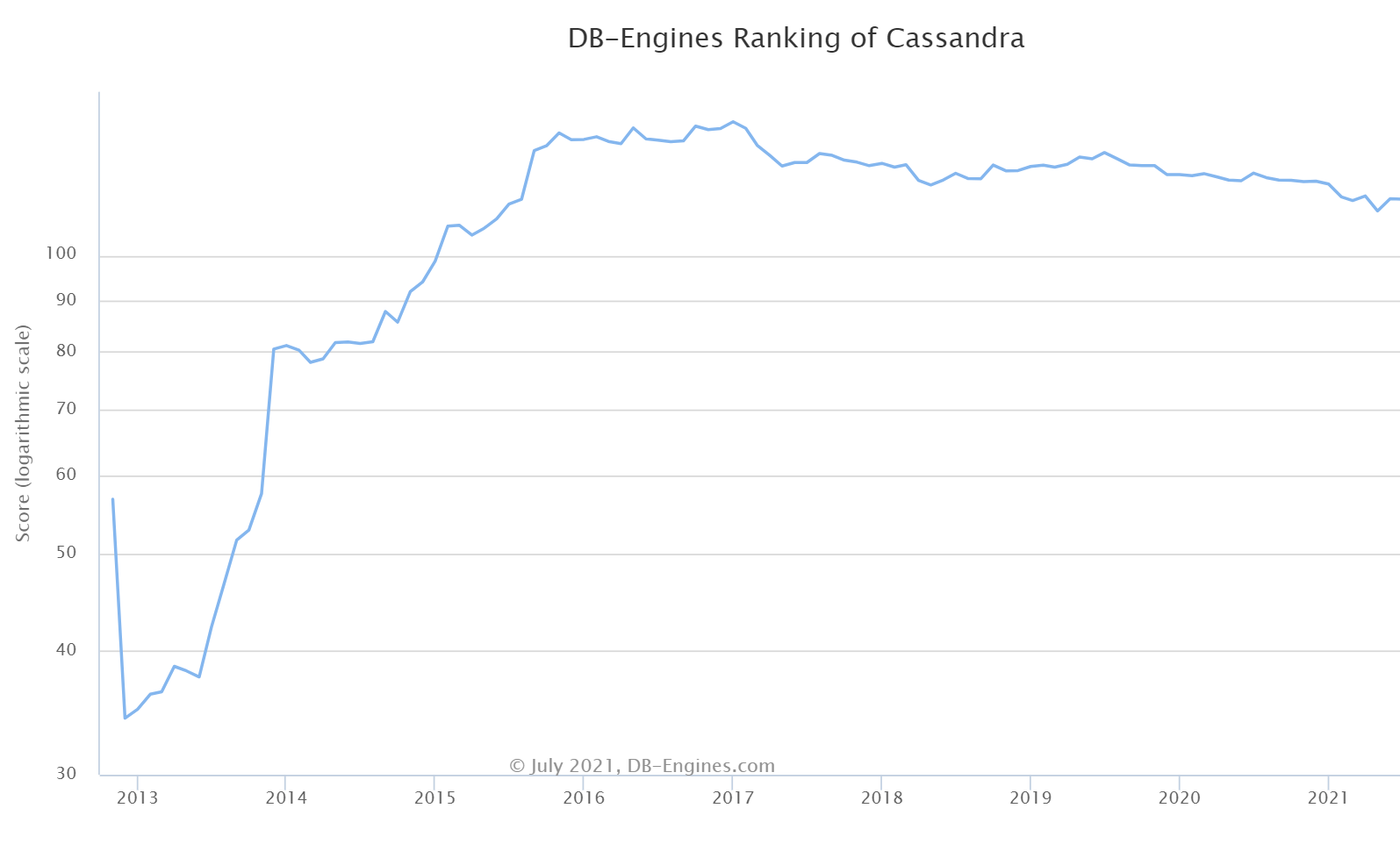
One of the key Cassandra 4.0 improvements is stabilization. We can attest that the late RC versions and GA are much better than the beta. In fact, the project reports more than 1,000 bug fixes. We see 476 closed issues year-to-date. (By comparison ScyllaDB has closed 611 in the same period while not focusing solely on stability.)
