



Paxos FAQs
Achieving Paxos Distributed Consensus – How Does it Work?
Paxos is an algorithm that enables a distributed set of computers (for example, a cluster of distributed database nodes) to achieve consensus over an asynchronous network. To achieve agreement, one or more of the computers proposes a value to Paxos. Consensus is achieved when a majority of the computers running Paxos agrees on one of the proposed values.
In general terms, Paxos selects a single value from one or more of the values that are proposed, and then broadcasts that value to all of the cooperating computers. Once the Paxos algorithm has run, all of the computers (or database nodes)) agree upon the proposed value, and the cluster clocks forward.
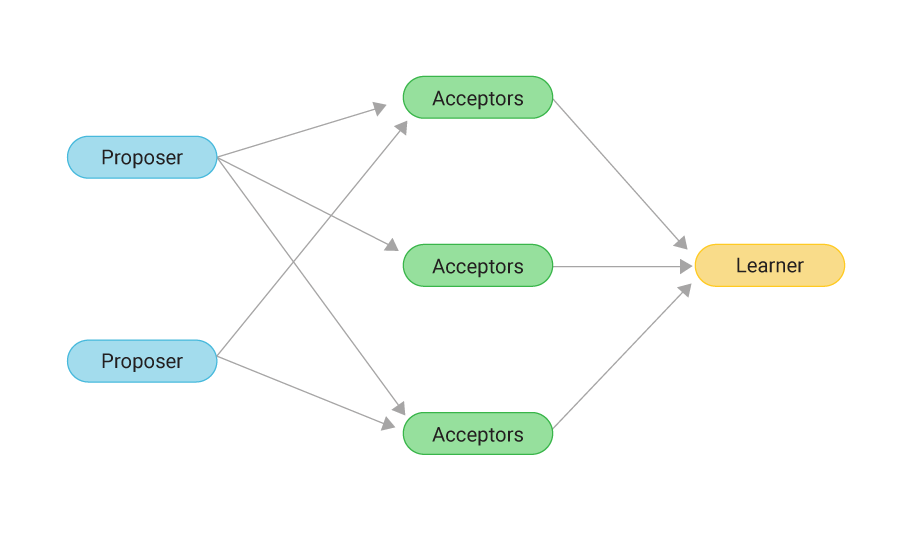
Paxos defines several different roles which must cooperate to achieve consensus; they interact to collectively agree on a proposed value. The three roles are:
- Proposers, who receive requests (values) from clients and try to convince acceptors to accept the value they propose.
- Acceptors, who accept certain proposed values from proposers and let proposers know whether a different value was accepted. A response from an acceptor represents a vote for a particular proposal.
- Learners, who announce the outcome to all participating nodes.
In practice, a single node may run as a proposer, acceptor, and a learner. Indeed, Paxos usually coexists with the service that requires consensus, with each node taking on all three roles. For the sake of understanding the protocol, however, it is useful to consider them to be independent entities.
Paxos achieves many of its properties through the concept of a ballot. A ballot is an effectively unique identifier that is associated with each transaction. For example, in the case of a NoSQL database , for example, a ballot is a 128-bit UUID based on 64-bit clock reading, a random bit sequence, and the machine id. This makes all ballots unique and chronologically orderable. Paxos ballots are tracked independently for each partition key. This is both a strength and a weakness. Absence of coordination between transactions against different partitions increases the overall throughput and availability, but provides no mutual order. As a result, transactions cannot span across partitions.
Ballots, as well as other protocol states, are stored in a local system table, system.paxos, at all replicas. When a transaction is complete, most of this state is pruned away. However, if a transaction fails mid-way, the state is kept for a preconfigured duration (which is set to 10 days by default). DBAs are expected to run nodetool repair before it expires.
The node which is performing the transaction (also known as the coordinator) begins by creating a new ballot and asking the nodes owning data for the respective token range to store it. Replicas refuse to store the ballot if it is older than the one they already know, while the coordinator refuses to proceed if it doesn’t have a majority of responses from replicas. This majority rule ensures that only a single transaction is modifying data at a time, and that the coordinator is up-to-date with the most recent changes before it suggests a new one.
Once the coordinator has received a majority of promises to accept a new value, it evaluates the lightweight transaction condition and sends a new row to all replicas. Finally, when a majority of replicas accept and persist the new row in their system.paxos table, the coordinator instructs them to apply the change to the base table. At any point some of the replicas may fail. Even in absence of failure, replicas may refuse a ballot because they have made a promise to a different coordinator. In all such cases, the coordinator retries, possibly with a new ballot. After all steps are complete, the coordinator requests the participants to prune system.paxos from intermediate protocol state. The pruning is performed as a background task.
Raft vs Paxos vs Other Consensus Algorithms
Paxos is a predecessor to Raft. The Raft protocol was invented specifically to improve on perceived weakness in the Paxos protocol. According to the inventors of Raft, the complexity of Paxos makes it difficult to implement. In their words, “Paxos’ formulation may be a good one for proving theorems about its correctness, but real implementations are so different from Paxos that the proofs have little value.” The title of the Raft paper speaks to this mission: “In Search of an Understandable Consensus Algorithm.”
Does ScyllaDB Offer Solutions for Paxos?
ScyllaDB originally supported Lightweight Transactions (LWT) using Paxos, but these transactions require three roundtrips. ScyllaDB is moving to the Raft protocol as part of Project Circe, ScyllaDB’s 2021 initiative to improve ScyllaDB by adding greater capabilities for consistency, performance, scalability, stability, manageability and ease of use..
By implementing Raft, ScyllaDB is able to execute consistent transactions without this performance penalty. Paxos I has been used only for LWT Integrating Raft with most aspects of ScyllaDB will significantly improve manageability and consistency. In addition to providing significant operational advantages, ScyllaDB’s Raft support will enable application developers to leverage strongly consistent transactions at the cost of regular database operations.
More about ScyllaDB’s move from Paxos to Raft
The core Raft protocol is implemented in ScyllaDB and ScyllaDB 5.4 implements strongly consistent schema management and topology updates. ScyllaDB Summit 2024 also features multiple discussions on what ScyllaDB is doing with Raft and what this means for ScyllaDB users.