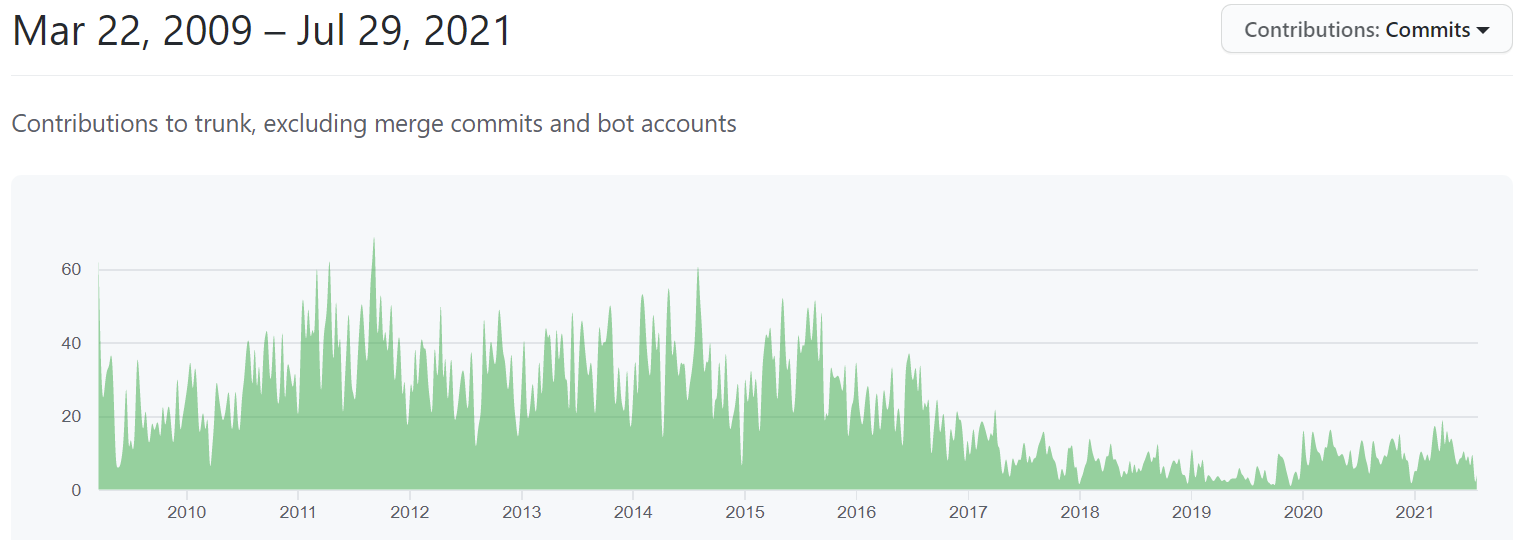
Despite its success with a wide base of users and having a foundation structure for its leadership, Cassandra’s contributors come primarily from Apple and Datastax. That is, its wide user base does not translate to core development, and the number of active contributors is lower than other projects — Kafka, Spark or ScyllaDB. Yes, we’re speaking from a somewhat biased perspective but these points are quite factual — even HBase has higher monthly code commits. When both of the major contributing companies are focusing on their own products, the amount of fresh code that reaches the project is low. This is not an opinion, it is a fact when you check the codebase — despite being six years in the making, the Cassandra 4.0 release doesn’t include many new features. Netty, virtual tables and zero copy for level triggered compaction aren’t that impressive. The major change is the use of a new JVM and a much better garbage collection algorithm — improving performance and latency by more than 25% over Cassandra 3.11 (Actually, we put this to the test and found Cassandra 4.0 capable of 25% – 33% greater throughput over Cassandra 3.11.).
We congratulate Apache Cassandra for a new major release, which is definitely more stable than any other Cassandra release, in addition, the new JVM with ZGC and Shenandoah GCs is a big improvement, but will this pace be sufficient to compete with the Amazons of the world?
The Dominant Wide Column Database of the Future
We at ScyllaDB have been challenging Cassandra for a long while. We firmly believe that we’re in the ideal position to become the best wide column store database. Our database is known for its performance and this Apache Cassandra 4.0 vs ScyllaDB 4.4 benchmark helps to illustrate our performance advantages. Yet, there are far many more reasons why one would choose ScyllaDB:
1. Open Source and Community
ScyllaDB is an open-source-first company. That means that any new changes — from features to bug fix — go first to the ScyllaDB open source branches and only later get backported to enterprise/cloud. We’re completely dedicated to open source NoSQL and we have championed industry-wide open source projects such as KVM, Linux kernel, OSv and many others.
ScyllaDB has many active contributors who commit at a rate of 100 commits/month. The vast majority of them come from ScyllaDB as this core project is highly complicated and our use of C++20 along with shard-per-core make the technical bar extremely high. We may not be a non-profit foundation community project but we tick all the other boxes (many of which are more important). We believe in open source and continue to dedicate lifetime(s) for it. We are also believers in traditional open source licenses and do not jump on SSPL-like trends.
Seastar, our open source core engine, receives many more external contributions and is powering Red Hat’s Ceph, Vectorized streaming and other outstanding projects. There are many other open source projects — ScyllaDB Operator was initiated by our community, ScyllaDB drivers are developed together with our community and projects like the Python sharded driver, Rust driver and GoCQLX are vibrant examples. There are many more, from Kafka connectors, CDC libraries, Spark migrators and more.And we haven’t even mentioned the Alternator — our open source database, compatible, DynamoDB API.
2. Current Featureset
ScyllaDB provides a featureset that’s superior to Cassandra. Our Change Data Capture feature is the most complete in the NoSQL community and we offer client libraries and Kafka connectors. But don’t take it from us; listen to what Confluent have to say about it in this recent webinar.
Materialized Views are supported at GA level. Design flaws led Cassandra to revert MV, while we at ScyllaDB fixed most of the issues and we’re about to have a major architecture change to make them flawless.
ScyllaDB is unique in our ability to provide per-service SLAs with different priorities. We even developed a new WebAssembly user-defined-function option which will allow us to run almost any language compiled code inside ScyllaDB itself.
3. Scalability
Cassandra has always been the industry’s northstar in terms of number of nodes per cluster. ScyllaDB adopted the same design and made it better, making it possible to scale to hundreds and even thousands of nodes. But the real difference for ScyllaDB is scaling up — ScyllaDB scales up to 256 CPUs and more. Moreover, our nodes can host 60TB of data while they can stream/decommission at hardware speed. It’s not rare to see disk writes of 12GB/s (bytes!) and 50gbp networking. ScyllaDB can scale the number of keyspaces to hundreds and beyond and our single partition record is 200GB and growing.
4. API
ScyllaDB fully supports the CQL api, along with an Amazon DynamoDB-compatible api. We even received a community-led Redis API (basic K/V portion). As the core is scalable and robust, it is easy to add compatible APIs. Beyond ease of migration, the ScyllaDB team analyzes the api and expands the core capabilities. DynamoDB streams encourage us to develop our CDC approach with pre/post images but with an innovative internal-table interface. DynamoDB’s leader election was one of the key drivers to add the Raft protocol.
5. Roadmap
The database is a 50 years-old domain, and even NoSQL itself isn’t new. However, the amount of innovation, use cases, challenges, and compute environments have never been as large. Our hands are full with work and we constantly have no choice but to pass on exciting project ideas.
Yet, the ScyllaDB team has decided to COMPLETELY TRANSFORM our fundamental assumptions. After we implemented LWT using Paxos and added read-modify-write verbs to match DynamoDB using LWT, we realized that it’s time to move to a better consensus protocol. This is a good match to improve other oversights of ScyllaDB/Cassandra and make schema changes transactional, topology changes consistent (and thus double a cluster in a single operation) and provide full consistency at the price of eventual consistency.
Our Raft initiative was announced last January and is now part of the Circe project. Raft will enable long-term improvements such as synchronous materialized views and can completely eliminate repair (as the replicas are always in-sync).
6. Performance
We have published a detailed benchmark comparison between Cassandra 4.0 and ScyllaDB. We tested throughput, latency and, more importantly, the speed of maintenance operations — from streaming to new nodes, decommission, failover and more. We’ve demonstrated leadership vs DynamoDB, Cassandra, Bigtable and others, but we’ll save all that for another day.
Cassandra isn’t going to go away. Instead, it will slowly lose traction as its development pace continues to slow down. Databases are hard to replace (here’s proof: Microsoft Access is still ranked high on db-engines) but it won’t be top of mind for new projects, either.
To be clear, we are not interested in the death of Cassandra. This is not a zero-sum game. If the ecosystem evolves and more CQL-based tools are generated, the whole segment benefits. More tools can be created on top of CQL, from JanusGraph to KairosDB, Kong and more. File formats can improve, drivers flourish and so forth. We are happy to see our own tools being used broadly, even by competitors — such as our Rust driver, Spark migrator and Gemini quality assurance tool.
All this to say, we are obviously very bullish on our future. We encourage you to join thousands of developers from such leading brands as Discord, Disney+, Bloomberg, Palo Alto networks, Instacart and many more who have chosen ScyllaDB as their NoSQL database.
You’ll find that the best reason of all to try ScyllaDB is on our downloads page.